
作者:惠州工业互联网研究院
小 T 导读:惠州市新一代工业互联网创新研究院(以下简称研究院)成立于 2018 年 6 月,是以部省联动实施国家重点研发计划“宽带通信和新型网络”重点专项为契机,在广东省科技厅和惠州市政府的支持下成立,立足惠州、面向广东、辐射全国、联动国际的工业互联网省级科技创新平台。
为实现宿舍用电的智能化管理、保证学生用电的独立性和安全性,针对学校宿舍用电的收费,研究院打造的智慧用电管控系统采用一室一表一保护的方案,为学生宿舍配置智能电能计量表计和用电保护设备,对每个用户的用电进行独立计量和保护。
这套系统通过互联网采集所有终端的数据,再由通讯网关将数据通过无线组成的专用网络或局域网将数据传输至远程管理计算机。系统管理软件再对数据进行存储、处理,形成学校后勤管理方需要的图形、文字等形式的文件,以此实现整个学生宿舍用电的智能化管理。
在整个系统的构建中,令我们比较头疼的是关于数据库的选择,这套用电系统会产生大量的时序数据,在达成基础的存储、压缩和查询功能需求外,还需要平衡搭建、学习和维护等各种成本。基于此,我们开始进行数据库选型,以期找到最适合该用电管控系统的数据库产品。
从系统架构进行数据库选型
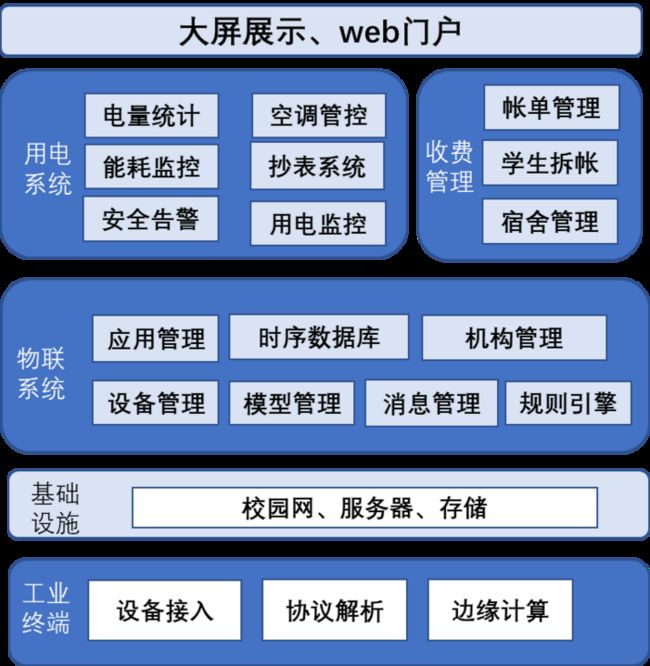
智慧用电管控系统采用工业互联网平台典型的端网边云系统架构,通过物联系统及网关解耦设备与应用平台,加速数据的聚合与开放,服务于智慧校园安全用电、用电缴费等场景,同时可支持智慧校园其他项目快速接入需要。下图为具体的架构示意图:
为了找到合适的数据库产品,我们先对整个系统架构进行了分析。
在整体架构中,该数据库的数据需要作为基础设施的数据存储,通过校园网络提供包括物联系统在内的如下数据输出:
- 工业通信终端:高性能通信网关能同时接入多台水电气表及智慧保护开关,支持多种工业协议,能同时解析不同类型设备数据,并能按自设置的上报频率上报数据到物联系统服务器。
- 物联系统:包括设备模型管理、设备管理、项目管理、历史消息管理、规则引擎等功能,能接入任意物联网类型设备,可支持智慧校园其他项目快速接入需要。
- 用电系统:实时监测、抄表系统、收费应用、能耗监测、安全管理、系统管理,所有宿舍可以按小时/天/月/季/年颗粒度查询用电量,电表电闸实时读数和开关状态查询,告警查询,宿管分权分域管理。
- 收费系统:实现学校公寓宿舍管理,根据校园阶梯计费的要求,实现学生阶梯计费拆帐算法,生成的帐单由校园宿舍管理人员确认后发布到收费系统进行查询并缴费,学生缴费后生成缴费历史清单。
- 大屏展示、Web 门户:通过数字大屏、Web 门户中的 Dashboard 面板,直观形象的进行数据展示。
这一整套系统产生的数据量之庞大可见一斑,除了存储外,各种查询操作也十分考验性能优劣,还需要能够快速接入其他项目。经过对各种数据库进行分析后,TDengine 这款时序数据库产品浮现在我们眼前,它的很多特性非常符合我们整体架构的设计初衷,也能够完美匹配系统的数据处理需求:
- 多样化的数据写入支持。校园网复杂的系统环境和网络环境提高了数据写入的多样性要求,TDengine 支持多种接口写入数据,包括 SQL、Prometheus、Telegraf、collectd、StatsD、EMQ MQTT Broker、HiveMQ Broker、CSV 文件等,不仅帮助我们实现了工业终端层的数据写入,而且部分其他系统的集成数据也得以用更低的成本进行了实施。
- 较低的学习成本。我们的研发团队是做智慧校园系统的,得益于 TDengine 运维方便、支持 SQL 等特性,整个团队仅用很低的安装、运维、使用方面的学习成本就完成了基于 TDengine 系统实施。
- TDengine 在整个构架最核心的时序场景的数据读写和压缩率方面,表现优异。智慧校园的工业物联设备的数据写入量,不论在种类、数据点、并发数量方面都有极高的要求,而且在大量数据的情况下,写入数据的压缩率也非常影响存储的成本。TDengine 满足了 3 万条/秒的写入速度,并且压缩率达到了惊人的 1/7 左右。
- TDengine 毫秒级别的数据查询、基于时间轴的滑动窗口聚合计算等特性,以及查询结果与 Grafana、BI 插件等快捷便利地集成,为最终的数据可视化提供了很好的支持。
以上几点原因,让我们坚定地选择了 TDengine 作为智慧用电管控系统的数据库产品,并开始实施搭建。
基于 TDengine 的建库、建表思路
作为一个专门为物联网结构化数据流设计的时序数据库,TDengine 的建库、建表思路与关系型数据库完全不同,其遵循一个数据流隔离的原则。
物联网设备产生的数据是按照时间顺序产生的数据流,在校园智慧用电管控系统系统,我们高频收集宿舍用电数据,一是用来统计每小时宿舍用电情况,二是用来判断宿舍大功率使用情况,及时发出大功率电器使用报警。
这种背景下,用诸如 SQL Server 的关系型数据库来存储时序数据时,做法通常是将所有同类设备的数据都建到同一张表中,每条记录会包含设备 ID、数据采集(或入库)时间戳、采集到的值,并按照时间范围来分表提速。这种做法的弊端在于查询麻烦且低效,从关系型数据库中查询某一个设备的数据时,还需要通过设备 ID 把其他设备的数据从大表中过滤掉,且每查询一个设备,就要面临过滤其他设备数据的开销。
与关系型数据库不同,TDengine 的设计思路是一个数据源(设备)一张表,每个数据源按照时间顺序产生的消息流可以流入一个表中,不与其他数据流混合。表的主键是数据记录采集或入库的时间戳,其他字段是采集的值。这样在 TDengine 中查询某个设备的指定时间段数据时,查询就简化为找到该设备的表并按照主键(时间戳)过滤搜索数据记录,效率大幅提升。
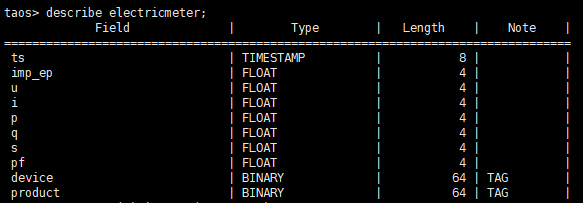
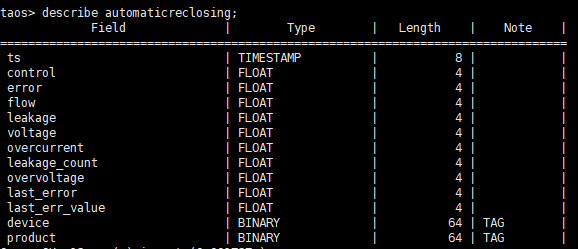
此外,在 TDengine 中,我们为了方便管理设备,对不同设备模型创建了不同的超级表,比如电表模型是一个超级表,智能保护开关是另一个超级表。
具体到我们的场景中,建库、建表思路如下:
- 超级表
超级表的结构非常简单,采集字段就是时间戳 ts 和采集值 val。但此处定义了两个标签,用于描述具体的点位静态信息。

- 普通表


搭载 TDengine 的效果和优势
上文中我们讲解了数据库选型思路和基于 TDengine 建库、建表的思路,那具体 TDengine 的表现如何呢?下面为大家一一揭秘。
- 高写入速度
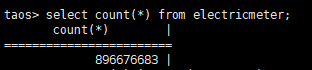
现在我们服务器接入的设备数是 4000 多个,包括 2000 多台电表和 2000 台智能保护开关,每台电表以每分钟频率采集一次数据,包括电流、电压、电能、有功功率、无功功率等 7 个测点,每台保护开关同样也以每分钟频率采集一次数据,包括智能开关状态、最近故障、最近故障值、当前故障状态、当前电压值、当前电流值、当前漏电电流值、过流次数、过压次数、漏电次数等 10 个测点。
目前系统总共有 4000 多张设备表,每张表每天新增 1440 条数据 13000 个测点,一天新增大约 500 多万条数据 4000 万个测点,由此可见 TDengine 的写入性能之高。
此外,使用 TDengine 带来的最大好处是不用再考虑 SQLServer 中的分库分表操作,即使数据不断写入一年,查询时延也不会增加。
- 低内存、高压缩比
在使用中,我们发现 TDengine 在处理 4000 多个设备、百万量级的数据量的写入任务时,内存开销只有 1.5GB,进行查询时,内存增长也不会有明显提升。在数据落盘后,我们查看了 var/lib/taos 下的数据文件大小,原来 5GB 的原始数据,经 TDengine 压缩后只有 80MB,压缩比为 1.6%。
- 双机备份
TDengine 还采用集群方案做了双机备份,具体的方案是两数据节点、两数据副本的集群方式。这一集群方式,不仅在运维底层实现了数据的备份,伴随着对 TDengine 功能的进一步深入使用,其去中心的多数据节点集群开始作用,使得应用可以对所有节点进行写入和读取,从而得以有效利用服务端的资源,以数据层提供的高效读写速度有效提升整个系统的响应时间。
在刚开始使用 TDengine 时,其还没有双机热备份,以集群方式在两台主机上使用时出现了一些问题,在和涛思数据的小伙伴充分沟通后,我们通过“充分发挥底层数据库的功能,再进一步优化平台的系统架构”的方式成功解决了此问题。
之后在 TDengine 双节点集群方案出炉后,整个系统在很多方面都获益匪浅:
- 对于在校园网环境服务的整个构架中运作的应用来说,不停机的数据节点扩展保证了稳定的服务。
- 实现了便利的服务能力扩容。服务能力从原来的一台数据节点硬件资源支撑能力,线性增长为 2 台节点的硬件资源支撑能力。
- 稳定可靠的数据备份。数据节点自动对数据副本进行备份,不仅从运维角度上轻松实现了多节点数据备份的效果,而且并没有对原有节点的运行效率有任何影响。
- 两节点去中心化集群,提供了数据层两节点写入和读取的支撑能力扩展。
值得一提的是,在 TDengine 这次单节点升级双机热备集群的过程中,通过监控可以看到,对于数据节点增加、减少或者离线时的负载机制,TDengine 底层稳定地将计算负载均衡到两个节点之上,这也为日后随着接入点和应用的增多而继续扩充 TDengine 节点提供了保障。
写在最后
我们的系统在采用 TDengine 后不仅节省了其他方案搭建集群的费用,而且在写入速度和查询性能方面完全满足了业务的需求。作为一款为物联网场景设计的时序数据库,在多设备、采集频率高的业务形态下,TDengine 展现出了高性能、架构简单的优势,其超级表的设计也省去了很多联表查询逻辑,极大简化了业务层的开发工作。