每日一书|如何成为一名合格的CRUD工程师?
一九七零年,那是一个夏天。
有一位来自IBM圣约瑟研究实验室的高级研究员Edgar Frank Codd在Communications of ACM上发表了名为A Relational Model of Data for Large Shared Data Banks的文章,从而创建了关系数据模型。时至今日,基于该模型的关系数据库仍然是企业存储和处理数据的主要方式。甚至可以说,绝大多数IT系统都是围绕着数据库执行数据增删改查操作的。
目前主流的关系型数据库包括MySQL、Oracle、Microsoft SQL Server、PostgreSQL以及SQLite等。虽然这些数据库管理系统的具体实现有所不同,但它们都使用SQL(Structured Query Language,结构化查询语言)作为访问和操作数据库的标准语言。
1 SQL
1974年,同样是来自IBM的Donald D. Chamberlin和Raymond F. Boyce基于关系模型开发了SQL的初始版本:SEQUEL(Structured English Query Language)。SEQUEL被设计用于IBM最初的准关系数据库管理系统SystemR。
1986年,美国国家标准学会(ANSI)首先发布了SQL标准;随后ISO标准组织于1987年创建了“数据库语言SQL”标准。在经历了1989、1992、1996、1999、2003、2006、2008、2011、2016以及2019年的多次修订之后,如今的SQL标准包含了大量的功能,内容多达数千页。以下是SQL发展过程中的一些关键节点:
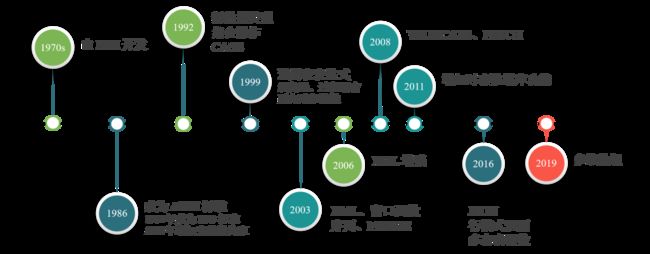
SQL是关系模式的第一个商业实现,同时也是最成功的一个实现。SQL是访问和操作关系型数据库的标准语言,所有的关系型数据库都可以使用SQL语句进行数据访问和控制,许多大数据平台(包括Flink、Spark、Hive等)也都提供的SQL支持。
SQL语句非常接近自然语言(英语),我们只需要掌握几个简单英文单词的作用,例如SELECT、INSERT、UPDATE、DELETE等,就可以完成绝大部分的数据库操作。例如,以下是一个简单的查询语句:
SELECT emp_id, emp_name, salaryFROM employeeWHERE salary >= 10000ORDER BY emp_id;
即便对于没有学过SQL的初学者,我们只要知道几个英文单词的意思就不难理解该语句的作用。该语句查找员工表(employee)中月薪(salary)大于等于10000的员工,返回了员工的工号(emp_id)、姓名(emp_name)以及月薪(salary),并且按照工号进行排序显示。
可以看出,SQL语句非常简单直观,全部都是由简单的英语单词组成,因为它在设计之初就考虑了非技术人员的使用需求。主要的SQL语句只有几个,很多时候甚至只需要使用一个SELECT语句。
也许正是由于它的简单易用,很多人都认为SQL就是简单的增删改查。但实际上,早在1999年SQL就支持了通用表表达式(WITH语句)和递归查询、用户定义类型以及许多在线分析功能,随后它又增加了窗口函数、MERGE语句、XML数据类型、JSON文档存储(SQL/JSON)、复杂事件和流数据处理(MATCH_RECOGNIZE子句)以及多维数组(SQL/MDA)等,最新的SQL标准正在定制图形存储(SQL/PGQ)相关的功能。
2 通用表表达式
我们以通用表表达式(WITH语句)为例,介绍如何使用SQL语句分析社交网络(微信、Facebook等)中的好友关系。以下是一个简单的好友关系网络:
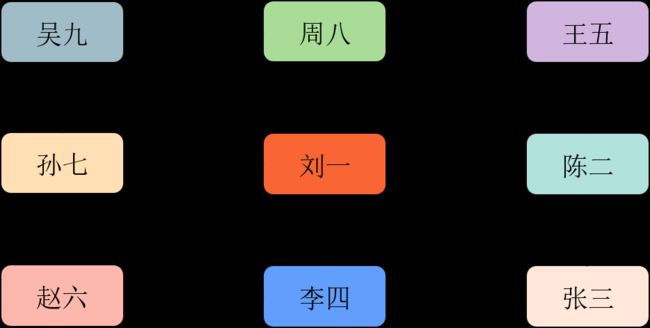
在接下来的案例分析中,我们使用t_user表存储用户信息:
user_id|user_name-------|---------1|刘一2|陈二3|张三...
其中,user_id是用户编号,user_name是用户姓名。
t_friend表中存储了好友关系,每个好友关系存储两条记录。例如:
user_id|friend_id-------|---------1| 22| 14| 1...
其中,user_id是用户编号,friend_id是好友的用户编号。
我们首先介绍如何查看共同好友,以下语句查找“张三”和“李四”的共同好友:
WITH f1(friend_id) AS (SELECT f.friend_idFROM t_user uJOIN t_friend f ON (u.user_id = f.friend_id AND f.user_id = 3)),f2(friend_id) AS (SELECT f.friend_idFROM t_user uJOIN t_friend f ON (u.user_id = f.friend_id AND f.user_id = 4))SELECT u.user_id AS "好友编号", u.user_name AS "好友姓名"FROM t_user uJOIN f1 ON (u.user_id = f1.friend_id)JOIN f2 ON (u.user_id = f2.friend_id);
我们在查询中定义了两个CTE,f1代表“张三”的好友,f2代表“李四”的好友,主查询语句通过连接这两个结果集返回了他们的共同好友。查询返回的结果如下:
好友编号|好友姓名-------|-------1|刘一
社交软件通常实现了推荐好友的功能。一方面它们可能是读取了用户的手机通讯录,找到已经在系统中注册但不属于该用户好友的用户进行推荐。另一方面系统可以找出和用户不是好友,但是有共同好友的用户进行推荐。
例如,以下语句返回了可以推荐给“陈二”的用户:
WITH friend(id) AS (SELECT f.friend_idFROM t_user uJOIN t_friend f ON (u.user_id = f.friend_id AND f.user_id = 2)),fof(id) AS (SELECT f.friend_idFROM t_user uJOIN t_friend f ON (u.user_id = f.friend_id)JOIN friend ON (f.user_id = friend.id AND f.friend_id != 2))SELECT u.user_id AS "用户编号", u.user_name AS "用户姓名",count(*) AS "共同好友"FROM t_user uJOIN fof ON (u.user_id = fof.id)WHERE fof.id NOT IN (SELECT id FROM friend)GROUP BY u.user_id, u.user_name;
我们在查询中定义了两个CTE,friend代表了“陈二”的好友,fof代表了“陈二”好友的好友(排除了“陈二”自己)。主查询语句通过WHERE条件排除了fof中已经是“陈二”好友的用户,并且统计了被推荐的用户和“陈二”的共同好友数量。查询返回的结果如下:
用户编号|用户姓名|共同好友-------|--------|-------4|李四 | 27|孙七 | 18|周八 | 2
基于查询结果,我们可以向“陈二”推3个可能认识的人,并且告诉他和这些用户有几位共同好友。
在社会学中存在一个六度关系理论(Six Degrees of Separation),指地球上任何两个人都可以通过六层以内的关系链联系起来。2011年Facebook以一个月内访问的7.21亿活跃用户为研究对象,计算出其中任何两个独立的用户之间平均间隔的人数为4.74。
我们以“赵六”和“孙七”为例,查找他们之间的好友关系链:
-- MySQLWITH RECURSIVE relation(uid, fid, hops, path) AS (SELECT user_id, friend_id, 0, CONCAT(',', user_id , ',', friend_id)FROM t_friendWHERE user_id = 6UNION ALLSELECT r.uid, f.friend_id, hops+1, CONCAT(r.path, ',', f.friend_id)FROM relation rJOIN t_friend fON (r.fid = f.user_id)AND (INSTR(r.path, CONCAT(',',f.friend_id,',')) = 0)AND hops < 6)SELECT uid, fid, hops, substr(path, 2) AS pathFROM relationWHERE fid = 7ORDER BY hops;
其中,relation是一个递归CTE。初始化语句用于查找“赵六”的好友,第1次递归返回了“赵六”好友的好友,然后以此类推。我们将关系层数hops限制为小于6,path字段中存储了使用逗号分隔的关系链,INSTR函数用于防止形成A->B->A的环路。
查询返回的结果如下。
uid|fid|hops|path---|---|----|---------------6| 7| 2|6,4,1,76| 7| 3|6,4,1,8,76| 7| 3|6,4,3,1,76| 7| 4|6,4,3,1,8,76| 7| 4|6,4,3,2,1,76| 7| 5|6,4,1,2,5,8,76| 7| 5|6,4,3,2,1,8,76| 7| 5|6,4,3,2,5,8,76| 7| 6|6,4,1,3,2,5,8,76| 7| 6|6,4,3,1,2,5,8,76| 7| 6|6,4,3,2,5,8,1,7
“赵六”和“孙七”之间最近的关系是通过“李四”和“刘一”两个人进行联系。
另外,我们也可以统计任何两个用户之间平均最少间隔的人数:
-- MySQLWITH RECURSIVE relation(uid, fid, hops, path) AS (SELECT user_id, friend_id, 0, CONCAT(',', user_id , ',', friend_id)FROM t_friendUNION ALLSELECT r.uid, f.friend_id, hops+1, CONCAT(r.path, ',', f.friend_id)FROM relation rJOIN t_friend fON (r.fid = f.user_id)AND (INSTR(r.PATH, CONCAT(',',f.friend_id,',')) = 0))SELECT AVG(min_hops)FROM (SELECT uid, fid, MIN(hops) min_hopsFROM relationGROUP BY uid, fid) mh;
查询返回的结果如下。
avg(min_hops)-------------0.8214
我们提供的测试数据集很小,任何两个人之间平均间隔0.8个人。
除了好友关系之外,通用表表达式也可以用于分析微博、知乎等软件中的粉丝关注关系。其他常用的案例包括生成数字序列、遍历组织关系图以及查询地铁、航班换乘路线图等。
3 SQL编程思想
如果你认为SQL就是简单的增删改查,那已经是40年前的概念了。虽然SQL是基于关系模型开发的语言,但是在经过几十年的发展之后,它早就不再局限于关系模型了。为了能够帮助大家了解并学习现代化的SQL语言和编程思想,而不仅仅局限于传统SQL提供的简单功能,《SQL编程思想》这本书应运而生。
![]()

本书基于作者十多年的工作经验和知识分享,全面覆盖了从SQL基础查询到高级分析、从数据库设计到查询优化等内容,通过循序渐进的方式和简单易懂的案例分析,透彻讲解了每个SQL知识点。本书采用了全新的SQL:2019标准,紧跟产业发展趋势,帮助读者解锁最前沿的SQL技能,同时提供了5种主流数据库的实现和差异。最后,本书还介绍了全新的SQL:2019标准对文档存储(JSON)、行模式识别(MATCH_RECOGNIZE)、多维数组(SQL/MDA)以及图形存储(SQL/PGQ)的支持。
本书适合需要在日常工作中完成数据处理的IT从业人员,包括SQL初学者、拥有一定基础的中高级工程师,甚至精通某种数据库产品的专家阅读。
(声明:本文转载自“博文视点Broadview”微信公众号。)