人脸属性识别的思考
目录
数据,数据
多人类任务网络设计:
人脸识别vs表情识别:
多任务训练问题:
1.多任务训练过程中的此消彼长
2.类别不平衡问题
3.难易学习问题
4.年龄,分类替代回归
5.表情识别界线模糊问题
6.eyeglass(yes,no),darkglass(yes,no)
7.性别精度不足
8.人脸关键点检测和人脸属性的适配问题
9.左右眼问题
时间是金钱,细节是魔鬼:
数据,数据
CelebA:(人脸属性) http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html
raf:(人脸表情) http://www.whdeng.cn/RAF/model1.html
Skin-Disease-Detection:(黑眼圈,痘痘,色斑,皱纹) https://github.com/gjain307/Skin-Disease-Detection.git
trade-off between visual quality and image diversity
一荣俱荣,一损俱损,

一件99%的事,胜过10件80%的事
登高而招,臂非加长也,而见者远;顺风而呼,声非加疾也,而闻者彰。假舆马者,非利足也,而致千里;假舟楫者,非能水也,而绝江河。君子生非异也,善假于物也。 http://www.seeprettyface.com/mydataset.html#mulu
star:中国100个明星数据集,(中国人)
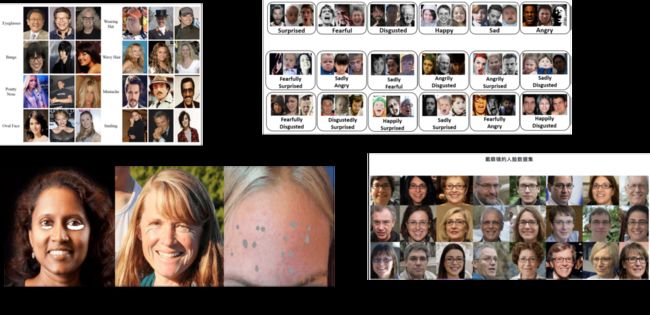
多人类任务网络设计:
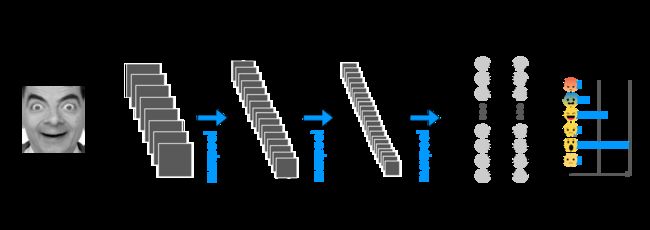
人脸识别vs表情识别:
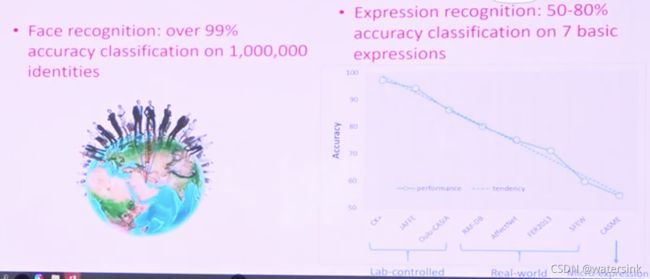
多任务训练问题:
1.多任务训练过程中的此消彼长
2.类别不平衡问题
(1)加大权重,性别提升非常明显
(2)focal loss,有一定效果
3.难易学习问题
(1)【易】剪枝,【难】堆层,效果不行
4.年龄,分类替代回归
(1)万物皆可分
(2)stagewise思想,减少参数量,例如, (0 ∼ 10,10 ∼ 20,20 ∼ 30,30 ∼ 40,40 ∼ 50,50 ∼ 60,60 ∼ 70,70 ∼ 80,80 ∼ 90)==(0 ∼ 30,30 ∼ 60,60 ∼ 90)*(小,中,大)
5.表情识别界线模糊问题
7个类别,"happy":0, "angry":1, "calm":2, "scared":3, "sad":4, "disgust":5, "surprised":6
(1)堆数据
(2)全局收敛,定点迭代,局部调优 from large to small,from general to specific
(3)运气成分,极致精神cover smile属性
6.eyeglass(yes,no),darkglass(yes,no)
双2分类-->一3分类(eyeglass,darkglass,none)
优点,减少参数量,减少计算量
7.性别精度不足
(1)relu --->prelu:训练更稳定,89.86%-->91.09%-->92.31%-->92.92%
(2)adam--->sgd+momentum, 92.92%--->94.13%-->95.04%-->95.24%-->95.35%
(3)固定权重训练,不奏效
8.人脸关键点检测和人脸属性的适配问题
(1)好马还需好鞍配
9.左右眼问题
(1)特征split,侧脸无法覆盖
(2)排列组合,00,01,10,11,不奏效
(3)左右眼遮挡--->根据位置加遮挡--->去掉
(4)左右眼开闭,嘴巴开闭--->关键点计算---->模块放哪里
(5)左右眼遮挡--->106关键点分类

时间是金钱,细节是魔鬼:
pytorch 分类,回归的维度区别:
分类:torch.Size([512, N]) torch.Size([512])
回归:torch.Size([512]) torch.Size([512])
age_loss = smoothL1(net_output['age'].squeeze(), ground_truth['age_labels'])
错误:torch.Size([512, 1]) torch.Size([512]),导致训练发散,不收敛pytorch的归一化和tf的区别,为什么pytorch可以不做归一化?
train_transform = transforms.Compose([
transforms.Resize(size =(128, 256)),
transforms.RandomCrop(size = (112,224)),
transforms.RandomHorizontalFlip(p=0.5),
transforms.ColorJitter(brightness=0.3, contrast=0.3, saturation=0.3, hue=0),
transforms.RandomAffine(degrees=20, translate=(0.1, 0.1), scale=(0.8, 1.2),
shear=None, resample=False, fillcolor=(255, 255, 255)),
transforms.ToTensor(),
transforms.Normalize(mean, std)
])
onnx:x = (x/255.0 -mean)/std
onnx slim:
pytorch 1.3:
torch.onnx.export(plfd_backbone, dummy_input, args.onnx_model, verbose=True,
input_names=input_names, output_names=output_names, keep_initializers_as_inputs=True)
pytorch1.2:
torch.onnx.export(plfd_backbone, dummy_input, args.onnx_model, verbose=True,
input_names=input_names, output_names=output_names)