Python request,httplib,urllib,bs4使用
python2.X 有这些库名可用: urllib, urllib2, urllib3, httplib, httplib2, requests
python3.X 有这些库名可用: urllib, urllib3, httplib2, requests
httplib 和 httplib2 httplib 是http客户端协议的实现,通常不直接使用, urllib是以httplib为基础 httplib2 是第三方库, 比httplib有更多特性。
urllib
python2:
import urllib
f = urllib.urlopen('https://www.baidu.com')
print f.read()
params = urllib.urlencode({
'spam': 1, 'eggs': 2, 'bacon': 0})
f = urllib.urlopen("http://www.musi-cal.com/cgi-bin/query?%s" % params) /GET方法
f = urllib.urlopen("http://www.musi-cal.com/cgi-bin/query", params) /POST方法
print f.read() /返回html页面
proxies = {
'http': 'http://proxy.example.com:8080/'}
opener = urllib.FancyURLopener(proxies)
opener = urllib.FancyURLopener({
}) /不使用代理
f = opener.open("http://www.python.org")
f.read()
///urllib2
import urllib2
GET一个URL
>>> import urllib2
>>> f = urllib2.urlopen('http://www.python.org/')
>>> print f.read()
使用基本的HTTP认证
import urllib2
auth_handler = urllib2.HTTPBasicAuthHandler()
auth_handler.add_password(realm='PDQ Application',
uri='https://mahler:8092/site-updates.py',
user='klem',
passwd='kadidd!ehopper')
opener = urllib2.build_opener(auth_handler)
urllib2.install_opener(opener)
urllib2.urlopen('http://www.example.com/login.html')
build_opener() 默认提供很多处理程序, 包括代理处理程序, 代理默认会被设置为环境变量所提供的.
一个使用代理的例子
proxy_handler = urllib2.ProxyHandler({
'http': 'http://www.example.com:3128/'})
proxy_auth_handler = urllib2.ProxyBasicAuthHandler()
proxy_auth_handler.add_password('realm', 'host', 'username', 'password')
opener = urllib2.build_opener(proxy_handler, proxy_auth_handler)
opener.open('http://www.example.com/login.html')
添加HTTP请求头部
import urllib2
req = urllib2.Request('http://www.example.com/')
req.add_header('Referer', 'http://www.python.org/')
r = urllib2.urlopen(req)
更改User-agent
import urllib2
opener = urllib2.build_opener()
opener.addheaders = [('User-agent', 'Mozilla/5.0')]
opener.open('http://www.example.com/')
python3:
这里urllib成了一个包, 此包分成了几个模块,
urllib.request 用于打开和读取URL, urllib.error 用于处理前面request引起的异常, urllib.parse 用于解析URL, urllib.robotparser用于解析robots.txt文件
import urllib.request
f = urllib.request.urlopen('https://www.baidu.com')
print(f.read())
with urllib.request.urlopen('http://www.python.org/') as f:
print(f.read(300))
在上面的例子里,urlopen()的参数就是一个url地址;
但是如果需要执行更复杂的操作,比如增加HTTP报头,必须创建一个 Request 实例来作为urlopen()的参数;而需要访问的url地址则作为 Request 实例的参数。
url = "http://www.itcast.cn"
#IE 9.0 的 User-Agent,包含在 ua_header里
ua_header = {
"User-Agent" : "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;"}
# url 连同 headers,一起构造Request请求,这个请求将附带 IE9.0 浏览器的User-Agent
request = urllib.request.Request(url, headers = ua_header)
request.add_header("Connection", "keep-alive") /使用add_header来添加headers
# 向服务器发送这个请求
response = urllib.request.urlopen(request)
html = response.read()
print (html)
print(request.headers)
print(request.get_header(header_name='Connection')) //查看headers
print(111)
print(response.headers)
当我们需要需要传递中文参数给URL时,可以
url = "/api?username={0}&auth={1}&num=0&q=product=={2}".format(
self.username, self.password, urllib.quote(self.product))
就可以解决在传输中文参数时时的解码报错问题。
>>> print urllib2.quote('我爱你')
%E6%88%91%E7%88%B1%E4%BD%A0
使用GET时设置URL的参数
>>> import urllib.request
>>> import urllib.parse
>>> params = urllib.parse.urlencode({
'spam': 1, 'eggs': 2, 'bacon': 0})
>>> url = "http://www.musi-cal.com/cgi-bin/query?%s" % params
>>> with urllib.request.urlopen(url) as f:
... print(f.read().decode('utf-8'))
使用POST时设置参数
>>> import urllib.request
>>> import urllib.parse
>>> data = urllib.parse.urlencode({
'spam': 1, 'eggs': 2, 'bacon': 0})
>>> data = data.encode('ascii')
>>> with urllib.request.urlopen("http://requestb.in/xrbl82xr", data) as f:
... print(f.read().decode('utf-8'))
httplib
httplib是提供了Web客户端的功能和接口。这样httplib将会完成Web浏览器的基本功能。httplib实现了http和https的客户端协议,但是在python中,模块urllib和urllib2对httplib进行了更上层的封装。
参数
httplib.HTTPConnection
- host: 请求的服务器host,不能带http://开头
- port: 服务器web服务端口
- strict: 是否严格检查请求的状态行,就是http1.0/1.1协议版本的那一行,即请求的第一行,默认为False,为True时检查错误会抛异常。
- timeout: 单次请求的超时时间,没有时默认使用httplib模块内的全局的超时时间
httplib.HTTPConnection(host[,port[, strict[, timeout[, source_address]]]])
conn =httplib.HTTPConnection('www.baidu.com')
conn = httplib.HTTPConnection('www.baidu.com:80')
conn =httplib.HTTPConnection('www.baidu.com','80')
conn =httplib.HTTPConnection('www.baidu.com','80',True)
conn =httplib.HTTPConnection('www.baidu.com','80',True,10)
conn =httplib.HTTPConnection('www.baidu.com:80',True,10)
print conn.request('get','/','',{
'user-agent':'test'})
/要创建https链接,必须要保证底层的socket模块是支持ssl的编译模式,即编译时ssl选项的开关是开着的
httplib.HTTPSConnection('www.baidu.com',443,key_file,cert_file,True,10)
HTTPConnection对象request方法:
conn.request(method, url[, body[, headers]])
method: 请求的方式,如’GET’,‘POST’,‘HEAD’,‘PUT’,'DELETE’等
url: 请求的网页路径。如:’/index.html’
body: 请求是否带数据,该参数是一个字典
headers: 请求是否带头信息,该参数是一个字典,不过键的名字是指定的http头关键字
con = httplib.HTTPConnection('newcmdb.intra.sina.com.cn', 80, 1)
header = {
"accept": "application/json"}
url = "/api?username={0}&auth={1}&num=0&q=product=={2}".format(username, password, urllib.quote(product))
con.request('GET', url, headers=header)
response = con.getresponse()
print response.read() / 获得http响应的内容部分,即网页源码
print response.getheaders() /获得所有的响应头内容,是一个元组列表[(name,value),(name2,value2)]
print response.msg /获取所有的响应头信息。包含响应头的mimetools.Message实例
print response.version /获取服务器所使用的http协议版本。11表示http/1.1;10表示http/1.0
print response.status / 获取响应的状态码。如:200表示请求成功
print response.reason /返回服务器处理请求的结果说明。一般为”OK”
conn.set_debuglevel(0) /设置高度的级别
conn.close() /关闭与服务器的连接
HTTPConnection类会实例并返回一个HTTPConnection对象
调用接口实例:
class HttpRequest(object):
"Http class for get information from cmdb"
def __init__(self, product):
self.username = 'api_bip'
self.password = 'rQK6SPDgQiByK61LNryP1P1Q'
self.product = product
def conn(self, url='newcmdb.intra.sina.com.cn', port=80):
self.con = httplib.HTTPConnection(url, port, 1)
def close(self):
self.con.close()
def get(self):
header = {
"accept": "application/json"}
url = "/api?username={0}&auth={1}&num=0&q=product=={2}".format(
self.username, self.password, urllib.quote(self.product))
self.con.request('GET', url, headers=header)
response = self.con.getresponse()
return response.read()
参考连接:源地址
Request
Requests 继承了urllib2的所有特性。Requests支持HTTP连接保持和连接池,支持使用cookie保持会话,支持文件上传,支持自动确定响应内容的编码,支持国际化的 URL 和 POST 数据自动编码。requests 的底层实现其实就是 urllib3
GET
场景一:直接返回内容
es9206.bip.sssa.com.cn:9206/_cat/nodes
这个连接用内网去访问可以直接看到以下内容:
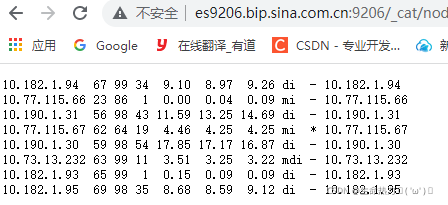
我们就可以这样获取内容:
import requests
url = "http://es5210.bip.sina.com.cn:9200/_cat/nodes"
response = requests.get(url)
print response.text #可以看到上面的内容,text返回unicode码
print type(response.text) #返回HTML页面 (bs4)库
当返回HTML页面的时候我们可以这样解析:
import requests
from bs4 import BeautifulSoup
#返回HTML内容
response = requests.get("http://www.baidu.com/").text
soup = BeautifulSoup(response,'html.parser')
print soup.prettify()

附上BeautifulSoup的一些其他解析用法。

bs4库的基本元素:
在上面,我们的soup = BeautifulSoup(response,‘html.parser’)

response = requests.get("http://www.baidu.com/").text
soup = BeautifulSoup(response,'html.parser')
print soup.input /返回input标签的内容,默认返回第一个该标签
print soup.input.attrs /返回input标签的内容以字典形式显示
print soup.title /返回title标签的内容
print soup.title.name /返回标签的名成,title就是title
print soup.title.string /返回标签之间的字符串。

基于bs4的html内容遍历法
掌握了遍历法 我们可以从一个节点获得想要的另一个节点信息,是提取html页面信息的重要方法
/上行遍历
print soup.a.parent /返回父亲标签
for i in soup.a.parents: /所有先辈节点
print i.name
/下行遍历
print len(soup.div.contents) /返回子节点列表
for i in soup.div.children: /div的所有子节点内容
print i
/平行遍历
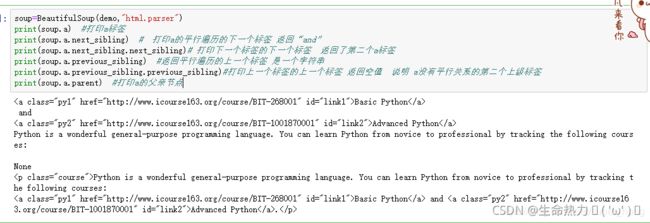
信息提取
# for link in soup.find_all('a'):
for link in soup('a'): /soup.find_all('a')可以省略未soup('a')
print link /找到所有a标签
print link.get('href') /打印出a标签href属性的值
print(soup.a.attrs['href']) /也可直接
print soup.find_all(['a','b']) /找到所有a,b标签放到列表里
print soup.find_all("a","mnav") /找到a标签中,有mnav属性的
import re
for tag in soup.find_all(re.compile("t$")): /根据正则匹配标签
print tag.name
场景二:加参数
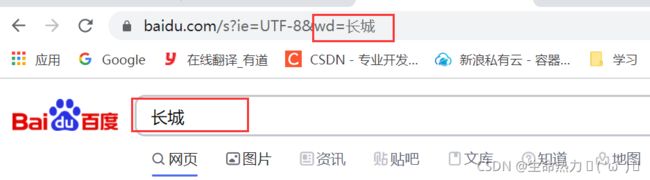
url = 'http://www.baidu.com/s?'
kw = {
'ie':'UTF-8','wd':'长城'}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
response = requests.get(url=url,params=kw)
print response.url / 查看完整url地址
http://www.baidu.com/s?wd=%E9%95%BF%E5%9F%8E&ie=UTF-8
print response.encoding / 查看响应头部字符编码
utf-8
print response.status_code / 查看响应码
200
print response.headers /取得响应头部信息,字典形式。
print response.headers['Content-Encoding']
gzip
print response.json() /把网页中的json数据转成字典并将其返回。
POST
formdata = {
"to": "AUTO",
"from": "AUTO",
"i": "i love python",
"smartresult": "dict",
"client": "fanyideskweb",
"doctype": "json",
"Version": "2.1",
"keyfrom": "fanyi.web",
"action": "FY_BY_ENTER"
}
url = "https://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36"}
response = requests.post(url, data=formdata, headers=headers)
print response.text
print response.status_code
print response.url
print response.headers

requests.post()
在通过requests.post()进行POST请求时,传入报文的参数有两个,一个是data,一个是json。
常见的form表单可以直接使用data参数进行报文提交,而data的对象则是python中的字典类型;
而在最新爬虫的过程中遇到了一种payload报文,是一种json格式的报文,因此传入的报文对象也应该是格式的;这里有两种方法进行报文提交:
import requests
import json
url = "http://example.com"
data = {
'a': 1,
'b': 2,
}
/ 1
requests.post(url, data=json.dumps(data))
/ 2-json参数会自动将字典类型的对象转换为json格式
requests.post(url, json=data)
代理proxies参数
如果需要使用代理,你可以通过为任意请求方法提供 proxies 参数来配置单个请求:
proxies = {
"http": "127.0.0.1",
"https": "http://12.34.56.79:9527"
}
response = requests.get("http://www.baidu.com", proxies=proxies)
print response.text
/也可以通过本地环境变量 HTTP_PROXY 和 HTTPS_PROXY 来配置代理:
export HTTP_PROXY="http://12.34.56.79:9527"
export HTTPS_PROXY="https://12.34.56.79:9527"
私密代理验证(特定格式) 和 Web客户端验证(auth 参数)
私密代理
/ 如果代理需要使用HTTP Basic Auth,可以使用下面这种格式:
proxy = {
"http": "mr_mao_hacker:[email protected]:16816" }
response = requests.get("http://www.baidu.com", proxies = proxy)
print response.text
web客户端验证
果是Web客户端验证,需要添加 auth = (账户名, 密码)
import requests
auth=('test', '123456')
response = requests.get('http://192.168.199.107', auth = auth)
print response.text
Cookies 和 Sission
Cookies
如果一个响应中包含了cookie,那么我们可以利用 cookies参数拿到:
import requests
response = requests.get("http://www.baidu.com/")
# 7. 返回CookieJar对象:
cookiejar = response.cookies
# 8. 将CookieJar转为字典:
cookiedict = requests.utils.dict_from_cookiejar(cookiejar)
print cookiejar
print cookiedict

Sission
在 requests 里,session对象是一个非常常用的对象,这个对象代表一次用户会话:从客户端浏览器连接服务器开始,到客户端浏览器与服务器断开。
会话能让我们在跨请求时候保持某些参数,比如在同一个 Session 实例发出的所有请求之间保持 cookie 。
实现人人网的登录
import requests
# 1. 创建session对象,可以保存Cookie值
ssion = requests.session()
# 2. 处理 headers
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
# 3. 需要登录的用户名和密码
data = {
"email":"[email protected]", "password":"alarmchime"}
# 4. 发送附带用户名和密码的请求,并获取登录后的Cookie值,保存在ssion里
ssion.post("http://www.renren.com/PLogin.do", data = data)
# 5. ssion包含用户登录后的Cookie值,可以直接访问那些登录后才可以访问的页面
response = ssion.get("http://www.renren.com/410043129/profile")
# 6. 打印响应内容
print response.text
处理HTTPS请求 SSL证书验证
Requests也可以为HTTPS请求验证SSL证书,要想检查某个主机的SSL证书,你可以使用 verify 参数(也可以不写)
import requests
response = requests.get("https://www.baidu.com/", verify=True)
# 也可以省略不写
# response = requests.get("https://www.baidu.com/")
print response.text
如果SSL证书验证不通过,或者不信任服务器的安全证书,则会报出SSLError,据说 12306 证书是自己做的.
response = requests.get("https://www.12306.cn/mormhweb/",verify=True)
print response.text
为request请求设置headers
为什么要设置headers?
在请求网页爬取的时候,输出的text信息中会出现抱歉,无法访问等字眼,这就是禁止爬取,需要通过反爬机制去解决这个问题。
headers是解决requests请求反爬的方法之一,相当于我们进去这个网页的服务器本身,假装自己本身在爬取数据。
请求头中最重要的就是User-Agent,通常说的用户代理。添加请求头可以使requests发送的请求,在服务器看来是浏览器发送的。对反爬虫网页,可以设置一些headers信息,模拟成浏览器取访问网站 。
注意:headers中有很多内容,主要常用的就是user-agent 和 host,他们是以键对的形式展现出来,如果user-agent 以字典键对形式作为headers的内容,就可以反爬成功,就不需要其他键对;否则,需要加入headers下的更多键对形式。
url1 = 'https://baike.so.com/doc/24386561-25208408.html'
# 添加请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 QIHU 360SE'
}
response_1 = requests.get(url1)
response_2 = requests.get(url1,headers=headers)
response_1.encoding = 'utf-8'
response_2.encoding = 'utf-8'
print(response_1.request.headers)
print(response_2.request.headers)
with open('steve_jobs2.html','w',encoding='utf-8') as f1:
f1.write(response_1.text)

可见headers后请求头机变成了和浏览器一样了。
其它
在requests.get()方法中可以使用params参数来构建url
有时候请求得到的结果可能呈现乱码的状态,可以通过resp.encoding属性查看网页编码方式,同时可以在获取resp.text之前对resp.encoding='utf-8’赋值,这样再次获取的resp.text则会使用我们要求的编码方式。