走过 30 年:银行数据库的下一步是国产化


作者 | 小枣君
来源 | 鲜枣课堂
头图 | 下载于视觉中国
今天,我们来聊一个和“钱”有关的话题。
在日常紧张的工作生活里,最欢乐的一件事情,莫过于老板们发红包,大家抢红包。
不知道大家有没有想过,在我们抢红包行为的背后,究竟是怎样的一套数据系统在提供支撑?如果这套系统出现了问题,我们的帐户余额多几个零或者少几个零,会如何?
哈哈,我相信这个画面是难以想象的!
没错,在数字信息时代,所有的钱和财富,其实都是一串又一串的数字。管理和记录这些数字的银行金融系统,拥有举足轻重的地位,关系到整个社会的稳定。
这些系统中,最为重要的,就是银行数据库系统。

银行数据库系统不仅支撑着金融行业的高速发展,也给我们的生活带来了极大便利。如今,我们之所以能够随时随地进行转账、支付和收款,就是因为有它的存在。

银行数据库技术的诞生
我们还是从银行数据库技术的发展历程开始讲起吧。
上世纪60年代,数据库技术作为计算机科学的一个分支,开始萌芽。
1961年,美国通用电气公司的查尔斯·巴赫曼(Charles Bachman),成功开发出世界上第一个数据库管理系统——IDS(IntegratedData Store,集成数据存储),奠定了网状数据库的基础,并在当时得到了广泛的发行和应用。
1970年,IBM公司的研究员埃德加·弗兰克·科德(Edgar Frank Codd)在题为《大型共享数据库数据的关系模型》的论文中,提出了数据库的关系模型,开创了关系数据库时代。这篇论文被普遍认为是数据库系统历史上最重要的论文。

70-80年代,几乎所有新开发的数据库系统都是关系型的。也就是这一时期,美国软件业进入黄金成长阶段,Microsoft(1975)、甲骨文(1977)等软件公司纷纷成立,Oracle(1979)、Informix (1981)、DB2(1983)、Sybase(1988)等数据库产品也陆续诞生。

80年代早期,我们国家信息产业萌芽,开始引进数据库技术。
当时,国家一穷二白,技术基础薄弱,所以基本上就是采用“拿来主义”,全盘采用。
1987年,IBM公司专门给中国定制的第一版SAFEII系统,在中国工商银行网点大量上线,标志着中国银行业开始走上信息化数据系统的道路。
进入90年代,越来越多的国内银行开始启动信息化改造。他们面临的头等问题,就是分支行各自为政,信息和数据无法打通、共享,进而影响通存通兑等业务的实现。
为了改变这一现状,银行普遍开始采用集中式数据管理模式,建立统一的数据中心和数据库,以此来实现网点和业务的数据集中,推动资金流动。

1998年的银行营业网点(图片来自网络)
前面小枣君说过,金融是国民经济的命脉,而数据是金融企业最核心的资产。因此,银行业对数据库的性能、稳定性及安全性有着极高的要求。
在这个背景下,银行对数据库产品的选型,往往会对价格不敏感,“要买就买最贵的”。所以,国外商业数据库轻而易举地垄断中国银行业全部的市场份额。像ORACLE、DB2等产品,市场占比90%以上,可以说是赚得盆满钵满。

分布式数据的崛起
进入21世纪之后,数据库技术的演进趋势发生了微妙的变化。
首先,互联网业务的爆炸式增长,催生了新一代互联网巨头的诞生,也给IT信息系统的性能提出了更高的要求。
高并发、大负载、高可靠、强安全,成了互联网公司搭建服务架构必须满足的条件。除此之外,互联网公司对成本更加敏感,无法承受老式IT架构的巨额软硬件投入和维护成本。
于是,互联网公司开始尝试用低成本的开源解决方案,挑战传统IT巨头的架构垄断。
这一时期,云计算技术和分布式架构开始流行。体现在数据库领域,就是分布式数据库技术的迅速崛起。
简单来说,分布式数据库就是“逻辑上集中、物理上分布”的数据库。它将一个单体数据库变成若干个异地分布的小型数据库功能节点,对外提供服务。而我们前面所提的Oracle、DB2,都是集中式架构产品。
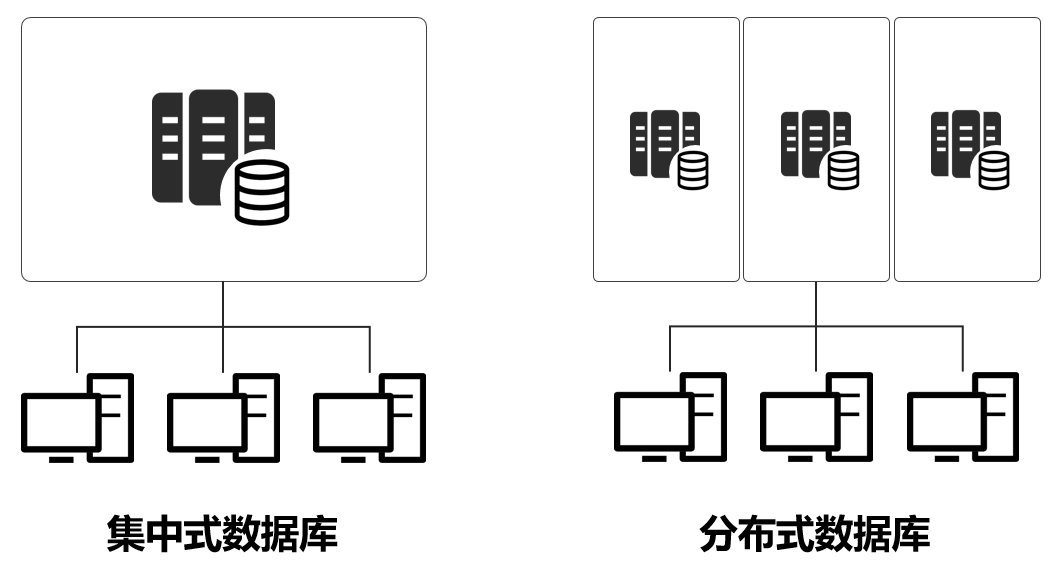
与集中式数据库相比,分布式数据库拥有明显的优势:
首先,分布式数据库可以均衡交易负载,通过高并发的架构,提升交易处理能力。
其次,分布式数据库还可以进行横向扩展(理论上可以无限扩展),不断提高自身的业务承载能力。
再有,分布式数据库能显著降低成本(包括硬件成本、人力成本等),减小开发和运维的难度及工作量。

随着金融科技的不断发展,针对IT基础设施的自主创新进程也在不断推进。越来越多的银行和数据库企业,开始研究如何采用基于分布式架构的国产数据库,替换集中式架构的国外数据库。他们的设计目标很明确,那就是既要实现弯道超车,也要保证稳定可靠。
这里面需要说明一下,对于一家银行来说,通常有几百套信息和数据系统。国有大行,甚至可能有几千套。这些系统,分为核心业务系统和非核心业务系统。简单来说,和“钱”有关的系统,例如资产管理、贷款管理等,是核心系统。而客服系统、积分系统等,都属于非核心系统。
核心业务系统,是银行的命根子,是关键中的关键。核心业务系统的替换,才是真正的目标达成。
相对于体量巨大的国有大行,最先行动起来的是股份制银行、城市商业银行、村镇商业银行和互联网银行。
这里面业界比较典型的案例包括:互联网银行中的微众银行、网商银行,农商行中的张家港农商,股份制银行中的中信银行,以及城商行中的赣州银行、贵州银行。
微众银行和网商银行,由于没有传统银行的历史负担,所以采用的是自家的腾讯TDSQL和阿里的Oceanbase。
张家港农商则是腾讯和其参股的长亮科技在2019年倾力打造的农商行国产数据库样板,据报道日均交易量达到69万笔。
中信银行是最早推动进行国产分布式数据库替代的股份制银行。他们选择的是中兴通讯的GoldenDB。
早在2015年,中信银行就开始商用了GoldenDB。紧接着,2019年10月,GoldenDB在新一代信用卡核心业务系统投产。2020年5月,更是成功在总行账务核心业务系统投产,累计交易额已达到万亿级、日均交易达到亿级。
贵州银行和赣州银行采用的是和中信银行一样的选择,也是GoldenDB。两家银行分别在2020年10月和11月上线其新一代信贷核心项目群项目和新核心业务系统项目。
中信银行和赣州银行基于成功的项目实践,分别在2019年和2020年入围中国国际金融展“金鼎奖”,荣获“年度优秀网信产品基础软硬件奖”。
上述成功落地的案例,极大提升了业界对国产数据库的认可,也加速了替换的进程。据悉,工商银行、建设银行、交通银行、广发银行等国内银行机构也已经纷纷着手启动相关工作,预计很快会传来更多振奋人心的消息。

结语
2020年,国内实际经营的银行机构共有4000家左右,银行数据库软件市场规模高达200亿元。而Oracle等海外厂商的市场占有率,仍然超过了80%。这意味着,国产化数据库拥有非常广阔的发展空间。
根据中国人民银行发布的《金融科技(FinTech)发展规划(2019-2021年)》,我们国家将有计划、分步骤地稳妥推动分布式数据库产品先行先试,形成可借鉴、能推广的典型案例和解决方案,为分布式数据库在金融领域的全面应用探明路径,确保分布式数据库在金融领域稳妥应用。
毫无疑问,基于国家对金融行业软件自主化提出的明确要求,未来更多的银行将加入国产分布式数据库的试点,金融自主创新将会进入快车道。
就在3月25日刚刚结束的中兴通讯2021年度政企云网生态峰会上,中兴通讯高级副总裁俞义方对外重磅发布GoldenDB年度新版本-GoldenDB v6.0,正式吹响中兴通讯GoldenDB分布式数据库进军国有大型商业银行的号角,这也是继GoldenDB在中信银行核心业务系统投产稳定运行超2年后的又一力作,我们相信自主创新且运行稳定的国产数据库,将迎来历史性的发展机遇。
银行数据库的国产化时代,已然到来!
![]()
CSDN协同行业大佬
打造13长热门知识图谱及IT成长路线
助力千万IT人成长,快速实现职场进阶!
更多精彩推荐
☞Kubernetes 和 Docker,到底什么关系?☞PassMark 更新排行,苹果 M1 杀疯了☞干货!Redis集群工作原理解析点分享点收藏点点赞点在看