机器学习实践:中文文本预处理(词袋模型/TF-IDF)
目标:为了实现利用贝叶斯模型进行新闻文本主题分类,对中文文本进行预处理。
步骤
-
- 1.准备
- 2.创建停用词词典
- 3.定义Document类(可省)
- 4.序列化标签 载入数据
- 5.创建词典
- 6.文本向量化
-
- 方法一:词袋模型
- 方法二:TF-IDF
- 7.打乱数据集
- 8.划分训练集、测试集,训练模型。(略)
1.准备
1/ 环境
win10 64位
anaconda3
pycharm 2017
2/分词好的文本
分词好的中文文本,同一主题的文章按行存储,存放在同一文本中。(未分词的文章可以先用jieba分词:参考文档)


2.创建停用词词典
防止特征空间维度过高,筛选掉无用的标点、数字、常用词。
import codecs #编码转换
import string
#创造停用词字典
def create_stop_word():
punc=string.punctuation #文档中没有英文标点,在此补充
stop_word={
}
file=codecs.open("./stop_word.txt",'r',encoding='utf-8').readlines() #codecs提供的open方法可以指定打开的文件的语言编码,这里用不用都一样
for c in file:
stop_word[c.strip()]=1
for c in punc: #补充英文标点
stop_word[c.strip()] = 1
return stop_word
stop_word=create_stop_word()
创建出的stop_word字典:

3.定义Document类(可省)
这一步是从师姐的代码中学到的,可以保证在文本处理过程中,文档和对应的主题标签不会乱。
#定义文档类
class Document:
def __init__(self,polarity,words):
self.polarity=polarity
self.words=words
4.序列化标签 载入数据
labal_name = ['fangchan', 'jiaoyu', 'caipiao']
label_index = [0, 1, 2]
domain_list = []
for key, value in zip(labal_name, label_index): #zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
print('label {} is {},loading...'.format(value, key))
documents = readFromFile('./{}.txt'.format(key), value)
domain_list.extend(documents)
readFromFile(path,polarity)函数
#读文本并写进文档类
def readFromFile(path,polarity):
documents=[]
lines = codecs.open(path, 'r', encoding='utf-8').readlines()
for line in lines: #line代表一行文本即一篇文章
line=line.split() #.split()则从每个分词的空格处将文章分成词列表
pieces = [w.strip().lower() for w in line if w.strip() not in stop_word and not w.isdigit() and "%" not in w and "." not in w] #.strip()去除词的首尾空格,调试的过程发现文章中有很多数字和百分率无法被筛掉,占用大量空间,在这里一起过滤掉。
if len(pieces)>0:
documents.append(Document(polarity,pieces)) #将一篇文章的词和标签封装到document类,以一个元素的形式存入列表
return documents
得到的domain_list列表,列表为一维列表,每个元素是一个Document实例,实例中存放了标签及词。
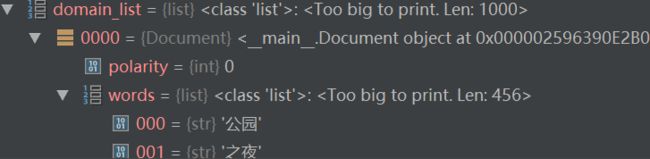
5.创建词典
常见包含数据集中所有词的词典({词:id}),并将文本列表中的词替换为对应的(id,词频)。
texts = [document.words for document in domain_list] #二位列表,一维长度为文档数目,二维为每篇文章的词
labels=[document.polarity for document in domain_list] #一维列表,长度为文档数目,存放于texts对应的标签
from gensim import corpora
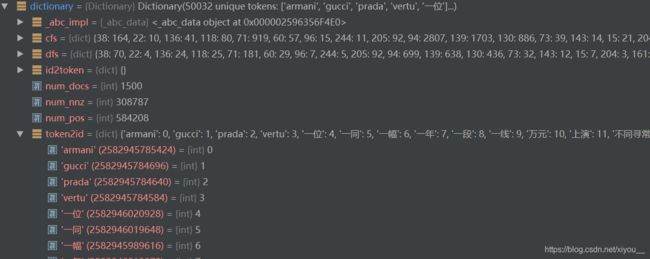
dictionary = corpora.Dictionary(texts) #生成字典 每个词对应一个id
dictionary.save('word.dict') #存储
dictionary字典如下(每个词对应一个id)。
corpus=[dictionary.doc2bow(text) for text in texts] #都转化为id表示
corpora.MmCorpus.serialize('word.mm',corpus) #保存到硬盘
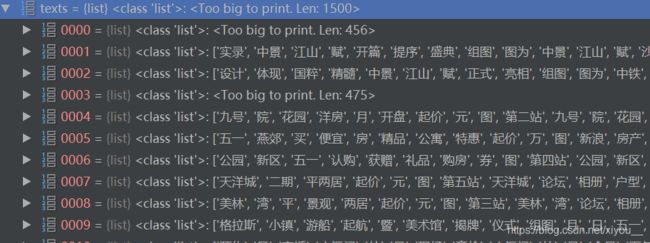
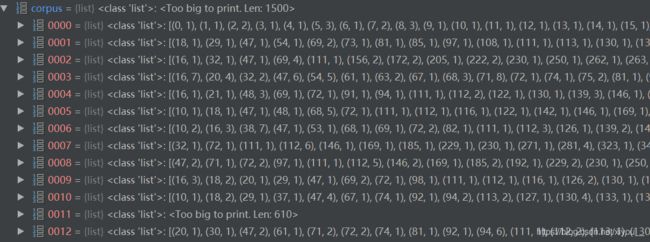
这一步将上面的texts文档中的所有词都转化为词对应的id。
原来的texts列表:
处理后得到的corpus列表(原先的词由(词id,词频)替代)。
参考:【gensim–dictionary】使用方法
6.文本向量化
方法一:词袋模型
考虑词在文章中出现的次数,适用于多项式贝叶斯模型。
#规范化2-考虑词出现的次数
from sklearn.preprocessing import MinMaxScaler
datas=np.zeros([len(corpus),len(dictionary)])
for i in range(len(corpus)):
for j in range(len(corpus[i])):
datas[i,corpus[i][j][0]]=corpus[i][j][1] #出现则置为词频
Scaler=MinMaxScaler() #可对数据做特征缩放,通过数据归一法将词频映射到0-1之间
datas=Scaler.fit_transform(datas)
得到的datas:

方法二:TF-IDF
特征选择算法,不仅考虑词频,还考虑逆文档频率,即文档集中出现某词的文章数目。当某个词条在一篇文章中出现的频率越高,且文档集中包含该词条的文档数较少,则该词条的特征权重越大。
#规范化3-tfidf
tfidf=TfidfModel(corpus).idfs #得到所有词对应的idf值
datas=np.zeros([len(corpus),len(dictionary)],dtype='float')
for i in range(len(corpus)):
for j in range(len(corpus[i])):
datas[i,corpus[i][j][0]]=corpus[i][j][1]*tfidf[corpus[i][j][0]] #词频tf×逆文档概率idf 得 权重
tfidf如下:
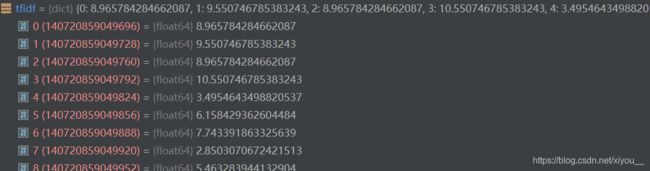
得到的datas:
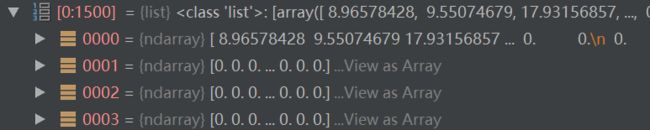
7.打乱数据集
目前为止,数据集还是0,1,2三种主题依次有序排放的,为了划分训练集和数据集并训练模型,需要打乱数据集。
#打乱文档顺序
index=np.arange(len(datas))
np.random.shuffle(index)
corpus=datas[index]
labels=np.array(labels)[index]
以labels为例,打乱前(且尚未化为ndarray形式):
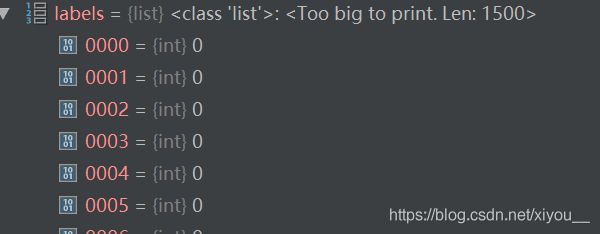
打乱后:
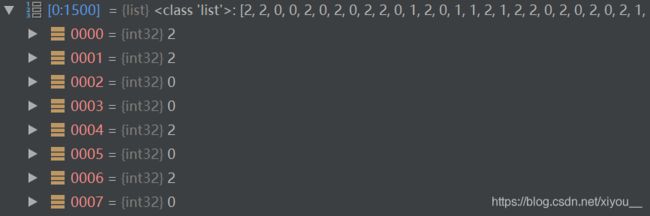
8.划分训练集、测试集,训练模型。(略)
如有问题,欢迎指正~ᕱ⑅ᕱ”
参考:
1.Python文本分类【NB、LR、SVM、CNN、RNN、TF-IDF、Word2Vec、FastText】
2.自然语言处理5——朴素贝叶斯及其sklearn实现
3.Python进行文本预处理(文本分词,过滤停用词,词频统计,特征选择,文本表示)
4.Gensim使用小解