目录
openGauss数据库SQL引擎
一.SQL引擎概览
二.SQL解析
三.查询优化
Ⅰ.查询重写
Ⅱ.路径搜索
Ⅲ.代价估算openGauss数据库执行器技术
openGauss存储技术
openGauss事务机制
openGauss数据库安全
openGauss数据库SQL引擎
三、查询优化
Ⅲ、代价估算
优化器会根据生成的逻辑执行计划枚举出候选的执行路径,要确保执行的高效,需要在这些路径中选择开销最小、执行效率最高的路径。那么如何评估这些计划路径的执行开销就变得非常关键。代价估算就是来完成这项任务的,基于收集的数据统计信息,对不同的计划路径建立代价估算模型,评估给出代价,为路径搜索提供输入。
- 统计信息
统计信息是计算计划路径代价的基石,统计信息的准确度对代价估算模型中行数估算和代价估算起着至关重要的作用,直接影响查询计划的优劣。openGauss支持使用Analyze命令语句来完成对全库、单表、列、相关性多列进行收集统计信息。
由于统计信息直接影响代价计算的准确度,所以统计信息的收集的频率就是一个非常敏感的参数,如果统计信息收集的频率太低,则会导致统计信息的滞后,相反,如果过于频繁的收集统计信息,则会间接影响查询的性能。
通常数据库管理系统会提供手动的收集统计信息的方法,openGauss支持通过Analyze命令来收集统计信息,同时数据库管理系统也会根据数据变化的情况自动决定是否重新收集统计信息,例如当一个表中的数据频繁的更新超过了一个阈值,那么就需要自动更新这个表的统计信息。在查询优化的过程中,如果优化器发现统计信息的数据已经严重滞后,也可以发起统计信息的收集工作。
表级的统计信息通常包括元组的数量(N)、表占有的页面数(B),而列级的统计信息则主要包括属性的宽度(W)、属性的最大值(Max)、最小值(Min)、高频值(MCV)等等,通常针对每个列会建立一个直方图(H),将列中的数据按照范围以直方图的方式展示出来,可以更方便的计算选择率。
直方图通常包括等高直方图、等频直方图和多维直方图等等,这些直方图可以从不同的角度来展现数据的分布情况,openGauss采用的是等高直方图,直方图的每个柱状体都代表了相同的频率。
- 选择率
通过统计信息,代价估算系统就可以了解一个表有多少行数据、用了多少个数据页面、某个值出现的频率等,然后根据这些信息就能计算出一个约束条件(例如SQL语句中的WHERE条件)能够过滤掉多少数据,这种约束条件过滤出的数据占总数据量的比例称为选择率。

约束条件可以是独立的表达式构成的,也可以是由多个表达式构成的合取范式或析取范式,其中独立的表达式需要根据统计信息计算选择率,合取范式和析取范式则借助概率计算的方法获得选择率。
合取范式:P(A and B) = P(A) + P(B) – P(AB)
析取范式:P(AB) = P(A) × P(B)
假设要对约束条件A > 5 AND B < 3计算选择率,那么首先需要对A > 5和B < 3分别计算选择率,由于已经有了A列和B列的统计信息,因此可以根据统计信息计算出A列中值大于5的数据比例,类似的还可以计算出B列的选择率。假设A>5的选择率为0.3,B<3的选择率为0.5,那么A > 5 AND B < 3的选择率为:
P(A>5 and B<3)
= P(A>5) + P(B<3) – P(A>5)×P(B<3)
= 0.3 + 0.5 – 0.3×0.5
= 0.65
由于约束条件的多样性,选择率的计算通常会遇到一些困难,例如选择率在计算的过程中通常假设多个表达式之间是相互“独立”的,但实际情况中不同的列之间可能存在函数依赖关系,因此这时候就可能导致选择率计算不准确。
- 代价估算方法
openGauss的优化器是基于代价的优化器,对每条SQL语句,openGauss都会生成多个候选的计划,并且给每个计划计算一个执行代价,然后选择代价最小的计划。
当一个约束条件确定了选择率之后,就可以确定每个计划路径所需要处理的行数,并根据行数可以推算出所需要处理的页面数。当计划路径处理页面的时候,会产生IO代价,而当计划路径处理元组的时候(例如针对元组做表达式计算),会产生CPU代价,由于openGauss是分布式数据库,在CN和DN之间传输数据(元组)会产生通信的代价,因此一个计划的总体代价可以表示为:
总代价 = IO代价 + CPU代价 + 通信代价
openGauss把所有顺序扫描一个页面的代价定义为单位1,所有其它算子的代价都归一化到这个单位1上。比如把随机扫描一个页面的代价定义为4,即认为随机扫描一个页面所需代价是顺序扫描一个页面所需代价的4倍。又比如,把CPU处理一条元组的代价为0.01,即认为CPU处理一条元组所需代价为顺序扫描一个页面所需代价的百分之一。
从另一个角度来看,openGauss将代价又分成了启动代价和执行代价,其中:
总代价 = 启动代价 + 执行代价
1) 启动代价
从SQL语句开始执行,到此算子输出第一条元组为止,所需要的代价,称为启动代价。有的算子启动代价很小,比如基表上的扫描算子,一旦开始读取数据页,就可以输出元组,因此启动代价为0。有的算子的启动代价相对较大,比如排序算子,它需要把所有下层算子的输出全部读取到,并且把这些元组排序之后,才能输出第一条元组,因此它的启动代价比较大。
2) 执行代价
从输出第一条元组开始,至查询结束,所需要的代价,称为执行代价。这个代价中又可以包含CPU代价、IO代价和通信代价,执行代价的大小与算子需要处理的数据量有关,与每个算子完成的功能有关。处理的数据量越大、算子需要完成的任务越重,则执行代价越大。
3) 总代价
代价计算是一个自底向上的过程,首先计算扫描算子的代价,然后根据扫描算子的代价计算连接算子的代价以及Non-SPJ算子的代价。
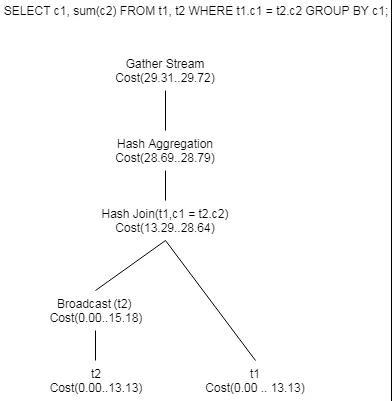
图8 代价计算示例
如图8所示,SQL查询中包含两张表,分别为t1、t2,它的某个候选计划的计算过程如下:
(1)扫描t1的启动代价为0.00,总代价为13.13。总代价中既包括了扫描表页面的IO代价,也包括了对元组进行处理的CPU代价,同理可以获得对t2表扫描的代价。
(2)由于连接条件(t1.c1 = t2.c2)中的列与两表的分布列不同,因此该计划对t2进行了广播(Broadcast),广播算子的总代价为15.18,此代价已经包括了顺序扫描t2的代价13.13。
(3)使用Hash Join时,必须先为内表的数据建立Hash表,因此Hash Join具有启动代价,它的启动代价是13.29,Hash Join的总代价为28.64。
(4)聚集算子的启动代价为28.69,总代价为28.79。
(5)依次类推,此计划最终的启动代价为29.31,总代价为29.72。
至此,openGauss数据库SQL引擎章节全部结束,下期文章将开始连载openGauss数据库执行器技术章节,敬请期待。
未完待续......