大数据技术原理与应用:期末考点总结
个人期末复习材料,根据林子雨的大数据技术教材与其它资料整理。
目录
-
- 第一章 大数据概述
- 第二章 Hadoop
- 第三章 HDFS
- 第四章 HBase
- 第五章 NoSQL
- 第六章 云数据库
- 第七章 MapReduce
- 第八章 Hadoop 2.x
- 第九章 Spark
- 第十章 流计算
第一章 大数据概述
1.大数据的4v特征
- 数据量大 volume
- 价值密度低 value
- 数据类型繁多 variety
- 处理速度快 velocity
2.大数据3种思维方式的转变
在思维方式方面,大数据完全颠覆了传统的思维方式:
-
全样而非抽样
-
效率而非精确
-
相关而非因果
3.大数据两大核心技术
分布式存储和分布式处理

4.大数据计算模式及其代表产品
| 大数据计算模式 | 解决问题 | 代表产品 |
|---|---|---|
| 批处理计算 | 针对大规模数据的批量处理 | MapReduce、Spark等 |
| 流计算 | 针对流数据的实时计算 | Storm、S4、Flume、Streams、Puma、DStream、Super Mario、银河流数据处理平台等 |
| 图计算 | 针对大规模图结构数据的处理 | Pregel、GraphX、Giraph、PowerGraph、Hama、GoldenOrb等 |
| 查询分析计算 | 大规模数据的存储管理和查询分析 | Dremel、Hive、Cassandra、Impala等 |
5.大数据、云计算与物联网之间的区别和联系

第二章 Hadoop
Hadoop面试题 http://www.dajiangtai.com/community/18456.do
1.Hadoop的发展历史
2002年,Hadoop起源于Doug Cutting开发Apache Nutch网络搜索引擎项目。
2004年,Nutch项目也模仿GFS开发了自己的分布式文件系统NDFS(Nutch Distributed File System),也就是HDFS的前身。
2004年,谷歌公司又发表了另一篇具有深远影响的论文《MapReduce:Simplified Data Processing on Large Clusters(Mapreduce:简化大规模集群上的数据处理)》,阐述了MapReduce分布式编程思想。
2005年,Doug Cutting等人开始尝试实现MapReduce计算框架,并将它与NDFS(Nutch Distributed File System)结合,用以支持Nutch引擎的主要算法,Nutch开源实现了谷歌的MapReduce。
2006年2月,由于NDFS和MapReduce在Nutch引擎中有着良好的应用,Nutch中的NDFS和MapReduce开始独立出来,成为Lucene项目的一个子项目,称为Hadoop,同时,Doug Cutting加盟雅虎。
2008年1月,Hadoop正式成为Apache顶级项目,包含众多子项目,Hadoop也逐渐开始被雅虎之外的其他公司使用。同年4月,Hadoop打破世界纪录,成为最快排序1TB数据的系统,它采用一个由910个节点构成的集群进行运算,排序时间只用了209秒。
在2009年5月,Hadoop更是把1TB数据排序时间缩短到62秒。Hadoop从此名声大震,迅速发展成为大数据时代最具影响力的开源分布式开发平台,并成为事实上的大数据处理标准。
2.Hadoop的特性
Hadoop以一种可靠、高效、可伸缩的方式进行处理的,它具有以下几个方面的特性:
- 高可靠性:多副本
- 高效性:并行工作
- 高可扩展性:方便扩展服务器
- 高容错性:失败的任务会重新分配
- 成本低:廉价的集群设备
- 运行在Linux平台上
- 支持多种编程语言
3.Hadoop的版本
Apache Hadoop版本分为两代,我们将第一代Hadoop称为Hadoop 1.0,第二代Hadoop称为Hadoop 2.0。
Hadoop 1.x 和Hadoop 2.x的区别:在1.x版本中,MapReduce负责逻辑运算和资源调度,耦合性比较大;2.x版本中新增了YARN,负责资源调度,这样MapReduce就只负责运算了。

4.Hadoop生态系统/项目结构
| 组件 | 功能 |
|---|---|
| HDFS | 分布式文件存储系统 |
| MapReduce | 分布式并行计算框架 |
| YARN | 资源调度管理框架 |
| HBase | 分布式非关系型数据库 |
| Hive | Hadoop上的数据仓库。提供HQL,将HQL语句转化为MapReduce程序 |
| Zookeeper | 提供分布式协调一致性服务 |
| Kafka | 高吞吐量的分布式发布/订阅消息系统 |
| Pig | 基于Hadoop的大数据分析平台,提供类似sql的查询语言Pig Latin。 |
| Flume | 日志采集框架 |
| Oozie | Hadoop上的作业流调度系统 |
| Spark | 分布式并行计算框架 |
| Sqoop | 数据传输框架,用于MySQL与HDFS之间的数据传递 |
| Storm | 流计算框架 |
5.配置文件中的参数
所有配置文件:

重点关注 hdfs-site.xml,core-site.xml
-
hdfs-site.xml
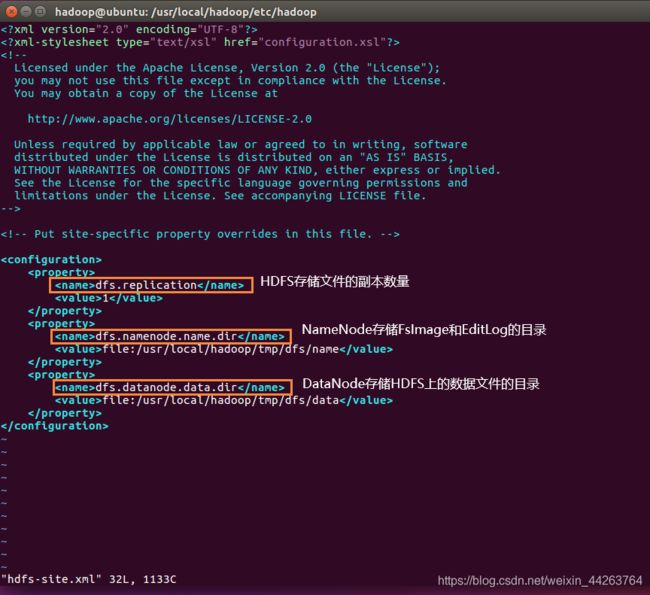
-
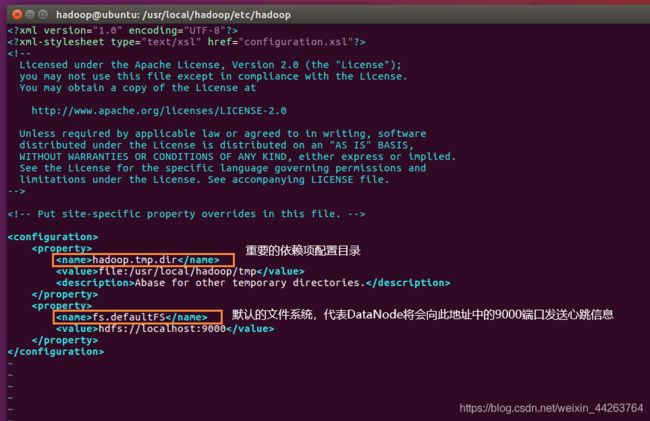
core-site.xml
hadoop.tmp.dir 是 hadoop文件系统依赖的基本配置,很多配置路径都依赖它,它的默认位置是在/tmp/{$user}下面,注意这是个临时目录。因此,它的持久化配置很重要的, 如果选择默认,一旦因为断电等外在因素影响,/tmp/{$user}下的所有东西都会丢失。
第三章 HDFS
1.分布式文件系统结构
主从结构:分布式文件系统在物理上是由诸多计算机节点组成的,这里计算机节点分为两类,一类叫主节点,一类叫从节点。
2.HDFS的目标
- 大数据集
- 流式数据读写
- 简单的文件模型
- 强大的跨平台兼容性
- 廉价的硬件设备
3.HDFS的局限性
-
不适合低延迟数据访问(不适合实时处理,io开销大)
-
无法高效存储大量小文件(文件块机制)
-
不支持多用户并发写入及任意修改文件(一个文件,同时只允许一个写入者对文件进行追加)
4.块 Block
块是HDFS中文件存储的基本单位,在Hadoop2.x中文件块大小默认为128MB,在1.x中默认为64MB。
HDFS采用抽象的块概念可以带来以下几个明显的好处:
- 支持大规模文件存储:文件以块为单位进行存储,一个大规模文件可以被分拆成若干个文件块,不同的文件块可以被分发到不同的节点上,因此,一个文件的大小不会受到单个节点的存储容量的限制,可以远远大于网络中任意节点的存储容量
- 简化系统设计(简化了文件和元数据的管理):首先,大大简化了存储管理,因为文件块大小是固定的,这样就可以很容易计算出一个节点可以存储多少文件块;其次,方便了元数据的管理,元数据不需要和文件块一起存储,可以由其他系统负责管理元数据
- 适合数据备份:每个文件块都可以冗余存储到多个节点上,大大提高了系统的容错性和可用性
5.HDFS体系结构
hdfs中采用了主-从结构模型,一个hdfs集群中包含1个namenode和若干个datanode。
- 名称节点 namenode
- 数据节点 datanode
- 客户端 client
6.NameNode 名称节点
namenode节点是整个hdfs集群的唯一的主节点,负责:
- 接收和回复客户的访问请求
- 存储文件系统的所有元数据(管理文件系统的命名空间)
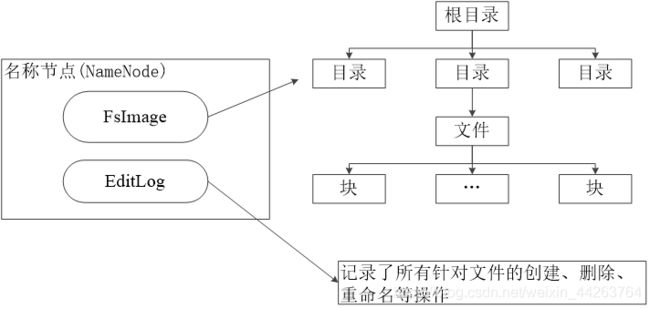
名称节点(NameNode)负责管理分布式文件系统的命名空间(Namespace),保存了两个核心的数据结构,即 FsImage 和 EditLog。
-
FsImage
命名空间镜像文件。FsImage 用于维护文件系统树以及文件树中所有的文件和目录的元数据,即包含文件系统中所有目录和文件inode的序列化形式。
-
EditLog
操作日志文件。EditLog 中记录了所有针对文件的创建、删除、重命名等操作。
启动过程(处于安全模式)
在名称节点启动的时候,第一次启动NameNode格式化后,创建Fsimage和Edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
它会将FsImage文件中的内容加载到内存中,之后再执行EditLog文件中的各项操作,使得内存中的元数据和实际的同步。
一旦在内存中成功建立文件系统元数据的映射,则创建一个新的FsImage文件和一个空的EditLog文件。
7.DataNode 数据节点
datanode节点是hdfs集群的工作节点,负责:
- 数据的存储:存储文件系统的数据文件,每个文件被分成多个数据块存储在不同节点上。
- 数据的读写:接收客户端的读写请求
- 定期向namenode发送心跳信息,若没有发送则被标记为宕机
- 在namenode的调度下进行对数据块的操作
8.元数据
存储的信息:hdfs中的元数据包含HDFS中文件的所有块和块的存储位置、修改和访问时间、访问权限、大小等信息。
存储的位置:元数据存储在NameNode节点的FsImage数据结构中,由它负责管理。
9.HDFS工作机制(上面都有提到过)
-
NameNode与SecondaryNameNode
(1)NN的启动过程
(2)采用SecondaryNameNode的原因
(3)SNN的工作机制
-
DataNode
存储文件、注册并接收与回复client读写请求、发送块列表、发送心跳信息
10.通信协议(了解)
HDFS中有5种通信协议,各个节点之间根据不同协议通过RPC (Remote Procedure Call) 进行交互。
11.HDFS冗余数据存储
HDFS对于同一个数据块会存储多个副本,默认为3个。且不同副本被分布到不同节点上。
保证:系统的容错性和可用性
优点:加快数据传输速度、多个副本对比容易检查数据错误、保证数据可靠性
13.HDFS数据存储策略
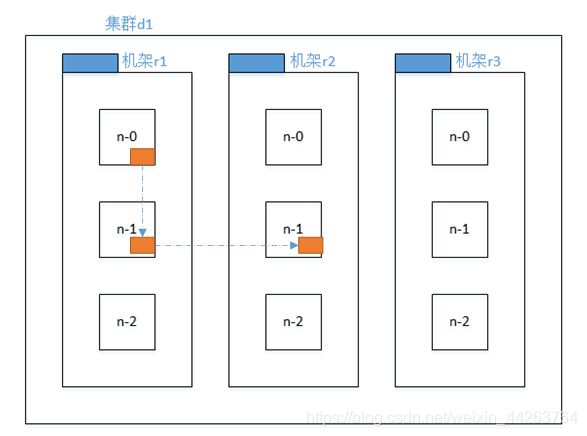
假如一个数据块有3个副本,
那么第1个副本会随机存储在一个机架上的某个节点;
第2个副本会存储在与第1个副本相同机架的不同节点上;
第3个副本会存储在与第1个副本不同机架的随机节点上。
14.HDFS数据错误的三种类型
- NameNode数据错误
- DataNode数据错误
- 数据出错
15.HDFS常用shell命令
# 启动HDFS
[ht@hadoop101 ~]$ start-dfs.sh
# 停止HDFS
[ht@hadoop101 ~]$ stop-dfs.sh
# 输出某个命令的帮助信息
[ht@hadoop101 ~]$ hadoop fs -help ls
# 显示目录详细信息,-p表示递归
[ht@hadoop101 ~]$ hadoop fs -ls [-R]
# 在HDFS上创建目录,-p表示递归创建
[ht@hadoop101 ~]$ hadoop fs -mkdir -p /user/ht
# 显示文件内容
[ht@hadoop101 myfile]$ hadoop fs -cat /user/ht/test.txt
# 将HDFS上的文件拷贝到 HDFS的另一个目录
# 从/user/ht/test.txt 拷贝到 /user/ht/file/
[ht@hadoop101 myfile]$ hadoop fs -cp /user/ht/test.txt /user/ht/file/
# -copyFromLocal:从本地文件系统中拷贝文件到HDFS路径去
# -copyToLocal:从HDFS拷贝到本地
# -put:等同于copyFromLocal
# -get:等同于copyToLocal
# -mv:在HDFS目录中移动文件
# -chgrp将文件所属的用户组改为ht,-R表示递归
# -chmod改变文件权限、-chown改变文件所属用户 也是一样的
[ht@hadoop101 ~]$ hadoop fs -chgrp -R ht /user/ht/test.txt
# 删除文件或文件夹,-r表示递归
[ht@hadoop100 hadoop]$ hdfs dfs -rm [-r] /user/ht/wcoutput
# -rmdir:删除空目录
# -du 统计目录的大小信息
第四章 HBase
1.起源
HBase是谷歌的BigTable的开源实现。
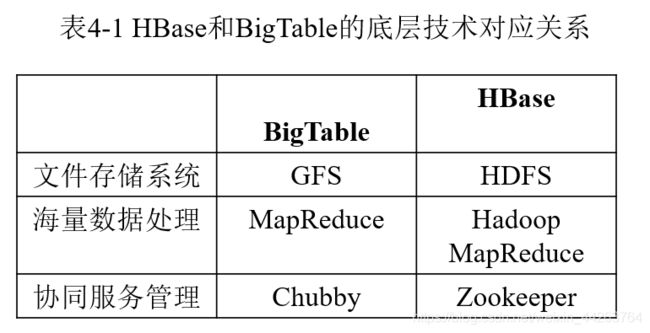
2.HBase和BigTable的底层技术对应关系
3.HBase与传统关系型数据库的对比
区别主要在于:
-
数据类型:hbase中所有数据都是字符串类型;关系型数据库中具有多种数据类型。
-
数据操作:hbase只能对数据进行增、删、查、清空等操作,不能进行表之间的连接;关系型数据库可以增删改查,还可以通过表的外键进行连接。
-
存储模型:hbase基于列存储,关系型数据库基于行存储。
-
数据维护:hbase对数据进行操作后会保留历史版本。
-
数据索引:hbase只有一个索引——行键,关系型数据库可以创建很多索引。
-
可伸缩性:hbase可以通过集群节点的扩展实现存储数据量的水平扩展,关系型数据库难以实现横向扩展,纵向扩展的空间有限。
在hbase中:类型是未经解释的字符串,只能对它进行增删查等操作,索引就是它本身的行键,它就是按列存储,对它操作后还会保留历史版本,hbase还通过集群的机器增加和减少来实现存储容量的增大和缩小。
4.HBase的物理视图与概念视图


5.Master 和 Region的功能
-
Master
master负责管理和维护HBase表的分区信息(Region列表),维护Region服务器列表,分配Region以确保负载均衡。
-
Region
region负责存储hbase表的数据,处理来自客户端的读写请求。
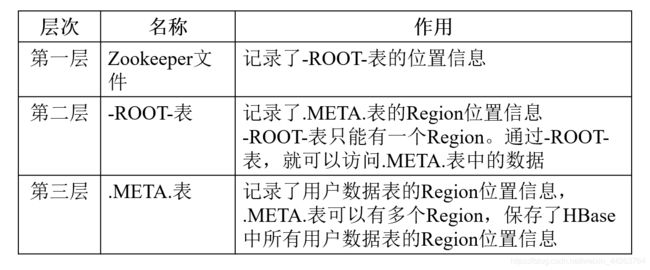
6.Region的定位(HBase的三层结构)
7.Region服务器工作原理
-
用户读写数据过程
-
缓存刷新
-
StoreFile的合并
8.HLog工作原理
HLog是记录Region中各项更新操作的日志,它持久化存储在磁盘中。
用户更新数据必须首先写入HLog后,才能写入MemStore缓存。
当Region启动时,首先检查HLog是否存在未合并的更新操作;若是则先执行更新操作,合并到MemStore和StoreFile中,然后生成一个新的空的HLog文件。
9.HBase性能优化方法(了解)
-
行键
行键是按照字典序存储,因此,设计行键时,要充分利用这个排序特点,将经常一起读取的数据存储到一块,将最近可能会被访问的数据放在一块。
举个例子:如果最近写入HBase表中的数据是最可能被访问的,可以考虑将时间戳作为行键的一部分,由于是字典序排序,所以可以使用Long.MAX_VALUE - timestamp作为行键,这样能保证新写入的数据在读取时可以被快速命中。
-
InMemory
创建表的时候,可以通过HColumnDescriptor.setInMemory(true)将表放到Region服务器的缓存中,保证在读取的时候被cache命中。
-
Max Version
创建表的时候,可以通过HColumnDescriptor.setMaxVersions(int maxVersions)设置表中数据的最大版本,如果只需要保存最新版本的数据,那么可以设置setMaxVersions(1)。
-
Time To Live
创建表的时候,可以通过HColumnDescriptor.setTimeToLive(int timeToLive)设置表中数据的存储生命期,过期数据将自动被删除,例如如果只需要存储最近两天的数据,那么可以设置setTimeToLive(2 * 24 * 60 * 60)。
10.HBase常用shell命令
# 启动hbase shell
hadoop@ubuntu:~$ hbase shell
# 创建表t:列族为f,列族版本号为5
hbase> create 't1',{
NAME => 'f1',VERSIONS => 5}
# 创建表t:列族为f1、f2、f3,两种方式等价
hbase> create 't1', {
NAME => 'f1'}, {
NAME => 'f2'}, {
NAME => 'f3'}
hbase> create 't1', 'f1', 'f2', 'f3'
# 创建表t:将表根据分割算法HexStringSplit 分布在15个Region里
hbase> create 't1', 'f1', {
NUMREGIONS => 15, SPLITALGO => 'HexStringSplit'}
# 创建表t:指定Region的切分点
hbase> create 't1', 'f1', SPLITS => ['10', '20', '30', '40']
--------------------------------------------------------------------------------------------------------
# help 查看create命令的帮助信息
hbase(main):002:0> help "create"
Creates a table. Pass a table name, and a set of column family # create命令的描述
specifications (at least one), and, optionally, table configuration.
Column specification can be a simple string (name), or a dictionary
(dictionaries are described below in main help output), necessarily
including NAME attribute.
Examples:
Create a table with namespace=ns1 and table qualifier=t1 #指定namespace与
hbase> create 'ns1:t1', {
NAME => 'f1', VERSIONS => 5}
Create a table with namespace=default and table qualifier=t1
hbase> create 't1', {
NAME => 'f1'}, {
NAME => 'f2'}, {
NAME => 'f3'}
hbase> # The above in shorthand would be the following:
hbase> create 't1', 'f1', 'f2', 'f3'
hbase> create 't1', {
NAME => 'f1', VERSIONS => 1, TTL => 2592000, BLOCKCACHE => true}
hbase> create 't1', {
NAME => 'f1', CONFIGURATION => {
'hbase.hstore.blockingStoreFiles' => '10'}}
hbase> create 't1', {
NAME => 'f1', IS_MOB => true, MOB_THRESHOLD => 1000000, MOB_COMPACT_PARTITION_POLICY => 'weekly'}
Table configuration options can be put at the end.
Examples:
hbase> create 'ns1:t1', 'f1', SPLITS => ['10', '20', '30', '40']
hbase> create 't1', 'f1', SPLITS => ['10', '20', '30', '40']
hbase> create 't1', 'f1', SPLITS_FILE => 'splits.txt', OWNER => 'johndoe'
hbase> create 't1', {
NAME => 'f1', VERSIONS => 5}, METADATA => {
'mykey' => 'myvalue' }
hbase> # Optionally pre-split the table into NUMREGIONS, using
hbase> # SPLITALGO ("HexStringSplit", "UniformSplit" or classname)
hbase> create 't1', 'f1', {
NUMREGIONS => 15, SPLITALGO => 'HexStringSplit'}
hbase> create 't1', 'f1', {
NUMREGIONS => 15, SPLITALGO => 'HexStringSplit', REGION_REPLICATION => 2, CONFIGURATION => {
'hbase.hregion.scan.loadColumnFamiliesOnDemand' => 'true'}}
hbase> create 't1', 'f1', {
SPLIT_ENABLED => false, MERGE_ENABLED => false}
hbase> create 't1', {
NAME => 'f1', DFS_REPLICATION => 1}
You can also keep around a reference to the created table:
hbase> t1 = create 't1', 'f1'
Which gives you a reference to the table named 't1', on which you can then
call methods.
-------------------------------------------------------------------------------------------------------
# list 列出所有表
hbase> list
# put 向表中指定的单元格添加数据
hbase> put 't1','row1','f1:c1',120000 # 通过表,行键,列族:列限定符进行定位,值为120000
# get 通过指定坐标来获取单元格的值
hbase(main):005:0> get 't1','row1','f1:c1'
COLUMN CELL
f1:c1 timestamp=1609810077099, value=120000
1 row(s)
Took 0.0722 seconds
# delete 删除表中指定单元格的数据
hbase(main):021:0> delete 't1','row1','f1:c1',timestamp=1609810077099
# scan 浏览表的信息
hbase(main):004:0> scan 't1' # 这时会显示表t1中的所有行
# scan 浏览某个单元格的数据
hbase(main):010:0> scan 't1',{
COLUMNS => 'f1:c1'}
# alter 修改列族模式
hbase(main):011:0> alter 't1',NAME => 'f2' # 向表t1中增加列族f2
hbase(main):014:0> alter 't1',NAME => 'f2',METHOD => 'delete' # 将表t1中的列族f2删除
# count 统计表中的行数
hbase(main):015:0> count 't1' # 统计t1的行数
# describe 显示表的相关信息
hbase(main):017:0> describe 't1'
Table t1 is ENABLED
t1
COLUMN FAMILIES DESCRIPTION
{
NAME => 'f1', VERSIONS => '5', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETE
D_CELLS => 'FALSE', CACHE_DATA_ON_WRITE => 'false', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', MIN_VERSI
ONS => '0', REPLICATION_SCOPE => '0', BLOOMFILTER => 'ROW', CACHE_INDEX_ON_WRITE => 'false', IN_MEMORY => 'fal
se', CACHE_BLOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS_ON_OPEN => 'false', COMPRESSION => 'NONE', BLOCKCACHE =
> 'true', BLOCKSIZE => '65536'}
1 row(s)
QUOTAS
0 row(s)
Took 0.1104 seconds
# enable/disable 使表有效或无效
hbase(main):015:0> disable 't1'
# drop 删除表,这里需要注意删除表之前要先使用disable使这个表无效,这也是为了防止误删
hbase(main):023:0> disable 't1'
Took 0.8378 seconds
hbase(main):024:0> drop 't1'
Took 0.4997 seconds
# exists 判断某个表是否存在
hbase(main):025:0> exists 't1'
Table t1 does not exist
Took 0.0231 seconds
=> false
# truncate 使表无效并清空该表的数据
hbase(main):029:0> truncate 'teacher'
Truncating 'teacher' table (it may take a while):
Disabling table...
Truncating table...
Took 2.1127 seconds
hbase(main):031:0> exists 'teacher' # truncate后查看该表是否存在
Table teacher does exist
Took 0.0156 seconds
=> true # 还存在
# 查看HBase集群状态
hbase(main):026:0> status
1 active master, 0 backup masters, 1 servers, 0 dead, 5.0000 average load
Took 0.0582 seconds
# 退出hbase shell
hbase> exit
第五章 NoSQL
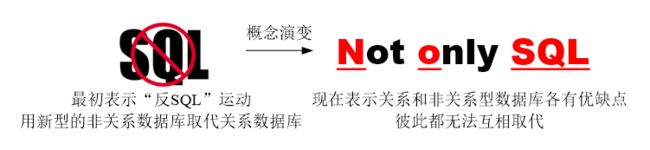
1.nosql 的含义
2.nosql 兴起的原因
- 关系数据库已经无法满足Web2.0的需求
(1)无法满足海量数据的管理需求
(2)无法满足数据高并发的需求
(3)无法满足高可扩展性和高可用性的需求
- 关系数据库的关键特性包括完善的事务机制和高效的查询机制,到了Web2.0时代却成了鸡肋
(1)Web2.0网站系统通常不要求严格的数据库事务
(2)Web2.0并不要求严格的读写实时性
(3)Web2.0通常不包含大量复杂的SQL查询(去结构化,存储空间换取更好的查询性能)
3.nosql与关系型数据库的比较
| 比较标准 | RDBMS | NoSQL | 备注 |
|---|---|---|---|
| 数据库原理 | 完全支持 | 部分支持 | RDBMS有关系代数理论作为基础;NoSQL没有统一的理论基础 |
| 一致性 | 强一致性 | 弱一致性 | RDBMS严格遵守事务ACID模型,可以保证事务强一致性;很多NoSQL数据库放松了对事务ACID四性的要求,而是遵守BASE模型,只能保证最终一致性 |
| 数据库模式 | 固定 | 灵活 | RDBMS需要定义数据库模式,严格遵守数据定义和相关约束条件;NoSQL不存在数据库模式,可以自由灵活定义并存储各种不同类型的数据 |
| 数据完整性 | 容易实现 | 很难实现 | 任何一个RDBMS都可以很容易实现数据完整性,比如通过主键或者非空约束来实现实体完整性,通过主键、外键来实现参照完整性,通过约束或者触发器来实现用户自定义完整性;但是,在NoSQL数据库却无法实现 |
| 数据规模 | 大 | 超大 | RDBMS很难实现横向扩展,纵向扩展的空间也比较有限,性能会随着数据规模的增大而降低;NoSQL可以很容易通过添加更多设备来支持更大规模的数据 |
| 扩展性 | 一般 | 好 | RDBMS很难实现横向扩展,纵向扩展的空间也比较有限;NoSQL在设计之初就充分考虑了横向扩展的需求,可以很容易通过添加廉价设备实现扩展 |
| 可用性 | 好 | 很好 | RDBMS在任何时候都以保证数据一致性为优先目标,其次才是优化系统性能,随着数据规模的增大,RDBMS为了保证严格的一致性,只能提供相对较弱的可用性;大多数NoSQL都能提供较高的可用性 |
| 查询效率 | 快 | 可以实现高效的简单查询,但是不具备高度结构化查询等特性,复杂查询的性能不尽人意 | RDBMS借助于索引机制可以实现快速查询(包括记录查询和范围查询);很多NoSQL数据库没有面向复杂查询的索引,虽然NoSQL可以使用MapReduce来加速查询,但是,在复杂查询方面的性能仍然不如RDBMS |
| 标准化 | 是 | 否 | RDBMS已经标准化(SQL);NoSQL还没有行业标准,不同的NoSQL数据库都有自己的查询语言,很难规范应用程序接口 StoneBraker认为:NoSQL缺乏统一查询语言,将会拖慢NoSQL发展 |
| 技术支持 | 高 | 低 | RDBMS经过几十年的发展,已经非常成熟,Oracle等大型厂商都可以提供很好的技术支持;NoSQL在技术支持方面仍然处于起步阶段,还不成熟,缺乏有力的技术支持。 |
| 可维护性 | 复杂 | 复杂 | RDBMS需要专门的数据库管理员(DBA)维护;NoSQL数据库虽然没有DBMS复杂,也难以维护。 |
总结
(1)关系数据库
优势:以完善的关系代数理论作为基础,有严格的标准,支持事务ACID四性,借助索引机制可以实现高效的查询,技术成熟,有专业公司的技术支持
劣势:可扩展性较差,无法较好支持海量数据存储,数据模型过于死板、无法较好支持Web2.0应用,事务机制影响了系统的整体性能等
(2)NoSQL数据库
优势:可以支持超大规模数据存储,灵活的数据模型可以很好地支持Web2.0应用,具有强大的横向扩展能力等
劣势:缺乏数学理论基础,复杂查询性能不高,大都不能实现事务强一致性,很难实现数据完整性,技术尚不成熟,缺乏专业团队的技术支持,维护较困难等
4.nosql的4大类型、各自的典型应用
典型的NoSQL数据库通常包括键值数据库、列族数据库、文档数据库和图形数据库。

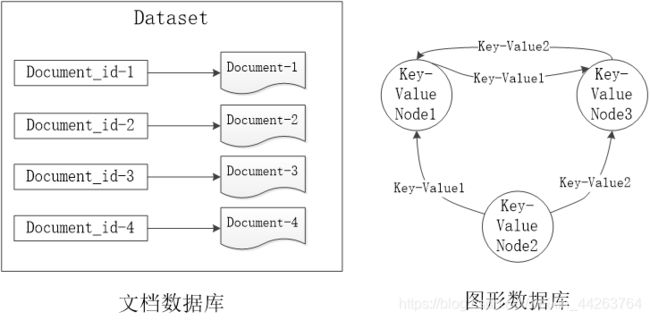
各类型的产品:

- 键值数据库
| 相关产品 | Redis、Riak、SimpleDB、Chordless、Scalaris、Memcached |
|---|---|
| 数据模型 | 键/值对 键是一个字符串对象 值可以是任意类型的数据,比如整型、字符型、数组、列表、集合等 |
| 典型应用 | 涉及频繁读写、拥有简单数据模型的应用 内容缓存,比如会话、配置文件、参数、购物车等 存储配置和用户数据信息的移动应用 |
| 优点 | 扩展性好,灵活性好,大量写操作时性能高 |
| 缺点 | 无法存储结构化信息,条件查询效率较低 |
| 不适用情形 | 不是通过键而是通过值来查:键值数据库根本没有通过值查询的途径 需要存储数据之间的关系:在键值数据库中,不能通过两个或两个以上的键来关联数据 需要事务的支持:在一些键值数据库中,产生故障时,不可以回滚 |
| 使用者 | 百度云数据库(Redis)、GitHub(Riak)、BestBuy(Riak)、Twitter(Redis和Memcached)、StackOverFlow(Redis)、Instagram (Redis)、Youtube(Memcached)、Wikipedia(Memcached) |
-
列族数据库
相关产品 BigTable、HBase、Cassandra、HadoopDB、GreenPlum、PNUTS 数据模型 列族 典型应用 分布式数据存储与管理 数据在地理上分布于多个数据中心的应用程序 可以容忍副本中存在短期不一致情况的应用程序 拥有动态字段的应用程序 拥有潜在大量数据的应用程序,大到几百TB的数据 优点 查找速度快,可扩展性强,容易进行分布式扩展,复杂性低 缺点 功能较少,大都不支持强事务一致性 不适用情形 需要ACID事务支持的情形,Cassandra等产品就不适用 使用者 Ebay(Cassandra)、Instagram(Cassandra)、NASA(Cassandra)、Twitter(Cassandra and HBase)、Facebook(HBase)、Yahoo!(HBase) -
文档数据库
相关产品 MongoDB、CouchDB、Terrastore、ThruDB、RavenDB、SisoDB、RaptorDB、CloudKit、Perservere、Jackrabbit 数据模型 键/值 值(value)是版本化的文档 典型应用 存储、索引并管理面向文档的数据或者类似的半结构化数据 比如,用于后台具有大量读写操作的网站、使用JSON数据结构的应用、使用嵌套结构等非规范化数据的应用程序 优点 性能好(高并发),灵活性高,复杂性低,数据结构灵活 提供嵌入式文档功能,将经常查询的数据存储在同一个文档中 既可以根据键来构建索引,也可以根据内容构建索引 缺点 缺乏统一的查询语法 不适用情形 在不同的文档上添加事务。文档数据库并不支持文档间的事务,如果对这方面有需求则不应该选用这个解决方案 使用者 百度云数据库(MongoDB)、SAP (MongoDB)、Codecademy (MongoDB)、Foursquare (MongoDB)、NBC News (RavenDB) -
图形数据库
相关产品 Neo4J、OrientDB、InfoGrid、Infinite Graph、GraphDB 数据模型 图结构 典型应用 专门用于处理具有高度相互关联关系的数据,比较适合于社交网络、模式识别、依赖分析、推荐系统以及路径寻找等问题 优点 灵活性高,支持复杂的图形算法,可用于构建复杂的关系图谱 缺点 复杂性高,只能支持一定的数据规模 使用者 Adobe(Neo4J)、Cisco(Neo4J)、T-Mobile(Neo4J)
5.nosql 的三大基石
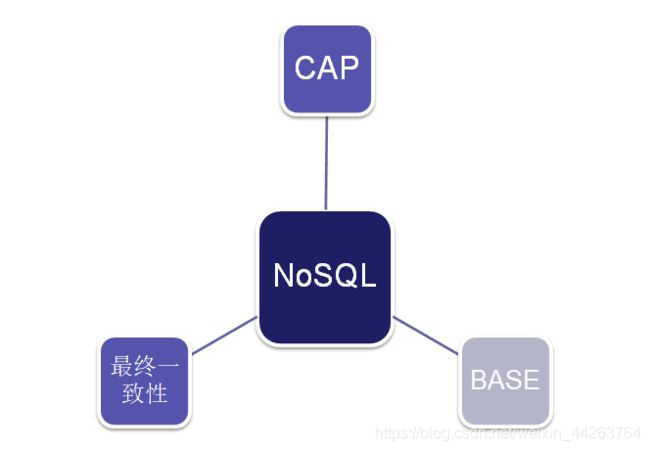
-
CAP
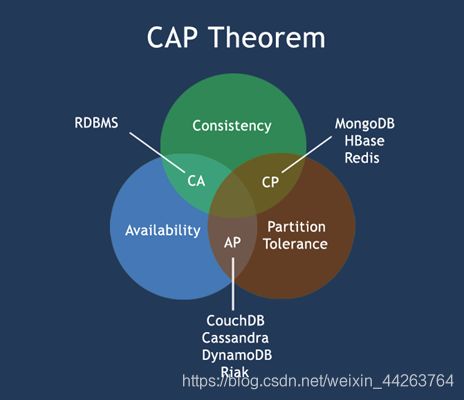
所谓的CAP指的是:
C(Consistency):一致性,是指任何一个读操作总是能够读到之前完成的写操作的结果,也就是在分布式环境中,多点的数据是一致的,或者说,所有节点在同一时间具有相同的数据
A:(Availability):可用性,是指快速获取数据,可以在确定的时间内返回操作结果,保证每个请求不管成功或者失败都有响应;
P(Tolerance of Network Partition):分区容忍性,是指当出现网络分区的情况时(即系统中的一部分节点无法和其他节点进行通信),分离的系统也能够正常运行,也就是说,系统中任意信息的丢失或失败不会影响系统的继续运作。
CAP理论告诉我们,一个分布式系统不可能同时满足一致性、可用性和分区容忍性这三个需求,最多只能同时满足其中两个,正所谓“鱼和熊掌不可兼得”。
-
BASE
说起BASE(Basically Availble, Soft-state, Eventual consistency),不得不谈到ACID。

一个数据库事务具有ACID四性:
A(Atomicity):原子性,是指事务必须是原子工作单元,对于其数据修改,要么全都执行,要么全都不执行
C(Consistency):一致性,是指事务在完成时,必须使所有的数据都保持一致状态
I(Isolation):隔离性,是指由并发事务所做的修改必须与任何其它并发事务所做的修改隔离
D(Durability):持久性,是指事务完成之后,它对于系统的影响是永久性的,该修改即使出现致命的系统故障也将一直保持BASE的基本含义是基本可用(Basically Availble)、软状态(Soft-state)和最终一致性(Eventual consistency):
1.基本可用:基本可用,是指一个分布式系统的一部分发生问题变得不可用时,其他部分仍然可以正常使用,也就是允许分区失败的情形出现。
2.软状态:“软状态(soft-state)”是与“硬状态(hard-state)”相对应的一种提法。数据库保存的数据是“硬状态”时,可以保证数据一致性,即保证数据一直是正确的。“软状态”是指状态可以有一段时间不同步,具有一定的滞后性。
3.最终一致性:一致性的类型包括强一致性和弱一致性,二者的主要**区别在于高并发的数据访问操作下,后续操作是否能够获取最新的数据。**对于强一致性而言,当执行完一次更新操作后,后续的其他读操作就可以保证读到更新后的最新数据;反之,如果不能保证后续访问读到的都是更新后的最新数据,那么就是弱一致性。而最终一致性只不过是弱一致性的一种特例,允许后续的访问操作可以暂时读不到更新后的数据,但是经过一段时间之后,必须最终读到更新后的数据。
最常见的实现最终一致性的系统是DNS(域名系统)。一个域名更新操作根据配置的形式被分发出去,并结合有过期机制的缓存;最终所有的客户端可以看到最新的值。 -
最终一致性
最终一致性根据更新数据后各进程访问到数据的时间和方式的不同,又可以区分为:
因果一致性:如果进程A通知进程B它已更新了一个数据项,那么进程B的后续访问将获得A写入的最新值。而与进程A无因果关系的进程C的访问,仍然遵守一般的最终一致性规则
“读己之所写”一致性:可以视为因果一致性的一个特例。当进程A自己执行一个更新操作之后,它自己总是可以访问到更新过的值,绝不会看到旧值
单调读一致性:如果进程已经看到过数据对象的某个值,那么任何后续访问都不会返回在那个值之前的值会话一致性:它把访问存储系统的进程放到会话(session)的上下文中,只要会话还存在,系统就保证“读己之所写”一致性。如果由于某些失败情形令会话终止,就要建立新的会话,而且系统保证不会延续到新的会话
单调写一致性:系统保证来自同一个进程的写操作顺序执行。系统必须保证这种程度的一致性,否则就非常难以编程了
扩展知识
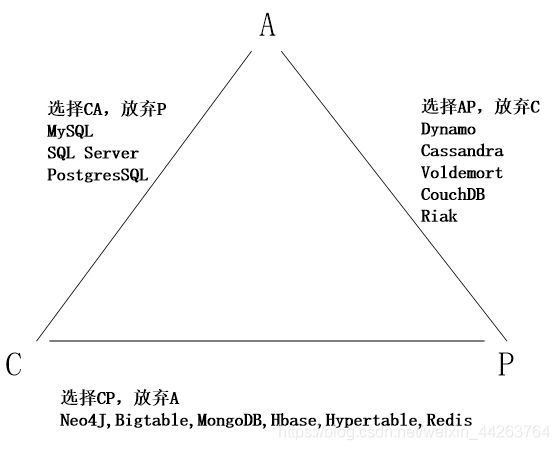
当处理CAP的问题时,可以有几个明显的选择:
1.CA:也就是强调一致性(C)和可用性(A),放弃分区容忍性(P),最简单的做法是把所有与事务相关的内容都放到同一台机器上。很显然,这种做法会严重影响系统的可扩展性。传统的关系数据库(MySQL、SQL Server和PostgreSQL),都采用了这种设计原则,因此,扩展性都比较差
2.CP:也就是强调一致性(C)和分区容忍性(P),放弃可用性(A),当出现网络分区的情况时,受影响的服务需要等待数据一致,因此在等待期间就无法对外提供服务
3.AP:也就是强调可用性(A)和分区容忍性(P),放弃一致性(C),允许系统返回不一致的数据
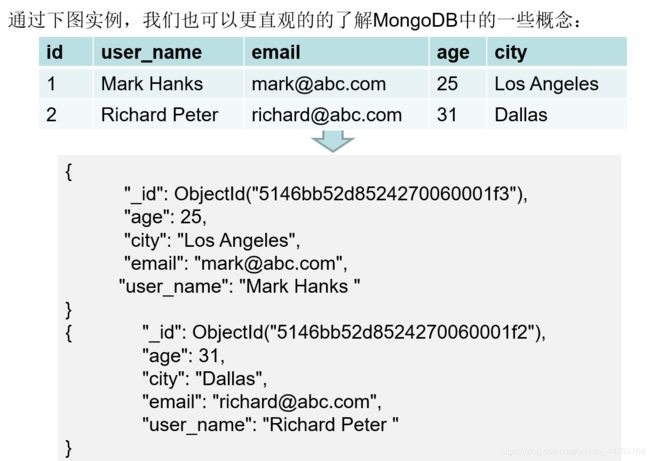
6.MongoDB基本概念
在mongodb中基本的概念是文档、集合、数据库
| SQL术语/概念 | MongoDB术语/概念 | 解释/说明 |
|---|---|---|
| database | database | 数据库 |
| table | collection | 数据库表/集合 |
| row | document | 数据记录行/文档 |
| column | field | 数据字段/域 |
| index | index | 索引 |
| table joins | 表连接,MongoDB不支持 | |
| primary key | primary key | 主键,MongoDB自动将_id字段设置为主键 |
第六章 云数据库
1.云数据库的概念
云数据库是部署和虚拟化在云计算环境中的数据库。
云数据库是在云计算的大背景下发展起来的一种新兴的共享基础架构的方法,它极大地增强了数据库的存储能力,消除了人员、硬件、软件的重复配置,让软、硬件升级变得更加容易。
云数据库具有高可扩展性、高可用性、采用多租形式和支持资源有效分发等特点。
2.云数据库的特性
(1)动态可扩展:用户按需扩展
(2)高可用性:云数据库具有故障自动单点切换、数据库自动备份等功能
(3)较低的使用代价:RDS支付的费用远低于自建数据库所需的成本
(4)易用性:提供WEB界面进行配置、操作数据库实例
(5)高性能
(6)免维护:有专门的维护人员
(7)安全
3.云数据库厂商以及各自的产品
| 企业 | 产品 |
|---|---|
| Amazon | Dynamo、SimpleDB、RDS |
| Google Cloud SQL | |
| Microsoft | Microsoft SQL Azure |
| Oracle | Oracle Cloud |
| Yahoo! | PNUTS |
| Vertica | Analytic Database v3.0 for the Cloud |
| EnerpriseDB | Postgres Plus in the Cloud |
| 阿里 | 阿里云RDS |
| 百度 | 百度云数据库 |
| 腾讯 | 腾讯云数据库 |
第七章 MapReduce
1.MapReduce与传统并行计算框架比较
| 传统并行计算框架 | MapReduce | |
|---|---|---|
| 集群架构/容错性 | 共享式(共享内存/共享存储),容错性差 | 非共享式,容错性好 |
| 硬件/价格/扩展性 | 刀片服务器、高速网、SAN,价格贵,扩展性差 | 普通PC机,便宜,扩展性好 |
| 编程/学习难度 | what-how,难 | what,简单 |
| 适用场景 | 实时、细粒度计算、计算密集型 | 非实时、批处理、数据密集型 |
2.MapReduce的2个特点
分而治之、计算向数据靠拢
3.MapReduce流程

4.MapReduce的体系结构
下面是Hadoop1.x中的体系结构,但我觉得不会考:
MapReduce体系结构主要由四个部分组成,分别是:Client、JobTracker、TaskTracker以及Task。
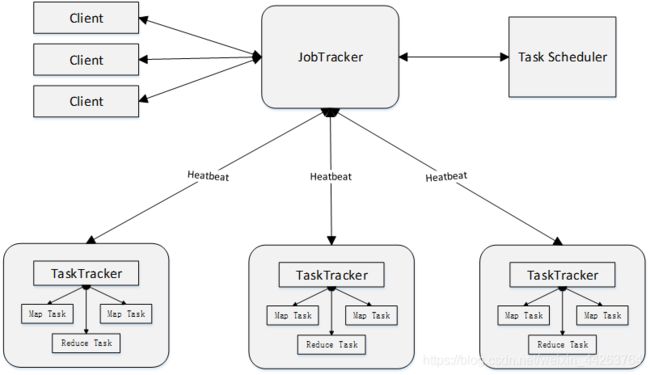
1)Client
用户编写的MapReduce程序通过Client提交到JobTracker端
用户可通过Client提供的一些接口查看作业运行状态
2)JobTracker
JobTracker负责资源监控和作业调度
JobTracker 监控所有TaskTracker与Job的健康状况,一旦发现失败,就将相应的任务转移到其他节点
JobTracker 会跟踪任务的执行进度、资源使用量等信息,并将这些信息告诉任务调度器(TaskScheduler),而调度器会在资源出现空闲时,选择合适的任务去使用这些资源
3)TaskTracker
TaskTracker 会周期性地通过“心跳”将本节点上资源的使用情况和任务的运行进度汇报给JobTracker,同时接收JobTracker 发送过来的命令并执行相应的操作(如启动新任务、杀死任务等)
TaskTracker 使用“slot”等量划分本节点上的资源量(CPU、内存等)。一个Task 获取到一个slot 后才有机会运行,而Hadoop调度器的作用就是将各个TaskTracker上的空闲slot分配给Task使用。slot 分为Map slot 和Reduce slot 两种,分别供MapTask 和Reduce Task 使用
4)Task
Task 分为Map Task 和Reduce Task 两种,均由TaskTracker 启动
5.map与reduce并行度的决定因素
maptask并行度由输入数据分片数量决定;reducetask并行度由输入数据分区数量决定。
6.WordCount代码
package com.ht.wordcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCount {
public static class WordCountMapper extends Mapper<LongWritable,Text,Text, IntWritable>{
IntWritable intWritable = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1.读取数据
String line = value.toString();
// 2.切片
String[] splits = line.split("\t");
// 3.输出
Text text = new Text();
for (String split : splits) {
text.set(split);
context.write(text, intWritable);
}
}
}
public static class WordCountReducer extends Reducer<Text,IntWritable,Text,IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
// 1.读取数据 >
int sumVal = 0;
for (IntWritable val:values){
sumVal += val.get();
}
// 2.输出数据
context.write(key,new IntWritable(sumVal));
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1.hadoop运行信息
Configuration configuration = new Configuration();
// 2.获取hadoop实例
String jobName = "WordCount";
Job job = Job.getInstance(configuration, jobName);
// 3.设置程序的本地jar包
job.setJarByClass(WordCount.class);
// 4.关联mapper和reducer
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 5.设置mapper的输出kv
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 6.设置reducer的输出kv(最终输出)
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 7.设置作业输入输出路径
Path inputPath = new Path("D:\\Document\\temp\\wordcount\\input.txt");
Path outputPath = new Path("D:\\Document\\temp\\wordcount\\output");
// 获取hdfs文件系统实例
FileSystem fileSystem = FileSystem.get(configuration);
if(fileSystem.exists(outputPath)){
fileSystem.delete(outputPath,true);
}
// 8.设置输入输出格式
FileInputFormat.addInputPath(job,inputPath);
FileOutputFormat.setOutputPath(job, outputPath);
// 9.查看作业运行情况
System.out.println("job " + jobName + "is running...");
// 若成功打印1,不成功打印0
System.out.println(job.waitForCompletion(true) ? 1:0);
}
}
第八章 Hadoop 2.x
1.Hadoop1.0的不足、改进(了解)
Hadoop1.0的核心组件(仅指MapReduce和HDFS,不包括Hadoop生态系统内的Pig、Hive、HBase等其他组件),主要存在以下不足:
- 抽象层次低,需人工编码
- 表达能力有限
- 开发者自己管理作业(Job)之间的依赖关系
- 难以看到程序整体逻辑
- 执行迭代操作效率低
- 资源浪费(Map和Reduce分两阶段执行)
- 实时性差(适合批处理,不支持实时交互式)
| 组件 | Hadoop1.0的问题 | Hadoop2.0的改进 |
|---|---|---|
| HDFS | 单一名称节点,存在单点故障问题 | 设计了HDFS HA,提供名称节点热备机制 |
| HDFS | 单一命名空间,无法实现资源隔离 | 设计了HDFS Federation,管理多个命名空间 |
| MapReduce | 资源管理效率低 | 设计了新的资源管理框架YARN |
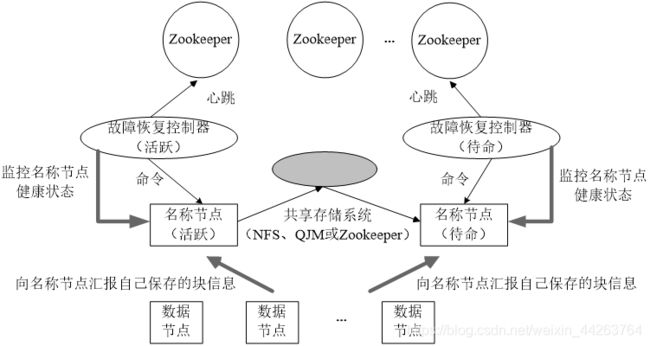
2.HA的工作原理
HDFS HA(High Availability)是为了解决单点故障问题。HA集群设置两个名称节点,“活跃(Active)”和“待命(Standby)”,两种名称节点的状态同步,可以借助于一个共享存储系统来实现。
一旦活跃名称节点出现故障,就可以立即切换到待命名称节点,Zookeeper确保一个名称节点在对外服务。名称节点维护映射信息,数据节点同时向两个名称节点汇报信息。
3.YARN设计思路
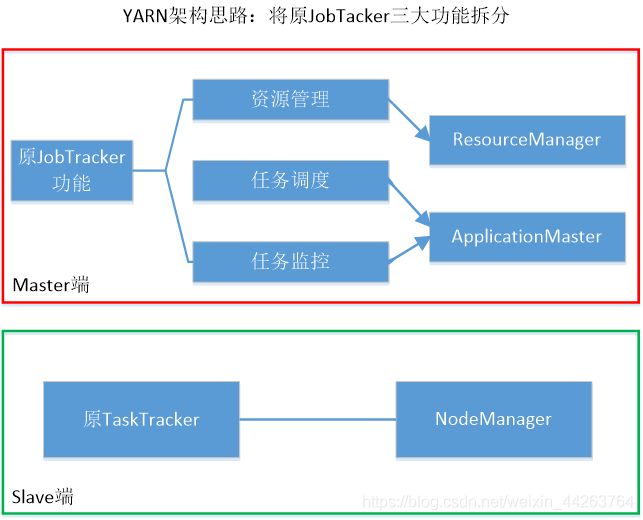
到了Hadoop2.0以后,MapReduce1.0中的资源管理调度功能,被单独分离出来形成了YARN,它是一个纯粹的资源管理调度框架,而不是一个计算框架。
4.YARN的发展目标
一个企业当中同时存在各种不同的业务应用场景,需要采用不同的计算框架
MapReduce实现离线批处理
使用Impala实现实时交互式查询分析
使用Storm实现流式数据实时分析
使用Spark实现迭代计算这些产品通常来自不同的开发团队,具有各自的资源调度管理机制,为了避免不同类型应用之间互相干扰,企业就需要把内部的服务器拆分成多个集群,分别安装运行不同的计算框架,即“一个框架一个集群”
导致问题:集群资源利用率低、数据无法共享、维护代价高
YARN的目标就是实现“一个集群多个框架”,即在一个集群上部署一个统一的资源调度管理框架YARN,在YARN之上可以部署其他各种计算框架。
由YARN为这些计算框架提供统一的资源调度管理服务,并且能够根据各种计算框架的负载需求,调整各自占用的资源,实现集群资源共享和资源弹性收缩。
可以实现一个集群上的不同应用负载混搭,有效提高了集群的利用率;不同计算框架可以共享底层存储,避免了数据集跨集群移动。
第九章 Spark
1.Spark的特点
- 运行速度快(相较于Hadoop)
- 通用性(具有完整的技术栈)
- 易用性(多种方式使用)
- 运行模式多样
2.Spark支持的语言
scala、java、python、r
3.scala的特点
- 函数式编程,具备强大的并发性,更好地支持分布式系统
- 兼容java
- 语法简洁优雅
- 支持高效的交互式编程
- 面向对象
- scala是spark的开发语言
4.Spark与Hadoop的比较
| Hadoop的不足 | Spark的改进 |
|---|---|
| 表达能力有限 | Spark的计算模式也属于MapReduce,但不局限于Map和Reduce操作,还提供了多种数据集操作类型,编程模型比Hadoop MapReduce更灵活 |
| 磁盘I/O开销大 | Spark提供了内存计算,可将中间结果放到内存中,对于迭代运算效率更高 |
| 延迟高 | Spark基于DAG的任务调度执行机制,要优于Hadoop MapReduce的迭代执行机制 |
5.Spark设计理念
一个技术栈满足不同应用场景。
6.Spark的组件、组件的应用场景、时间跨度
| 应用场景 | 时间跨度 | 其他框架 | Spark生态系统中的组件 |
|---|---|---|---|
| 复杂的批量数据处理 | 小时级 | MapReduce、Hive | Spark Core |
| 基于历史数据的交互式查询 | 分钟级、秒级 | Impala、Dremel、Drill | Spark SQL |
| 基于实时数据流的数据处理 | 毫秒、秒级 | Storm、S4 | Spark Streaming、Structured Streaming |
| 基于历史数据的数据挖掘 | - | Mahout | MLlib |
| 图结构数据的处理 | - | Pregel、Hama | GraphX |
7.RDD基本概念
RDD是弹性分布式数据集,一种基于内存的数据共享模型。
8.Spark程序的运行流程
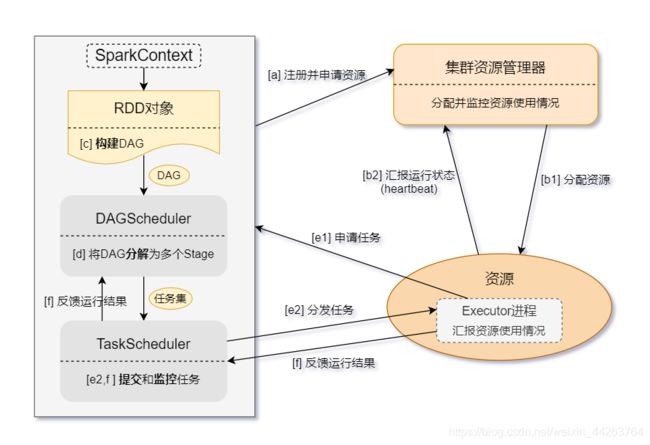
用户提交代码生成一个Job — sparkcontext向集群资源管理器注册并申请资源 — 集群资源管理器分配Executor资源给这个Job — Executor向sparkcontext申请任务 — sparkcontext分发任务 — Executor执行完成,返回给sparkcontext
9.RDD的两种算子
transformation 转换算子、action行动算子
10.血缘关系
多个RDD之间一系列的依赖关系称为血缘关系。
11.RDD的特性
1.A list of partitions 可分区
RDD是一个由多个partition(某个节点里的某一片连续的数据)组成的的list;将数据加载为RDD时,一般会遵循数据的本地性(一般一个hdfs里的block会加载为一个partition)。
2.A function for computing each split 分区计算
一个函数计算每一个分片,RDD的每个partition上面都会有function,也就是函数应用,其作用是实现RDD之间partition的转换。
3.A list of dependencies on other RDDs 依赖关系
RDD会记录它的依赖 ,依赖还具体分为宽依赖和窄依赖,但并不是所有的RDD都有依赖。为了容错(重算,cache,checkpoint),也就是说在内存中的RDD操作时出错或丢失会进行重算。
4.Optionally,a Partitioner for Key-value RDDs 自定义分区
可选项,如果RDD里面存的数据是key-value形式,则可以传递一个自定义的Partitioner进行重新分区,例如这里自定义的Partitioner是基于key进行分区,那则会将不同RDD里面的相同key的数据放到同一个partition里面
5.Optionally, a list of preferred locations to compute each split on 数据的本地性
最优的位置去计算,也就是数据的本地性。
12.RDD的依赖关系
两个相邻RDD之间的关系。有两种,分为“窄依赖”和“宽依赖”。经过Shuffle过程的称为宽依赖。
13.stage的划分
如果有shuffle过程即宽依赖,那么就会创建一个新的stage。
14.Spark的三种部署方式
spark独立部署、On YARN、On Meros
15.Spark编程
-
SparkContext:程序运行的上下文环境
-
SparkSession:用于创建会话,其实是封装了 SQLContext 和 HiveContext
-
sparksql提供了DataFrame\DataSet,Spark SQL执行计划生成和优化都由Catalyst(函数式关系查询优化框架)负责
-
df与rdd的区别:
RDD是分布式的 Java对象的集合,但是,对象内部结构对于RDD而言却是不可知的;
DataFrame是一种以RDD为基础的分布式数据集,提供了详细的结构信息。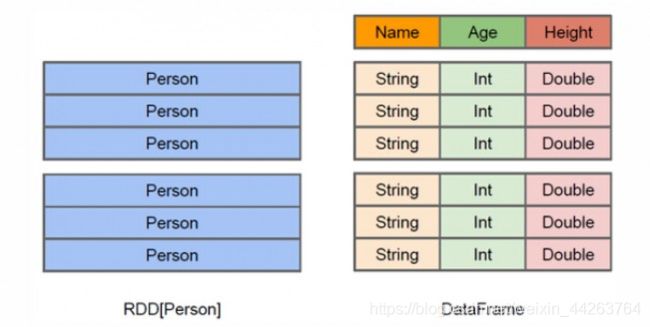
-
df的创建、隐式转换
DataFrame可以从文件中读取并创建、还可以由RDD转换得到。
SparkSession.implicits $是Scala中的隐式方法,用于将常见的Scala对象转换为DataFrames。RDD对象可以通过隐式转换转为DataFrame。 -
rdd转换为df的2种方式
利用反射机制推断RDD模式、利用编程方式定义RDD模式
-
WordCount
1.RDD
package Com.HT.Final import org.apache.spark.{ SparkConf, SparkContext} object WordCount { def main(args: Array[String]): Unit = { val sparkConf = new SparkConf().setMaster("local[2]").setAppName("spark") val sparkContext = new SparkContext(sparkConf) // 步骤:读取文件,分割,map,reduceByKey val rdd = sparkContext.textFile("D:\\Document\\temp\\wordcount\\input.txt") // 读取文件 // 方法1:不简化 //val rdd1 = rdd.flatMap(line => line.split("\t")).map(word => (word, 1)).reduceByKey((a, b) => a + b) // 方法2:简化 (scala的至简原则) val rdd2 = rdd.flatMap(_.split("\t")).map((_, 1)).reduceByKey(_+_) rdd2.collect().foreach(println) sparkContext.stop() } }2.Spark SQL
package Com.HT.Final.wordcount import org.apache.spark.sql.{ DataFrame, Dataset, SparkSession} import org.apache.spark.{ SparkConf, SparkContext} object WordCount_sparksql { def main(args: Array[String]): Unit = { //1.创建Sparksession,获取SparkContext val sparkConf: SparkConf = new SparkConf().setAppName("WordCount").setMaster("local[*]") val spark: SparkSession = SparkSession.builder().config(sparkConf).getOrCreate() val sparkContext: SparkContext = spark.sparkContext sparkContext.setLogLevel("WARN") import spark.implicits._ //DS和DF的底层都是RDD,下面的计算过程中底层涉及到他们的相互转换,所以需要导入隐式转换 //2.读取文件,读取为Dataset[String] val fileDS: Dataset[String] = spark.read.textFile("D:\\Do,cument\\temp\\wordcount\\input.txt") //3.对文件数据进行处理 -> Dataset[String] val wordDS: Dataset[String] = fileDS.flatMap(line => line.split("\t")) // 分割符\t //4.注册表 wordDS.createOrReplaceTempView("word_count") //5.书写sql语句 val sql:String = "select value as word,count(*) as counts from word_count group by word order by counts desc" //6.执行sql语句,查看内容 val dataFrame: DataFrame = spark.sql(sql) dataFrame.show() //7.关闭资源 sparkContext.stop() spark.stop() } }3.Spark Streaming
package Com.HT.Final.wordcount import org.apache.spark.streaming.{ Seconds, StreamingContext} import org.apache.spark.{ SparkConf} object WordCount_sparkstreaming { def main(args: Array[String]): Unit = { //创建一个sparkconf对象,其中local[2]表示任务运行在本地且需要两个CUP val sparkconf = new SparkConf().setMaster("local[2]").setAppName("FileWordCount") //这里必须至少有2个线程,一个用于接收数据,一个用于统计 //创建StreamingContext对象,rdd批次处理间隔设为5秒 val ssc = new StreamingContext(sparkconf,Seconds(5)) // 方法1:从hdfs中读取文件,生成DStream val lines = ssc.textFileStream("D:\\Document\\temp\\wordcount\\input.txt") // 必须用流的形式写入到这个目录形成文件才能被监测到 // 方法2:通过Socket端口监听并接收数据,设置主机名、端口、持久化存储级别(如果数据在内存中放不下,则溢写到磁盘) // val lines = ssc.socketTextStream("localhost", 9999, StorageLevel.MEMORY_AND_DISK) val res = lines.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_) //用空格分割单词并计数 res.print() //显示结果 //启动spark streaming ssc.start() //等待直到任务停止 ssc.awaitTermination() ssc.stop() } }4.Structured Streaming
package Com.HT.Final.wordcount import org.apache.spark.sql.streaming.OutputMode import org.apache.spark.sql.{ DataFrame, Dataset, SparkSession} object WordCount_structuredstreaming { def main(args: Array[String]): Unit = { //1.创建SparkSession val spark = SparkSession.builder().master("local[*]").appName("structuredstreaming").getOrCreate() spark.sparkContext.setLogLevel("WARN") // 设置日志级别 import spark.implicits._ // 导入隐式转换 //2.数据集的生成,数据读取 val source: DataFrame = spark.readStream .format("socket") // 设置socket读取流数据 .option("host","localhost") // 监听主机的ip地址或主机名 .option("port",9999) // 指定监听主机的端口 .load() // 3.数据的处理:行转换成一个个单词 // 方法1:Dataset[String] -> Dataset[(String, Int)] -> KeyValueGroupedDataset[String, (String, Int)] -> Dataset[(String, Long)] // groupByKey :按Key进行分组,返回[K,Iterable[V]] // val words: Dataset[(String, Long)] = source.as[String].flatMap(_.split(" ")).map((_,1)).groupByKey(_._1).count() // 方法2:Dataset[String] -> RelationalGroupedDataset -> DataFrame // groupBy:新建一个RelationalGroupedDataset,而这个方法提供count(),max(),agg()等方法。 // groupByKey 后返回的类是 KeyValueGroupedDataset ,它里面所提供的操作接口不如 groupBy 返回的 RelationalGroupedDataset 所提供的接口丰富。 val words: DataFrame = source.as[String].flatMap(_.split(" ")).groupBy("value").count() //4.结果集的生成输出 words.writeStream .outputMode(OutputMode.Complete()) .format("console") // 设置在控制台显示结果 .start() // 开启 .awaitTermination() // 等待直到任务停止 } } -
案例1:求TOP值
package Com.HT.Final import org.apache.spark.{ SparkConf, SparkContext} object TopN { def main(args: Array[String]): Unit = { // 设置环境 val sparkConf = new SparkConf().setMaster("local").setAppName("TopN") val sparkContext = new SparkContext(sparkConf) // 读取文件 val rdd = sparkContext.textFile("D:\\Document\\temp\\rddfile\\TopN\\input.txt") // 过滤数据:长度小于多少、分割后长度小于多少 val filterRDD = rdd.filter(line => (line.trim().length>0) && (line.split(",").length == 4)) // 分割、排序、输出 var i = 1; // 最终输出排名的序号 val sortRdd = filterRDD .map(_.split(",")(2)) // 分隔每一行数据,RDD的类型变成Array[String],然后取索引为2的元素,就是要进行排序的数据 .map(x => (x.toInt,"")) // 将该列数据的每一行都变为键值对RDD,键为数据,值为"" .sortByKey(false) // 根据键进行降序排序 .map(x => x._1) // 取排序后的那一列数据,只要键不要值 .take(5) // 取出top5的数据 .foreach(x => { // 遍历打印 println(i + "\t" + x) i+=1 }) } } -
案例2:求最大最小值
package Com.HT.Final import org.apache.spark.rdd.RDD import org.apache.spark.{ SparkConf, SparkContext} object MaxAndMinVal { def main(args: Array[String]): Unit = { // 设置环境 val sparkConf = new SparkConf().setMaster("local").setAppName("MaxAndMinVal") val sparkContext = new SparkContext(sparkConf) // 读取文件,读取进来每一行都是一个字符串 val lines: RDD[String] = sparkContext.textFile("D:\\Document\\temp\\rddfile\\maxandmin.txt") // 过滤、转换、根据key进行分组、求最大最小值 val rdd: Unit = lines.filter(line => line.trim.length > 0) // trim:删除指定字符串的首尾空白符 .map(line => ("key", line.toInt)) .groupByKey() // 转换为(“key”,value-list) .map(line => { var minValue: Int = Integer.MAX_VALUE var maxValue: Int = Integer.MIN_VALUE for (num <- line._2) { // 遍历value-list。line._2就是键值对(key,value-list)中的value-list,这里value-list就是<129,54,167,…,5,329,14,...> if (num < minValue) { minValue = num } if (num > maxValue) { maxValue = num } } (maxValue, minValue) }).collect().foreach(x => { println("最大值 = " + x._1) println("最小值 = " + x._2) }) sparkContext.stop() } } -
案例3:文件排序
有多个输入文件,每个文件中的每一行内容均为一个整数。要求读取所有文件中的整数,进行排序后,输出到一个新的文件中,输出的内容个数为每行两个整数,第一个整数为第二个整数的排序位次,第二个整数为原待排序的整数。
package Com.HT.Final import org.apache.spark.rdd.RDD import org.apache.spark.{ HashPartitioner, SparkConf, SparkContext} object FileSort { def main(args: Array[String]): Unit = { // 设置环境 val sparkConf = new SparkConf().setMaster("local").setAppName("FileSort") val sparkContext = new SparkContext(sparkConf) // 读取文件 val rdd: RDD[String] = sparkContext.textFile("D:\\Document\\temp\\rddfile\\filesort",3) // 过滤、分割、排序、输出 var index = 0; // 第一列:序号 val result: RDD[(Int, Int)] = rdd.filter(_.trim.length > 0) // 过滤长度不大于0的记录 .map(x => (x.trim.toInt, "")) // 将字符串rdd转换类型为:(整型,"") .partitionBy(new HashPartitioner(1)) // 将3个分区归为一个:由入输入文件有多个,产生不同的分区,为了生成序号,使用HashPartitioner将中间的RDD归约到一起 .sortByKey() // 按照key进行升序排序 .map(kv => { // 输出两列 index += 1 println(index + "\t" + kv._1) (index, kv._1) }) result.saveAsTextFile("D:\\Document\\temp\\rddfile\\filesortout") // 保存为一个文件 // 关闭sc sparkContext.stop() } } -
案例4:二次排序
对于一个给定的文件(数据如file1.txt所示),请对数据进行排序,首先根据第1列数据降序排序,如果第1列数据相等,则根据第2列数据降序排序。
spark程序:
package Com.HT.Final.TwoTimesSort import org.apache.spark.rdd.RDD import org.apache.spark.{ SparkConf, SparkContext} object SecondarySort { def main(args: Array[String]): Unit = { // 设置配置信息、上下文环境 val sparkConf = new SparkConf().setMaster("local").setAppName("SecondarySort") val sparkContext = new SparkContext(sparkConf) // 过滤、分割、转换、二次排序(第一列降序,第一列相等的按照第二列降序排序) // 读取文件 val lines = sparkContext.textFile("D:\\Document\\temp\\rddfile\\secondarysort\\input.txt") val pairWithSortKey = lines .filter(line => line.trim.length>0) // 过滤 .map(line => (new SecondarySortKey(line.split("\t")(0).toInt, line.split("\t")(1).toInt),line)) // k-v,k是SecondarySortKey对象,规定了排序规则,v是原本输入的一对数据 // 根据键进行排序,这里会遵循 SecondarySortKey对象 的排序规则 val sorted = pairWithSortKey.sortByKey(false) // 取出原本的一对数字组成的字符串 val sortedResult = sorted.map(sortedLine => sortedLine._2) // 并打印 sortedResult.collect().foreach (println) // 关闭sc sparkContext.stop() } }SecondarySortKey:
package Com.HT.Final.TwoTimesSort import org.apache.spark.{ SparkConf, SparkContext} class SecondarySortKey(val first:Int,val second:Int) extends Ordered [SecondarySortKey] with Serializable { def compare(other:SecondarySortKey):Int = { // 实现compare方法,可以二次排序 if (this.first - other.first !=0) { // first与other不相等 this.first - other.first // 第一列降序排序 } else { // first与other相等 this.second - other.second // 第二列降序排序 } } } -
案例5:连接操作
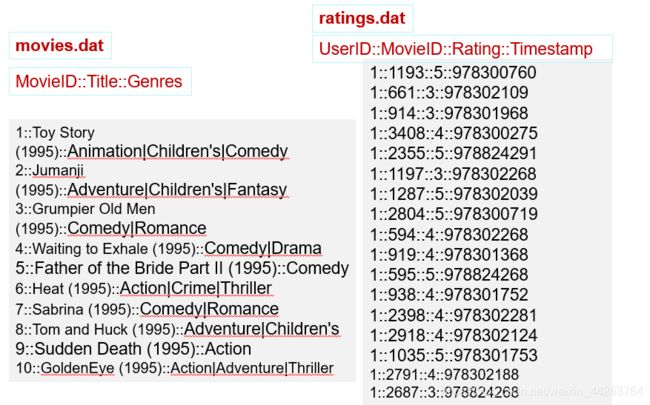
任务描述:在推荐领域有一个著名的开放测试集,下载链接是:http://grouplens.org/datasets/movielens/,该测试集包含三个文件,分别是ratings.dat、sers.dat、movies.dat,具体介绍可阅读:README.txt。请编程实现:通过连接ratings.dat和movies.dat两个文件得到平均得分超过4.0的电影列表,采用的数据集是:ml-1m。
package Com.HT.Final import org.apache.spark.rdd.RDD import org.apache.spark.{ SparkConf, SparkContext} object SparkJoin { def main(args: Array[String]): Unit = { // 设置上下文环境 val sparkConf = new SparkConf().setAppName("SparkJoin").setMaster("local") val sparkContext = new SparkContext(sparkConf) //TODO 1.处理ratings数据:读取、分割、抽取、计算、keyby // 读取ratings文件为RDD,一共4列 val ratingsRDD: RDD[String] = sparkContext.textFile("D:\\Document\\temp\\rddfile\\join\\ratings.rat") // 提取(第2列movieid电影id, 第3列rating电影评分) val idAndRatings = ratingsRDD .map(line => { val fileds = line.split("::") // 分割,得到字符串数组 (fileds(1).toInt, fileds(2).toDouble) // 提取电影id和电影评分,索引分别为1和2 }) // KeyBy: 为各个元素,按指定的函数生成key,形成key-value的RDD。 // 电影id + 计算电影的平均评分 val movieIdAndAvgScoreKey = idAndRatings .groupByKey() // 根据电影id将电影评分进行分组 .map(data => { val avg = data._2.sum / data._2.size // 求平均评分 (data._1, avg) // 返回电影id和平均评分 }).keyBy(tup => tup._1) // 设置key为 电影id, value为 电影id和平均分 //TODO 2.处理电影信息的数据::读取、分割、抽取、keyby // 读取movies文件为RDD,一共3列 val moviesRDD = sparkContext.textFile("D:\\Document\\temp\\rddfile\\join\\movies.dat") // 提取(第1列movieid电影id, 第2列moviename电影名称) val movieskey = moviesRDD.map(line => { // movieskey:(1,(1,Toy Story (1995) )) val fileds = line.split("::") // 分割为 (1,Toy Story (1995)) (fileds(0).toInt, fileds(1)) // 整型数,字符串 }).keyBy(tup => tup._1) // 设置key为 电影id, value为电影id和电影名称 //TODO 3.连接、过滤、抽取输出 val joinResult = movieIdAndAvgScoreKey // 连接操作 .join(movieskey) .filter(f => f._2._1._2 > 4.0) // 过滤 .map( f => (f._1, f._2._1._2, f._2._2._2) // 取出电影id,电影平均分,电影名称 ) joinResult.saveAsTextFile("D:\\Document\\temp\\rddfile\\joinoutput") } } // KeyBy: 为各个元素,按指定的函数生成key,形成key-value的RDD。 -
史上最全的spark面试题 https://www.cnblogs.com/think90/p/11461367.html
第十章 流计算
1.流计算与批处理的区别
批处理:处理离线数据。单个处理数据量大,处理速度比流慢。
流计算:处理实时产生的数据。单次处理的数据量小,但处理速度更快。
2.文件流
Spark支持从兼容HDFS API的文件系统中读取数据,创建数据流。就是上面 Spark Streaming程序里提到的文件流。
http://dblab.xmu.edu.cn/blog/1082-2/
https://blog.csdn.net/zhangdy12307/article/details/90379543
3.socket
Spark Streaming可以通过Socket端口监听并接收数据,然后进行相应处理。
使用命令开启socket监听端口:nc -lk [port]
socket工作原理(应该不会考):

如果有问题可以在评论区提出,或者私信我。如果哪里有错误的,欢迎提出~