前言
DETR首创了使用transformer解决视觉任务的方法,它直接将图像特征图转化为目标检测结果。尽管很有效,但由于在某些区域(如背景)上进行冗余计算,输入完整的feature maps的成本会很高。
在这项工作中,论文将减少空间冗余的思想封装到一个新的轮询和池(Poll and Pool, PnP)采样模块中,该模块具有通用和即插即用的特点,利用该模块构建了一个端到端的PnP-DETR体系结构,该体系结构可以自适应地在空间上分配计算,以提高计算效率。
本文来自公众号CV技术指南的
关注公众号CV技术指南 ,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读。

![]()
代码:https://github.com/twangnh/pnp-detr
Background
目标检测是一项基本的计算机视觉任务,其目的是识别图像中的目标实例,并使用精确的边界框对其进行定位。现代检测器主要利用代理学习目标(proxy learning objectives)来处理该集合预测任务,即,回归距预定义锚框的偏移量或距网格位置的边界。这些启发式设计不仅使模型设计复杂化,而且还需要手工制作的后处理来消除重复。
最近的一种方法DETR消除了这些手工设计,实现了端到端的目标检测。它在卷积特征图上建立了一个有效的集合预测框架,并显示出与faster R-CNN检测器相当的性能。特征图在空间维度上被展平为一维特征向量。然后,transformer利用其强大的注意机制对它们进行处理,以生成最终的检测列表。
尽管简单而有效,但将transformer网络应用于图像特征映射可能在计算上代价高昂,这主要是由于对长展平的特征向量的注意操作。这些特征可能是冗余的:除了感兴趣的对象之外,自然图像通常包含巨大的背景区域,这些背景区域可能在相应的特征表示中占据很大一部分;而且,一些区分特征向量可能已经足以检测对象。现有的提高transformer效率的工作主要集中在加速注意操作上,很少考虑上面讨论的空间冗余。
创新思路
为了解决上述局限性,论文开发了一个可学习的轮询和池化(Poll and Pool, PnP)采样模块。它的目的是将图像特征图压缩成由精细特征向量和少量粗略特征向量组成的抽象特征集。
从输入特征图中确定性地采样精细特征向量,以捕捉精细前景信息,这对于检测目标是至关重要的。粗略特征向量聚合来自背景位置的信息,所产生的上下文信息有助于更好地识别和定位对象。然后,transformer对细粗特征空间内的信息交互进行建模,并获得最终结果。
由于抽象集比直接扁平化的图像特征图短得多,因此transformer的计算量大大减少,并且主要分布在前景位置。这种方法与提高transformer效率的方法是正交的,可以进一步与它们结合得到更有效的模型。
Contributions
总结起来,本文的主要贡献在于:
1. 识别了DETR模型中图像特征图的空间冗余问题,该问题导致transformer网络计算量过大。因此,提出对特征映射进行抽象,以显著降低模型运算量。
2. 为了实现特征提取,设计了一种新颖的两步轮询池采样模块。该算法首先利用poll采样器提取前景精细特征向量,然后利用pool采样器获取上下文粗特征向量。
3. 构建了PnP-DETR,该变换在抽象的细粗特征空间上进行操作,并自适应地将计算分布在空间域。通过改变精细特征集的长度,PnP-DETR算法效率更高,在单一模型下实现了即时计算和性能折衷。
4. PnP抽样模块是通用的,是端到端学习的,没有像地区提案网络那样的明确监督。论文进一步在全景分割和最近的ViT模型上对其进行了验证,并显示出一致的效率增益。这种方法为未来研究使用transformer的视觉任务的有效解决方案提供了有用的见解。
Methods

PnP-DETR结构图
feature abstration
论文提出了一种特征抽象方案来解决网格结构化表征均匀地分布在空间位置上的限制。具体来说就是把CNN输出的feature maps用紧凑特征表示的两组特征向量来代替作为transformer部分的输入,细节如下图所示。
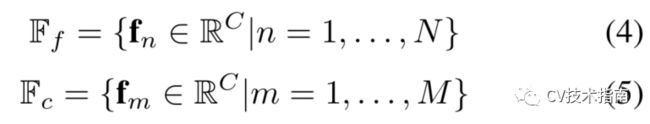
精细特征集Ff是从feature maps离散采样的,包含识别和检测对象所必需的精细信息。粗略特征集Fc是通过聚集来自多个空间位置的信息并编码背景上下文信息而获得的。它们一起形成一个抽象集合F∗:F* = Ff U Fc。F∗对检测图像内的对象所需的所有高层信息进行编码,并将其传递给transformer以生成目标检测结果。

Poll and Pool (PnP) Sampling
上述抽象方案需要解决两个挑战:
1)精集需要确定性的二进制采样,这是不可微的。手工设计的采样器可以用一些中间目标来学习,例如,区域提议网络或点提议网络,然而,这与端到端学习不兼容,并且手工采样规则可能不是最优的。
2)提取仅关注背景上下文信息的紧凑、粗略的特征集是困难的。论文将抽象方案分为两个步骤,并开发了轮询采样器和池化采样器来实现。采样器是确定性的,是端到端学习的,计算量可以忽略不计。
Poll Sampler
由于显式学习二进制采样器是不可行的,论文提出了一个采样排序策略。我们使用小型元评分网络来预测每个空间特征位置(i,j)的信息性分数:
![]()
分数越大,f_ij向量的信息量越大。接下来对它们排序,得到一个分数向量Sl,向量的长度l为feature maps的HxW。取排序后的TopN , N = alpha * l。此alpha用来控制比例。
为了能够使用反向传播学习ScoringNet,将预测的信息量得分Sl作为对采样的精细特征集的调制因子:
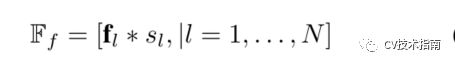
作者发现在调制前对特征向量进行归一化可以稳定ScoringNet的学习,因此实际上先对fl做了一个LayerNorm,再与Sl相乘。
Pool Sampler
上面的轮询采样器提取了精细的特征集。剩余的特征向量主要对应于背景区域。为了将它们压缩成一个总结上下文信息的小特征集,论文设计了一个池化采样器,它对剩余的特征向量进行加权汇集,以获得固定数量的背景上下文特征向量。这部分地受到双线性汇集和双重注意操作的启发,其中生成全局描述符以捕获特征图的二阶统计量。
公式太多,用一句话来解释Pool采样的主要操作:
-
使用一个可学习的加权向量W^a,与Poll采样过后剩余的向量Fr进行相乘,得到一个聚合权重向量a_r,再使用Softmax对聚合向量a_r进行归一化;
-
与此并列的是,使用一个可学习的加权向量W^v,与Poll采样过后的剩余向量Fr相乘,得到一个映射后的向量F'r;
-
将归一化后的a_r聚合向量和F'r相乘,即可得到Pool Sampler的输出。
文献[34]表明,上下文信息是识别目标的关键,不同尺度的金字塔特征能更好地聚合上下文信息。通过动态生成聚合权重,池化采样器能够自由获取不同尺度的上下文信息。也就是说,一些特征向量可以捕获局部上下文,而其他特征向量可以编码全局上下文。
论文通过可视化聚集权重实证地展示了池采样器的这种能力。与轮询采样器中的精细集合Ff一起,获得所需的抽象集合F∗。请注意,PnP模块也可以在transformer层之后应用,而不仅仅是卷积特征图。
密集预测任务的反向投影
PnP模块将图像特征映射从2D坐标空间缩减到抽象空间,这不能用于密集预测任务,如图像分割。为了解决这一局限性,论文提出将编码器输出的特征向量投影回2D坐标空间。
具体地说,精细特征向量散布回采样位置;粗略特征向量首先过聚合权重扩散回通的原始2D空间:然后分散回Poll采样器的未采样位置。然后,将所获得的2D特征图用于密集预测。
Conclusion
论文在COCO基准上进行了大量的实验,结果表明PnP-DETR有效地降低了成本,实现了动态计算和性能折中。
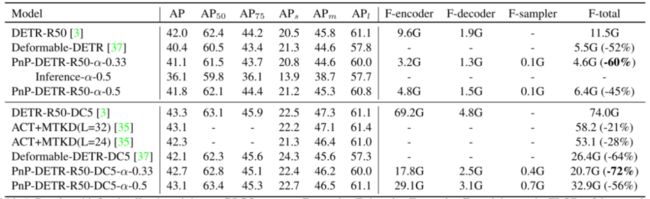
在没有花里胡哨的情况下,单个PnP-DETR-DC5可获得42.7 AP,transformer计算量减少72%,而与43.3 AP基线和竞争性43.1 AP相比,transformer计算量减少56%。进一步用全景分割和最近的vision transformer模型(ViT)验证了效率增益。例如,PnP-ViT在精确度仅下降0.3的情况下实现了近一半的FLOP减少。
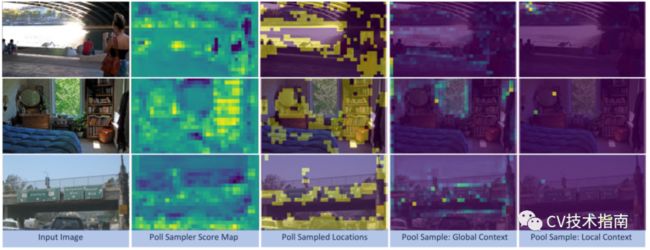
使用PnP-DETR-R50可视化来自池化采样器的Poll样本位置和示例聚合权重图。第一列:输入图像;第二/第三列:轮询采样器的得分映射及其相应的样本映射;最后两列:来自池化采样器的示例聚合权重映射,其中前者聚合全局上下文,而后者聚合局部上下文。
欢迎关注公众号 CV技术指南 ,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读。
在公众号中回复关键字 “入门指南“可获取计算机视觉入门所有必备资料。

其它文章