
随着深度学习和人工智能领域取得突破性进展,以及无人配送车、无人出租车、无人巴士等智驾场景逐步落地深入,自动驾驶行业近年来取得了越来越多的关注和进步。然而,想要真正实现在道路上行驶,还需要解决众多技术问题。
感知系统作为车辆路径规划的依据之一,需要通过“数据训练”夯实基础,以监督学习的方式,将数十 PB 的训练数据提供给算法,通过其生成具有普适感知能力的模型,帮助自动驾驶车辆拥有更好地感知实际道路、车辆位置、障碍物信息等方面的能力,达到实时感知在途风险,作出具体行为决策的目的。
随着越来越多的雷达、摄像头等传感器被部署在车辆里,各个环节的工作量与日俱增,尤其是高性能自动驾驶汽车对数据的存储需求更是巨大,一天生成的数据量可达到 3-8 TB 左右。因此,如何高效、稳定地保证自动驾驶过程中收集到的大量数据,并快速形成自动驾驶的计算模型,成为了各大自动驾驶企业关注的首要问题。

本篇文章,焱融科技将基于国内某专注于研发和应用L4级自动驾驶技术,聚焦自动驾驶出行和自动驾驶同城货运两大场景的自动驾驶公司实际案例,分享 YRCloudFile 在自动驾驶训练场景下针对 IO 模型、容器化部署、性能提升、智能分层方面的实践经验和启发,希望能给相关从业者解决类似问题时提供一些参考和帮助。
海量数据,毫厘必争
此前,国内某 L4 级自动驾驶公司主要采取的是开源的存储解决方案,将 GPU 计算和存储以融合的形式进行部署,但是随着文件数量的上升,性能出现明显下降,原有的存储方式也逐渐开始影响训练的效率。因此,他们开始考虑升级现有的存储解决方案。在升级过程中,该公司重点关注并解决以下问题:
- 在日益剧增的海量数据场景下,如何提升设备性能,加快训练进度;
- 开源方案虽然具备解决海量文件的能力,但是随着数据量的增多,如何保证产品稳定性,避免难以维护的问题;
- 如何解决存算融合架构下,无法根据需求单独扩容的问题;
- 在数据经历收集、清洗、训练后,如何解决过程中所产生的冷数据的问题。
YRCloudFile 如何应对?
在了解该公司驾驶训练场景以后,焱融科技针对其自动驾驶训练数据集进行了一系列分析,并总结出其训练数据具备以下特征:
- 浩瀚数据文件,训练数据集的文件数量在几亿至几十亿甚至上百亿的规模;
- 小文件难治理,大部分文件的大小在几 KB 到几 MB 之间,一些特征文件的大小更是只有几十到几百 Byte;
- 读多写少,在数据写入存储后,根据训练要求会进行多次读取。
针对上述特征,焱融科技从元数据处理能力、目录热点、多级智能缓存、针对性调优再到智能分层,提供了一系列高性能、高可用、高扩展的存储方案。

焱融 YRCloudFile 自动驾驶应用场景下的工作流程
01 元数据处理能力,处理海量数据文件的基石
在面临海量文件时,由于 MDS 不能及时地响应读写请求,所以极易出现应有性能无法发挥的情况。如果想要突破存储的瓶颈,主要解决方案是提升元数据的处理能力。为此,焱融科技选择通过可水平扩展设计的 MDS 架构,实现 MDS 集群化。这主要考虑到以下三方面:
- 第一,MDS 集群化有利于缓解 CPU,降低内存压力;
- 第二,多个 MDS 有利于企业存储更多元的数据信息;
- 第三,在实现元数据处理能力水平扩展的同时,提升海量文件并发访问的性能。
目前,焱融 YRCloudFile 主要采用静态子树 + 目录Hash两者结合的方式搭建可水平扩展设计的 MDS 架构,其主要包含三大要素:
- 将根目录固定在 MDS 节点;
- 每一级目录会根据 Entry name 进行 hash,再次选择 MDS,以此保证横向扩展的能力;
- 在目录下文件的元数据进行存放过程中,不再进行 hash,而是跟父目录在同一个节点,以此保证一定程度的元数据本地性。
这种架构方式有两种好处,首先是实现了元数据的分布存储,通过扩展元数据节点,即可支持百亿级别的文件数量;其次是在一定程度上,保证了元数据的检索性能,减少在多个节点上进行元数据检索和操作。
02 目录热点,解决热点引发问题的关键
由于大数据集群的目录以及文件数据数不胜数,所以在自动驾驶车辆训练过程中,如果遇到多个计算节点需要同时读取这批文件时,其所在的 MDS 节点就会变成一个热点。整体结构如下图所示:
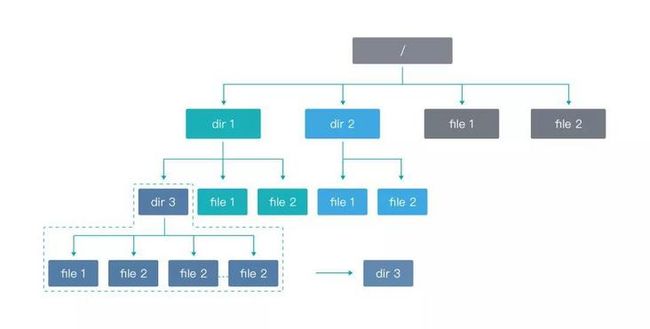
为了进一步提升小文件筛选与治理流程,焱融科技采用了增加虚拟子目录的方式,虽然这种方式增加了一层目录查询的操作,但是其具备灵活性强的特点,可以将热点分摊到集群中所有元数据节点。同时,这种解决方法还可以解决另一个问题——单目录的文件数量问题,使单目录实现支撑 20 亿左右的文件数量,并且可以根据虚拟子目录的数量灵活调整。整体结构如下图所示:
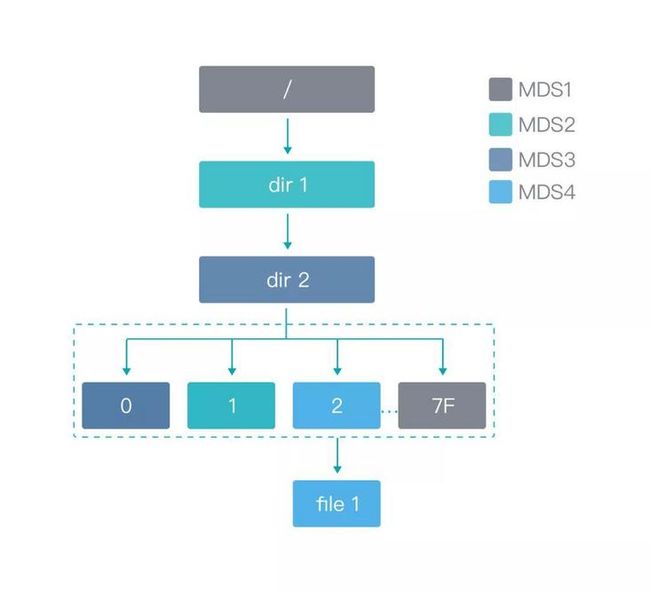
我们可以尝试通过访问/dir1/dir2/file1,来查看虚拟子目录是如何实现的。在这里,我们假设,dir2 是开启了 dirStripe 功能。主要访问流程如下:
- 在 MDS1 上拿到根目录的 inode 信息,查看没有开启 dirStripe
- 在 MDS1 上获取 dir1 的 dentry 信息,找到所属 owner(mds2)
- 在 MDS2 上拿到 dir1 的 inode 信息,查看没有开启 dirStripe
- 在 MDS2 上获取 dir2 的 dentry 信息,找到所属 owner(mds3)
- 在 MDS3 上拿到 dir2 的 inode 信息,查看开启了 dirStripe
- 根据 file1 的 filename,hash 到虚拟目录2上
- 在 MDS3 上获取虚拟目录2的 dentry 信息,找到所属 owner (mds4)
- 在 MDS4 上拿到 file1 的 inode 信息,返回给客户端
在整个模拟测试过程中,我们模拟了多个客户端,并发访问同一个目录的场景。在完成以后,我们通过对比发现,目录拆分后有10倍以上的性能提升。
03 多级智能缓存,提升整体性能的最佳实践
由于自动驾驶训练数据有很多类型,不同数据信息存储数据量不可估计,所以普通文件缓存容易出现只提供内存缓存,导致容量有限,通常一台 GPU 服务器可用的内存缓存仅数十 GB;同时,也容易出现内存缓存 LRU 置换算法,epoch 缓存在每个 epoch 的命中率低的问题。为了应对上述问题,焱融 YRCloudFile 客户端采用能提升整体性能的多级智能缓存特点:
- 在客户端缓存过程中,由内存缓存 + GPU 服务器本地 SSD 缓存组成;
- 可以指定缓存大小和位置;
- 训练程序先从客户端内存缓存中加载,未命中则从客户端服务器 SSD 加载,不命中最后从文件系统集群中加载;
- 对训练框架、应用程序完全透明。
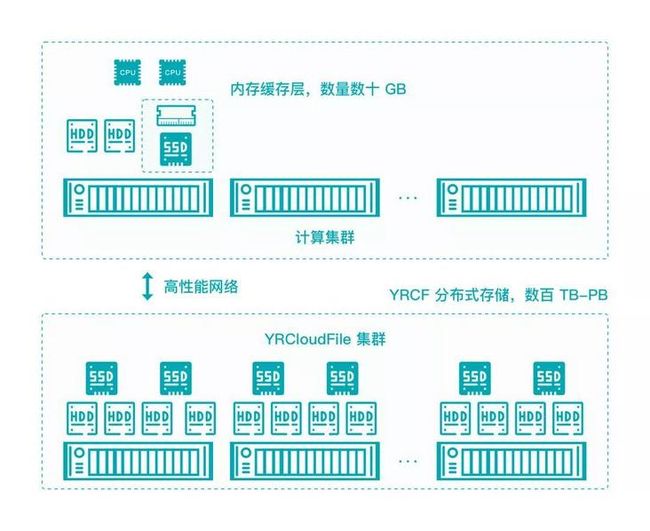
YRCloudFile 客户端多级智能缓存工作图
通过焱融 YRCloudFile 所提供的方案,可实现在整个训练中,数据集加载速度提升5倍的效果。
04 针对性调优,提升存储性能的最优解
大多数存储厂商在产品规划、产品稳定性、技术服务等方面更为专业。在现场进行 POC 测试的过程中,焱融 YRCloudFile 进行了包括但不限于功能、性能、可靠性等方面的测试。从中我们发现,集群的性能已经超过原有存储系统,但是没有达到预期的数值。因此,我们可以通过对现场环境的分析,提出以下几点优化措施:
- 增大节点上的 socks 数量,已获得更大的连接数;
- 调整线程数 workers,以匹配访问的数量;
- 调整 listeners 侦听线程数;
- 调整轮询策略,平衡响应速度和 CPU 资源。
经测试,通过针对性的调整后,YRCloudFile 可以将以上存储参数的调整性能提升了 20%-30%。
05 智能分层,数据流动最佳决策
了解数据存储的朋友都知道,访问频繁的数据为热数据,访问较少的数据为冷数据。然而,一旦冷数据过多,不仅会占用大量的存储空间,而且存储成本也随之增加。为此,焱融 YRCloudFile 专门提供了文件存储系统目录级的智能分层功能,通过高性能文件存储+低成本对象存储的组合,我们将有效实现热数据依然为人工智能等新兴业务提供高性能访问的特性,而冷数据可以在用户现有低成本的对象存储中有效保存。目前,焱融 YRCloudFile 智能分层技术支持以下特性:
- 根据不同目录,可以定义不同的冷热数据和数据流动策略;
- 冷数据自动流动至低成本的对象存储;
- 提供标准的 POSIX 接口,数据在冷热数据层之间流动对业务完全透明。
通过冷、热数据智能分层的方式,可以满足绝对大多数企业在自动驾驶训练过程中,对于存储高性能和数据长期保存的需求。
自动驾驶场景 YRCloudFile 无缝对接容器存储
当前,为了提升自动驾驶训练测试效率,大多数厂商以及 AI 应用会选择在容器为应用运行载体的 Kubernetes 平台上,运行 AI 训练和推理任务。Kubernetes 在 AI 训练方面主要有两个优势:
- 首先,Kubernetes 支持 GPU 调度,可以减少协调 GPU 资源所需的人力。同时,它可以实现 GPU 资源的自动回收,做到资源的有效分配;
- 其次,Kubernetes 支持多种负载的调度方式,适应不同的业务场景,作业与训练任务两者切合度非常高。
在自动驾驶训练过程中,存储系统对接容器场景常常遇到以下问题:
- 采用 in-tree 类型的存储代码,如 CephFS、GlusterFS、NFS 等,使得 Kubernetes 和存储厂商的代码紧耦合;
- 更改 in-tree 类型的存储代码,用户必须更新 Kubernetes 组件,成本较高;
- in-tree 存储代码中的 BUG 会引发 Kubernetes 组件不稳定;
- in-tree 存储插件享有与 Kubernetes 核心组件同等的特权,存在安全隐患;
- 仅支持部分 AccessModes、PV 管理、故障等方面的特性。
焱融 YRCloudFile 从设计到实现,主要场景就是解决 Kubernetes 环境中,容器化应用对存储的访问需求。焱融 YRCloudFile 通过支持 CSI、FlexVolume 等插件,实现对 AI 场景容器持久化存储的支持,并且根据客户实践应用,针对容器化场景的功能进行了优化:
- 海量 PV 场景下,快速定位 PV 热点,支持 RWO、RWX 等多种读写模式;
- 实现 CSI 对 PV 的智能调度;
- 依赖 PV 的 Pod 跨节点快速重建;
- 呈现 Pod、PV、PVC 实时监控与关联关系。
YRCloudFile 穿透自动驾驶存储全链增长
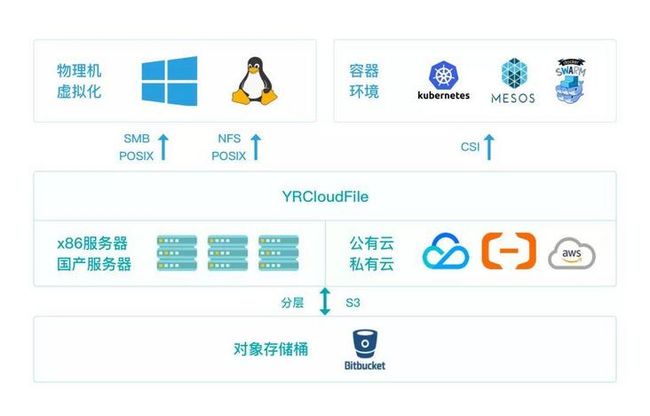
YRCloudFile 高性能分布式文件存储架构图
通过焱融 YRCloudFile,该 L4 级自动驾驶公司突破了存储性能的瓶颈,完美对接容器服务,完成数据跟随服务。另外,通过快速定位 PV 热点,该公司实现呈现 Pod、PV、PVC 实时监控与关联关系等独创性的管理功能,提升容器的管理效率。
当前,该 L4 级自动驾驶公司在焱融 YRCloudFile 高性能、高可用、易扩展的分布式存储支撑平台的帮助下,可以轻松应对海量小文件性能、容量的挑战。同时,满足了未来扩容需求。未来,该公司工作人员将极大减少在存储系统管理、配置和排错的时间,将更多的精力投入到训练业务中。
