特征工程:机器学习中的特征与标签nlp化
机器学习中的特征与标签自然语言化
引子
这是一篇关于机器自然语言应用和特征工程结合的文章,目的在于探讨在企业或科研场景中,特征工程的另一种可能性——解决特征稀疏或数据和模型异构场景下一种通用的解决方案。一种大大降低模型开发及数仓建设人力成本,同时提高模型精度的解决方案。
在机器学习科研领域中,往往可以看到的是在规整及缺失率低特征的数据集下,固定的生产线解决一个特定的问题。
而工业和现实场景中,用户的信息往往是极度稀疏的:
1.企业的目标用户的静态特征可能是平均缺失率在90%以上,用户的行为也极度稀疏,行为日志(购买各种各样的商品、进行不同软件的安装卸载)的种类太多无法onehot导致维度爆炸;
2.预测目标复杂,无法用一个简单的loss function描述:推荐平台需要预测用户购买物品的可能性而广告平台需要预测用户B是否点击广告,用户画像团队需要刻画用户的各种画像属性。
企业的数据团队往往需要不断使用开发人力维护输入端不同的特征工程以及机器学习人力输出端不同的模型甚至不同的流水线训练。随着业务扩展,整个架构越来越臃肿,如人月神话中的场景一样,团队陷入焦油坑。
困境:传统模型的软肋
传统的模型如决策树和神经网络都不能直接解决问题,只有依赖于优秀的算法专家的特征工程才能躲避特征的维度灾难。这是因为从本质上来说模型是一个概率统计的解决方案,通过样本的输入,对特征尝试进行解析,从而使用固定的范式(决策树、神经网络的激活函数)及合适的权重拟合输出。
这里提出大部分模型的两个短板:
1.从输入端说,模型并不能进行推理层面的特征学习。
例如性别特征在onehot后使用0,1作为输入,此时特征已经丢失了性别的含义,仅仅可能通过样本的标签反馈进行学习,获得这个特征0和1与标签的相关性。也就是说没有足够的样本,即使非常简单明了的特征模型也无法理解。
2.从输出端说,模型也不能很好的理解目标,无论是回归还是分类模型,在模型内也仅仅是权重的分布。
比如一个模型在吃下一定样本后能非常好的预测一个人的性别和年龄,但这个模型对于另一个场景需要对用户的穿衣类型确毫无帮助(事实上这两个问题十分相关),除非再提供同样多的穿衣样本才能帮助模型解决第二个场景。
银弹:特征及目标自然语言化
对nlp领域有一定了解的朋友一定清楚,深度学习的nlp模型对于情感分析以及文章关键词抓取已经较为成熟。word2vec等技术也可以很好的解释了模型对于文本确实有一定的理解力。那么试想一下,我们为什么不抛弃这么多年的思维定式:模型一定需要二进制01表征特征和标签吗?为什么模型不可以像正常人类一样,阅读一段自然语言给出答案呢?
也就是特征和目标自然语言化:
liling 0,-1,-1,7 (-1代表缺失)
wangping 1,20,3,-1 ……
->
“李灵 性别男性 关注体育”
“王平 性别女性 年龄20岁 学历本科”
……
liling login,08:00
liling logout,12:00
wangping click,100,12:00 ……
->
“李灵 上午登录 中午登出”
“王平 中午点击推荐页”
……
可以看到学历等枚举特征是很难onthot或线性化处理的,行为日志也没有办法规整成统一的格式给模型。而自然语言化完全没有这个问题所有结构化数字信息都可以转义成自然语言。
方案的优与劣——算法部分
脑洞开完,轮廓调子定好,现在来抠细节。
优势:
1.更加理解特征。在现在的神经网络nlp解决方案中,翻译等领域还不成熟,也就是seq2seq并不能很好的吃透自然语言。所幸的是我们并不需要模型真的像人类一样流利的阅读能力,因为我们的特征可以整理成相对规范的自然语言。lstm比较适合文章整体的把握而cnn活attentiong更适合局部字段的截取,所以一个attention层或textcnn都可以很好的解决特征阅读的功能。更加微妙的是,由于自然语料大量存在,模型可以一定程度理解特征(如男性,女性等词语)。
2.稀疏特征问题完美解决。由于缺失值如上可以直接忽略,所有目标的描述都可以紧凑写入,完美解决稀疏问题。即使随着业务变更,不需要修改模型结构,仅仅需要将新的特征append到老的特征后即可,由于attention或cnn的特性,连顺序都可以忽略。
3.数仓建设困难大大降低,一个简易的消息管道+汇聚的方式即可解决问题(见后文架构部分)。再也没有巨大的横表。
4.训练目标更加弹性。既然输入特征可以自然语言化,预测目标同样可以是一段自然语言。
说到这里,我们可以大致把模型的结构画成如下:
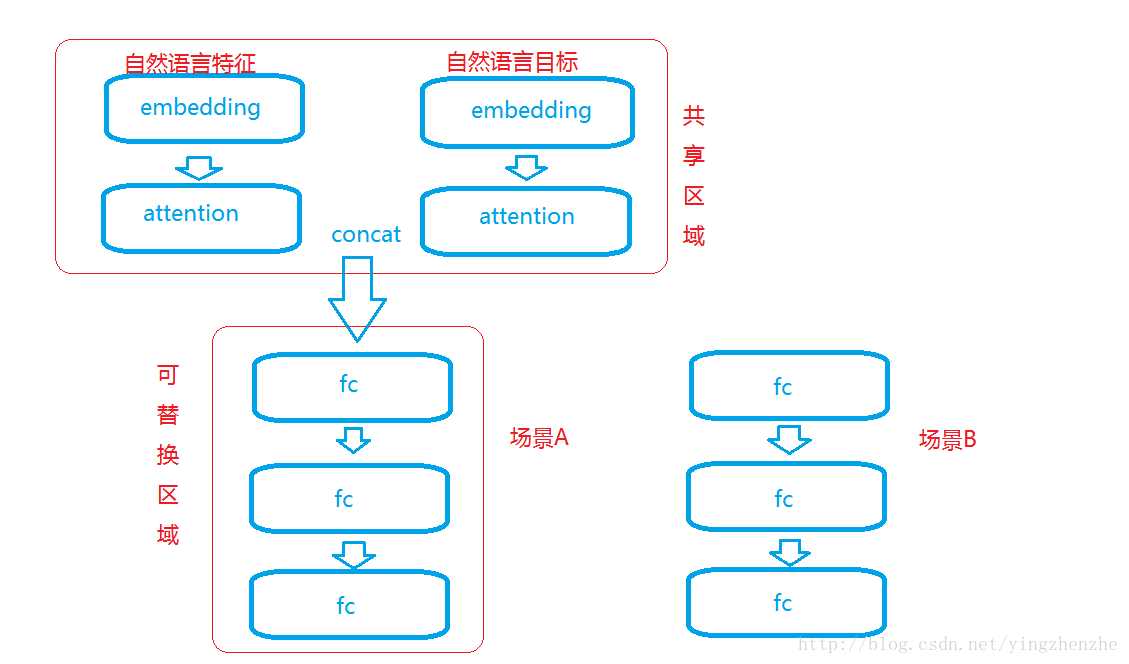
所有的自然语言embedding层共享权重,不同场景只要有一个良好的fine-tune方式加上每个场景若干个较少神经元的fc层(防止过拟合)。如:
场景目标1
特征:”王平 性别女性 年龄20岁 学历本科 昨天上午收藏了iphone7” 目标:”购买iphone7”
标签:0(购买)1(不买)
场景目标2
特征:”王平 性别女性 年龄20岁 学历本科 七天内购买了基金” 目标:”月收入”
标签:0~10000(线性结果)
这两个场景只要用样本finetune fc层即可,这让模型需要的样本大大减少。
这个优势有待商榷,作者还在不同的场景中尝试验证。
理论上说,随着场景增加,模型底层也会具有更加丰富的知识,维护多个场景多个模型反而更加轻松。
劣势:
1.训练模型的过程更加复杂,需要一个对深度学习模型有较多经验的工程师,在不同类型场景的样本中使用一个合理的方式训练embedding层及attention层。
2.虽然模型可能吸收更多的行为特征原始记录,但依然需要人力考虑精简特征,否则会给模型带来负担。团队中需要对业务有理解的分析人员在不同的场景可以筛选不同的特征放入模型。
方案的优与劣——数仓部分
这个部分给数仓建设或算法团队的架构师。
优势:
以往的数仓往往是如下:
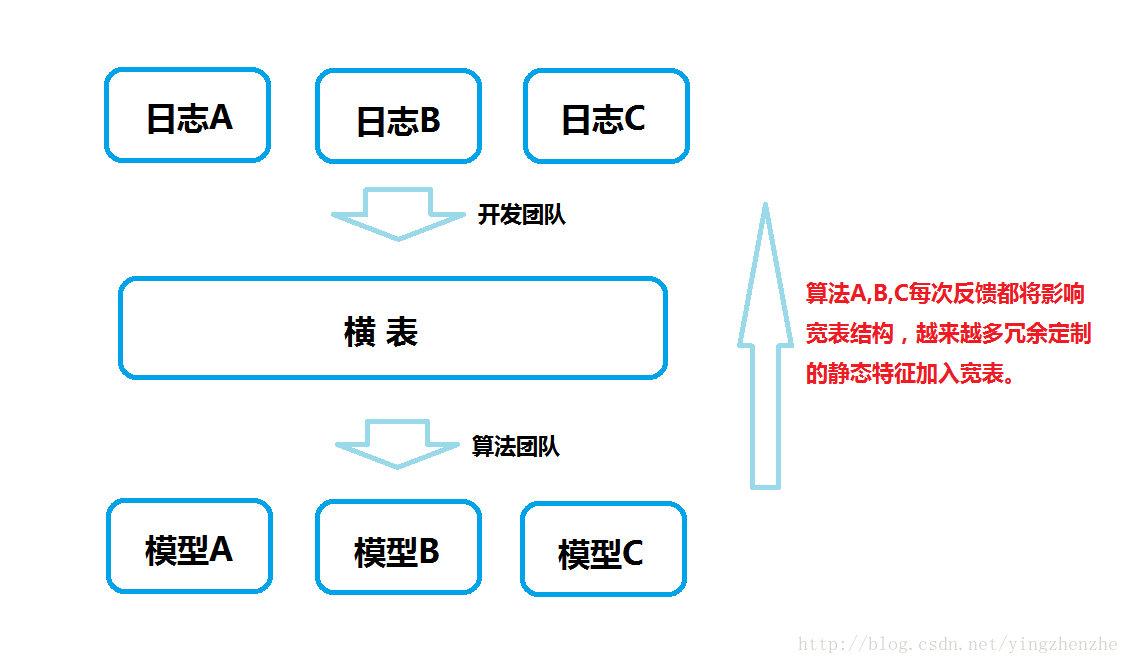
这个需要大量的算法人员各自维护各自的模型,同时当算法需要某些特征的时候,反馈给数仓开发人员,开发人员把静态特征集合到横表中。而行为特征没有办法快照的情况下,需要算法人员找寻一个合适的刻画方式将行为特征转化为静态特征(如登录详单无法喂给模型,需要刻画成一周登录频率等)。这个过程不仅丢失细节,同时生产线太长,如果刻画的特征不好用,又需要重新反馈给开发进行新的任务开发。同样的一波数仓开发人员很可能要应对多个场景的特征提取。
而在这个新的模型下,数仓架构只需要:
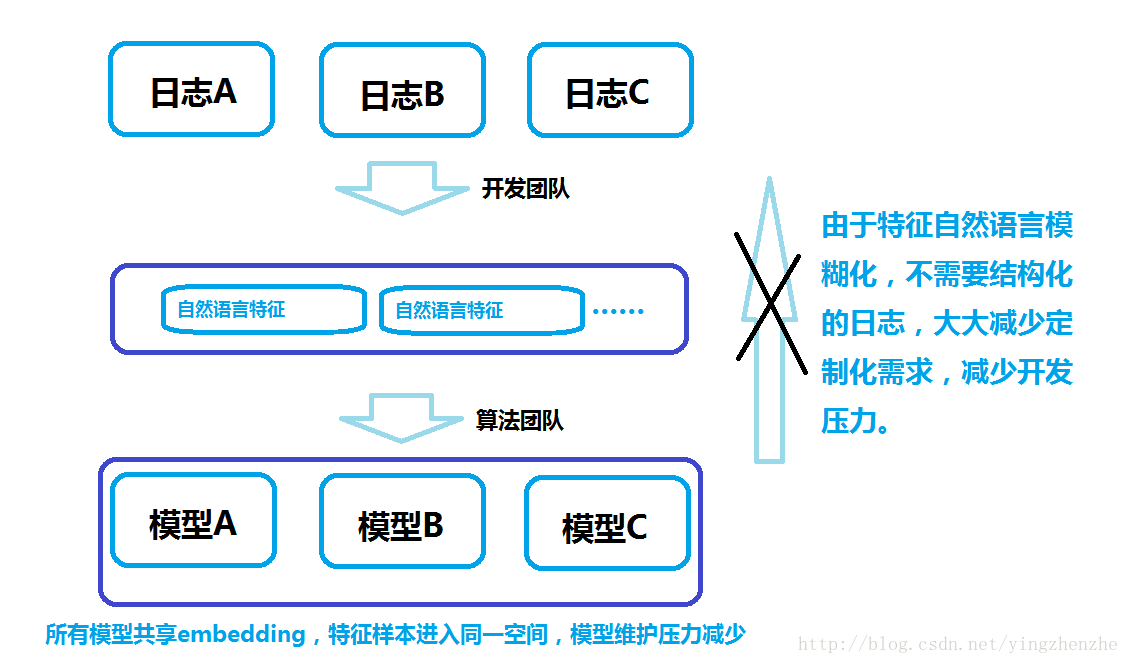
此时数仓的建设标准化,不需要再应对变化的需求,与算法几乎解耦。特征提取目标明确,不需要再在各个维度加工特征,仅需要清洗和自然语言化原始日志。
各个算法工程师可以非常随意地自取需要的特征union+groupby到一起即可。
劣势:
线上需要机器的资源由cpu密集型特征提取计算转向gpu密集进行训练预测。由于nlp的特征目前仅仅可以由神经网络使用,所以LR等模型不可用。gpu训练是一次性消耗,不需要频繁使用。
没有看到其他明显劣势。可能我工作经验较少,欢迎各位大牛拍砖。
写在最后
暂不提供代码的原因是作者在业界并没有看到相关的文章或模型,亦没有这样混乱的异构数据集让我测试,所以我在寻找各式场景尝试及更新理论,如果能找到一个非常合适的模型及数据会将样例代码分享出来。目前我搜集到的数据进行测试的结果里,在十万级别用户处理单一分类问题场景时,百万样本下,自然语言风格的模型已经超越了普通特征模型(决策树及传统神经网络),且随着特征和行为的复杂化、样本的增多,自然语言模型效果越来越好。
如果大家有意见或建议,以及合适的公开数据集可以测试这个算法,欢迎联系我[email protected]。把这个思路分享出来也欢迎有兴趣的各位自行进行尝试交流,个人来看这个脑洞还是很有趣的。
最后。未经授权,严禁转载。