原创:Sijie Guo
翻译:翟佳
之前的文章,我们描述了 Apache Pulsar 能够成为企业级流和消息系统的原因。Pulsar 的企业特性包括消息的持久化存储,多租户,多机房互联互备,加密和安全性等。我们经常被问到的一个问题是 Apache Pulsar 和 Apache Kafka 有什么不同。
在本系列的Pulsar和Kafka比较文章中,我们将引导您认识和了解消息系统中一些重要关注点,比如健壮性,高可用性和高带宽低延迟等。
在用户选择一个消息系统时,消息模型是用户首先考虑的事情。消息模型应涵盖以下3个方面:
- 消息消费 - 如何发送和消费消息;
- 消息确认(ack) - 如何确认消息;
- 消息保存 - 消息保留多长时间,触发消息删除的原因以及怎样删除;
消息消费模型
在实时流式架构中,消息传递可以分为两类:队列(Queue)和流(Stream)。
队列(Queue)模型
队列模型主要是采用无序或者共享的方式来消费消息。通过队列模型,用户可以创建多个消费者从单个管道中接收消息;当一条消息从队列发送出来后,多个消费者中的只有一个(任何一个都有可能)接收和消费这条消息。消息系统的具体实现决定了最终哪个消费者实际接收到消息。
队列模型通常与无状态应用程序一起结合使用。无状态应用程序不关心排序,但它们确实需要能够确认(ack)或删除单条消息,以及尽可能地扩展消费并行性的能力。典型的基于队列模型的消息系统包括 RabbitMQ 和 RocketMQ。
流式(Stream)模型
相比之下,流模型要求消息的消费严格排序或独占消息消费。对于一个管道,使用流式模型,始终只会有一个消费者使用和消费消息。消费者按照消息写入管道的确切顺序接收从管道发送的消息。
流模型通常与有状态应用程序相关联。有状态的应用程序更加关注消息的顺序及其状态。消息的消费顺序决定了有状态应用程序的状态。消息的顺序将影响应用程序处理逻辑的正确性。
在面向微服务或事件驱动的体系结构中,队列模型和流模型都是必需的。
Pulsar 的消息消费模型
Apache Pulsar 通过“订阅”,抽象出了统一的: producer-topic-subscription-consumer 消费模型。Pulsar 的消息模型既支持队列模型,也支持流模型。
在 Pulsar 的消息消费模型中,Topic 是用于发送消息的通道。每一个 Topic 对应着 Apache BookKeeper 中的一个分布式日志。发布者发布的每条消息只在Topic中存储一次;存储的过程中,BookKeeper 会将消息复制存储在多个存储节点上;Topic 中的每条消息,可以根据消费者的订阅需求,多次被使用,每个订阅对应一个消费者组(Consumer Group)。
主题(Topic)是消费消息的真实来源。尽管消息仅在主题(Topic)上存储一次,但是用户可以有不同的订阅方式来消费这些消息:
- 消费者被组合在一起以消费消息,每个消费组是一个订阅。
- 每个 Topic 可以有不同的消费组。
- 每组消费者都是对主题的一个订阅。
- 每组消费者可以拥有自己不同的消费方式: 独占(Exclusive),故障切换(Failover)或共享(Share)。
Pulsar通过这种模型,将队列模型和流模型这两种模型结合在了一起,提供了统一的API接口。 这种模型,既不会影响消息系统的性能,也不会带来额外的开销,同时还为用户提供了更多灵活性,方便用户程序以最匹配模式来使用消息系统。
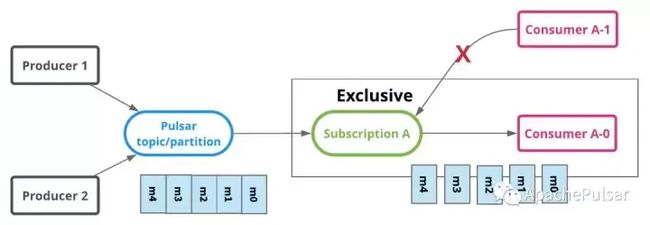
独占订阅(Stream流模型)
顾名思义,独占订阅中,在任何时间,一个消费者组(订阅)中有且只有一个消费者来消费 Topic 中的消息。下图是独占订阅的示例。在这个示例中有一个有订阅A的活跃消费者A-0,消息 m0 到 m4 按顺序传送并由 A-0 消费。如果另一个消费者 A-1 想要附加到订阅A,则是不被允许的。
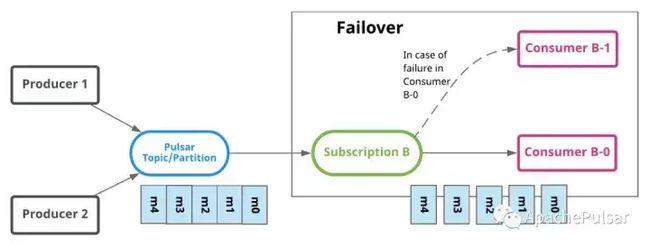
故障切换(Stream流模型)
使用故障切换订阅,多个消费者(Consumer)可以附加到同一订阅。 但是,一个订阅中的所有消费者,只会有一个消费者被选为该订阅的主消费者。 其他消费者将被指定为故障转移消费者。
当主消费者断开连接时,分区将被重新分配给其中一个故障转移消费者,而新分配的消费者将成为新的主消费者。 发生这种情况时,所有未确认(ack)的消息都将传递给新的主消费者。 这类似于 Apache Kafka 中的 Consumer partition rebalance。
下图是故障切换订阅的示例。 消费者 B-0 和 B-1 通过订阅 B 订阅消费消息。B-0 是主消费者并接收所有消息。 B-1 是故障转移消费者,如果消费者 B-0 出现故障,它将接管消费。
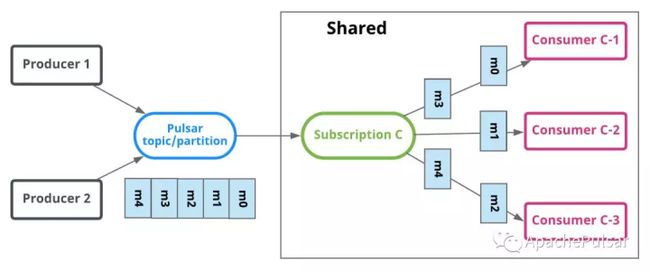
共享订阅(Queue队列模型)
使用共享订阅,在同一个订阅背后,用户按照应用的需求挂载任意多的消费者。 订阅中的所有消息以循环分发形式发送给订阅背后的多个消费者,并且一个消息仅传递给一个消费者。
当消费者断开连接时,所有传递给它但是未被确认(ack)的消息将被重新分配和组织,以便发送给该订阅上剩余的剩余消费者。
下图是共享订阅的示例。 消费者 C-1,C-2 和 C-3 都在同一主题上消费消息。 每个消费者接收大约所有消息的 1/3。
如果想提高消费的速度,用户不需要不增加分区数量,只需要在同一个订阅中添加更多的消费者。
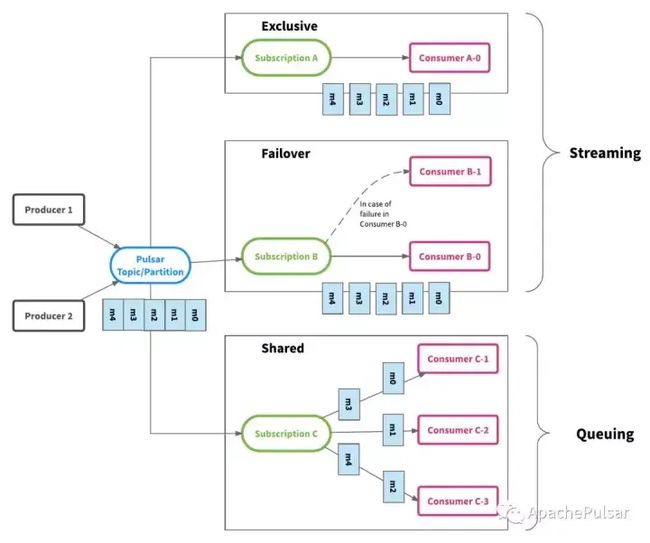
三种订阅模式的选择
独占和故障切换订阅,仅允许一个消费者来使用和消费,每个对主题的订阅。这两种模式都按主题分区顺序使用消息。它们最适用于需要严格消息顺序的流(Stream)用例。
共享订阅允许每个主题分区有多个消费者。同一订阅中的每个消费者仅接收主题分区的一部分消息。共享订阅最适用于不需要保证消息顺序的队列(Queue)的使用模式,并且可以按照需要任意扩展消费者的数量。
Pulsar 中的订阅实际上与 Apache Kafka 中的 Consumer Group 的概念类似。创建订阅的操作很轻量化,而且具有高度可扩展性,用户可以根据应用的需要创建任意数量的订阅。对同一主题的不同订阅,也可以采用不同的订阅类型。比如用户可以在同一主题上可以提供一个包含3个消费者的故障切换订阅,同时也提供一个包含20个消费者的共享订阅,并且可以在不改变分区数量的情况下,向共享订阅添加更多的消费者。下图描绘了一个包含3个订阅 A,B 和 C 的主题,并说明了消息如何从生产者流向消费者。
除了统一消息API之外,由于Pulsar主题分区实际上是存储在 Apache BookKeeper 中,它还提供了一个读取 API(Reader),类似于消费者API(但 Reader 没有游标管理),以便用户完全控制如何使用 Topic 中的消息。
Pulsar的消息确认(ACK)
由于分布式系统的特性,当使用分布式消息系统时,可能会发生故障。比如在消费者从消息系统中的主题消费消息的过程中,消费消息的消费者和服务于主题分区的消息代理(Broker)都可能发生错误。消息确认(ACK)的目的就是保证当发生这样的故障后,消费者能够从上一次停止的地方恢复消费,保证既不会丢失消息,也不会重复处理已经确认(ACK)的消息。在 Apache Kafka 中,恢复点通常称为 Offset,更新恢复点的过程称为消息确认或提交 Offset。
在 Apache Pulsar 中,每个订阅中都使用一个专门的数据结构--游标(Cursor)来跟踪订阅中的每条消息的确认(ACK)状态。每当消费者在主题分区上确认消息时,游标都会更新。更新游标可确保消费者不会再次收到消息。
Apache Pulsar 提供两种消息确认方法,单条确认(Individual Ack)和累积确认(Cumulative Ack)。通过累积确认,消费者只需要确认它收到的最后一条消息。主题分区中的所有消息(包括)提供消息ID将被标记为已确认,并且不会再次传递给消费者。累积确认与 Apache Kafka 中的 Offset 更新类似。
Apache Pulsar可以支持消息的单条确认,也就是选择性确认。消费者可以单独确认一条消息。 被确认后的消息将不会被重新传递。下图说明了单条确认和累积确认的差异(灰色框中的消息被确认并且不会被重新传递)。在图的上半部分,它显示了累计确认的一个例子,M12 之前的消息被标记为acked。在图的下半部分,它显示了单独进行 acking 的示例。仅确认消息 M7 和 M12 - 在消费者失败的情况下,除了 M7 和 M12 之外,其他所有消息将被重新传送。
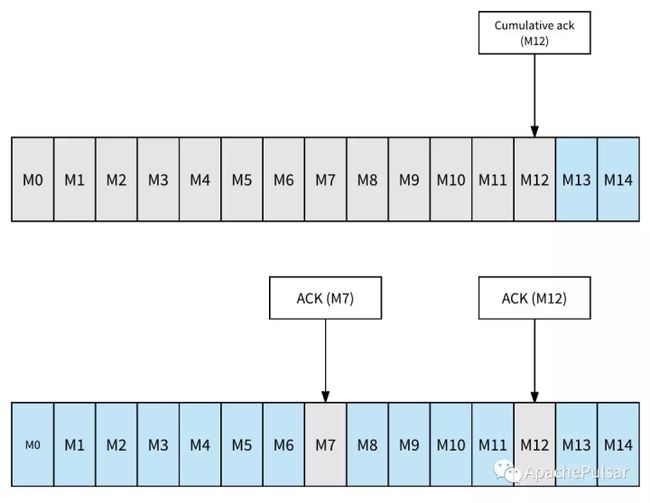
独占订阅或故障切换订阅的消费者能够对消息进行单条确认和累积确认;共享订阅的消费者只允许对消息进行单条确认。单条确认消息的能力为处理消费者故障提供了更好的体验。对于某些应用来说,处理一条消息可能需要很长时间或者非常昂贵,防止重新传送已经确认的消息非常重要。
这个管理Ack的专门的数据结构--游标(Cursor),由 Broker 来管理,利用 BookKeeper 的 Ledger 提供存储,在后面的文章中我们会介绍更多的关于游标(Cursor)的细节。
Apache Pulsar 提供了灵活的消息消费订阅类型和消息确认方法,通过简单的统一的 API,就可以支持各种消息和流的使用场景。
Pulsar的消息保留(Retention)
在消息被确认后,Pulsar的Broker 会更新对应的游标。当 Topic 里面中的一条消息,被所有的订阅都确认 ack 后,才能删除这条消息。Pulsar还允许通过设置保留时间,将消息保留更长时间,即使所有订阅已经确认消费了它们。下图说明了如何在有2个订阅的主题中保留消息。订阅 A 在 M6 和订阅 B 已经消耗了 M10 之前的所有消息之前已经消耗了所有消息。这意味着M6之前的所有消息(灰色框中)都可以安全删除。订阅A仍未使用 M6 和 M9 之间的消息,无法删除它们。如果主题配置了消息保留期,则消息M0到M5将在配置的时间段内保持不变,即使 A 和 B 已经确认消费了它们。
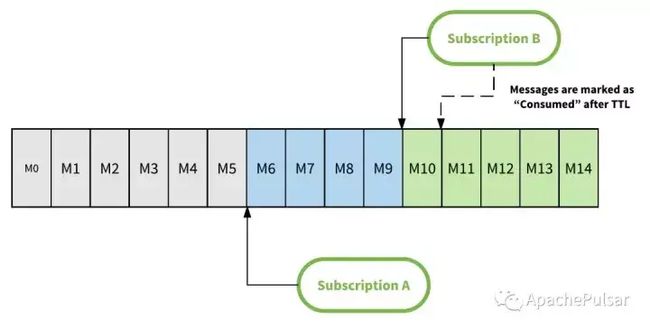
在消息保留策略中,Pulsar 还支持消息生存时间(TTL)。如果消息未在配置的TTL时间段内被任何消费者使用,则消息将自动标记为已确认。 消息保留期消息 TTL 之间的区别在于:消息保留期作用于标记为已确认并设置为已删除的消息,而 TTL 作用于未 ack 的消息。 上面的图例中说明了 Pulsar 中的TTL。 例如,如果订阅 B 没有活动消费者,则在配置的 TTL 时间段过后,消息 M10 将自动标记为已确认,即使没有消费者实际读取该消息。
Pulsar VS. Kafka
通过以上几个方面,我们对 Pulsar 和Kafka在消息模型方面的不同点进行一个总结。
模型概念
Kafka: Producer - topic - consumer group - consumer;
Pulsar:Producer - topic - subscription - consumer。
消费模式
Kafka: 主要集中在流(Stream)模式,对单个 partition 是独占消费,没有共享(Queue)的消费模式;
Pulsar:提供了统一的消息模型和API。流(Stream)模式 -- 独占和故障切换订阅方式;队列(Queue)模式 -- 共享订阅的方式。
消息确认(Ack)
Kafka: 使用偏移 Offset;
Pulsar:使用专门的 Cursor 管理。累积确认和 Kafka 效果一样;提供单条或选择性确认。
消息保留
Kafka:根据设置的保留期来删除消息。有可能消息没被消费,过期后被删除。 不支持 TTL。
Pulsar:消息只有被所有订阅消费后才会删除,不会丢失数据。也允许设置保留期,保留被消费的数据。支持 TTL。
对比总结:
Apache Pulsar 将高性能的流(Apache Kafka所追求的)和灵活的传统队列(RabbitMQ 所追求的)结合到一个统一的消息模型和 API 中。 Pulsar 使用统一的 API 为用户提供一个支持流和队列的系统,且具有同样的高性能。
总结
在这篇博客文章中,我们介绍了 Apache Pulsar 的消息模型,该模型将队列和流式传输统一到一个 API 中。应用程序可以将此统一的 API 用于高性能队列和流式传输,而无需维护两套系统:RabbitMQ 进行队列处理,Kafka 进行流式处理。希望这篇文章能让您了解 Apache Pulsar 中的消息模型,消息消费,删除和保留是如何工作的;了解 Pulsar 和Kafka消息模型之间的区别。在后面一篇文章中,我们将向您介绍 Apache Pulsar 的架构细节以及 Pulsar 与 Apache Kafka 在数据分发,复制,可用性和持久性方面的差异。
如果对Pulsar感兴趣,可通过下列方式参与 Pulsar 社区:
Pulsar Slack 频道:https://apache-pulsar.slack.com/
可自行在这里注册:https://apache-pulsar.herokua...
- Pulsar 邮件列表: http://pulsar.incubator.apach...
有关 Apache Pulsar 项目的常规信息,请访问官网:http://pulsar.incubator.apach...此外也可关注 Twitter 帐号@apache_pulsar。