Python爬虫:抓取智联招聘岗位信息和要求(进阶版)
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理
以下文章来源于腾讯云 作者:王强
( 想要学习Python?Python学习交流群:1039649593,满足你的需求,资料都已经上传群文件流,可以自行下载!还有海量最新2020python学习资料。 )

前言:
上一篇文章中我们已经抓取了智联招聘一些信息,但是那些对于找工作来说还是不够的,今天我们继续深入的抓取智联招聘信息并分析,本文使用到的第三方库很多,涉及到的内容也很繁杂,请耐心阅读。
运行平台: Windows
Python版本: Python3.6
IDE: Sublime Text
其他工具: Chrome浏览器
本文是基于基础版上做的修改,如果没有阅读基础版,请移步 Python爬虫:抓取智联招聘岗位信息和要求(基础版)
在基础版中,构造url时使用了urllib库的urlencode函数:
url = 'https://sou.zhaopin.com/jobs/searchresult.ashx?' + urlencode(paras)
try:
# 获取网页内容,返回html数据
response = requests.get(url, headers=headers)
...
其实用reuqests库可以完成此工作,本例将该部分改为:
url = 'https://sou.zhaopin.com/jobs/searchresult.ashx?'
try:
# 获取网页内容,返回html数据
response = requests.get(url, params=paras, headers=headers)
...
1、找到职位链接
为了得到更加详细的职位信息,我们要找到职位链接,在新的页面中寻找数据。上篇文章中我们没有解析职位链接,那再来找一下吧:
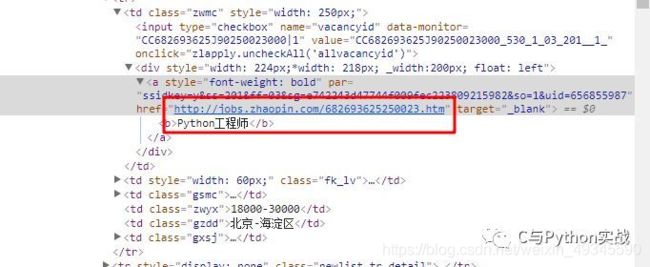
修改一下正则表达式:
# 正则表达式进行解析
pattern = re.compile('(.*?).*?' # 匹配职位详情地址和职位名称
' .*? target="_blank">(.*?).*?' # 匹配公司名称
' (.*?) ', re.S) # 匹配月薪
# 匹配所有符合条件的内容
items = re.findall(pattern, html)
2、求工资平均值
工资有两种形式xxxx-yyyy或者面议,此处取第一种形式的平均值作为分析标准,虽有偏差但是也差不多,这是求职中最重要的一项指标。
for item in items:
salary_avarage = 0
temp = item[3]
if temp != '面议':
idx = temp.find('-')
# 求平均工资
salary_avarage = (int(temp[0:idx]) + int(temp[idx+1:]))//2
3、解析职位详细信息
3.1 网页解析
第一步已经将职位地址找到,在浏览器打开之后我们要找到如下几项数据:
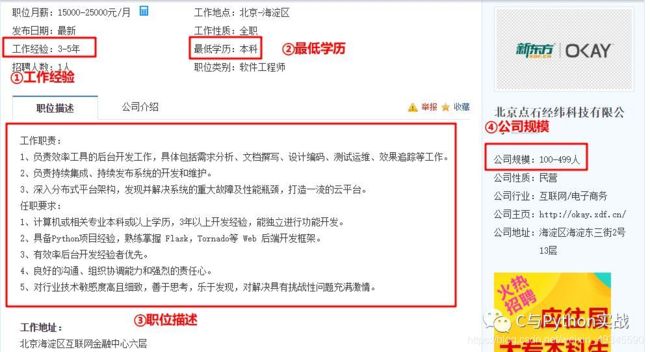
在开发者工具中查找这几项数据,如下图所示:
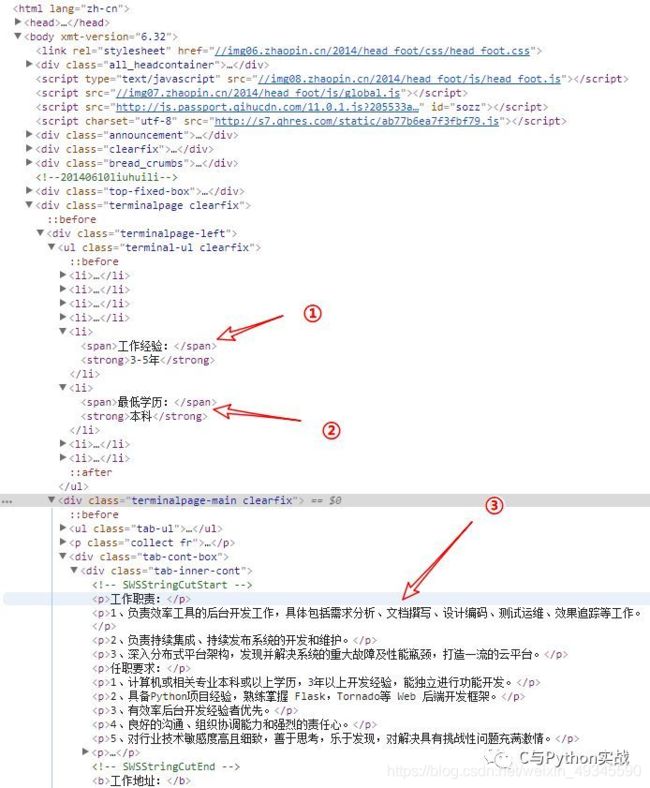
HTML结构如下所示:
# 数据HTML结构
<body>
|------<div class="terminalpage clearfix">
==>|------<div class="terminalpage-left">
==>==>|------<ul class="terminal-ul clearfix">
==>==>==>|------<li><span>工作经验:</span><strong>3-5年</strong>
==>==>==>|------<li><span>最低学历:</span><strong>本科</strong>
==>==>|------<div class="terminalpage-main clearfix">
==>==>==>|------<div class="tab-cont-box">
==>==>==>==>|------<div class="tab-inner-cont">
==>==>==>==>==>|------<p>工作职责:</p>
==>==>==>==>==>|------<p>********</p>
==>==>==>==>==>|------<p>********</p> # 工作职责详情
==>|------<div class="terminalpage-right">
==>==>|------<div class="company-box">
==>==>==>|------<ul class="terminal-ul clearfix terminal-company mt20">
==>==>==>==>|------<li><span>公司规模:</span><strong>100-499人</strong>
3.2 代码实现
为了学习一下BeautifulSoup库的使用,我们不再使用正则表达式解析,而是BeautifulSoup库解析HTML标签来获得我们想要得到的内容。
解析库的安装:pip install beautifulsoup4
下面介绍一下本例中使用到的功能:
- 库的引入:from bs4 import BeautifulSoup
- 数据引入:soup = BeautifulSoup(html, ‘html.parser’) ,其中html是我们要解析的html源码,html.parser指定HTML的解析器为Python标准库。
- 查找标签:find(name,attrs,recursive,text,**kwargs),find返回的匹配结果的第一个元素
- 查找所有标签:find_all(name,attrs,recursive,text,**kwargs)可以根据标签名,属性,内容查找文档,返回找到的所有元素。
- 获取内容:get_text()就可以获取文本内容
- 获取子标签:soup.p这种方式就可以获取到soup下的第一个p标签
def get_job_detail(html):
requirement = ''
# 使用BeautifulSoup进行数据筛选
soup = BeautifulSoup(html, 'html.parser')
# 找到标签
for ul in soup.find_all('ul', class_='terminal-ul clearfix'):
# 该标签共有8个子标签,分别为:
# 职位月薪|工作地点|发布日期|工作性质|工作经验|最低学历|招聘人数|职位类别
lis = ul.find_all('strong')
# 工作经验
years = lis[4].get_text()
# 最低学历
education = lis[5].get_text()
# 筛选任职要求
for terminalpage in soup.find_all('div', class_='terminalpage-main clearfix'):
for box in terminalpage.find_all('div', class_='tab-cont-box'):
cont = box.find_all('div', class_='tab-inner-cont')[0]
ps = cont.find_all('p')
# "立即申请"按钮也是个p标签,将其排除
for i in range(len(ps) - 1):
requirement += ps[i].get_text().replace("\n", "").strip() # 去掉换行符和空格
# 筛选公司规模,该标签内有四个或五个标签,但是第一个就是公司规模
scale = soup.find(class_='terminal-ul clearfix terminal-company mt20').find_all('li')[0].strong.get_text()
return {
'years': years, 'education': education, 'requirement': requirement, 'scale': scale}
本次我们将职位描述写入txt文件,其余信息写入csv文件。
csv文件采用逐行写入的方式这样也可以省点内存,修改write_csv_rows函数:
def write_csv_rows(path, headers, rows):
'''
写入行
'''
with open(path, 'a', encoding='gb18030', newline='') as f:
f_csv = csv.DictWriter(f, headers)
# 如果写入数据为字典,则写入一行,否则写入多行
if type(rows) == type({
}):
f_csv.writerow(rows)
else:
f_csv.writerows(rows)
添加写txt文件函数:
def write_txt_file(path, txt):
'''
写入txt文本
'''
with open(path, 'a', encoding='gb18030', newline='') as f:
f.write(txt)
我们最重要对职位描述的内容进行词频统计,一些标点符号等会影响统计,使用正则表达式将其剔除:
# 对数据进行清洗,将标点符号等对词频统计造成影响的因素剔除
pattern = re.compile(r'[一-龥]+')
filterdata = re.findall(pattern, job_detail.get('requirement'))
write_txt_file(txt_filename, ''.join(filterdata))
至此,职位详细信息的获取及保存的工作已经完成,来看一下此时的main函数:
def main(city, keyword, region, pages):
'''
主函数
'''
csv_filename = 'zl_' + city + '_' + keyword + '.csv'
txt_filename = 'zl_' + city + '_' + keyword + '.txt'
headers = ['job', 'years', 'education', 'salary', 'company', 'scale', 'job_url']
write_csv_headers(csv_filename, headers)
for i in range(pages):
'''
获取该页中所有职位信息,写入csv文件
'''
job_dict = {
}
html = get_one_page(city, keyword, region, i)
items = parse_one_page(html)
for item in items:
html = get_detail_page(item.get('job_url'))
job_detail = get_job_detail(html)
job_dict['job'] = item.get('job')
job_dict['years'] = job_detail.get('years')
job_dict['education'] = job_detail.get('education')
job_dict['salary'] = item.get('salary')
job_dict['company'] = item.get('company')
job_dict['scale'] = job_detail.get('scale')
job_dict['job_url'] = item.get('job_url')
# 对数据进行清洗,将标点符号等对词频统计造成影响的因素剔除
pattern = re.compile(r'[一-龥]+')
filterdata = re.findall(pattern, job_detail.get('requirement'))
write_txt_file(txt_filename, ''.join(filterdata))
write_csv_rows(csv_filename, headers, job_dict)
4、数据分析
本节内容为此版本的重点。
4.1 工资统计
我们对各个阶段工资的占比进行统计,分析该行业的薪资分布水平。前面我们已经把数据保存到csv文件里了,接下来要读取salary列:
def read_csv_column(path, column):
'''
读取一列
'''
with open(path, 'r', encoding='gb18030', newline='') as f:
reader = csv.reader(f)
return [row[column] for row in reader]
# main函数里添加
print(read_csv_column(csv_filename, 3))
#下面为打印结果
['salary', '7000', '5000', '25000', '12500', '25000', '20000', '32500', '20000', '15000', '9000', '5000', '5000', '12500', '24000', '15000', '18000', '25000', '20000', '0', '20000', '12500', '17500', '17500', '20000', '11500', '25000', '12500', '17500', '25000', '22500', '22500', '25000', '17500', '7000', '25000', '3000', '22500', '15000', '25000', '20000', '22500', '15000', '15000', '25000', '17500', '22500', '10500', '20000', '17500', '22500', '17500', '25000', '20000', '11500', '11250', '12500', '14000', '12500', '17500', '15000']
从结果可以看出,除了第一项,其他的都为平均工资,但是此时的工资为字符串,为了方便统计,我们将其转换成整形:
salaries = []
sal = read_csv_column(csv_filename, 3)
# 撇除第一项,并转换成整形,生成新的列表
for i in range(len(sal) - 1):
# 工资为'0'的表示招聘上写的是'面议',不做统计
if not sal[i] == '0':
salaries.append(int(sal[i + 1]))
print(salaries)
# 下面为打印结果
[7000, 5000, 25000, 12500, 25000, 20000, 32500, 20000, 15000, 9000, 5000, 5000, 12500, 24000, 15000, 18000, 25000, 20000, 0, 20000, 12500, 20000, 11500, 17500, 25000, 12500, 17500, 25000, 25000, 22500, 22500, 17500, 17500, 7000, 25000, 3000, 22500, 15000, 25000, 20000, 22500, 15000, 22500, 10500, 20000, 15000, 17500, 17500, 25000, 17500, 22500, 25000, 12500, 20000, 11250, 11500, 14000, 12500, 15000, 17500]
我们用直方图进行展示:
plt.hist(salaries, bins=10 ,)
plt.show()
生成效果图如下:

从图中可以看出工资分布的情况,这样在你找工作时可以做一个参考。
4.2 职位描述词频统计
对职位描述词频统计的意义是可以了解该职位对技能的基本要求,如果正在找工作,可以估计一下自己的要求是否符合该职位;如果想要一年后换工作,那么也可以提前做好准备,迎接新的挑战。
词频统计用到了 jieba、numpy、pandas、scipy库。如果电脑上没有这两个库,执行安装指令:
- pip install jieba
- pip install pandas
- pip install numpy
- pip install scipy
4.2.1 读取txt文件
前面已经将职位描述保存到txt文件里了,现在我们将其读出:
def read_txt_file(path):
'''
读取txt文本
'''
with open(path, 'r', encoding='gb18030', newline='') as f:
return f.read()
简单测试一下:
import jieba
import pandas as pd
content = read_txt_file(txt_filename)
segment = jieba.lcut(content)
words_df=pd.DataFrame({
'segment':segment})
print(words_df)
# 输出结果如下:
segment
0 岗位职责
1 参与
2 公司
3 软件产品
4 后台
5 研发
6 和
7 维护
8 工作
9 参与
10 建筑物
11 联网
12 数据分析
13 算法
14 的
15 设计
16 和
17 开发
18 可
19 独立
20 完成
21 业务
22 算法
23 模块
... ...
从结果可以看出:“岗位职责”、“参与”、“公司”、软件产品“、”的“、”和“等单词并没有实际意义,所以我们要将他们从表中删除。
4.2.2 stop word
下面引入一个概念:stop word, 在网站里面存在大量的常用词比如:“在”、“里面”、“也”、“的”、“它”、“为”这些词都是停止词。这些词因为使用频率过高,几乎每个网页上都存在,所以搜索引擎开发人员都将这一类词语全部忽略掉。如果我们的网站上存在大量这样的词语,那么相当于浪费了很多资源。
在百度搜索stpowords.txt进行下载,放到py文件同级目录。接下来测试一下:
content = read_txt_file(txt_filename)
segment = jieba.lcut(content)
words_df=pd.DataFrame({
'segment':segment})
stopwords=pd.read_csv("stopwords.txt",index_col=False,quoting=3,sep=" ",names=['stopword'],encoding='utf-8')
words_df=words_df[~words_df.segment.isin(stopwords.stopword)]
print(words_df)
# 以下为输出结果
0 岗位职责
1 参与
2 公司
3 软件产品
4 后台
5 研发
7 维护
8 工作
9 参与
10 建筑物
11 联网
12 数据分析
13 算法
15 设计
17 开发
19 独立
21 业务
22 算法
23 模块
24 开发
28 产品
29 目标
31 改进
32 创新
33 任职
35 熟练
38 开发
39 经验
40 优先
41 熟悉
... ...
从结果看出,那些常用的stop word比如:“的”、“和”、“可”等已经被剔除了,但是还有一些词如“岗位职责”、“参与”等也没有实际意义,如果对词频统计不产生影响,那么就无所谓,在后面统计时再决定是否对其剔除。
4.2.3 词频统计
重头戏来了,词频统计使用numpy:
import numpy
words_stat = words_df.groupby(by=['segment'])['segment'].agg({
"计数":numpy.size})
words_stat = words_stat.reset_index().sort_values(by=["计数"],ascending=False)
print(words_stat)
# 以下是爬取全部“北京市海淀区Python工程师”职位的运行结果:
segment 计数
362 开发 505
590 熟悉 409
701 经验 281
325 工作 209
820 负责 171
741 能力 169
793 设计 161
82 优先 160
409 技术 157
621 相关 145
322 岗位职责 127
683 系统 126
64 产品 124
904 项目 123
671 算法 107
78 任职 107
532 框架 107
591 熟练 104
可以看出,某些词语还是影响了统计结果,我将以下stop word加入stopword.txt中:
开发、熟悉、熟练、精通、经验、工作、负责、能力、有限、相关、岗位职责、任职、语言、平台、参与、优先、技术、学习、产品、公司、熟练掌握、以上学历
最后运行结果如下:
775 设计 136
667 系统 109
884 项目 105
578 熟练 95
520 框架 92
656 算法 90
143 分析 90
80 优化 77
471 数据库 75
693 维护 66
235 团队 65
72 代码 61
478 文档 60
879 需求 58
766 计算机 56
698 编程 56
616 研发 49
540 沟通 49
527 模块 49
379 性能 46
695 编写 45
475 数据结构 44
这样基本上就是对技能的一些要求了,你也可以根据自己的需求再去修改stopword.txt已达到更加完美的效果。
4.2.4 词频可视化:词云
词频统计虽然出来了,可以看出排名,但是不完美,接下来我们将它可视化。使用到wordcloud库,详细介绍见 github ,使用pip install wordcloud进行安装。
from scipy.misc import imread
from wordcloud import WordCloud, ImageColorGenerator
# 设置词云属性
color_mask = imread('background.jfif')
wordcloud = WordCloud(font_path="simhei.ttf", # 设置字体可以显示中文
background_color="white", # 背景颜色
max_words=100, # 词云显示的最大词数
mask=color_mask, # 设置背景图片
max_font_size=100, # 字体最大值
random_state=42,
width=1000, height=860, margin=2,# 设置图片默认的大小,但是如果使用背景图片的话, # 那么保存的图片大小将会按照其大小保存,margin为词语边缘距离
)
# 生成词云, 可以用generate输入全部文本,也可以我们计算好词频后使用generate_from_frequencies函数
word_frequence = {
x[0]:x[1]for x in words_stat.head(100).values}
word_frequence_dict = {
}
for key in word_frequence:
word_frequence_dict[key] = word_frequence[key]
wordcloud.generate_from_frequencies(word_frequence_dict)
# 从背景图片生成颜色值
image_colors = ImageColorGenerator(color_mask)
# 重新上色
wordcloud.recolor(color_func=image_colors)
# 保存图片
wordcloud.to_file('output.png')
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
运行效果图如下(左图为原图,右图为生成的图片):

至此,词频统计及其可视化完成。
5、其他想法
本例中进行了两种数据分析,虽为进阶版,但是还是有很多可以继续发挥的地方:
- 分析工作年限和工资的关系并展示、预测
- 统计不同工作岗位的薪资差别
- 利用多线程或多进程提升效率