数据库Mysql其他细节点
目录
什么是视图?以及视图的使用场景有哪些?
使用JDBC连接数据库
preparedStatement和statement的区别
在数据库中查询语句速度很慢,如何优化?
union和union all有什么不同?union和union all有什么不同?
Limit的优化
数据库count语句相关问题
“order by”是怎么工作的?
为什么不建议把数据库部署在docker容器内
为什么有的查询语句会忽然变得很慢?
为什么表数据删掉一半,表文件大小不变?
如何判断一个数据库是不是出问题了?
为什么还有Kill不掉的语句?
为什么自增主键会出现不连续的情况?
如何设计一个论坛表
什么是视图?以及视图的使用场景有哪些?
| 视图是一种虚拟的表,具有和物理表相同的功能。可以对视图进行增,改,查,操作,视图通常是有一个表或者多个表的行或列的子集。对视图的修改不影响基本表。它使得我们获取数据更容易,相比多表查询。 1.只暴露部分字段给访问者,所以就建一个虚表,就是视图。 2.查询的数据来源于不同的表,而查询者希望以统一的方式查询,这样也可以建立一个视图,把多个表查询结果联合起来,查询者只需要直接从视图中获取数据,不必考虑数据来源于不同表所带来的差异 |
使用JDBC连接数据库
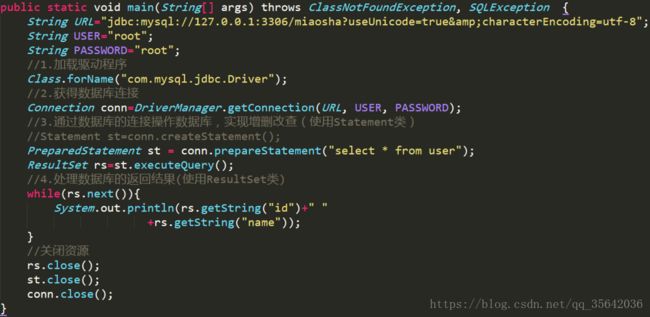
preparedStatement和statement的区别
| 说一下preparedStatement和statement的区别与联系:在JDBC应用中,如果你已经是稍有水平开发者,你就应该始终以PreparedStatement代替Statement.也就是说,在任何时候都不要使用Statement。PreparedStatement 接口继承 Statement ,PreparedStatement 实例包含已编译的 SQL 语句, 所以其执行速度要快于 Statement 对象。 Statement为一条Sql语句生成执行计划, 如果要执行两条sql语句 select colume from table where colume=1;select colume from table where colume=2; 会生成两个执行计划 一千个查询就生成一千个执行计划! PreparedStatement用于使用绑定变量重用执行计划 select colume from table where colume=:x; 通过set不同数据只需要生成一次执行计划,可以重用。 并且PreparedStatement可以防止SQL攻击 |
在数据库中查询语句速度很慢,如何优化?
| 1.建索引 2.减少表之间的关联 3.优化sql,尽量让sql很快定位数据,不要让sql做全表查询,应该走索引,把数据量大的表排在前面 4.简化查询字段,没用的字段不要,以及对返回结果的控制,尽量返回少量数据 5.尽量用PreparedStatement来查询,不要用Statement |
union和union all有什么不同?union和union all有什么不同?
| UNION在进行表链接后会筛选掉重复的记录,所以在表链接后会对所产生的结果集进行排序运算,删除重复的记录再返回结果。实际大部分应用中是不会产生重复的记录,最常见的是过程表与历史表UNION。 UNION ALL只是简单的将两个结果合并后就返回。这样,如果返回的两个结果集中有重复的数据,那么返回的结果集就会包含重复的数据了。 从效率上说,UNION ALL 要比UNION快很多,所以,如果可以确认合并的两个结果集中不包含重复的数据的话,那么就使用UNION ALL。 |
Limit的优化
| 在Limit的偏移量offset上,比如limit 100000,10虽然最后只返回10条数据,但是偏移量却高达100000,数据库的操作其实是拿到100010数据,然后返回最后10条。 那么解决思路就是,我能不能跳过100000条数据然后读取10条,而不是读取100010条数据然后返回10条数据。(案例中出发于无法直接推算出第100000条数据的id) 原SQL语句:select * from mytbl order by id limit 100000,10; 改进后的SQL语句如下: select * from mytbl where id >= (select id from mytbl order by id limit 10000,1) limit 10; 注:假设id是主键索引,那么里层走的是索引,外层也是走的索引,所以性能大大提高 |
数据库count语句相关问题
| count语义 count()是一个聚合函数,对于返回的结果集,一行行地判断,如果count函数的参数不是NULL,累计值就加1,否则不加。最后返回累计值。 count实现方式:在不同的MySQL引擎中,count(*)有不同的实现方式。
为什么InnoDB不跟MyISAM一样,也把数字存起来呢? 这是因为即使是在同一个时刻的多个查询,由于多版本并发控制(MVCC)的原因,InnoDB表“应该返回多少行”也是不确定的。 不同count语句的对比: count(*)、count(主键id)和count(1) 都表示返回满足条件的结果集的总行数;而count(字段),则表示返回满足条件的数据行里面,参数“字段”不为NULL的总个数。 对于count(主键id)来说,InnoDB引擎会遍历整张表,把每一行的id值都取出来,返回给server层。server层拿到id后,判断是不可能为空的,就按行累加。 对于count(1)来说,InnoDB引擎遍历整张表,但不取值。server层对于返回的每一行,放一个数字“1”进去,判断是不可能为空的,按行累加。 对于count(字段)来说:
对于count(*)来说,它并不会把全部字段取出来,而是专门做了优化,不取值。count(*)肯定不是null,按行累加。 所以结论是:按照效率排序的话,count(字段) count(*)执行很慢,应该如何优化? 在实际使用中(默认使用Innodb),随着系统中记录数越来越多,我们会发现系统执行select count(*) from t的速度变得越来越慢(不带任何where条件时都慢) 1. 用缓存系统保存计数 可以用一个Redis服务来保存这个表的总行数。这个表每被插入一行Redis计数就加1,每被删除一行Redis计数就减1。 但是这种情况可能会存在数据不一致的问题。我们用以下的一些场景来进行解释:
2. 在数据库保存计数 把这个计数直接放到数据库里单独的一张计数表C中 此种方法可以较好地解决数据不一致的问题,俗称以子之矛攻子之盾,因为我们充分利用“事务”这个特性 假设我们有如下两个会话 可以看到,虽然会话B的读操作仍然是在T3执行的,但是因为这时候更新事务还没有提交,所以计数值加1这个操作对会话B还不可见。 因此,会话B看到的结果里, 查计数值和“最近100条记录”看到的结果,逻辑上就是一致的。
在用一个计数表记录一个业务表的总行数,在往业务表插入数据的时候,我们需要给计数值加1。 逻辑实现上是启动一个事务,执行两个语句: 1. insert into 数据表; 2. update 计数表,计数值加1。 问:从系统并发能力的角度考虑,怎么安排这两个语句的顺序呢? 答:从并发系统性能的角度考虑,应该先插入操作记录,再更新计数表。因为更新计数表涉及到行锁的竞争,先插入再更新能最大程度地减少事务之间的锁等待,提升并发度。(不同业务表更新数据时,由于我们通常是会给计数表加唯一索引,所以不同业务表更新时不会有行锁冲突)。知识点在《行锁功过:怎么减少行锁对性能的影响?》 其实,把计数放在Redis里面,不能够保证计数和MySQL表里的数据精确一致的原因,是因为这两个不同的存储构成的系统,不支持分布式事务,无法拿到精确一致的视图。而把计数值也放在MySQL中,就解决了一致性视图的问题。 |

“order by”是怎么工作的?
为什么不建议把数据库部署在docker容器内
为什么有的查询语句会忽然变得很慢?
| 其实数据库语句执行忽然变得很慢,可能是因为数据库正在flush脏页 根据WAL机制。InnoDB在处理更新语句的时候,只做了写日志这一个磁盘操作。 当内存数据页跟磁盘数据页内容不一致的时候,我们称这个内存页为“脏页”。内存数据写入到磁盘后,内存和磁盘上的数据页的内容就一致了,称为“干净页”。 在什么情况下数据库需要执行flush呢?
所以,InnoDB会在后台刷脏页,而刷脏页的过程是要将内存页写入磁盘。所以,无论是你的查询语句在需要内存的时候可能要求淘汰一个脏页,还是由于刷脏页的逻辑会占用IO资源并可能影响到了你的更新语句,都可能是造成我们从业务端感知到数据库查询变慢了的原因
|
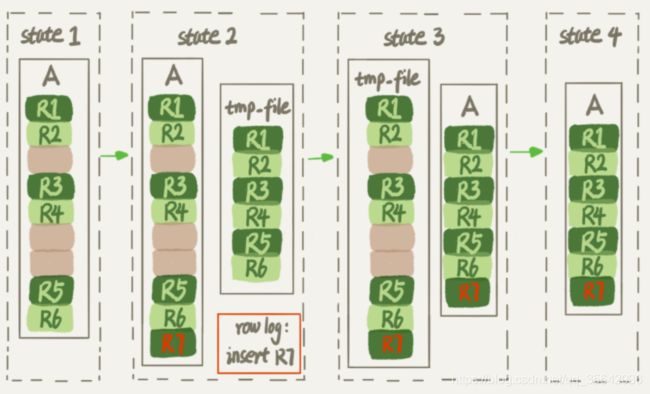
为什么表数据删掉一半,表文件大小不变?
| 在我们使用delete语句从innodb表中删除数据的时候,实际上的过程是到对应的数据库上面标记该记录已经删除,但是由于数据页通常不会仅仅只有这一条数据,删除数据只能表现为该数据页中出现一些“空洞”,因此在我们看来,就表现为delete了数据以后,数据库空间没有变小。 如果数据是按照索引递增顺序插入的,那么索引是紧凑的。但如果数据是随机插入的,就可能造成索引的数据页分裂。而分裂就会导致数据空间的利用率下降。 另外,更新索引上的值,可以理解为删除一个旧的值,再插入一个新值。也是会造成空洞的。 以上的情况发生后,通常只能通过重建表对数据空间进行收缩。 我们可以使用以下语句对表进行重建: alter table A engine=InnoDB;
在Mysql5.5之前,其逻辑为:新建一个与表A结构相同的表B,然后按照主键ID递增的顺序,把数据一行一行地从表A里读出来再插入到表B中。 注意:在整个DDL过程中,表A中不能有更新。 从Mysql5.6版本开始,执行以上语句,其逻辑变为(Online DDL):
可以看到,Online DDL其最大的特点在于支持表重建时插入数据 |

如何判断一个数据库是不是出问题了?
为什么还有Kill不掉的语句?
| 通常执行kill命令后,会告诉执行线程,这条语句已经不需要继续执行了,可以开始“执行停止的逻辑了”。 Mysql有以下两个Kill命令: 1. kill query + thread id (可用此语句终止等待锁的线程) 1. 把线程的运行状态改成THD::KILL_QUERY(将变量killed赋值为THD::KILL_QUERY)(一个语句执行过程中有多处“埋点”,在这些“埋点”的地方判断线程状态,如果发现线程状态是THD::KILL_QUERY,才开始进入语句终止逻辑) 2. 给线程发一个信号(若线程处于等待状态,它通常是可以被唤醒的) 2. kill connection(令客户端断开连接,实际上服务端上这条语句还在执行过程中) 执行以上语句后,会把当前连接执行的线程状态设置为:KILL_CONNECTION。 对一个阻塞状态下的连接执行以上语句后,客户端连接将会报:Lost connection to MySQL server during query 此时,执行show processlist显示server端的语句执行,将会看到其线程状态为Killed(若线程状态是KILL_CONNECTION,同样也会显示为Killed)
注意:kill connection本质上只是把客户端的sql连接断开,后面的执行流程还是要走kill query的 处于Killed状态的线程,我们之所以还能在processlist中看到它,本质上是因为线程没有执行到判断线程状态的逻辑,若等到满足进入InnoDB的条件后,该线程的语句将继续执行,然后才有可能判断到线程状态已经变成了KILL_QUERY或者KILL_CONNECTION,再进入终止逻辑阶段。之后该线程才算被终止。 例如以下情况会导致我们在执行kill后还能看到处于killed状态的语句: 1. 当当前线程个数达到了/超过InnoDB的并发线程上限数,对于正在阻塞状态下的语句(没有得到执行),执行kill connection后也只会标识为Killed,需要等待后面得到执行机会时才会进入终止逻辑。 2. IO压力过大,读写IO的函数一直无法返回,导致不能及时判断线程的状态 3. 终止逻辑耗时较长,如以下场景:
在客户端查询中,执行ctrl+c底层逻辑是啥? 执行Ctrl+C的时候,是MySQL客户端另外启动一个连接,然后发送一个kill query 当前线程的命令。 |

为什么自增主键会出现不连续的情况?
| 一般来说,使用自增主键可以让主键索引尽量地保持递增顺序插入,避免了页分裂,其索引更紧凑。 Mysql对于自增主键值的保存策略 1. MyISAM引擎的自增值保存在数据文件中 2. InnoDB引擎的自增值,其实是保存在了内存里,并且到了MySQL 8.0版本后,才有了“自增值持久化”的能力(将自增值的变更记录在了redo log中,重启的时候依靠redo log恢复重启之前的值) Mysql对于自增主键的修改策略 1. 如果插入数据时id字段指定为0、null 或未指定值,那么就把这个表当前的 AUTO_INCREMENT值填到自增字段; 2. 如果插入数据时id字段指定了具体的值,就直接使用语句里指定的值。 假设X为插入时设置的主键值,Y为数据库实际主键值 1. 如果X 2. 如果X≥Y,就需要把当前自增值修改为新的自增值。 新的自增值生成算法是:从auto_increment_offset开始,以auto_increment_increment(双M的主备结构里要求双写的时候,我们可能会设置auto_increment_increment=2,让一个库的自增id都是奇数,另一个库的自增id都是偶数,避免两个库生成的主键发生冲突)为步长,持续叠加,直到找到第一个大于X的值,作为新的自增值。 可能会出现自增主键不连续的场景: 1. 唯一键冲突:插入数据时,申请到了新的主键值,但是实际插入时出现唯一索引deplicate key失败,此时插入失败,但是实际mysql记录的自增主键值已经+1,如原来主键为1,下次分配时就是3了; 2. 事务回滚: 自增值为什么不能回退。 假设有两个并行执行的事务,在申请自增值的时候,为了避免两个事务申请到相同的自增id,肯定要加锁,然后顺序申请。 假设事务A申请到了id=2, 事务B申请到id=3,那么这时候表t的自增值是4,之后继续执行。 事务B正确提交了,但事务A出现了唯一键冲突。 如果允许事务A把自增id回退,也就是把表t的当前自增值改回2,那么就会出现这样的情况:表里面已经有id=3的行,而当前的自增id值是2。 接下来,继续执行的其他事务就会申请到id=2,然后再申请到id=3。这时,就会出现插入语句报错“主键冲突”。 而为了解决这个主键冲突,有两种方法: 每次申请id之前,先判断表里面是否已经存在这个id。如果存在,就跳过这个id。但是,这个方法的成本很高。因为,本来申请id是一个很快的操作,现在还要再去主键索引树上判断id是否存在。 把自增id的锁范围扩大,必须等到一个事务执行完成并提交,下一个事务才能再申请自增id。这个方法的问题,就是锁的粒度太大,系统并发能力大大下降。 可见,这两个方法都会导致性能问题。造成这些麻烦的罪魁祸首,就是我们假设的这个“允许自增id回退”的前提导致的。 因此,InnoDB放弃了这个设计,语句执行失败也不回退自增id。也正是因为这样,所以才只保证了自增id是递增的,但不保证是连续的。 3. MySQL对于批量插入语句(insert … select、replace … select、load data等)使用批量申请自增ID的方式 |
如何设计一个论坛表
推荐阅读:Mysql灵魂十连问