分布式ID(唯一id-详解及教程)
应用场景
在业务系统中很多场景下需要生成不重复的 ID,比如京东订单编号、飞机票订单号、外卖订单号、支付流水单号、优惠券编号等都需要使用到。账户进行标识,以一个有意义的有序的序列号来作为全局唯一的ID。如电商平台,为了保证(用户信息安全),可通过订单编号查询到:商家信息、买家信息、物流信息、等关联全部信息。
分布式ID特点
分布式系统中我们对ID生成器要求又有哪些呢?
1. 全局唯一性:不能出现重复的ID号,既然是唯一标识,这是最基本的要求。
2. 简洁/直观:(生成的ID号)客户用于关联其它业务的唯一重要凭证。
3. 高并发
4. 高性能
5. 高可用
解决方案
1. 基于数据库方案
2. UUID
3. Redis生成ID
4. Twitter的snowflake算法
5. 利用zookeeper生成唯一ID
分布式解决方案描述
基于数据库方案
利用数据库生成ID是最常见的方案。能够确保ID全数据库唯一。
优点:
非常简单,代码方便,利用现有数据库系统的功能实现,成本小,有DBA专业维护。
ID单调自增(数字ID天然排序)
缺点:
不同数据库语法和实现不同,数据库迁移的时候或多数据库版本支持的时候需要处理。
在单个数据库或读写分离或一主多从的情况下,只有一个主库可以生成。有单点故障的风险。
在性能达不到要求的情况下,比较难于扩展。
如果涉及多个系统需要合并或者数据迁移会比较麻烦。
分表分库的时候会有麻烦。
UUID/GUID
UUID 是 通用唯一识别码(Universally Unique Identifier)的缩写,UUID 的目的是让分布式系统中的所有元素,都能有唯一的辨识资讯,
全局唯一标识符(GUID,Globally Unique Identifier)是一种由算法生成的二进制长度为128位的数字标识符。
特点
1.需要GUID的时候,可以完全由算法自动生成,不需要一个权威机构来管理。
2.GUID理论上能产生全宇宙唯一的值,对于以后的数据导入很方便。
优点:
全球唯一,在遇见数据迁移(不仅是表独立的,而且是库独立的),系统数据合并,或者数据库变更等情况下,可以从容应对。
代码简单、编写方便。
生成ID性能非常好,基本不会有性能问题。
缺点:
性能问题:UUID太长,通常以36长度的字符串表示,对MySQL索引不利:如果作为数据库主键/或关联查询,在InnoDB引擎下,UUID的无序性可能会引起数据位置频繁变动,严重影响性能。(UUID往往是使用字符串存储,查询的效率比较低。)
UUID无业务含义:很多需要ID能标识业务含义的地方不使用。
可读性很差(不直观且非简洁) ,如:6d9d06c3-976f-45fd-913a-01e636e90830
Redis生成ID
Redis 的原子自增:使用 incr/incrby(String key) 生成的 ID。
特点:
性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s 。
丰富的数据类型 – Redis支持的类型 String, Hash,List, , Set 及 Ordered Set 数据类型操作。
原子性 – Redis的所有操作都是原子性的,意思就是要么成功执行要么失败完全不执行。单个操作是原子性的。多个操作也支持事务,即原子性,通过MULTI和EXEC指令包起来。
丰富的特性 – Redis还支持 publish/subscribe, 通知, key 过期等等特性。
高速读写,redis使用自己实现的分离器,代码量很短,没有使用lock(MySQL),因此效率非常高。
优点:
不依赖于数据库,灵活方便,且性能优于数据库。
数字ID天然排序,对分页或者需要排序的结果很有帮助。
缺点:
如果系统中没有Redis,还需要引入新的组件,增加系统复杂度。
需要编码和配置的工作量比较大。
需要搭建Redis集群满足高可用
SnowFlake算法
snowflake是Twitter开源的分布式ID生成算法,结果是一个long型的ID。其核心思想是:使用41bit作为毫秒数,10bit作为机器的ID(5个bit是数据中心,5个bit的机器ID),12bit作为毫秒内的流水号(意味着每个节点在每毫秒可以产生 4096 个 ID),最后还有一个符号位,永远是0。 官方代码:https://github.com/twitter/snowflake。雪花算法支持的TPS可以达到419万左右(2^22*1000)。 雪花算法在工程实现上有单机版本和分布式版本。单机版本如下, 分布式版本可以参看美团leaf算法:https://github.com/Meituan-Dianping/Leaf 百度封装并开源:uid-generator https://github.com/baidu/uid-generator
百度uid-generator
唯一ID生成器
UidGenerator是Java实现的, 基于Snowflake算法的唯一ID生成器。UidGenerator以组件形式工作在应用项目中, 支持自定义workerId位数和初始化策略, 从而适用于docker等虚拟化环境下实例自动重启、漂移等场景。 在实现上, UidGenerator通过借用未来时间来解决sequence天然存在的并发限制; 采用RingBuffer来缓存已生成的UID, 并行化UID的生产和消费, 同时对CacheLine补齐,避免了由RingBuffer带来的硬件级「伪共享」问题. 最终单机QPS可达600万。依赖版本:Java8及以上版本, MySQL(内置WorkerID分配器, 启动阶段通过DB进行分配; 如自定义实现, 则DB非必选依赖)
中文文档
https://github.com/baidu/uid-generator/blob/master/README.zh_cn.md
官方源码
https://github.com/baidu/uid-generator
代码实战
架构如下依次创建
chapter-disributed-id 父工程(pom) uid-generator jar(普通jar) boot-disributed-id jar[8080]微服务 SSM操作
MySQL创建表WORKER_NODE
DROP TABLE IF EXISTS WORKER_NODE;
CREATE TABLE WORKER_NODE
(
ID BIGINT NOT NULL AUTO_INCREMENT COMMENT 'auto increment id',
HOST_NAME VARCHAR(64) NOT NULL COMMENT 'host name',
PORT VARCHAR(64) NOT NULL COMMENT 'port',
TYPE INT NOT NULL COMMENT 'node type: ACTUAL or CONTAINER',
LAUNCH_DATE DATE NOT NULL COMMENT 'launch date',
MODIFIED TIMESTAMP NOT NULL COMMENT 'modified time',
CREATED TIMESTAMP NOT NULL COMMENT 'created time',
PRIMARY KEY(ID)
)
COMMENT='DB WorkerID Assigner for UID Generator',ENGINE = INNODB;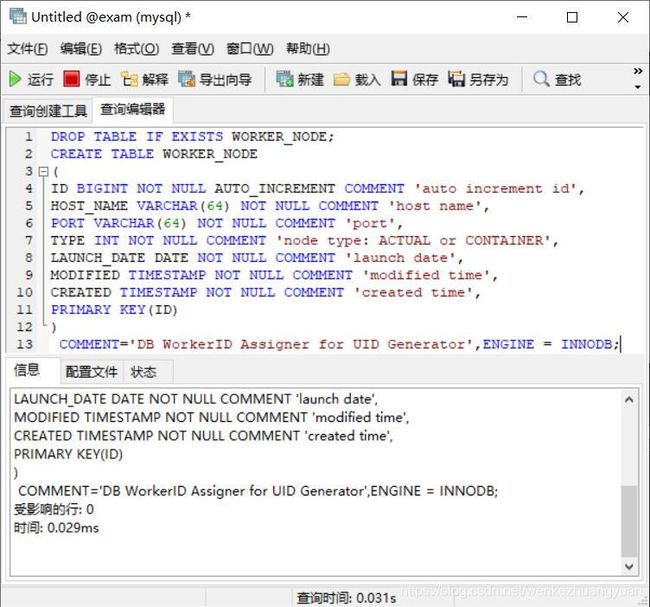
官方源码下载
https://github.com/baidu/uid-generator/
创建uid-generator 普通jar 子工程
pom.xml
chapter-distributed-id
com.example
1.0-SNAPSHOT
4.0.0
uid-generator
uid-generator
http://www.example.com
UTF-8
1.8
4.2.5.RELEASE
1.7.7
commons-collections
commons-collections
3.2.2
commons-lang
commons-lang
2.6
创建微服务子工程boot-disributed-id
SpringBoot SSM整合(此处忽略)
导入上方支持依赖jar
com.example
uid-generator
1.0-SNAPSHOT
配置生成器 cached-uid-spring.xml
提供了两种生成器: DefaultUidGenerator、CachedUidGenerator。
如对UID生成性能有要求, 请使用CachedUidGenerator 对应Spring配置分别为: default-uid-spring.xml、cached-uid-spring.xml
CachedUidGenerator配置
项目资源包路径下创建uid文件夹,然后到官方uid-generator 测试 [注意:这里是测试资源包] 资源包路径下uid/cached-uid-spring.xml 复制cached-uid-spring.xml文件,粘贴到该文件夹uid内。
创建配置UidConfig
package com.wpc.config;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.ImportResource;
@Configuration
//导入外部XML配置文件
@ImportResource(locations = { "classpath:uid/cached-uid-spring.xml" })
public class UidConfig {
}
入口类
package com.wpc;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class BootDisributedIdApplication {
public static void main(String[] args) {
SpringApplication.run(BootDisributedIdApplication.class, args);
}
}测试
package com.wpc;
import com.baidu.fsg.uid.UidGenerator;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import javax.annotation.Resource;
@SpringBootTest
class BootDisributedIdApplicationTests {
@Resource(name="cachedUidGenerator")
private UidGenerator uidGenerator;
@Test
void contextLoads() {
System.out.println(uidGenerator.getUID());
}
}
可以从mysql表中看到成功的数据

为了测试生成id是否支持高并发,我们可以编写一个controller测试
package com.wpc.controller;
import com.baidu.fsg.uid.UidGenerator;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.ResponseBody;
import javax.annotation.Resource;
import java.util.HashSet;
import java.util.Set;
@Controller
@ResponseBody
@Slf4j
@RequestMapping("ID")
public class IDController {
@Resource(name="cachedUidGenerator")
private UidGenerator uidGenerator;
@GetMapping("uid")
public Object generatorId(){
Set set=new HashSet<>(100000);
log.info("开始--->");
for(int i=0;i<100000;i++){
set.add(uidGenerator.getUID());
}
log.info("----->结束---->"+set.size());
return set;
}
}

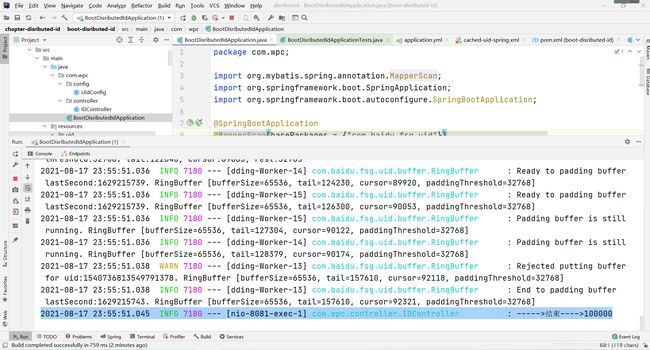
可以看出set中有100000条数据,也就是生成了100000条唯一的id
用其他浏览器再访问一次

![]()
可以看出其具有高并发,高性能,高可用的特性。
方案总结
实际业务中,除了分布式ID全局唯一之外,还有是否趋势/连续递增的要求。根据具体业务需求的不同,有两种可选方案。
一是只保证全局唯一,不保证连续递增。二是既保证全局唯一,又保证连续递增。