hadoop,hdfs和yarn回顾
回顾之旅第二篇
emm 一年前曾经自己搭过hadoop分布式集群,集群倒是跑起来了,而且成功安装了hive,spark,yarn。不过吧,之后忙其他事情去了,现在啥都想不起来了,只能康康以前留下的资料。所以啊,还是要写写文章,让自己记得更牢固一些!!
一、从hadoop的生态圈讲起,主要包括hdfs, mapreduce和yarn。hdfs是用于存储数据的,mapreduce是用于计算的,yarn是用于资源调度的。所以在搭建伪分布式hadoop中,至少有这三种功能。

HDFS means the hadoop distributed file system is designed to run on commodity hardware. The differences from other distributed file systems is that hdfs is highly fault-tolerant and to be deployed on low-cost hardware. Hence, hdfs has a master/slave architecture. An hdfs cluster consists of a single NameNode, a master server, that manages the file system namespace and regulates access by clients. Besides, In hdfs cluster, it also has few DataNodes that manages storage attached to the nodes. However, a file is distributed into one or more blocks and they are stored in different DataNodes. The NameNode executes file system namespace operation like opening, closing and renaming files and directories and also decides the mapping of blocks to DataNodes. While DataNodes are responsible for serving read and write operation from clients.
YARN stands for "Yet Another Resource Negotiator" and was introduced in hadoop 2.0. Yarn was described as a "Redesigned Resource Manager". It allows different data processing engines such as interactive processing and stream processing to run and process data stored in hdfs. Even though its various components, it could allocate various resource to these processings. For Yarn, it also is master/slave architecture. When clients submit map-reduce jobs, the resource manager (master) is responsible for resource assignment and management among all the applications. The resource manager sends the processing request to the corresponding node manager (slave) and allocates resources for completion of the request. Whereas, node manager takes care of individual node on hadoop cluster and monitors resource usage, performs log management and container etc. There is a program illustrating how does the communication work in yarn. Furthermore, there is a concept about application manager (master) that negoiatiates resource from the resource manager and nodemanagers. Container is a collection of physical resource such as RAM, CPU and disk on a single node.
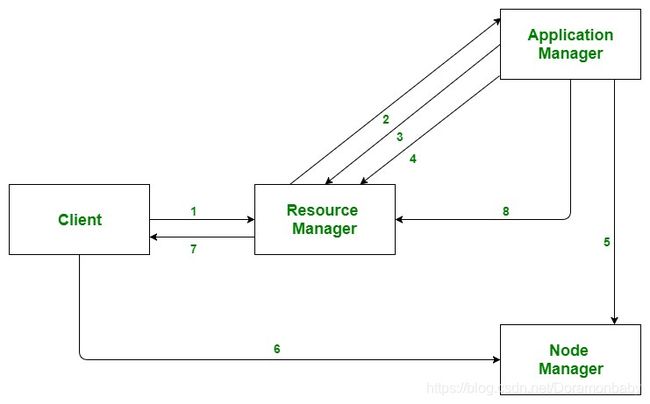
- Client submits an application
- The Resource Manager allocates a container to start the Application Manager
- The Application Manager registers itself with the Resource Manager
- The Application Manager negotiates containers from the Resource Manager
- The Application Manager notifies the Node Manager to launch containers
- Application code is executed in the container
- Client contacts Resource Manager/Application Manager to monitor application’s status
- Once the processing is complete, the Application Manager un-registers with the Resource Manager
MapReduce is a processing technique and a program model for distributed computing based on java, which consists two components Map and Reduce. Map takes a set of data and converts it into another set of data like key-value pairs. The reduce task takes the output from a map as input and combines those pairs.
自己的理解,不一定对仅供参考哈:伪分布式模式是通过虚拟机模拟多个主机,例如三个虚拟节点,一个是master节点,另一个是slave节点。在虚拟机中,我们可以直接复制已经配置好的虚拟节点,这样就不需要三个节点重复配置, 它们可以通过ssh免密登录。Namenode就是相当于管理文件的,而datanode相当于文件中具体的内容。另一方面,Master节点包括了NameNode,ResourceManager 和 Application Manager。NameNode是HDFS的Master,主要负责Hadoop分布式文件系统元数据的管理工作;ResourceManager是Yarn的Master,其主要职责就是启动、跟踪、调度各个NodeManager的任务执行。另外两个结点均为slave结点包括了DataNodes 和 NodeManager,其中一个是用于冗余目的,如果没有冗余,就不能称之为hadoop了。Slave结点主要将运行hadoop程序中的datanode和tasktracker任务。所以每一个Slave逻辑节点通常同时具有DataNode以及NodeManager的功能。
二、配置伪分布式hadoop集群
其实网上有很多教程啊!这俩就挺好的
https://blog.csdn.net/quiet_girl/article/details/74352190
https://www.cnblogs.com/zhangyinhua/p/7652686.html
所以我就不重复了,接下来我就总结一下。
一、搭建伪分布式集群的前提条件是:
1、每个节点都要有Ubuntu OS, jdk 和 hadoop安装包;配置hosts文件使得三个虚拟机有固定的IP地址,它们可以进行沟通。
2、每个节点都要修改Ubuntu OS的权限,安装jdk并配置环境变量。
3、每个节点都要安装hadoop,配置hadoop环境变量。
二、伪分布式集群配置
Configure relative components about hadoop in etc/hadoop directory
Common component -- core-site.xml
HDFS component -- hdfs-site.xml
MapReduce component -- mapred-site.xml
YARN component -- yarn-site.xml
Hadoop environment setting -- hadoop-env.sh
Finally, testing whether hadoop is installed or not with command "hadoop version"
三、测试
1、格式化集群
./hdfs namenode -format
2、启动和关闭集群
hadoop-daemon.sh start/stop namenode
hadoop-daemon.sh start/stop secondarynamenode
hadoop-daemon.sh start/stop datanode
yarn-daemon.sh start/stop resourcemanager
yarn-daemon.sh start/stop nodemanager
mr-jobhistory-daemon.sh start/stop historyserver
Or start-all.sh
Using jps to check master node and slave nodes, which process is run.
三、常用语句
首先先找到hadoop的安装位置,通过echo $hadoop_home
然后切换到hadoop的安装目录,就可以使用hadoop,hdfs,mapred 和yarn命令了。
there are many kinds of shell command for hdfs: hadoop fs, hadoop dfs and hdfs dfs. Here is the difference between hadoop fs and hdfs dfs, and hadoop dfs has been deprecated.

1. hadoop 命令
$hadoop -help 中可以发现hadoop自带的命令,其中fs最常用。
- version: hadoop version
- mkdir: hadoop fs -mkdir /path/directory_name; hadoop fs -mkdir -p /datafile2
- ls: hadoop fs -ls /path
- put(copy local files to hdfs): hadoop fs -put ~/localfiles /filefromlocal
- copyFromLocal(like put): hadoop fs -copyFromLocal ~/localfiles /copylocal
- cat: hadoop fs -cat /copylocal
- get(copy hdfs files to local): hadoop fs -get /testfile ~/copyfromhdfs
- copyToLocal(like get): hadoop fs -copyToLocal /testfile ~/copyfromhdfs
- mv: hadoop fs -mv /file1 /file2
- cp(copy hdfs file to hdfs): hadoop fs -cp /file1 /file2
https://data-flair.training/blogs/top-hadoop-hdfs-commands-tutorial/
官网资料:http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/CommandsManual.html
2. hdfs 命令
$hdfs -help
- hdfs dfs -df -h 查看空间大小
- hdfs dfs -du -s -h 查看文件大小
- hdfs dfs -ls 列出文件
- hdfs dfsadmin -report 查看集群运行状态
3. mapred 命令
$mapred -help
- mapred queue -list
- mapred job -list all
- mapred job -kill job-id
官方文档:https://hadoop.apache.org/docs/current/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapredCommands.html
4. yarn 命令
$yarn -help
- yarn application -appId
- yarn application -kill
- yarn applicaiton -list -appStates RUNNING/ALL
- yarn application -status
- yarn container -list
5. hive 命令
- hive -e "select * from ..." > results_log.txt 然后
- hive -f test.sql 执行独立的sql文件
- hive -v 额外打印hql语句
- hive -S -e"select * from "
https://blog.csdn.net/qq_36864672/article/details/78624060
大概就是这些吧~下面是我用到的一个reference
https://www.cnblogs.com/suheng01/p/12143338.html
https://www.cnblogs.com/caimuqing/p/7811435.html
https://blog.csdn.net/qq_21125183/article/details/86572013
https://www.geeksforgeeks.org/hadoop-yarn-architecture/#:~:text=YARN%20stands%20for%20%E2%80%9CYet%20Another%20Resource%20Negotiator%E2%80%9C.&text=YARN%20architecture%20basically%20separates%20resource,resource%20manager%20and%20application%20manager.
https://www.tutorialspoint.com/hadoop/hadoop_mapreduce.htm
https://blog.csdn.net/guolindonggld/article/details/82111217