《SQL必知必会》(9,10,11):汇总数据、分组数据、使用子查询
上回:《SQL必知必会》(7,8):创建计算字段、使用数据处理函数
文章目录
- 第九课:汇总数据
-
- 9.1 聚合函数
-
- AVG() 函数
- COUNT()函数
- MAX()函数
- MIN()函数
- SUM()函数
- 9.2 聚集不同值
- 9.3 组合聚集函数
- 9.4 小结
- 第十课:分组数据
-
- 10.1 数据分组
- 10.2 创建分组
- 10.3 过滤分组
- 10.4 分组和排序
- 10.5 select子句顺序
- 10.6小结
- 第十一课:使用子查询
-
- 11.1 子查询
- 11.2 利用子查询进行过滤
- 11.3 作为计算字段使用子查询
- 11.4 小结
第九课:汇总数据
9.1 聚合函数
就是我们需要汇总的,但不一定要检索出来,比我我们需要数据库表的行数,或者是某些行的和,最大值,最小值,平均值等等。。。
聚合函数(aggregate function):对某些行 运行的函数,计算并返回一个值。
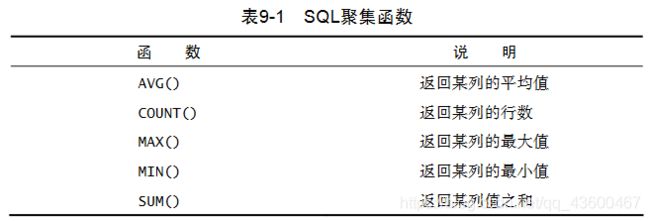
下面简单举例子,逐个说明。
基于此表,Products
AVG() 函数
即 average 。
平均值的计算公式,想必不陌生:
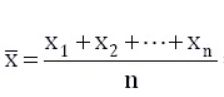
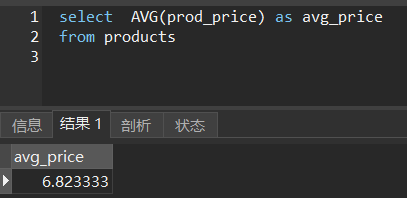
返回Products表中所有产品的平均价格:
select AVG(prod_price) as avg_price
from products
AVG()函数只能用于单个列的平均值,一行数据是由多个列组成的。如果要获得多个列的平均值,必须使用多个AVG()函数。
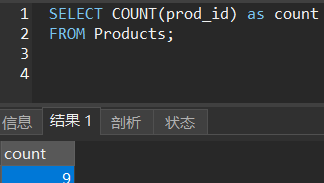
COUNT()函数
行数。
SELECT COUNT(prod_id) as count
FROM Products;
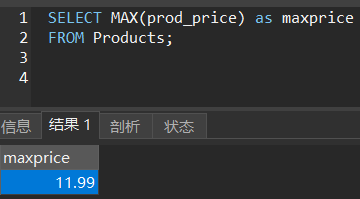
MAX()函数
最大值。
SELECT MAX(prod_price) as maxprice
FROM Products;
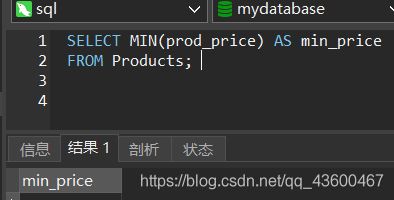
MIN()函数
最小值。
SELECT MIN(prod_price) AS min_price
FROM Products;
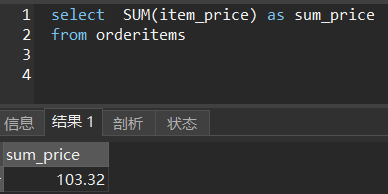
SUM()函数
求和。锤子刘涛TNT
select SUM(item_price) as sum_price
from orderitems
9.2 聚集不同值
ALL 和distinct ;
distinct就是除去重复值,结果集中都是不相同的值。
默认是all;
SELECT AVG(DISTINCT prod_price) AS avg_price
FROM Products
WHERE vend_id = 'DLL01';
这个就是,平均值,只考虑不同的价格的情况。实际中大概是每个种类的价格。
注意,distinct不能用于count(*)
如果指定列名,则distinct只能用于count()。类似的,distinct必须使用列名,不能用于计算或表达式。
9.3 组合聚集函数
聚集函数可以组合使用,一个或多个都可以。
如:
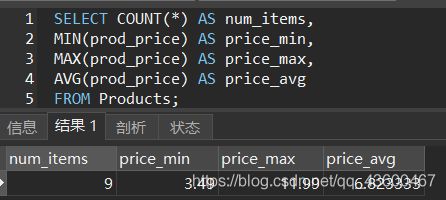
SELECT COUNT(*) AS num_items,
MIN(prod_price) AS price_min,
MAX(prod_price) AS price_max,
AVG(prod_price) AS price_avg
FROM Products;
9.4 小结
聚集函数用来汇总数据。SQL支持5个聚集函数,可以用多种方法使用它们,返回所需的结果。这些函数很高效,它们返回结果一般比你在自己的客户端应用程序中计算要快得多。
第十课:分组数据
group by子句 和 having子句 !很重要
10.1 数据分组
我们用上一节课学到的,
如:可以查询某个供应商DLL01提供的产品数目,但是我们无法查询所有供应商各自提供的产品数目。
所以我们要解决他,就要分组,使用分组可以将数据分为多个逻辑组。对每个组进行聚集计算。
10.2 创建分组
分组是使用select语句的group by子句建立的。
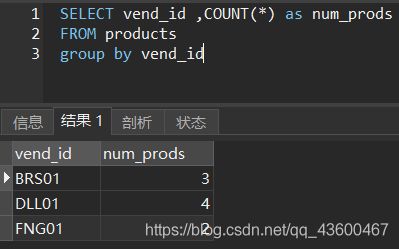
这个就是在products表中查询每个vend_id的数量。
group by vend_id 就是以vend_id 来分组。
在使用group by之前有一些规定:
- group by子句可以包含任意数量的列,因此分组可以嵌套,就像一维数组中嵌套一维数组,然后就变成了二维数组,俄罗斯套娃了解一下!!
- 子句中每一列都必须是检索列或有效的的
表达式
表达式是一个或多个值,运算符和SQL函数的组合,它们计算结果为确定的值。 这些SQL 表达式就像公式,它们是用查询语言编写的。还可以使用它们在数据库中查询特定的数据集。
- 大多数SQL不支持group by 列是文本等可变长度的数据类型。
- 如果分组列中有null ,那么将多行的null 分为一组。
- group by子句必须出现在where后边,order by之前。
10.3 过滤分组
除了能用group by分组数据,还可以用having过滤分组。规定包括哪些分组,排除哪些分组。
where和having;
- where是过滤指定的是行而不是分组,where没有分组的概念。
- having非常类似where。目前我们了解过的所有类型的where都可以用having来代替。
唯一的差别是,where过滤行,having过滤分组。
例子:
SELECT cust_id, COUNT(*) AS orders
FROM Orders
GROUP BY cust_id
HAVING orders >= 2;
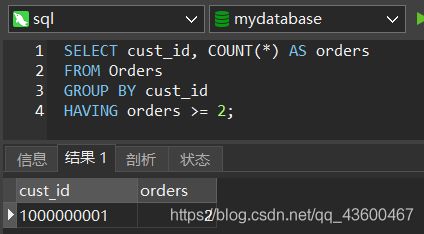
第四行代码就是过滤 orders >= 2 的情况。
having 和 where差别
这里有另一种理解方法,WHERE在数据分组前进行过滤,HAVING在数据分组后进行过滤。这是一个重要的区别,WHERE排除的行不包括在分组中。这可能会改变计算值,从而影响 HAVING子句中基于这些值过滤掉的分组。
在同一条SQL中可不可以同时使用where和having呢?
答:也是可以的
嗯哼?
例:
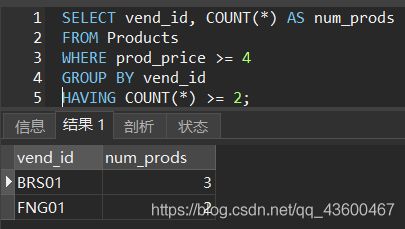
列出具有两个以上产品且其价格大于等于4的供应商:
SELECT vend_id, COUNT(*) AS num_prods
FROM Products
WHERE prod_price >= 4
GROUP BY vend_id
HAVING COUNT(*) >= 2;
10.4 分组和排序
group by 和 order by 经常一块干活,但是他们非常不一样!!

一般在使用group by的时候 也要给出 order by,这可以保证数据正确排序的唯一方法。不能仅依赖group by排序数据。
下面举个例子来对比 :
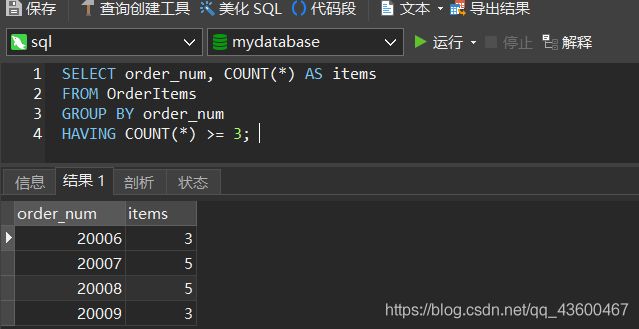
SELECT order_num, COUNT(*) AS items
FROM OrderItems
GROUP BY order_num
HAVING COUNT(*) >= 3;
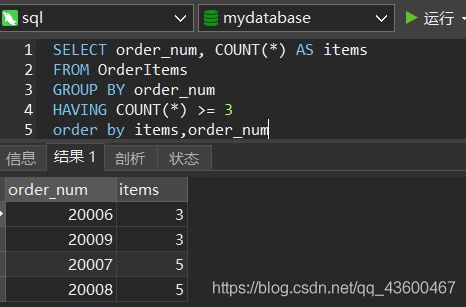
SELECT order_num, COUNT(*) AS items
FROM OrderItems
GROUP BY order_num
HAVING COUNT(*) >= 3
order by items,order_num
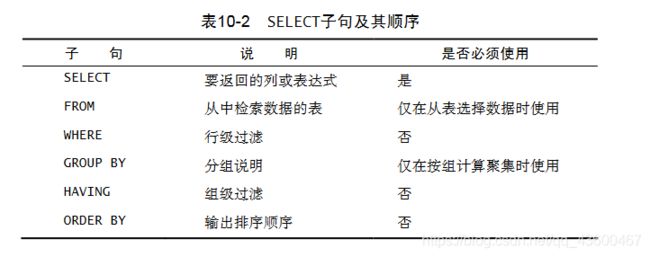
10.5 select子句顺序
10.6小结
这一届我们了解到,group by将数据分组,having 过滤分组数据,where和having使用的区别。
第十一课:使用子查询
11.1 子查询
查询(query):任何SQL语句本质都是查询,但是这个术语一般是指select语句。
注意:MySQL中,是在4.1版本引入的,之前的版本不支持子查询。
11.2 利用子查询进行过滤
我们用的所有表都是关系表,可以点击my头像,找数据库分组中的附录 那篇文章了解一下。
订单存储在两个表中。
- 每个订单包含订单编号,客户ID,订单日期,在Orders表中存储为一行。
- 各订单的物品存储在相关的OrderItems表中。
- Orders表不存储顾客信息,只存储顾客ID。顾客的实际信息存储在Customers表中。
我们需要列出订购物品 RGAN01的所有顾客,应该怎么检索?
- 在OrderItems表中检索包含物品 RGAN01 的订单编号。
- 在Orders表中 列出 订单编号的所有顾客ID
- 检索所有顾客信息
我们的这三步骤是紧密相连的,是有关系的。我们可以单独执行。
第一条SQL:我们是要找出order_num 列。
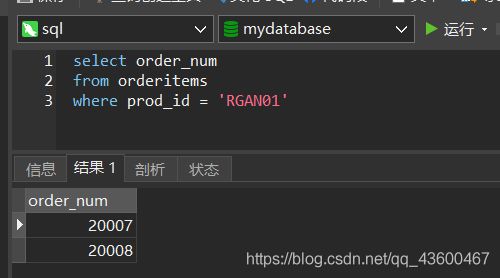
现在我们知道了哪个订单包含要检索的物品。下一步我们就要查询 相关的客户ID。
第二步:
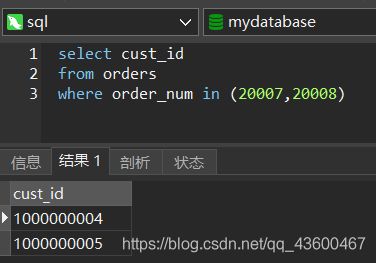
。
现在我们把这两个步骤结合起来。
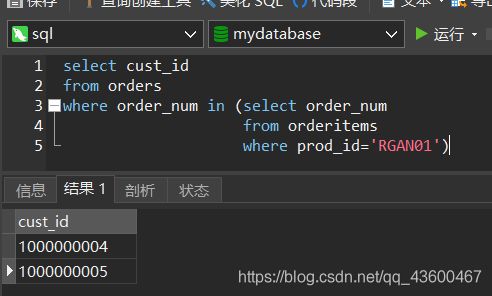
执行步骤跟 单独写SQL一样。
到这 我们走完了两步还剩最后一个。检索顾客ID的顾客信息。
第三步:
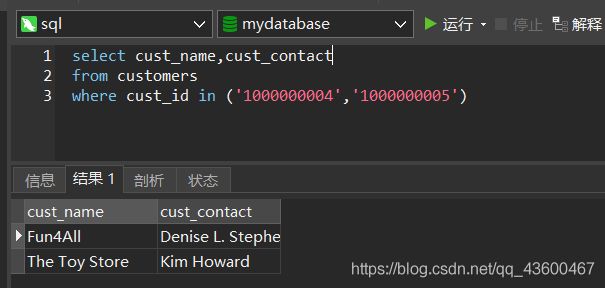
可以把其中的where子句转换为子查询:
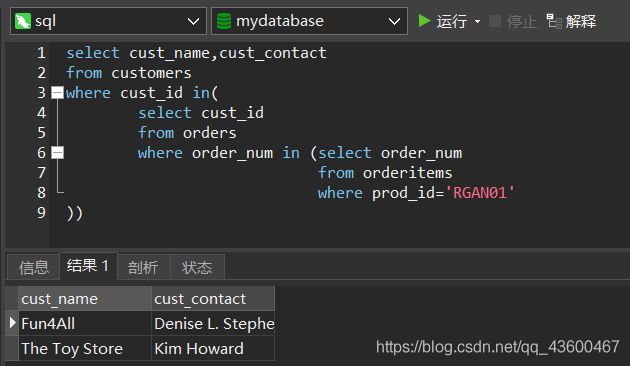
与前边一样,只是多了一步。
warning !!!
作为子查询的select语句只能查询单列,不能返回多个列。
子查询性能不太好。后边(下一节)我们会有更好的解决方法。
11.3 作为计算字段使用子查询
假如需要显示Customers表中每个顾客的订单总数。订单与相应的顾客ID存在Orders表中。
解:
- 在Customers表中检索顾客列表。
- 对于检索出的每个顾客,统计在Orders表中的订单数目。
SELECT COUNT(*) AS orders
FROM Orders
WHERE cust_id = '1000000001';
要对每个顾客执行count(*) 应该将它作为一个查询。
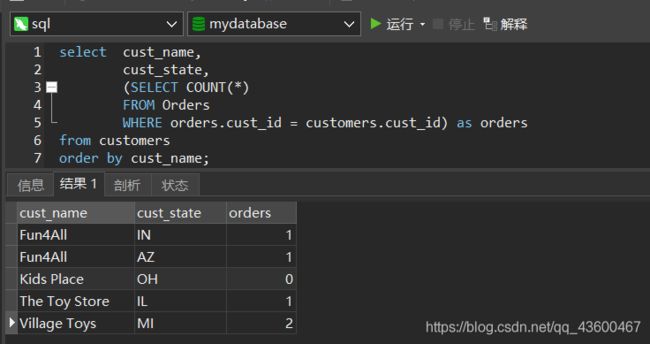
orders.cust_id = customers.cust_id
是完全限定列名,table.column;
很重要!!!
11.4 小结
学习了 子查询,如何用。子查询常用在where子句的in操作符中,以及用来填充的计算列。