主要摘自 http://dblab.xmu.edu.cn/post/8116/
案例简介
Spark课程实验案例:淘宝双11数据分析与预测课程案例,由厦门大学数据库实验室团队开发,旨在满足全国高校大数据教学对实验案例的迫切需求。本案例涉及数据预处理、存储、查询和可视化分析等数据处理全流程所涉及的各种典型操作,涵盖Linux、MySQL、Hadoop、Hive、Sqoop、Eclipse、ECharts、Spark等系统和软件的安装和使用方法。案例适合高校(高职)大数据教学,可以作为学生学习大数据课程后的综合实践案例。通过本案例,将有助于学生综合运用大数据课程知识以及各种工具软件,实现数据全流程操作。各个高校可以根据自己教学实际需求,对本案例进行补充完善。
案例目的
熟悉Linux系统、MySQL、Hadoop、Hive、Sqoop、Spark等系统和软件的安装和使用;
了解大数据处理的基本流程;
熟悉数据预处理方法;
熟悉在不同类型数据库之间进行数据相互导入导出;
熟悉使用JSP语言搭建动态Web工程;
熟悉使用Spark MLlib进行简单的分类操作。
预备知识
需要案例使用者,已经学习我的本系列文章的前续内容。
软件工具
本案例所涉及的系统及软件:
Linux系统
MySQL
Hadoop
Hive
Sqoop
ECharts
Intellij idea
Spark
数据集
淘宝购物行为数据集 (5000万条记录,数据有偏移,不是真实的淘宝购物交易数据,但是不影响学习)
案例任务
安装Linux操作系统 (前述教程已经完成)
安装关系型数据库MySQL(前述教程已经完成)
安装大数据处理框架Hadoop(前述教程已经完成)
安装数据仓库Hive(前述教程已经完成)
安装Sqoop(前述教程已经完成)
安装Intellij idea(前述教程已经完成)
安装 Spark(前述教程已经完成)
对文本文件形式的原始数据集进行预处理
把文本文件的数据集导入到数据仓库Hive中
对数据仓库Hive中的数据进行查询分析
使用Sqoop将数据从Hive导入MySQL
利用Eclipse搭建动态Web应用
利用ECharts进行前端可视化分析
利用Spark MLlib进行回头客行为预测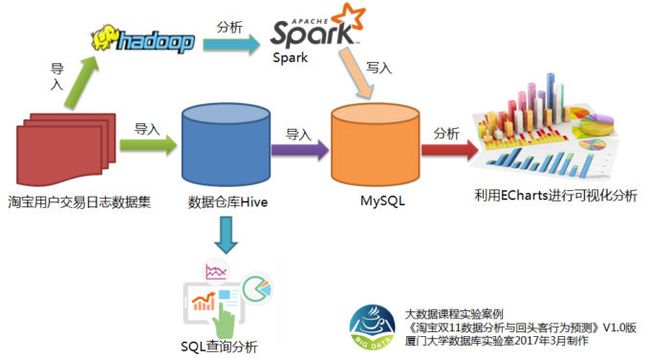
一、本地数据集上传到数据仓库Hive
实验数据集的下载
本案例采用的数据集压缩包为data_format.zip(点击这里下载data_format.zip数据集),该数据集压缩包是淘宝2015年双11前6个月(包含双11)的交易数据(交易数据有偏移,但是不影响实验的结果),里面包含3个文件,分别是用户行为日志文件user_log.csv 、回头客训练集train.csv 、回头客测试集test.csv. 下面列出这3个文件的数据格式定义:
用户行为日志user_log.csv,日志中的字段定义如下:
- user_id | 买家id
- item_id | 商品id
- cat_id | 商品类别id
- merchant_id | 卖家id
- brand_id | 品牌id
- month | 交易时间:月
- day | 交易事件:日
- action | 行为,取值范围{0,1,2,3},0表示点击,1表示加入购物车,2表示购买,3表示关注商品
- age_range | 买家年龄分段:1表示年龄<18,2表示年龄在[18,24],3表示年龄在[25,29],4表示年龄在[30,34],5表示年龄在[35,39],6表示年龄在[40,49],7和8表示年龄>=50,0和NULL则表示未知
- gender | 性别:0表示女性,1表示男性,2和NULL表示未知
- province| 收获地址省份
回头客训练集train.csv和回头客测试集test.csv,训练集和测试集拥有相同的字段,字段定义如下:
user_id | 买家id
age_range | 买家年龄分段:1表示年龄<18,2表示年龄在[18,24],3表示年龄在[25,29],4表示年龄在[30,34],5表示年龄在[35,39],6表示年龄在[40,49],7和8表示年龄>=50,0和NULL则表示未知
gender | 性别:0表示女性,1表示男性,2和NULL表示未知
merchant_id | 商家id
label | 是否是回头客,0值表示不是回头客,1值表示回头客,-1值表示该用户已经超出我们所需要考虑的预测范围。NULL值只存在测试集,在测试集中表示需要预测的值。
现在,下面需要把data_format.zip进行解压缩,我们需要首先建立一个用于运行本案例的目录dbtaobao,请执行以下命令:
cd /usr/local
ls
sudo mkdir dbtaobao
//这里会提示你输入当前用户(本教程是hadoop用户名)的密码
//下面给hadoop用户赋予针对dbtaobao目录的各种操作权限
sudo chown -R hadoop:hadoop ./dbtaobao
cd dbtaobao
//下面创建一个dataset目录,用于保存数据集
mkdir dataset
//下面就可以解压缩data_format.zip文件
unzip data_format.zip -d /usr/local/dbtaobao/dataset
cd /usr/local/dbtaobao/dataset
ls现在你就可以看到在dataset目录下有三个文件:test.csv、train.csv、user_log.csv
我们执行下面命令取出user_log.csv前面5条记录看一下
执行如下命令:
head -5 user_log.csv可以看到,前5行记录如下:
user_id,item_id,cat_id,merchant_id,brand_id,month,day,action,age_range,gender,province
328862,323294,833,2882,2661,08,29,0,0,1,内蒙古
328862,844400,1271,2882,2661,08,29,0,1,1,山西
328862,575153,1271,2882,2661,08,29,0,2,1,山西
328862,996875,1271,2882,2661,08,29,0,1,1,内蒙古
数据集的预处理
1.删除文件第一行记录,即字段名称
user_log.csv的第一行都是字段名称,我们在文件中的数据导入到数据仓库Hive中时,不需要第一行字段名称,因此,这里在做数据预处理时,删除第一行
cd /usr/local/dbtaobao/dataset
//下面删除user_log.csv中的第1行
sed -i '1d' user_log.csv //1d表示删除第1行,同理,3d表示删除第3行,nd表示删除第n行
//下面再用head命令去查看文件的前5行记录,就看不到字段名称这一行了
head -5 user_log.csv2.获取数据集中双11的前100000条数据
由于数据集中交易数据太大,这里只截取数据集中在双11的前10000条交易数据作为小数据集small_user_log.csv
下面我们建立一个脚本文件完成上面截取任务,请把这个脚本文件放在dataset目录下和数据集user_log.csv:
cd /usr/local/dbtaobao/dataset
vim predeal.sh上面使用vim编辑器新建了一个predeal.sh脚本文件,请在这个脚本文件中加入下面代码:
#!/bin/bash
#下面设置输入文件,把用户执行predeal.sh命令时提供的第一个参数作为输入文件名称
infile=$1
#下面设置输出文件,把用户执行predeal.sh命令时提供的第二个参数作为输出文件名称
outfile=$2
#注意!!最后的$infile > $outfile必须跟在}’这两个字符的后面
awk -F "," 'BEGIN{
id=0;
}
{
if($6==11 && $7==11){
id=id+1;
print $1","$2","$3","$4","$5","$6","$7","$8","$9","$10","$11
if(id==10000){
exit
}
}
}' $infile > $outfile下面就可以执行predeal.sh脚本文件,截取数据集中在双11的前10000条交易数据作为小数据集small_user_log.csv,命令如下:
chmod +x ./predeal.sh
./predeal.sh ./user_log.csv ./small_user_log.csv3.导入数据库
下面要把small_user_log.csv中的数据最终导入到数据仓库Hive中。为了完成这个操作,我们会首先把这个文件上传到分布式文件系统HDFS中,然后,在Hive中创建两个个外部表,完成数据的导入。
a.启动HDFS
下面,请登录Linux系统,打开一个终端,执行下面命令启动Hadoop:
cd /usr/local/hadoop
./sbin/start-dfs.sh然后,执行jps命令看一下当前运行的进程:
jps如果出现下面这些进程,说明Hadoop启动成功了。
3765 NodeManager
3639 ResourceManager
3800 Jps
3261 DataNode
3134 NameNode
3471 SecondaryNameNode
b.把user_log.csv上传到HDFS中
现在,我们要把Linux本地文件系统中的user_log.csv上传到分布式文件系统HDFS中,存放在HDFS中的“/dbtaobao/dataset”目录下。
首先,请执行下面命令,在HDFS的根目录下面创建一个新的目录dbtaobao,并在这个目录下创建一个子目录dataset,如下:
cd /usr/local/hadoop
./bin/hdfs dfs -mkdir -p /dbtaobao/dataset/user_log然后,把Linux本地文件系统中的small_user_log.csv上传到分布式文件系统HDFS的“/dbtaobao/dataset”目录下,命令如下:
./bin/hdfs dfs -put /usr/local/dbtaobao/dataset/small_user_log.csv /dbtaobao/dataset/user_log下面可以查看一下HDFS中的small_user_log.csv的前10条记录,命令如下:
./bin/hdfs dfs -cat /dbtaobao/dataset/user_log/small_user_log.csv | head -10c.在Hive上创建数据库
下面,请在Linux系统中,再新建一个终端(可以在刚才已经建好的终端界面的左上角,点击“终端”菜单,在弹出的子菜单中选择“新建终端”)。因为需要借助于MySQL保存Hive的元数据,所以,请首先启动MySQL数据库:
service mysql start #可以在Linux的任何目录下执行该命令由于Hive是基于Hadoop的数据仓库,使用HiveQL语言撰写的查询语句,最终都会被Hive自动解析成MapReduce任务由Hadoop去具体执行,因此,需要启动Hadoop,然后再启动Hive。由于前面我们已经启动了Hadoop,所以,这里不需要再次启动Hadoop。下面,在这个新的终端中执行下面命令进入Hive:
cd /usr/local/hive
./bin/hive # 启动Hive启动成功以后,就进入了“hive>”命令提示符状态,可以输入类似SQL语句的HiveQL语句。
下面,我们要在Hive中创建一个数据库dbtaobao,命令如下:
hive> create database dbtaobao;
hive> use dbtaobao;d.创建外部表
关于数据仓库Hive的内部表和外部表的区别,请访问网络文章《Hive内部表与外部表的区别》。本教程采用外部表方式。
这里我们要分别在数据库dbtaobao中创建一个外部表user_log,它包含字段(user_id,item_id,cat_id,merchant_id,brand_id,month,day,action,age_range,gender,province),请在hive命令提示符下输入如下命令:
hive> CREATE EXTERNAL TABLE dbtaobao.user_log(user_id INT,item_id INT,cat_id INT,merchant_id INT,brand_id INT,month STRING,day STRING,action INT,age_range INT,gender INT,province STRING) COMMENT 'Welcome to xmu dblab,Now create dbtaobao.user_log!' ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE LOCATION '/dbtaobao/dataset/user_log';e.查询数据
上面已经成功把HDFS中的“/dbtaobao/dataset/user_log”目录下的small_user_log.csv数据加载到了数据仓库Hive中,我们现在可以使用下面命令查询一下:
hive> select * from user_log limit 10;步骤一的实验顺利结束, 会看到如下数据。
OK
328862 406349 1280 2700 5476 11 11 0 0 1 四川
328862 406349 1280 2700 5476 11 11 0 7 1 重庆市
328862 807126 1181 1963 6109 11 11 0 1 0 上海市
328862 406349 1280 2700 5476 11 11 2 6 0 台湾
328862 406349 1280 2700 5476 11 11 0 6 2 甘肃
328862 406349 1280 2700 5476 11 11 0 4 1 甘肃
328862 406349 1280 2700 5476 11 11 0 5 0 浙江
328862 406349 1280 2700 5476 11 11 0 3 2 澳门
328862 406349 1280 2700 5476 11 11 0 7 1 台湾
234512 399860 962 305 6300 11 11 0 4 1 安徽
Time taken: 1.775 seconds, Fetched: 10 row(s)二、Hive数据分析
在“hive>”命令提示符状态下执行下面命令:
hive> use dbtaobao; -- 使用dbtaobao数据库
hive> show tables; -- 显示数据库中所有表。
hive> show create table user_log; -- 查看user_log表的各种属性;执行结果如下:
OK
CREATE EXTERNAL TABLE `user_log`(
`user_id` int,
`item_id` int,
`cat_id` int,
`merchant_id` int,
`brand_id` int,
`month` string,
`day` string,
`action` int,
`age_range` int,
`gender` int,
`province` string)
COMMENT 'Welcome to xmu dblab,Now create dbtaobao.user_log!'
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'field.delim'=',',
'serialization.format'=',')
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://localhost:9000/dbtaobao/dataset/user_log'
TBLPROPERTIES (
'numFiles'='1',
'totalSize'='4729522',
'transient_lastDdlTime'='1487902650')
Time taken: 0.084 seconds, Fetched: 28 row(s)可以执行下面命令查看表的简单结构:
hive> desc user_log;二、简单查询分析
先测试一下简单的指令:
hive> select brand_id from user_log limit 10; -- 查看日志前10个交易日志的商品品牌如果要查出每位用户购买商品时的多种信息,输出语句格式为 select 列1,列2,….,列n from 表名;
比如我们现在查询前20个交易日志中购买商品时的时间和商品的种类
hive> select month,day,cat_id from user_log limit 20;有时我们在表中查询可以利用嵌套语句,如果列名太复杂可以设置该列的别名,以简化我们操作的难度,以下我们可以举个例子:
hive> select ul.at, ul.ci from (select action as at, cat_id as ci from user_log) as ul limit 20;这里简单的做个讲解,action as at ,cat_id as ci就是把action 设置别名 at ,cat_id 设置别名 ci,FROM的括号里的内容我们也设置了别名ul,这样调用时用ul.at,ul.ci,可以简化代码。
三、查询条数统计分析
经过简单的查询后我们同样也可以在select后加入更多的条件对表进行查询,下面可以用函数来查找我们想要的内容。
(1)用聚合函数count()计算出表内有多少条行数据
hive> select count(*) from user_log; -- 用聚合函数count()计算出表内有多少条行数据执行结果如下:
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
Query ID = hadoop_20180422041924_371ea6b0-cfb1-492b-b11c-a2ba28f7dcf0
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=
In order to set a constant number of reducers:
set mapreduce.job.reduces=
Job running in-process (local Hadoop)
2018-04-22 04:19:26,494 Stage-1 map = 100%, reduce = 100%
Ended Job = job_local493578924_0001
MapReduce Jobs Launched:
Stage-Stage-1: HDFS Read: 1004134 HDFS Write: 0 SUCCESS
Total MapReduce CPU Time Spent: 0 msec
OK
10000
Time taken: 2.381 seconds, Fetched: 1 row(s) 我们可以看到,得出的结果为OK下的那个数字10000
(2)在函数内部加上distinct,查出uid不重复的数据有多少条
下面继续执行操作:
hive> select count(distinct user_id) from user_log; -- 在函数内部加上distinct,查出user_id不重复的数据有多少条(3)查询不重复的数据有多少条(为了排除客户刷单情况) **
hive> select count(*) from (select user_id,item_id,cat_id,merchant_id,brand_id,month,day,action from user_log group by user_id,item_id,cat_id,merchant_id,brand_id,month,day,action having count(*)=1)a;可以看出,排除掉重复信息以后,只有4754条记录。
注意:嵌套语句最好取别名,就是上面的a,否则很容易出现如下错误.
四.关键字条件查询分析
1.以关键字的存在区间为条件的查询
使用where可以缩小查询分析的范围和精确度,下面用实例来测试一下。
(1)查询双11那天有多少人购买了商品
hive> select count(distinct user_id) from user_log where action='2';2.关键字赋予给定值为条件,对其他数据进行分析
取给定时间和给定品牌,求当天购买的此品牌商品的数量
hive> select count(*) from user_log where action='2' and brand_id=2661;五.根据用户行为分析
从现在开始,我们只给出查询语句,将不再给出执行结果。
1.查询一件商品在某天的购买比例或浏览比例
hive> select count(distinct user_id) from user_log where action='2'; -- 查询有多少用户在双11购买了商品hive> select count(distinct user_id) from user_log; -- 查询有多少用户在双11点击了该店根据上面语句得到购买数量和点击数量,两个数相除即可得出当天该商品的购买率。
2.查询双11那天,男女买家购买商品的比例
hive> select count(*) from user_log where gender=0; --查询双11那天女性购买商品的数量
hive> select count(*) from user_log where gender=1; --查询双11那天男性购买商品的数量上面两条语句的结果相除,就得到了要要求的比例。
3.给定购买商品的数量范围,查询某一天在该网站的购买该数量商品的用户id
hive> select user_id from user_log where action='2' group by user_id having count(action='2')>5; -- 查询某一天在该网站购买商品超过5次的用户id六.用户实时查询分析
不同的品牌的浏览次数
hive> create table scan(brand_id INT,scan INT) COMMENT 'This is the search of bigdatataobao' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE; -- 创建新的数据表进行存储
hive> insert overwrite table scan select brand_id,count(action) from user_log where action='2' group by brand_id; --导入数据
hive> select * from scan; -- 显示结果三、将数据从Hive导入到MySQL
Hive预操
然后,在“hive>”命令提示符状态下执行下面命令:
1、创建临时表inner_user_log和inner_user_info
hive> create table dbtaobao.inner_user_log(user_id INT,item_id INT,cat_id INT,merchant_id INT,brand_id INT,month STRING,day STRING,action INT,age_range INT,gender INT,province STRING) COMMENT 'Welcome to XMU dblab! Now create inner table inner_user_log ' ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE;这个命令执行完以后,Hive会自动在HDFS文件系统中创建对应的数据文件“/user/hive/warehouse/dbtaobao.db/inner_user_log”。
2、将user_log表中的数据插入到inner_user_log,
在[大数据案例-步骤一:本地数据集上传到数据仓库Hive(待续)]中,我们已经在Hive中的dbtaobao数据库中创建了一个外部表user_log。下面把dbtaobao.user_log数据插入到dbtaobao.inner_user_log表中,命令如下:
hive> INSERT OVERWRITE TABLE dbtaobao.inner_user_log select * from dbtaobao.user_log;使用Sqoop将数据从Hive导入MySQL
1、将前面生成的临时表数据从Hive导入到 MySQL 中,包含如下四个步骤。
(1)登录 MySQL
请在Linux系统中新建一个终端,执行下面命令:
mysql -u root -p为了简化操作,本教程直接使用root用户登录MySQL数据库,但是,在实际应用中,建议在MySQL中再另外创建一个用户。
执行上面命令以后,就进入了“mysql>”命令提示符状态。
(2)创建数据库
mysql> show databases; #显示所有数据库
mysql> create database dbtaobao; #创建dbtaobao数据库
mysql> use dbtaobao; #使用数据库注意:请使用下面命令查看数据库的编码:
mysql> show variables like "char%";请确认当前编码为utf8,否则无法导入中文,请参考Ubuntu安装MySQL及常用操作修改编码。
(3)创建表
下面在MySQL的数据库dbtaobao中创建一个新表user_log,并设置其编码为utf-8:
mysql> CREATE TABLE `dbtaobao`.`user_log` (`user_id` varchar(20),`item_id` varchar(20),`cat_id` varchar(20),`merchant_id` varchar(20),`brand_id` varchar(20), `month` varchar(6),`day` varchar(6),`action` varchar(6),`age_range` varchar(6),`gender` varchar(6),`province` varchar(10)) ENGINE=InnoDB DEFAULT CHARSET=utf8;提示:语句中的引号是反引号`,不是单引号’。需要注意的是,sqoop抓数据的时候会把类型转为string类型,所以mysql设计字段的时候,设置为varchar。
创建成功后,输入下面命令退出MySQL:
mysql> exit;(4)导入数据
注意,刚才已经退出MySQL,回到了Shell命令提示符状态。下面就可以执行数据导入操作,
cd /usr/local/sqoop
bin/sqoop export --connect jdbc:mysql://localhost:3306/dbtaobao --username root --password root --table user_log --export-dir '/user/hive/warehouse/dbtaobao.db/inner_user_log' --fields-terminated-by ',';字段解释:
./bin/sqoop export ##表示数据从 hive 复制到 mysql 中
–connect jdbc:mysql://localhost:3306/dbtaobao
–username root #mysql登陆用户名
–password root #登录密码
–table user_log #mysql 中的表,即将被导入的表名称
–export-dir ‘/user/hive/warehouse/dbtaobao.db/user_log ‘ #hive 中被导出的文件
–fields-terminated-by ‘,’ #Hive 中被导出的文件字段的分隔符
3、查看MySQL中user_log或user_info表中的数据
下面需要再次启动MySQL,进入“mysql>”命令提示符状态:
mysql -u root -p会提示你输入MySQL的root用户的密码,本教程中安装的MySQL数据库的root用户的密码是hadoop。
然后执行下面命令查询user_action表中的数据:
mysql> use dbtaobao;
mysql> select * from user_log limit 10;从Hive导入数据到MySQL中,成功!
四、利用Spark预测回头客行为
预处理test.csv和train.csv数据集
这里需要预先处理test.csv数据集,把这test.csv数据集里label字段表示-1值剔除掉,保留需要预测的数据.并假设需要预测的数据中label字段均为1.
cd /usr/local/dbtaobao/dataset
vim predeal_test.sh上面使用vim编辑器新建了一个predeal_test.sh脚本文件,请在这个脚本文件中加入下面代码:
#!/bin/bash
#下面设置输入文件,把用户执行predeal_test.sh命令时提供的第一个参数作为输入文件名称
infile=$1
#下面设置输出文件,把用户执行predeal_test.sh命令时提供的第二个参数作为输出文件名称
outfile=$2
#注意!!最后的$infile > $outfile必须跟在}’这两个字符的后面
awk -F "," 'BEGIN{
id=0;
}
{
if($1 && $2 && $3 && $4 && !$5){
id=id+1;
print $1","$2","$3","$4","1
if(id==10000){
exit
}
}
}' $infile > $outfile下面就可以执行predeal_test.sh脚本文件,截取测试数据集需要预测的数据到test_after.csv,命令如下:
chmod +x ./predeal_test.sh
./predeal_test.sh ./test.csv ./test_after.csvtrain.csv的第一行都是字段名称,不需要第一行字段名称,这里在对train.csv做数据预处理时,删除第一行
sed -i '1d' train.csv然后剔除掉train.csv中字段值部分字段值为空的数据。
vim predeal_train.sh上面使用vim编辑器新建了一个predeal_train.sh脚本文件,请在这个脚本文件中加入下面代码:
#!/bin/bash
#下面设置输入文件,把用户执行predeal_train.sh命令时提供的第一个参数作为输入文件名称
infile=$1
#下面设置输出文件,把用户执行predeal_train.sh命令时提供的第二个参数作为输出文件名称
outfile=$2
#注意!!最后的$infile > $outfile必须跟在}’这两个字符的后面
awk -F "," 'BEGIN{
id=0;
}
{
if($1 && $2 && $3 && $4 && ($5!=-1)){
id=id+1;
print $1","$2","$3","$4","$5
if(id==10000){
exit
}
}
}' $infile > $outfile下面就可以执行predeal_train.sh脚本文件,截取测试数据集需要预测的数据到train_after.csv,命令如下:
chmod +x ./predeal_train.sh
./predeal_train.sh ./train.csv ./train_after.csv预测回头客
将两个数据集分别存取到HDFS中
cd /usr/local/hadoop/
bin/hadoop fs -mkdir -p /dbtaobao/dataset
bin/hadoop fs -put /usr/local/dbtaobao/dataset/train_after.csv /dbtaobao/dataset
bin/hadoop fs -put /usr/local/dbtaobao/dataset/test_after.csv /dbtaobao/dataset你就可以进入“mysql>”命令提示符状态,然后就可以输入下面的SQL语句完成表的创建:
use dbtaobao;
create table rebuy (score varchar(40),label varchar(40));启动Spark Shell
Spark支持通过JDBC方式连接到其他数据库获取数据生成DataFrame。
下载MySQL的JDBC驱动(mysql-connector-java-5.1.40.zip)
mysql-connector-java-*.zip是Java连接MySQL的驱动包,默认会下载到”~/下载/”目录
执行如下命令:
cd /usr/local/spark/spark-2.3.0-bin-hadoop2.7
./bin/spark-shell --jars /usr/local/spark/spark-2.3.0-bin-hadoop2.7/jars/mysql-connector-java-5.1.46-bin.jar --driver-class-path /usr/local/spark/spark-2.3.0-bin-hadoop2.7/jars/mysql-connector-java-5.1.46-bin.jar支持向量机SVM分类器预测回头客
这里使用Spark MLlib自带的支持向量机SVM分类器进行预测回头客,有关更多Spark MLlib中SVM分类器的学习知识,请点击大数据-10-Spark入门之支持向量机SVM分类器。
在spark-shell中执行如下操作:
1.导入需要的包
首先,我们导入需要的包:
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.mllib.regression.LabeledPoint
import org.apache.spark.mllib.linalg.{Vectors,Vector}
import org.apache.spark.mllib.classification.{SVMModel, SVMWithSGD}
import org.apache.spark.mllib.evaluation.BinaryClassificationMetrics
import java.util.Properties
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row2.读取训练数据
首先,读取训练文本文件;然后,通过map将每行的数据用“,”隔开,在数据集中,每行被分成了5部分,前4部分是用户交易的3个特征(age_range,gender,merchant_id),最后一部分是用户交易的分类(label)。把这里我们用LabeledPoint来存储标签列和特征列。LabeledPoint在监督学习中常用来存储标签和特征,其中要求标签的类型是double,特征的类型是Vector。
val train_data = sc.textFile("/dbtaobao/dataset/train_after.csv")
val test_data = sc.textFile("/dbtaobao/dataset/test_after.csv")3.构建模型
val train= train_data.map{line =>
val parts = line.split(',')
LabeledPoint(parts(4).toDouble,Vectors.dense(parts(1).toDouble,parts
(2).toDouble,parts(3).toDouble))
}
val test = test_data.map{line =>
val parts = line.split(',')
LabeledPoint(parts(4).toDouble,Vectors.dense(parts(1).toDouble,parts(2).toDouble,parts(3).toDouble))
}接下来,通过训练集构建模型SVMWithSGD。这里的SGD即著名的随机梯度下降算法(Stochastic Gradient Descent)。设置迭代次数为1000,除此之外还有stepSize(迭代步伐大小),regParam(regularization正则化控制参数),miniBatchFraction(每次迭代参与计算的样本比例),initialWeights(weight向量初始值)等参数可以进行设置。
val numIterations = 1000
val model = SVMWithSGD.train(train, numIterations)4.评估模型
接下来,我们清除默认阈值,这样会输出原始的预测评分,即带有确信度的结果。
model.clearThreshold()
val scoreAndLabels = test.map{point =>
val score = model.predict(point.features)
score+" "+point.label
}
scoreAndLabels.foreach(println)spark-shell会打印出结果。
如果我们设定了阀值,则会把大于阈值的结果当成正预测,小于阈值的结果当成负预测。
model.setThreshold(0.0)
scoreAndLabels.foreach(println)- 把结果添加到mysql数据库中
现在我们上面没有设定阀值的测试集结果存入到MySQL数据中。
model.clearThreshold()
val scoreAndLabels = test.map{point =>
val score = model.predict(point.features)
score+" "+point.label
}
//设置回头客数据
val rebuyRDD = scoreAndLabels.map(_.split(" "))
// 下面要设置模式信息
val schema = StructType(List(StructField("score", StringType, true),StructField("label", StringType, true)))
//下面创建Row对象,每个Row对象都是rowRDD中的一行
val rowRDD = rebuyRDD.map(p => Row(p(0).trim, p(1).trim))
//建立起Row对象和模式之间的对应关系,也就是把数据和模式对应起来
val rebuyDF = spark.createDataFrame(rowRDD, schema)
//下面创建一个prop变量用来保存JDBC连接参数
val prop = new Properties()
prop.put("user", "root") //表示用户名是root
prop.put("password", "root") //表示密码是hadoop
prop.put("driver","com.mysql.jdbc.Driver") //表示驱动程序是com.mysql.jdbc.Driver
//下面就可以连接数据库,采用append模式,表示追加记录到数据库dbtaobao的rebuy表中
rebuyDF.write.mode("append").jdbc("jdbc:mysql://localhost:3306/dbtaobao", "dbtaobao.rebuy", prop)五、利用ECharts进行数据可视化分析
ECharts是一个纯 Javascript 的图表库,可以流畅的运行在 PC 和移动设备上,兼容当前绝大部分浏览器(IE8/9/10/11,Chrome,Firefox,Safari等),提供直观,生动,可交互,可高度个性化定制的数据可视化图表。下面将通过Web网页浏览器可视化分析淘宝双11数据。
由于ECharts是运行在网页前端,我们选用JSP作为服务端语言,读取MySQL中的数据,然后渲染到前端页面。使用Web应用服务器:tomcat和Intellij idea来作开发。
搭建tomcat+mysql+JSP开发环境
Tomcat 服务器是一个免费的开放源代码的Web 应用服务器,属于轻量级应用服务器,在中小型系统和并发访问用户不是很多的场合下被普遍使用,是开发和调试JSP 程序的首选。
查看Linux系统的Java版本,执行如下命令:
java -version结果如下:
openjdk version "1.8.0_162"
OpenJDK Runtime Environment (build 1.8.0_162-8u162-b12-0ubuntu0.16.04.2-b12)
OpenJDK 64-Bit Server VM (build 25.162-b12, mixed mode)可以看出Linux系统中的Java版本是1.8版本,那么下载的tomcat也要对应Java的版本。这里下载apache-tomcat-8.0.41.zip。
解压apache-tomcat-8.0.41.zip到用户目录~下,执行如下命令:
unzip apache-tomcat-8.0.41.zip -d ~利用Intellij idea 新建可视化Web应用
1.打开idea,点击“File”菜单,或者通过工具栏的“New Project”创建 Web Application,弹出向导对话框,并点击”Next”,如下图所示: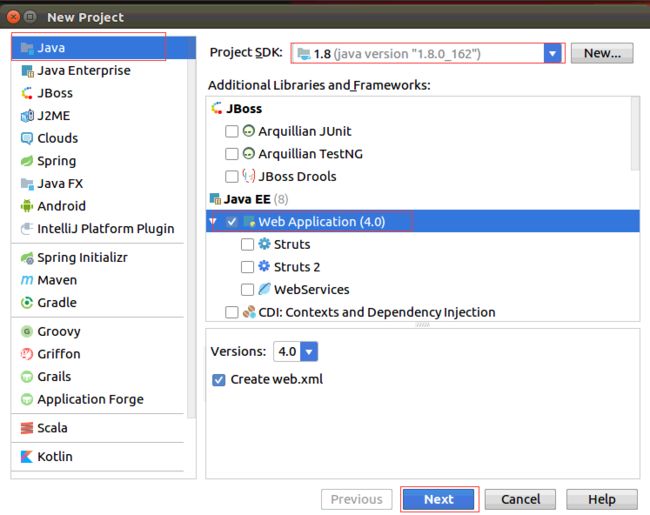
输入项目名字MyWebApp, 点击finish创建项目。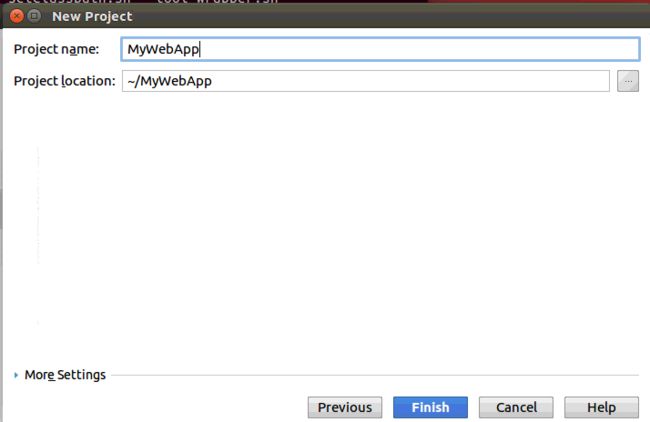
然后,我们要作项目的运行配置, 在菜单"Run"下,选择"Edit Configuration"后,显示出如下图所示,并作相应选择:
选择+号来加添加配置,并命名为tomcat_1。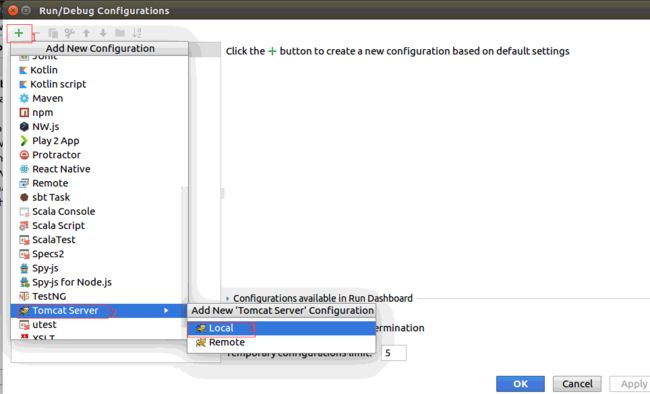
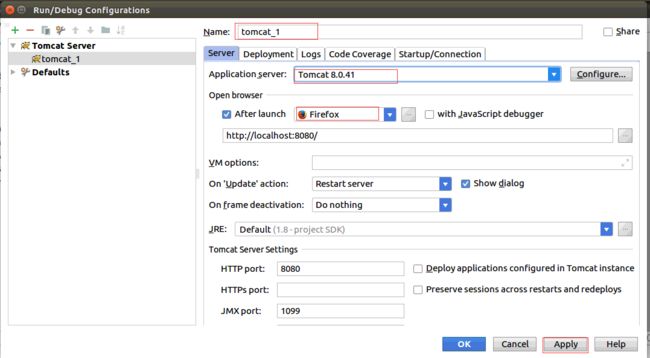
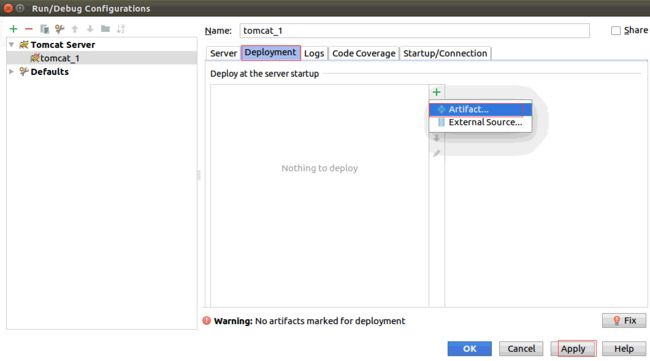
最后,点击运行就OK了:
如果,未运行成功,出现权限错误,如下所示 :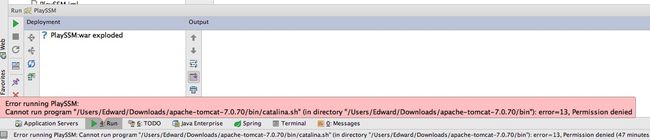
打开Terminal,找到catalina.sh所在的文件夹下;
输入chmod a+x catalina.sh即可
我的Idea 代码MyWebApp, 下载密码:zvtv
重要代码解析
服务端代码解析
整个项目,Java后端从数据库中查询的代码都集中在项目文件夹下/Java src/dbtaobao/connDb.java
代码如下:
package dbtaobao;
import java.sql.*;
import java.util.ArrayList;
public class connDb {
private static Connection con = null;
private static Statement stmt = null;
private static ResultSet rs = null;
//连接数据库方法
public static void startConn(){
try{
Class.forName("com.mysql.jdbc.Driver");
//连接数据库中间件
try{
con = DriverManager.getConnection("jdbc:MySQL://localhost:3306/dbtaobao","root","root");
}catch(SQLException e){
e.printStackTrace();
}
}catch(ClassNotFoundException e){
e.printStackTrace();
}
}
//关闭连接数据库方法
public static void endConn() throws SQLException{
if(con != null){
con.close();
con = null;
}
if(rs != null){
rs.close();
rs = null;
}
if(stmt != null){
stmt.close();
stmt = null;
}
}
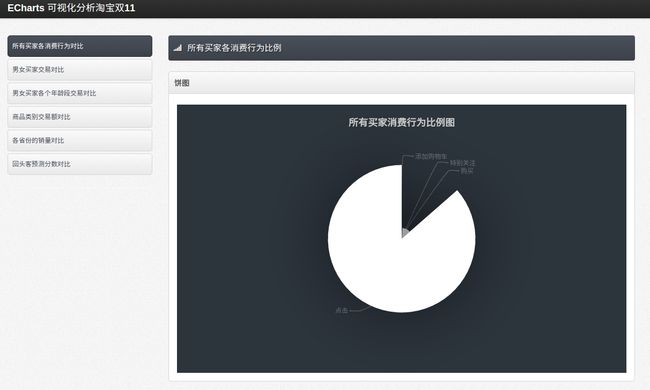
//数据库双11 所有买家消费行为比例
public static ArrayList index() throws SQLException{
ArrayList list = new ArrayList();
startConn();
stmt = con.createStatement();
rs = stmt.executeQuery("select action,count(*) num from user_log group by action desc");
while(rs.next()){
String[] temp={rs.getString("action"),rs.getString("num")};
list.add(temp);
}
endConn();
return list;
}
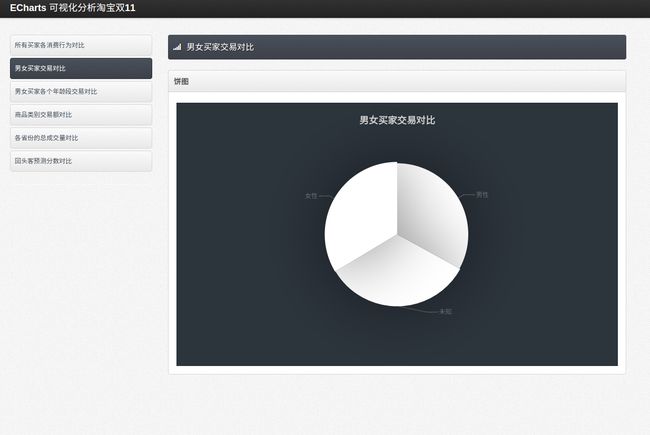
//男女买家交易对比
public static ArrayList index_1() throws SQLException{
ArrayList list = new ArrayList();
startConn();
stmt = con.createStatement();
rs = stmt.executeQuery("select gender,count(*) num from user_log group by gender desc");
while(rs.next()){
String[] temp={rs.getString("gender"),rs.getString("num")};
list.add(temp);
}
endConn();
return list;
}
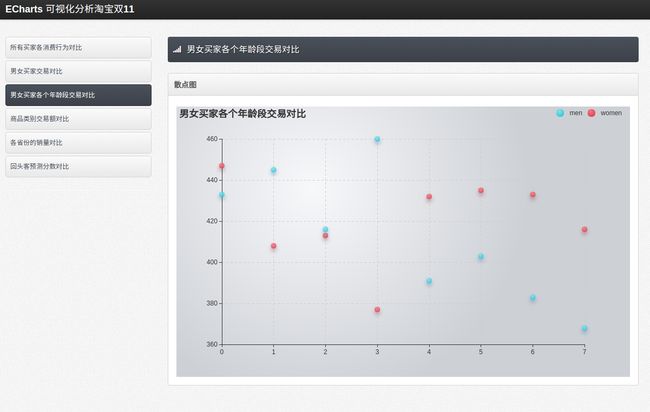
//男女买家各个年龄段交易对比
public static ArrayList index_2() throws SQLException{
ArrayList list = new ArrayList();
startConn();
stmt = con.createStatement();
rs = stmt.executeQuery("select gender,age_range,count(*) num from user_log group by gender,age_range desc");
while(rs.next()){
String[] temp={rs.getString("gender"),rs.getString("age_range"),rs.getString("num")};
list.add(temp);
}
endConn();
return list;
}
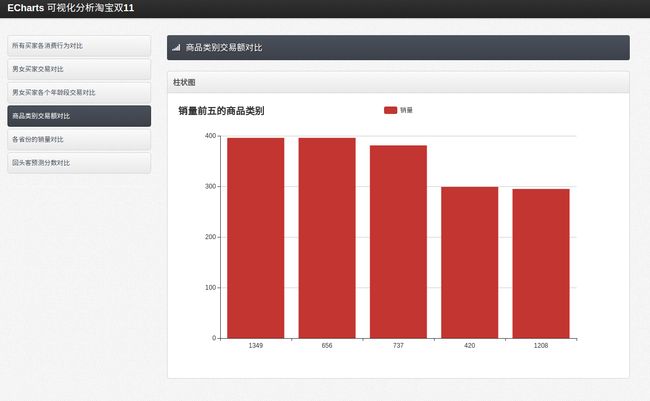
//获取销量前五的商品类别
public static ArrayList index_3() throws SQLException{
ArrayList list = new ArrayList();
startConn();
stmt = con.createStatement();
rs = stmt.executeQuery("select cat_id,count(*) num from user_log group by cat_id order by count(*) desc limit 5");
while(rs.next()){
String[] temp={rs.getString("cat_id"),rs.getString("num")};
list.add(temp);
}
endConn();
return list;
}
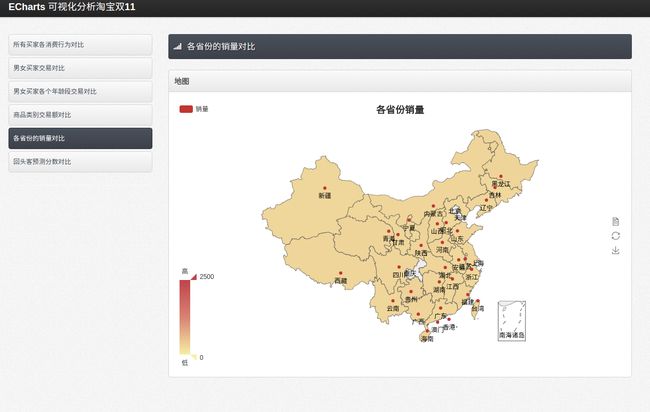
//各个省份的总成交量对比
public static ArrayList index_4() throws SQLException{
ArrayList list = new ArrayList();
startConn();
stmt = con.createStatement();
rs = stmt.executeQuery("select province,count(*) num from user_log group by province order by count(*) desc");
while(rs.next()){
String[] temp={rs.getString("province"),rs.getString("num")};
list.add(temp);
}
endConn();
return list;
}
} 前端代码解析
前端页面想要获取服务端的数据,还需要导入相关的包,例如:/WebContent/index.jsp部分代码如下:
<%@ page language="java" import="dbtaobao.connDb,java.util.*" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"%>
<%
ArrayList list = connDb.index();
%> 前端JSP页面使用ECharts来展现可视化。每个JSP页面都需要导入相关ECharts.js文件,如需要中国地图的可视化,还需要另外导入china.js文件。
那么如何使用ECharts的可视化逻辑代码,我们在每个jsp的底部编写可视化逻辑代码。这里展示index.jsp中可视化逻辑代码:
ECharts包含各种各样的可视化图形,每种图形的逻辑代码,请参考ECharts官方示例代码,请读者自己参考index.jsp中的代码,再根据ECharts官方示例代码,自行完成其他可视化比较。
页面效果
注意:由于ECharts更新,提供下载的中国矢量地图数据来自第三方,由于部分数据不符合国家《测绘法》规定,目前暂时停止下载服务。
最终,我自己使用饼图,散点图,柱状图,地图等完成了如下效果,读者如果觉得有更适合的可视化图形,也可以自己另行修改。
最后展示所有页面的效果图: