双链表
问题
本节没有讲太多知识,主要是围绕优化方面来展开,设想一下,对于单链表的addLast()方法
public void addLast(int x) {
size += 1;
IntNode p = sentinel;
while (p.next != null) {
p = p.next;
}
p.next = new IntNode(x, null);
}可以看出每次在添加一个新的末尾结点之前都要遍历到当前的末尾结点,时间复杂度是O(n),有没有方法可以达到O(1)的呢?
优化1
添加一个变量last,总是指向最后一个结点,类似于C语言的尾指针
public class SLList {
private IntNode last;
public void addLast(int x) {
last.next = new IntNode(x, null);
last = last.next;
size += 1;
}
...
}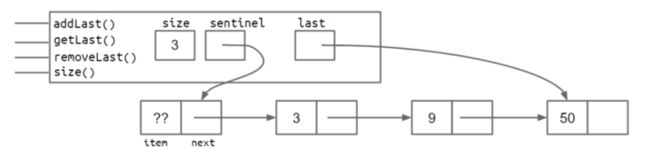
这样做之后对于新增末尾结点addLast()与求末尾结点的值getLast()的时间复杂度都可以优化到O(1),但是对于removeLast(),也就是删除末尾结点来说,复杂度仍是O(n),因为当我要删除末尾结点,那么我需要找到倒数第二个结点并将其next赋值为NULL,依然需要从头遍历整个链表
优化2
考虑给每个结点增加一个prev指针域,指向其前一个结点,这样的话对于一个结点来说,既可以访问其前一个结点,也可以访问其后一个结点,也就是双链表
public class IntNode {
public IntNode prev;
public int item;
public IntNode next;
}
优化之后,当我们需要删除最后一个结点时,只需last.prev.next = null
即可删除最后一个结点,时间复杂度降到O(1)
随之而来的问题是,当一个链表所有结点都删完了,只剩下哨兵结点时,sentinel与last一起指向哨兵结点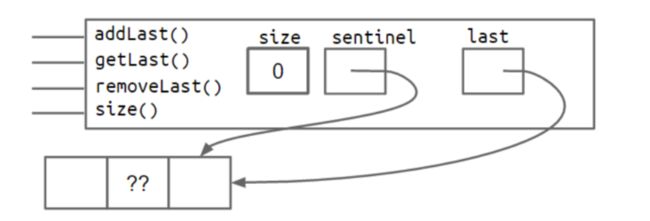
这也就是说last有时候指向正常的结点,有时候却指向哨兵结点,因此我们可能需要加很多特判条件,比如当删除到只剩哨兵结点时
优化3
那么我们可以考虑增加两个哨兵结点,一个在头部,一个在尾部,众所周知哨兵结点数据域我们不关心(图中的??),哨兵结点即标记结点的作用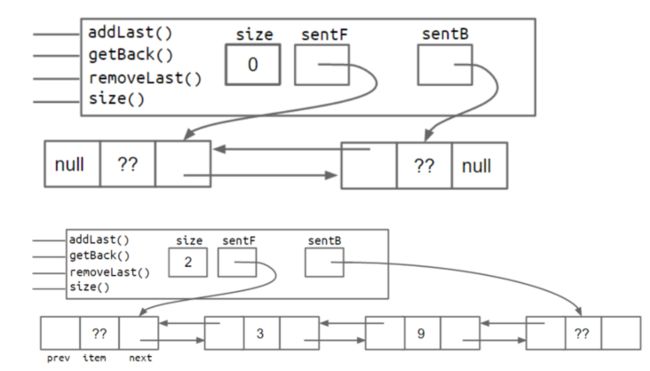
另一种方法即循环双链表,共享同一个哨兵结点,如图所示

泛型
我们的IntNode代码定义是
public class IntNode {
public IntNode prev;
public int item;
public IntNode next;这意味着我们只能对链表结点的数据域添加整数,倘如我们尝试使用字符串
DLList d2 = new DLList("hello");
d2.addLast("world");那么很显然编译器会报错,一个直接的方法是将int全部改为String,但是当我又想生成Double类型的结点呢?岂不是又要改一遍,非常麻烦,因此Java提供了一种叫做泛型的语法,我们只需在class name(类名)后面加上
DLList可以容纳任何类型的泛型如下所示:
public class DLList {
private stuffNode sentinel;
private int size;
public class stuffNode {
public stuffNode prev;
public ElemType item;
public stuffNode next;
...
}
...
} 我们已经定义了DLList类的泛型。当我们在main()函数中使用时,传入我们想实现的类型即可,我们在声明时,将所需类型放在尖括号内,并在实例化时使用< >。例如:
字符串类型
DLList d2 = new DLList<>("hello");
d2.addLast("world"); 整数类型
DLList d1 = new DLList<>(5);
d1.addFirst(10); 注意
实例化泛型时,传参必须是类型的大写,即
Integer, Double, Character, Boolean, Long, Short, Byte, Float
而非int char