Pandas学习总结
Pandas
基本数据结构

创建序列
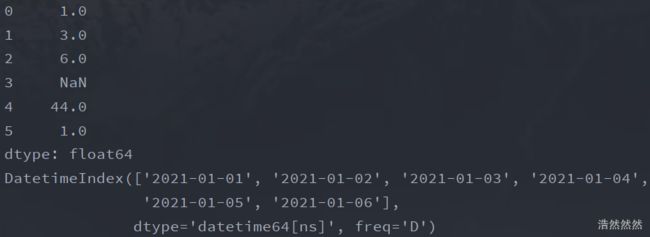
s=pd.Series([1,3,6,np.nan,44,1])#创建pandas的序列
print(s)
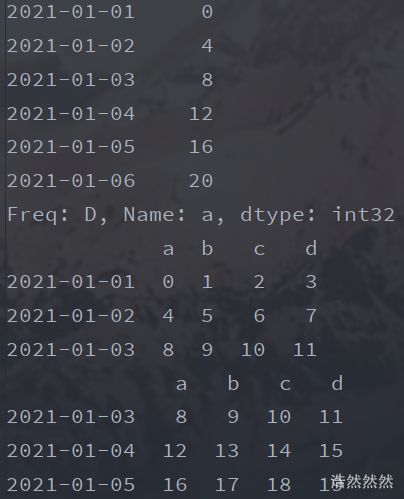
dates=pd.date_range('20210101',periods=6)#日期的序列
print(dates)
运行结果:
创建DataFrame
在所有操作之前当然要先import必要的pandas库,因为pandas常与numpy一起配合使用,所以也一起import吧。
import pandas as pd
import numpy as np
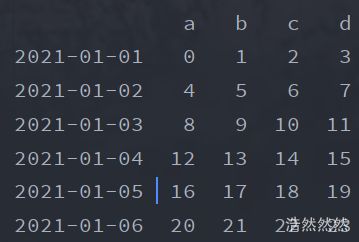
- 可以直接使用pandas的DataFrame函数创建,比如接下来我们随机创建一个6*4的DataFrame。
df=pd.DataFrame(np.arange(24).reshape(6,4),index=dates,columns=['a','b','c','d'])#产生二维表
print(df)
运行结果:
- 也可以用字典创建。
dic1={
'name':['小明','小红','狗蛋','铁柱'],'age':[17,20,5,40],'gender':['男','女','女','男']}
df3=pd.DataFrame(dic1)
print(df3)
运行结果:

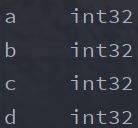
- 查看数据类型
print(df.dtypes)
运行结果:
- 查看行、列标签
print(df.index)#行标签
print(df.columns)#列标签
运行结果:

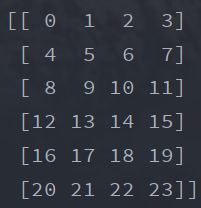
- 查看二维表的数据值,返回数组
print(df.values)
运行结果:
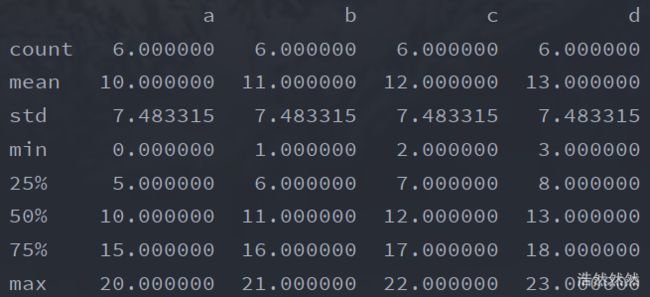
- 对数据根据列进行描述性统计
print(df.describe())
运行结果:
- 将行列互换(转置)
print(df.transpose())
print(df.T)#这样也可以
运行结果:

- 排序
print(df.sort_index(axis=0,ascending=False))#按列倒叙
print(df.sort_index(axis=1,ascending=False))#按行倒叙
print(df.sort_values(by='c'))#axis=0,,ascending=True,按第c列升序
运行结果:
| a | b | c | d | |
|---|---|---|---|---|
| 2021-01-06 | 20 | 21 | 22 | 23 |
| 2021-01-05 | 16 | 17 | 18 | 19 |
| 2021-01-04 | 12 | 13 | 14 | 15 |
| 2021-01-03 | 8 | 9 | 10 | 11 |
| 2021-01-02 | 4 | 5 | 6 | 7 |
| 2021-01-01 | 0 | 1 | 2 | 3 |
| d | c | b | a | |
|---|---|---|---|---|
| 2021-01-01 | 3 | 2 | 1 | 0 |
| 2021-01-02 | 7 | 6 | 5 | 4 |
| 2021-01-03 | 11 | 10 | 9 | 8 |
| 2021-01-04 | 15 | 14 | 13 | 12 |
| 2021-01-05 | 19 | 18 | 17 | 16 |
| 2021-01-06 | 23 | 22 | 21 | 20 |
| a | b | c | d | |
|---|---|---|---|---|
| 2021-01-01 | 0 | 1 | 2 | 3 |
| 2021-01-02 | 4 | 5 | 6 | 7 |
| 2021-01-03 | 8 | 9 | 10 | 11 |
| 2021-01-04 | 12 | 13 | 14 | 15 |
| 2021-01-05 | 16 | 17 | 18 | 19 |
| 2021-01-06 | 20 | 21 | 22 | 23 |
筛选、修改数据
- 可以按列,按行选取
print(df['a'])#或者print(df.a)
print(df[0:3])#选取第0行到第2行
print(df['20210103':'20210105'])
运行结果:
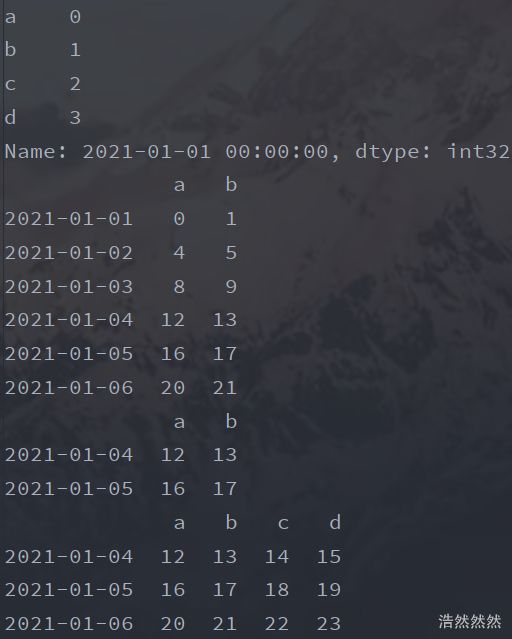
- 使用loc或者iloc查看数据值,区别是loc是根据标签(行名),iloc是根据数字索引(也就是行号)。
print(df.loc['20210101'])
print(df.loc[:,['a','b']])#筛选a,b两列
print(df.iloc[3:5,0:2])#找第4行到第5行,第1列到第2列
print(df[df['a']>8])#选取第a列大于8的行
运行结果:
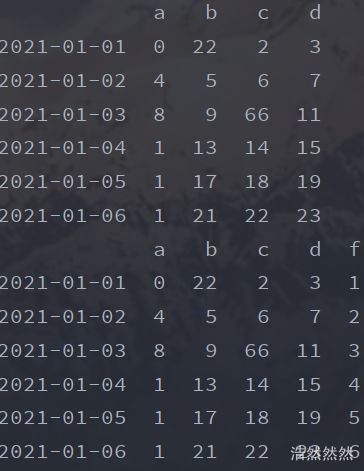
- 修改操作
df.iloc[2,2]=66
df.loc['20210101','b']=22
df['a'][df['a']>8]=1#或者df.a[df.a>8]=1
print(df)
df['f']=pd.Series([1,2,3,4,5,6], index=df.index)
print(df)
运行结果:
- 对数据处理时,需要判空,然后进行去除或者填充,代码如下:

文件的读取保存
- Pandas常用的有以下三种文件:
- csv文件
- txt文件
- xls/xlsx文件
- 读取文件时的注意事项:
- 文件路径是否正确,相对路径 ./
- 编码方式
- 分隔符
- 列名
#读取csv文件
df = pd.read_csv('student.csv')
#读取txt文件,直接读取可能会出现数据都挤在一列上
df_txt = pd.read_table('student.txt')
#读取xls/xlsx文件
df_excel = pd.read_excel('student.xlsx')
df.to_pickle('student.pickle')#保存文件
数据合并
- pd.concat() 函数可以沿着指定的轴将多个 DataFrame 或者 Series 拼接到一起。
df11=pd.DataFrame(np.ones((3,4))*0,columns=['a','b','c','d'])
df22=pd.DataFrame(np.ones((3,4))*1,columns=['a','b','c','d'])
df33=pd.DataFrame(np.ones((3,4))*2,columns=['a','b','c','d'])
res=pd.concat([df11,df22,df33],axis=0,ignore_index=True)#ignore_index可以忽略标签
print(res)#合并矩阵
运行结果:

- pd.merge() 函数只能实现两个表的拼接。
df1=pd.DataFrame(np.ones((3,4))*0,columns=['a','b','c','d'],index=[1,2,3])
df2=pd.DataFrame(np.ones((3,4))*1,columns=['b','c','d','e'],index=[2,3,4])
res1=pd.concat([df1,df2],join='inner',ignore_index=True)
print(res1)#交集
res2=pd.concat([df1,df2],join='outer',ignore_index=True,sort=True)#这里sort要改为True
print(res2)#并集
运行结果:

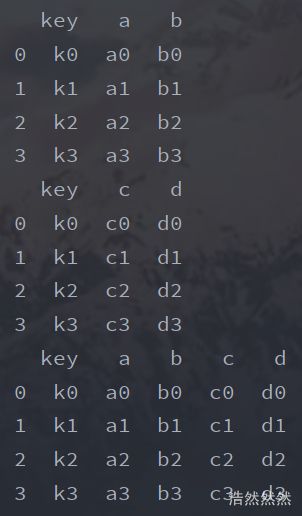
left=pd.DataFrame({
'key':['k0','k1','k2','k3'],
'a':['a0','a1','a2','a3'],
'b':['b0','b1','b2','b3']})
right=pd.DataFrame({
'key':['k0','k1','k2','k3'],
'c':['c0','c1','c2','c3'],
'd':['d0','d1','d2','d3']})
print(left)
print(right)
reslr=pd.merge(left,right,on='key')
print(reslr)
运行结果:
Pandas plot 画图
首先要import matplotlib.pyplot as plt
- 绘制图
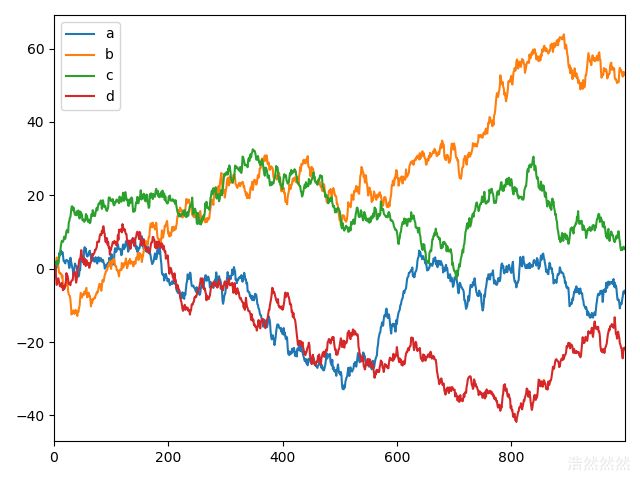
datad=pd.DataFrame(np.random.randn(1000,4),index=np.arange(1000),columns=['a','b','c','d'])
datad=datad.cumsum()
print(datad.head())#默认5行
datad.plot()
plt.show()
运行结果:
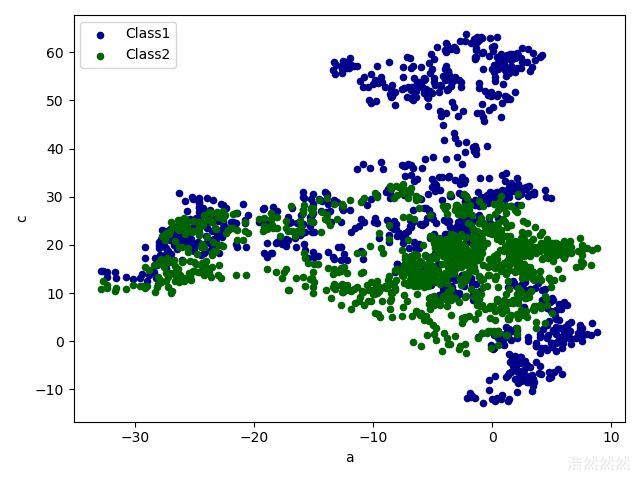
- 绘制散点图
ax=datad.plot.scatter(x='a',y='b',color='DarkBlue',label='Class1')
datad.plot.scatter(x='a',y='c',color='DarkGreen',label='Class2',ax=ax)
plt.show()
运行结果:
其他文章:
Numpy学习总结
Matplotlib学习总结