从零搭建大数据集群环境:Hadoop2.7.4 + Spark2.4.5 分布式部署
此部署教程为基于虚拟机的 Hadoop2.7.4 + Spark2.4.5 完全分布式部署文档,虚拟机系统为centos7,读者可根据自己实际部署环境情况进行相应调整。
其中第三节Hadoop安装为可选安装:如果你的Spark应用涉及到HDFS或者使用YARN来调度集群资源,则必须安装;如果你只会用到Spark的local模式或者standalone模式并且不会涉及HDFS文件则可跳过(都点开本文了,建议全装上)。
本人水平有限,文章难免会有错误,欢迎各位指正。
文章目录
- 1 基础配置清单
-
- 1.1 软件及系统配置
- 1.2 集群规划
- 2 系统环境配置
-
- 2.1网络配置
-
- 配置IP
- 配置网关
- 重启网络服务
- 测试网络配置是否正确
- 2.2 关闭防火墙
-
- 关闭防火墙
- 关闭 selinux
- 2.3 配置IP映射关系
- 2.4 SSH免密登录配置
-
- 每台机子产生新的rsa公钥私钥文件
- 统一拷贝到一个authorized_keys文件中
- 授权文件分配至其他主机
- 2.5 JDK配置
-
- 解压安装
- 配置profile
- 验证JDK是否安装正确
- 3 Hadoop安装
-
- 3.1 解压Hadoop安装包
- 3.2 修改Hadoop配置文件
-
- 配置 hadoop-env.sh
- 配置core-site.xml
- 配置 hdfs-site.xml
- 配置 yarn-site.xml
- 配置 slaves
- 3.3 分发配置好的hadoop文件至所有节点
- 3.4 hadoop1上修改环境变量
- 3.5 格式化hdfs
- 3.6 启动Hadoop集群
-
- 启动hdfs
- 验证hdfs是否成功启动
- 启动yarn
- 验证yarn是否启动成功
- 4 Spark安装
-
- 4.1 解压Spark安装包
- 4.2 修改Spark配置文件
-
- 配置spark-env.sh
- 配置slaves
- 4.3 分发配置好的spark文件至所有节点
- 4.4 hadoop1上修改环境变量
- 4.5 启动Spark集群
- 4.6 运行Spark程序测试
- 参考资料
1 基础配置清单
1.1 软件及系统配置
此清单为本样例部署情况,实际部署可根据自身情况调整。
集群的操作系统均为 centos7,软件主要配置如下。
| 软件名 | 版本号 | 下载链接 |
|---|---|---|
| JDK | 1.8 | https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html |
| Hadoop | 2.7.4 | https://archive.apache.org/dist/hadoop/common/hadoop-2.7.4/ |
| Spark | 2.4.5 | http://archive.apache.org/dist/spark/spark-2.4.5/ |
1.2 集群规划
本样例集群部署在VMware虚拟机上,实际部署可以根据自身情况调整(ps 我实际把host命名为了kkk1,kkk2,kkk3 ( ╯□╰ ) 个人习惯。后续截图情况和文章描述会有点出入)
| hostname | IP | 角色 | 配置 |
|---|---|---|---|
| hadoop1 | 192.168.50.131 | master | 4G+2核 |
| hadoop2 | 192.168.50.132 | worker | 2G+2核 |
| hadoop3 | 192.168.50.133 | worker | 2G+2核 |
2 系统环境配置
本部分配置所有节点都需要操作,文章以主节点hadoop1为例。
2.1网络配置
参考VMware NAT网络设置修改相应网络配置。

配置IP
# vi /etc/sysconfig/network-scripts/ifcfg-ens33
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="static"
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens33"
UUID="16fdce89-c12c-497b-9515-ead13dd1b527"
DEVICE="ens33"
ONBOOT="yes"
IPADDR=192.168.50.131
DNS1=192.168.50.2
GATEWAY=192.168.50.2
NETMASK=255.255.255.0
配置网关
# vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=hadoop1
GATEWAY=192.168.50.2
重启网络服务
# systemctl restart network
测试网络配置是否正确
# ping www.baidu.com
2.2 关闭防火墙
在测试环境下可以将防火墙完全关闭,方便集群安装、访问。
关闭防火墙
# systemctl stop firewalld
# systemctl disable firewalld
查看防火墙状态验证是否关闭
# systemctl status firewalld
关闭 selinux
# vi /etc/sysconfig/selinux
SELINUX=disabled
SELINUXTYPE=targeted
2.3 配置IP映射关系
将集群IP和别名配置,方便互相访问
# vi /etc/hosts
192.168.50.131 hadoop1
192.168.50.132 hadoop2
192.168.50.133 hadoop3
配置完后可以互相ping一下测试是否ping通
2.4 SSH免密登录配置
集群机器互相之间需要满足免密登录。
每台机子产生新的rsa公钥私钥文件
登录hadoop1,在.ssh目录下输入(如果不存在则新建一个文件夹)。
# cd .ssh
# ssh-keygen -t rsa
三次回车后,该目录下将会产生id_rsa,id_rsa.pub文件。其他主机也使用该方式产生密钥文件。
登录hadoop1,在.ssh目录下生成authorized_keys文件。
# cat id_rsa.pub >> authorized_keys
统一拷贝到一个authorized_keys文件中
登录其他主机,将其他主机的公钥文件内容都拷贝到hadoop1主机上的authorized_keys文件中。
# ssh-copy-id -i hadoop1
授权文件分配至其他主机
# scp /root/.ssh/authorized_keys hadoop2:/root/.ssh/
# scp /root/.ssh/authorized_keys hadoop3:/root/.ssh/
至此免密登录配置完毕,可以互相间ssh测试
# ssh hadoop2
第一次ssh登录时需要输入密码,再次访问即可免密登录。ssh登录后注意使用 exit 退出
2.5 JDK配置
所有节点都需要安装JDK。
解压安装
将下载的JDK安装包解压到 /usr/java 路径下(路径可自定,后续配置环境正确即可)
# tar xzvf jdk-8u211-linux-x64.tar
# ls
jdk1.8.0_211 jdk-8u211-linux-x64.tar
配置profile
在/etc/profile 文件末尾加入JAVA环境配置,其中JAVA_HOME根据实际JDK目录情况配置,本例中即为 /usr/java/jdk1.8.0_211
# vi /etc/profile
export JAVA_HOME=/usr/java/jdk1.8.0_211
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
配置完毕后使其生效
# source /etc/profile
验证JDK是否安装正确
# java -version
java version "1.8.0_211"
Java(TM) SE Runtime Environment (build 1.8.0_211-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.211-b12, mixed mode)
TIP:至此,分布式基础环境已经配置完毕,可以给各节点做个快照(非必须),后续集群部署出错也可以恢复至此然后继续安装配置
3 Hadoop安装
注意Hadoop集群的安装及集群配置文件所有节点都需要配置,可以在hadoop1操作完毕之后使用scp命令将配置完毕的文件复制到其余节点。
3.1 解压Hadoop安装包
本例中hadoop相关软件均放在/opt/apache文件下。将下载的hadoop压缩包解压至/opt/apache目录下。
# cd /opt/apache
# tar xzvf hadoop-2.7.4.tar.gz
# ls
hadoop-2.7.4 hadoop-2.7.4.tar.gz
3.2 修改Hadoop配置文件
配置文件在/opt/apache/hadoop-2.7.4/etc/hadoop目录下,该步骤操作均在hadoop1节点。
配置 hadoop-env.sh
修改 JAVA_HOME,根据实际路径修改
# vim hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_211
配置core-site.xml
在文件添加如下内容

其中 hadoop.tmp.dir 配置后需要根据value值新建文件夹。
配置 hdfs-site.xml
在文件中添加如下内容

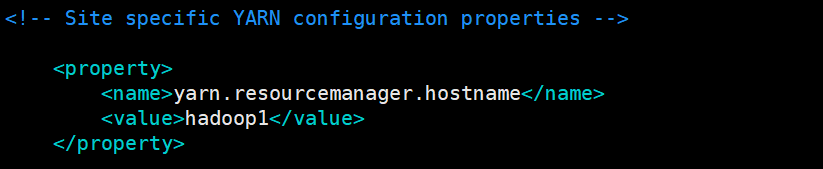
配置 yarn-site.xml
在文件中添加如下内容
配置 slaves
将hadoop2,hadoop3添加至slaves文件即可。
# vim slaves
hadoop2
hadoop3
3.3 分发配置好的hadoop文件至所有节点
在hadoop1上执行命令
# scp -r /opt/apache/hadoop-2.7.4 root@hadoop2:/opt/apache
# scp -r /opt/apache/hadoop-2.7.4 root@hadoop3:/opt/apache
3.4 hadoop1上修改环境变量
和JDK配置profile文件相似,在profile文件中添加Hadoop相关配置
# vim /etc/profile
export HADOOP_HOME=/opt/apache/hadoop-2.7.4
export PATH=$PATH:$HADOOP_HOME/bin
别忘记使其生效
# source profile
3.5 格式化hdfs
在配置完毕后,首先格式化hdfs,在hadoop1上进入${HADOOP_HOME}/bin 下执行命令
# cd ${HADOOP_HOME}/bin
# hdfs namenode -format
3.6 启动Hadoop集群
在hadoop1下,进入到${HADOOP_HOME}/sbin目录下,启动 hdfs 和 yarn
启动hdfs
# cd ${HADOOP_HOME}/sbin
# ./start-dfs.sh

验证hdfs是否成功启动
在主节点使用 jps 命令查看是否有SecondaryNameNode和NameNode进程,子节点使用使用 jps 命令查看是否有DataNode进程。


但是可能因为防火墙或者格式化次数较多(造成子节点的cluster_id跟主节点的cluster_id不一致),导致主节点无法接收到子节点发送的心跳信息,那么此时对于主节点来说子节点相当于挂掉了。
jps命令检查过后可以使用
# hdfs dfsadmin -report

命令来查看如果如下则说明集群hdfs正常工作。或者在本机使用浏览器访问192.168.50.131: 50070检查(即masterIP:配置开放端口号)

启动yarn
在 ${HADOOP_HOME}/sbin 目录下
# ./start-yarn.sh

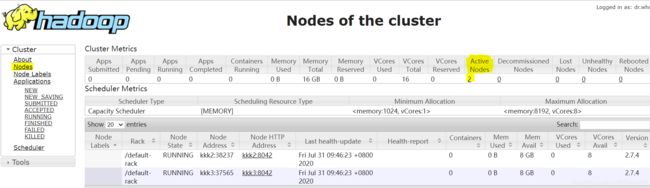
验证yarn是否启动成功
同样使用 jps 命令,查看主节点是否有ResourceManager进程,从节点是否有NodeManager进程。


和验证hdfs类似,需要用
# yarn node --list --all
命令进一步查看各节点是否成功启动。

或者使用浏览器访问192.168.50.131: 8088检查(即masterIP:配置开放端口号)
4 Spark安装
Spark安装和Hadoop类似,其文件结构基本和Hadoop一致。同样的Spark集群的安装及集群配置文件所有节点都需要配置,可以在hadoop1操作完毕之后使用scp命令将配置完毕的文件复制到其余节点。
4.1 解压Spark安装包
本例中spark相关软件均放在/opt/apache文件下。
# cd /opt/apache
# tar xzvf spark-2.4.5-bin-hadoop2.7.tgz
# ls
hadoop-2.7.4 hadoop-2.7.4.tar.gz spark-2.4.5-bin-hadoop2.7 spark-2.4.5-bin-hadoop2.7.tgz
4.2 修改Spark配置文件
Spark的配置文件在/opt/apache/spark-2.4.5-bin-hadoop2.7/conf目录下
配置spark-env.sh
Spark提供了模板文件spark-env.sh.template,根据模板文件修改。
# cd /opt/apache/spark-2.4.5-bin-hadoop2.7/conf
# cp spark-env.sh.template spark-env.sh
# vim spark-env.sh
在文件中添加如下内容。其中 JAVA_HOME 和 HADOOP_HOME 根据实际路径填写。

配置slaves
Spark提供了一个slaves文件模板slaves.template,根据模板文件修改,在文件中添加 hadoop2,hadoop3即可。
# cd /opt/apache/spark-2.4.5-bin-hadoop2.7/conf
# cp slaves.template slaves
# vim slaves
hadoop2
hadoop3
4.3 分发配置好的spark文件至所有节点
在hadoop1上执行命令
# scp -r /opt/apache/spark-2.4.5-bin-hadoop2.7 root@hadoop2:/usr/apache
# scp -r /opt/apache/spark-2.4.5-bin-hadoop2.7 root@hadoop3:/usr/apache
4.4 hadoop1上修改环境变量
在profile文件中添加Spark相关配置
# vim /etc/profile
export SPARK_HOME=/opt/apache/spark-2.4.5-bin-hadoop2.7
并使其生效
# source profile
4.5 启动Spark集群
在hadoop1的${SPARK_HOME}/sbin目录下,使用脚本文件启动集群
# cd ${SPARK_HOME}/sbin
# ./start-all.sh

此时在各节点使用jps命令,主节点会多出Master进程,从节点会多出Worker进程。


主机访问浏览器 192.168.50.131:8080可以查看SparkUI

4.6 运行Spark程序测试
集群是否真正成功安装还需要跑一遍程序,可以利用Spark自带的样例,本例Spark 2.4.5自带的是计算PI值。可以利用Spark的standalone模式跑一遍样例代码,在hadoop1的 ${SPARK_HOME}目录下执行如下命令
# ./bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://hadoop1:7077 ./examples/jars/spark-examples_2.11-2.4.5.jar 100
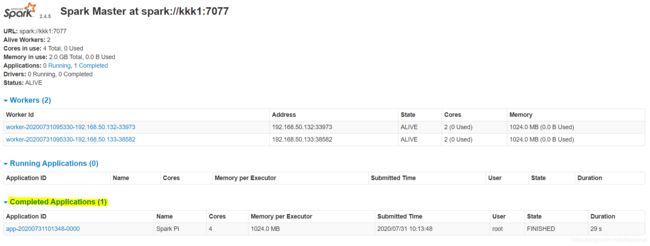
在SparkUI上也可以查看application的信息
或者使用spark on yarn 启动,如下命令是以yarn-client模式启动
# ./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client ./examples/jars/spark-examples_2.11-2.4.5.jar 100
参考资料
| 链接 | |
|---|---|
| spark官方文档 | http://spark.apache.org/docs/2.4.5/ |
| hadoop官方文档 | https://hadoop.apache.org/docs/r2.7.4/ |
| 集群搭建 | https://www.linuxidc.com/Linux/2018-06/152795.htm |
| 集群ssh免密配置 | https://www.linuxidc.com/Linux/2017-03/141296.htm |