深度学习导论(3)PyTorch基础
深度学习导论(3)PyTorch基础
- 一. Tensor-Pytorch基础数据结构
- 二. Tensor索引及操作
-
- 1. Tensor索引类型
- 2. Tensor基础操作
- 3. 数值类型
- 4. 数值类型操作
- 三. Tensor与Numpy的互操作
-
- 1. 小案例
- 2. 序列化Tensor-torch方式
- 3. 序列化Tensor-h5py方式
- 四. Tensor on GPU
- 五. Tensor operations
-
- 1. Tensor reshaping(变形操作,非常重要)
- 2. Broadcasting(广播)
- 3. Tensor product(乘法运算)
- 4. 自动求导
介绍了PyTorch基础,包括以下内容:一. Tensor-Pytorch基础数据结构; 二. Tensor索引及操作; 三. Tensor与Numpy的互操作; 四. Tensor on GPU; 五. Tensor operations
一. Tensor-Pytorch基础数据结构
-
可以把Tensor理解为多维数组
-
深度学习任务: 将数据从分阶段从一种形式转换成另一种形式(用浮点数表示)。
-
深度学习小例子:

如图所示,图片中有大海和太阳,图片的原始形态实际上就是对像素的采样出来的一个矩阵,在这个矩阵中,每个元素都是[0, 255]的像素值(机器学习或者深度学习中一般将将其浮点数化,即将其变为[0, 1]或者[-1, 1])。将这张图片放入神经网络中,结果出来的OUTPUT为一个矩阵Softmax,矩阵中的向量值范围为[0, 1]。其中每个向量代表着对应标签的概率值,例如“太阳”、“海边”、“风景”等等。从以上例子可以看出,深度学习其实就是根据样本评判标签的过程。
二. Tensor索引及操作
1. Tensor索引类型

(1) Scalar
称为0维的Tensor。如上图所示,“3”就是一个标量。
(2) Vector
称为1维的Tensor。如上图所示,X[2]代表Vector中第3个元素,即“5”。
(3) Matrix
称为2维的Tensor。如上图所示,X[1, 0]代表Matrix中第3行第1列的元素,即“7”。
(4) 3-D Tensor
可以将其理解为将多个向量“摞”起来。如上图所示,X[0, 2, 1]代表3-D Tensor中第1个矩阵的第3行第2列的元素,即“5”。(注: 对于不同的任务,怎么表示是由自己定义的,例如X[0, 2, 1]也可以代表3-D Tensor中第1个矩阵的宽度为3,高度为2的元素,即“3”。)
(5) 多维Tensor
多维的Tensor。如上图所示,X[…]代表从最外围的一层一直延伸到最里边一层的元素。
注:Tensor与List(Tuple)的区别:

- List(Tuple): 在内存中单独分配的对象集合;
- Tensor: 将向量和矩阵推广到任意维度,也可以理解为多维数组。在内存中连续存储的一组元素(非对象);
- 一些操作如dot,mul等不能针对list进行。
如: 一个包括100万个浮点数的一维Tensor需要存储400万个连续字节,加上少量元数据(维度、数字类型等)的开销。
2. Tensor基础操作
查看conda环境有哪些:
conda env list
在图形界面启动Jupyter Notebook
(1) 生成一个每个元素都为1的矩阵

(2) 生成一个三行三列的矩向量

(3) Scalar(0-D Tensors): 0维的Tensor

(4) Vectors(1-D Tensors): 1维的Tensor,即向量的形式

(5) Matrix(2-D Tensors): 2维的Tensor,即矩阵的形式
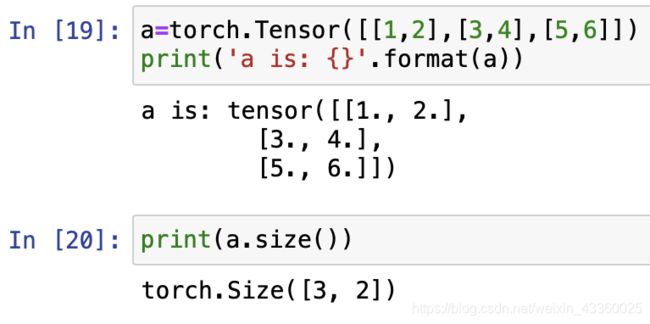
(6) 4-D & 5-D Tensors

注:
- 4-D举例: 642242243: 其中224224表示的是图像的宽和高,3表示的是RGB图像的通道数,64代表每个批次的样本数(往模型当中送数据时,并不是一个一个往里送,而是分批次往里送,即一个batch一个batch往里送,一个batch可能是32个、64个、256个或者1024个样本)。
- 5-D Tensors: 视频,多了一个“帧”的维度。首先是最外边的维度“batch”,即每个批次的样本数; 然后是“t”,即帧; 然后是“h”和“w”,即图像的高和宽然后是“c”,即通道数。即 [batch, t, h, w, c]。
3. 数值类型
(1) 32位浮点型
torch.float32 or torch.float——32-bit floating-point
(2) 64位浮点型
torch.float64 or torch.double——64-bit, double-precision floating-point
(3) 16位浮点型
torch.float16 or torch.half——16-bit, half-precision floating-point
(4) 8位整型(有符号)
torch.int8——Signed 8-bit integers
(5) 8位整型(有符号)
torch.uint8——Unsigned 8-bit integers
(6) 16位整型(无有符号)
torch.int16 or torch.short——Signed 16-bit integers
(7) 32位整型(有符号)
torch.int32 or torch.int——Signed 32-bit integers
(8) 64位整型(有符号)
torch.int64 or torch.long——Signed 64-bit integers
4. 数值类型操作
(1) 使用dtype指定数值类型
![]()
(2) 使用dtype获取数值类型

(3) 数值类型转换

(4) to方法

(5) type方法

- 数据索引操作
(1) 取出所有元素
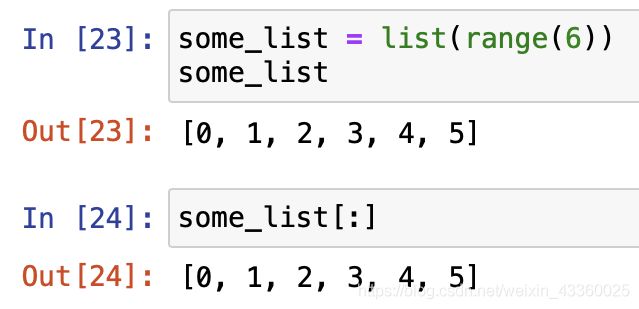
(2) 取出第2~4个元素

注: 切片操作为左闭右开
(3) 取出第2~最后一个元素

(4) 取出第一~第4个元素

(5) 取出第一个~倒数第二个元素

(6) 取出第2~4个元素,步长为2(隔一个一取)

三. Tensor与Numpy的互操作
1. 小案例
(1) 导入大熊猫图片,并查看size

(2) 取出第0个通道,并转换成numpy的形式

(3) 局部截取(切片操作),高: 25~175; 宽: 60,130; 第0个通道切片

2. 序列化Tensor-torch方式

注: PyTorch使用pickle序列化Tensors对象,存储的文件其它应用无法使用。
3. 序列化Tensor-h5py方式

注: 序列化成为h5py形式的数据时,任何类型的框架或者方法都可以读,但是只能用Tensor或者PyTorch来存储或者打开。
四. Tensor on GPU

五. Tensor operations
- Tensor reshaping
- Broadcasting
- Tensor product
注: 神经网络完全由Tensor operations组成
1. Tensor reshaping(变形操作,非常重要)
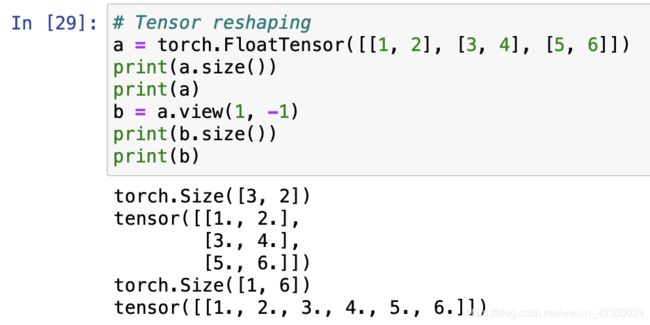
注: view(1, -1),其中前面的“1”表示将其变为1行,后面的“-1”表示如果不知道有几列,那么直接用“-1”代替即可,相当于“b = a.view(1, 6)”。
2. Broadcasting(广播)

3. Tensor product(乘法运算)
- torch.dot: 向量点积(只能用于一维的向量)。
- torch.mul: element product(相当于直接使用“*”)。
- torch.mm: 按照矩阵乘法规则运算(相乘的两个元素需要满足一定的维度(size)要求)。
- torch.matmul: torch.mm的broadcasting版本。
(1) torch.dot
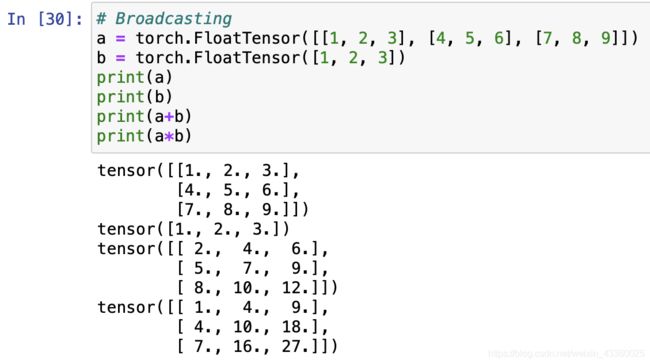
- 上图中“a*b”即为dot操作,即点积操作。
(2) torch.mul

注: a被定义完是Python中List的形式,所以必须要转换成Tensor的形式
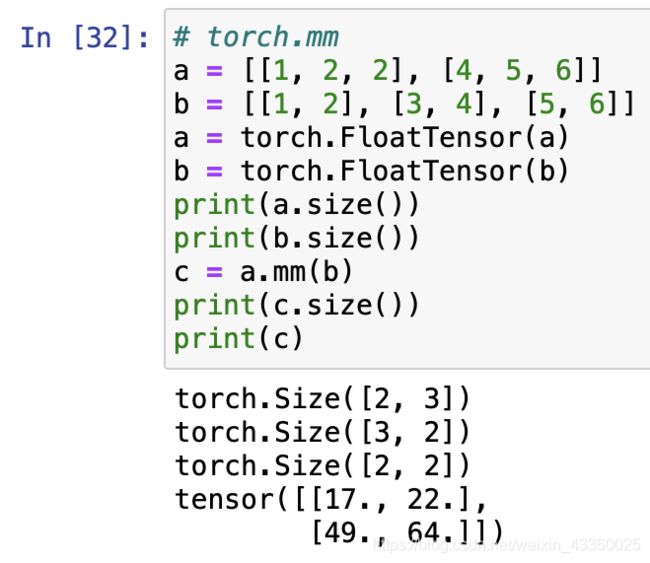
(3) torch.mm
(4) torch.matmul

4. 自动求导

(1) requires_grad

- 如果将Tensor的.require_grad属性设置成True,则将会跟踪对该Tensor的所有操作,计算结束以后调用.backward()将会自动计算所有梯度。该Tensor的梯度将会累积到.grad属性中。
- 如果不想跟踪对Tensor的操作,可以将代码块封装到“with torch.no_grad()”中,如在测试过程中不需要计算梯度。
(2) grad_fn
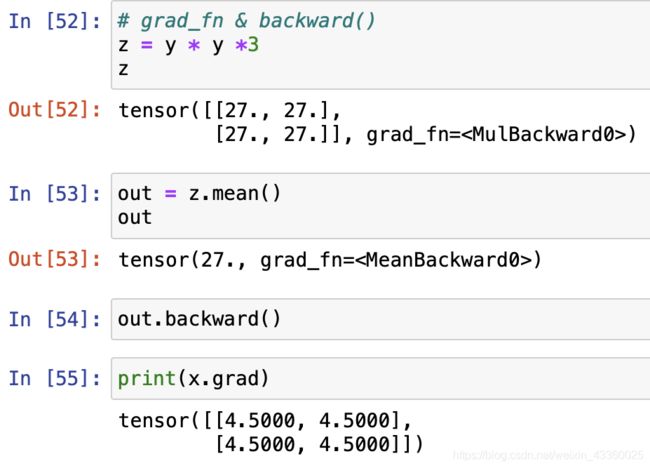
- 该属性指向创建该Tensor的函数。
(3) backward()

注: 调用该方法计算梯度,如果Tensor为标量,则该方法不需要参数,如果Tensor为向量,则该方法需要一个tensor作为参数。