20189206 2018-2019-2 《密码与安全新技术专题》 课程总结
课程:《密码与安全新技术专题》
班级: 1892
姓名: 王子榛
学号:20189206
上课教师:王志强
1.本学期讲座的学习总结
第七次课 —— 各组论文学习
第一组:在10秒内找到未知的恶意:在Google-Play规模上大规模审查新的威胁
背景内容
Android设备已经成为市场上的主流产品之一,也带来了一个充满活力的应用程序生态系统,经统计Android用户已经安装了数百万个应用程序,这种开放的应用开发环境不仅带来了各式各样的应用程序,同样,Android恶意软件也十分猖獗,常见的有伪装成一个有用的程序,通常通过重新打包合法的应用程序,肆虐,例如,拦截一个人的消息,偷窃,发送presmiumSMS消息等等。
为了解决这种问题,论文针对应用程序审查,Google Play运营Bouncer,这是一种安全服务,可以静态扫描应用程序中的已知恶意代码,然后在Google云端的模拟环境中执行该操作,以检测隐藏的恶意行为。但现存问题是静态方法不适用于新威胁,而动态问题可以通过能够对测试环境进行指纹识别的应用程序来识别。
实际上,绝大多数Android恶意软件都是重新打包的应用程序,经过观察结果也表明,恶意重新打包的应用程序是Android恶意软件的支柱。论文提出了一种新颖、高度可扩展的审查机制,用于在一个市场或跨市场上检测重新包装的Android恶意软件————MassVet,为了检查新的应用程序,MassVet针对整个市场对其进行了高效的DiffCom分析。
检测范围

MassVet
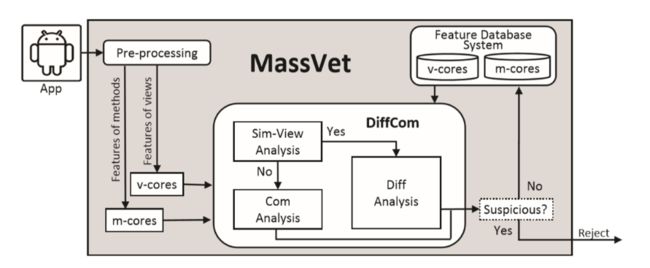
MassVet首先处理所有的应用程序,包括用于查看结构的数据库和用于数据库的数据库。两个数据库都经过排序以支持二进制搜索,并用于审核提交到市场的新应用程序。考虑一个重新包装的AngryBird。一旦上载到市场,它首先在预处理阶段自动拆解成一个小型表示,从中可以识别其接口结构和方法。它们的功能(用于视图,用户界面,小部件和事件的类型,以及方法,控制流程和代码)通过计算映射到v核和m核分别是视图和控制流的几何中心。应用程序的v-cores首先用于通过二进制搜索查询数据库。一旦匹配满足,当存在具有类似的AngryBird用户界面结构的另一个应用程序时,将重新打包的应用程序与方法级别的市场上的应用程序进行比较以识别它们的差异。然后自动分析这些不同的方法(简称差异)以确保它们不是广告库并且确实是可疑的,如果是,则向市场报告。当没有任何东西2时,MassVet继续寻找方法数据库中的AngryBird的m核心。如果找到了类似的方法,我们的方法会尝试确认包含方法的app确实与提交的AngryBird无关,并且它不是合法的代码重用。在这种情况下,MassVet报告认为是令人感到满意的。所有这些步骤都是完全完全自动化,无需人工干预。
v-core
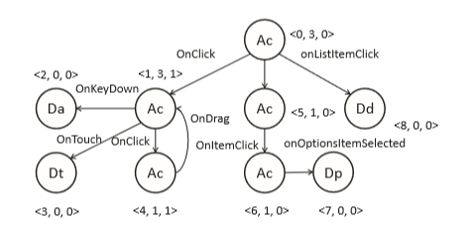
特征提取,将UI结构建模为视图,这个视图是一个有向加权图,包括应用程序中的所有视图以及它们之间的导航关系。在这样的图上,每个节点都是一个视图,其活动小部件的数量作为其权重,并且连接节点的网络描述了由它们之间的关系。根据其类型的事件,边缘可以彼此区分,这样的视图可以有效的描述具有相当复杂的UI结构的APP。
DiffCom分析
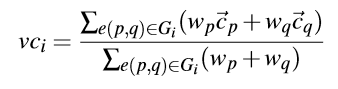
对于通过批量审查流程的应用程序,视图分析首先确定它是否与市场上已有的应用程序相关。 如果是这样,将进一步比较这两个应用程序,以确定其恶意软件分析的差异。 否则,将在方法级别针对整个市场检查应用程序,以尝试找到与其他应用程序共享的程序组件。 进一步检查差异和公共组件以删除公共代码重用(库,示例代码等)并收集其安全风险的证据。 这种“差异 - 共性”分析由DiffCom模块执行。 我们还提供了有效的代码相似性分析器的实体,并讨论了DiffCom的规避。
m-core的构建
为了准备审查,首先通过市场上的所有应用程序,并将其分解为方法。 删除公共库后,预处理模块分析其代码,计算各个方法(即mcores)的几何中心,然后在将结果存储到数据库之前对它们进行排序。 在审核过程中,如果发现提交的应用程序与另一个应用程序共享视图图形,则可以通过比较其个人方法的mcores来快速识别它们的差异。 在适用于执行步骤的过程中,它的方法用于在m-core数据库上进行二进制搜索,该数据库可以快速发现现有应用程序中包含的那些数据库。
系统建设
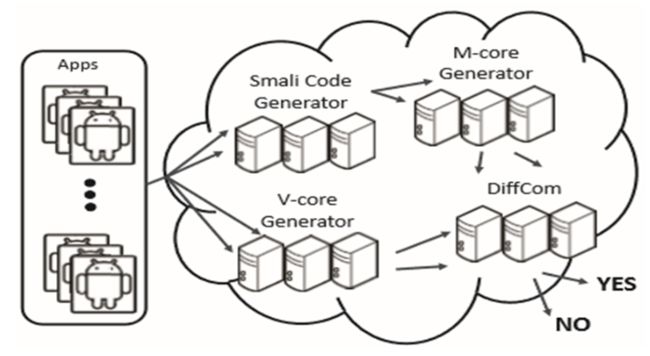
- 系统引导和恶意软件检测
为了引导我们的系统,市场首先需要使用我们的技术以高效的方式完成所有现有的应用程序。 这些应用程序的APK被反编译成smali(使用工具baksmali)来提取他们的视图和单个方法,它们分别进一步转换为v-cores和m-cores。 我们使用NetworkX来处理图形和找到循环。 然后在存储到它们各自的数据库之前对这些特征(即核心)进行分类和索引。
- 扫描恶意内容
一种简单的方法是通过二分查找逐个检查它们。 这将需要数千万步骤进行比较和分析。论文使用了一种有效的替代方案:一种简单的方法是通过二分查找逐个检查它们。 这将需要数千万步骤进行比较和分析。对m内核的检查要简单得多,不需要将一个应用程序与其他应用程序进行比较。 这是因为我们所关心的只是已经出现在个别等效组中的常用方法。 然后进一步分析这些方法以检测可疑方法。
- 云支持
为了支持对应用程序进行高性能审查,MassVet旨在在云上运行。整个审查过程的工作流程被转换为这样的拓扑:首先将提交的应用程序反汇编以提取视图和方法,然后根据白名单检查以删除合法的库和模板;然后,应用程序的v - 计算核心和m核心,并对v核心数据库进行二元搜索;根据研究结果,首先运行差异分析,然后进行交叉分析。每个操作都被分配到拓扑上的工作单元,并且与应用程序关联的所有数据都在单个流中。 Storm引擎旨在支持同时处理多个流,这使市场能够有效地审查大量提交。
第二组论文:幽灵攻击:利用预测执行
预测执行
预测执行就是一些具有预测执行能力的新型处理器,可以预测即将执行的指令,采用预先计算的方法来加快整个处理流程,其设计理念就是加速大概率事件。(ps:在看深入理解计算机系统的时候,书上就有讲过,处理器会对判断语句提前进行预测以提高运行速度,如果预测与实际结果不同,就抛弃前面预测执行的结果)
预测执行是高速处理器使用的一种技术,通过考虑可能的未来执行路径并提前地执行其中的指令来提高性能。例如,当程序的控制流程取决于物理内存中未缓存的值时,可能需要几百个时钟周期才能知道该值。除了通过空闲浪费这些周期之外,过程还会控制控制流的方向,保存其寄存器状态的检查点并且继续在推测的路径上推测性地执行该程序。当值从存储器中偶然到达时,处理器检查最初猜测的正确性。如果猜测错误,则处理器将寄存器状态恢复为存储的检查点并丢弃(不正确的)预测执行,如果猜测是正确的,则该部分代码已被执行过,不需要再次执行,因此带来了显著的性能增益。
幽灵攻击
熔断(Meltdown)和幽灵(Spectre)是CPU的两组严重漏洞,Meltdown漏洞影响几乎所有的Intel CPU和部分ARM CPU,而Spectre则影响所有的Intel CPU和AMD CPU。
条件分支错误预测
看如下一段代码:
if (x < array1_size)
y = array2[array1[x] * 256]攻击者首先选择使条件成立的x调用相关代码,训练分支预测期判断该判断语句为真,然后攻击者设置x值在array1_size之外。
CPU在执行时,会猜测边界检查将为真,推测性地使用这个恶意的x读取array2的内容。读取array2使用恶意x将数据加载到依赖于array1 [x]的地址的高速缓存中。当处理器意识到这个if为假时,重现选择执行路径,但缓存状态的变化不会被恢复,并且可以被攻击者检测到以找到受害者的存储器的一个字节。 通过使用不同的x值重复,可以利用该构造来读取受害者的存储器。
- 代码执行过程
进入if判断语句后,首先从高速缓存查询有无array1_size的值,如果没有则从低速存储器查询。按照我们的设计,高速缓存一直被擦除所以没有array1_size的值,总要去低速缓存查询。查询到后,该判断为真,于是先后从高速缓存查询array1[x]和array2[array1[x]*256]的值,一般情况下是不会有的,于是从低速缓存加载到高速缓存。
执行过几次之后,if判断连续为真,在下一次需要从低速缓存加载array1_size时,为了不造成时钟周期的浪费,CPU的预测执行开始工作,此时它有理由判断if条件为真,因为之前均为真(根据之前的结果进行推测),于是直接执行if为真的代码,也就是说此时即便x的值越界了,我们依然很有可能在高速缓存中查询到内存中array1[x]和array2[array1[x]*256]的值,当CPU发现预测错误时我们已经得到了需要的信息。
执行流程
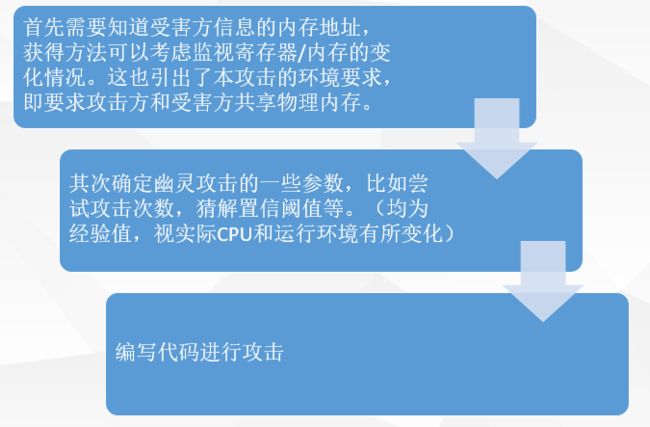
预测执行在提高CPU运行效率的同时也带来了安全隐患,它本身会导致CPU去执行程序本不该执行的代码,再加之操作系统和处理器没有对程序或者说低权限程序访问内存地址的范围作出很好的限制,高速缓存更是只能共用,这就导致本不该执行的代码执行后,还会把信息泄露给攻击者。
第三组论文:你所有的GPS都属于我们:道路导航系统的隐形操控
论文探讨了对道路导航系统隐身操纵攻击的可行性,目标是触发假转向导航,引导受害者达到错误的目的地而不被察觉。其主要想法是略微改变GPS的位置,以便假冒的导航路线与实际道路的形状相匹配并触发实际可能的指示。论文首先通过实施便携式GPS欺骗器并在真实汽车上进行测试来执行受控测量。然后论文设计一个搜索算法来实时计算GPS移位和受害者路线。
GPS攻击步骤
- GPS欺骗的两个关键步骤
- 接管步骤:攻击者诱使受害者GPS接收器从合法信号迁移到欺骗信号(接管方式可以强制或者平滑)
- 强制接管,欺骗着只是以高功率发送错误信号,导致受害者失去对卫星的跟踪并锁定更强的欺骗信号
- 平滑接管,接管开始于与原始信号同步的信号,然后逐渐超过原始信号以引起迁移
- 攻击者通过移动信号的到达时间或修改导航消息来操纵GPS接收器
- 接管步骤:攻击者诱使受害者GPS接收器从合法信号迁移到欺骗信号(接管方式可以强制或者平滑)
GPS欺骗器

便携式GPS欺骗器来执行受控实验
四个组件:HackRF One-based前端,Raspberry Pi,便携式电源和天线。整体机可以放在一个小盒子里如上图所示。
GPS欺骗的可行性
为了使攻击更加隐蔽,关键是要找到一条模仿真实道路形状的虚拟路线。这样,导航指令可以与物理世界保持一致。另一个因素是导航系统通常会显示第一人称视角,司机没有看到整个路线,而是关注当前路线和下一个转弯,这样会增加攻击者成功的机会。
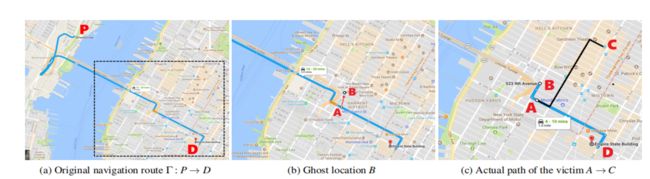
如上图所示,在依靠GPS导航时,受害者正在从P到D,假设攻击者接管受害者在A处的GPS接收器,攻击者创建错误的GPS信号以将GPS位置设置为附近的主机位置B,为了对应错误的位置漂移,导航系统将重新计算B和D之间的新路线。在物理道路上,受害者在A开始按照错误导航,最终达到不同的地方C。根据攻击目的,攻击者可以预先定义目标目的地C或者仅仅旨在转移受害者来自原始目的地D。
遍历并生成欺骗路线的伪代码

真实驾驶测试
论文在两种不同的路由上进行了测试:
A行→D表示原始路径
蓝线代表幽灵路线
黑线代表受害者
A是用户的实际位置
B是对应的鬼位置
C是用户的改道目的地
D是原来的目的地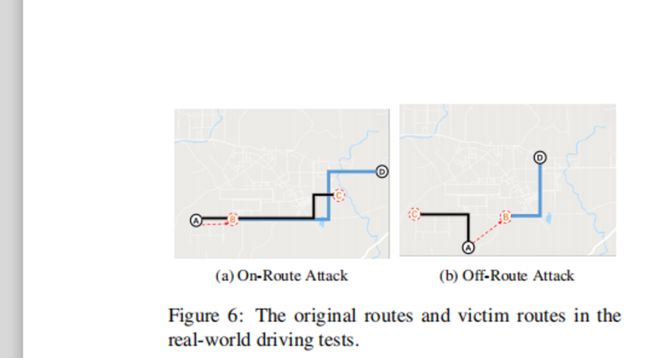
在第一种情况(图6a),攻击者设置鬼的位置到原来路线上的另一个地点。测试表明,这确实可以避免触发“重新计算”语音提示。这条路线花了九分钟,司机很成功。 完全改道到预定地点,距原目的地2.1公里。
在第二种情况下(图6b),攻击者将鬼位置设置在原始路由之外,这将触发 一个“重新计算”语音提示。这一次,司机驾驶了五分钟,并被转向2.5公里以外。在这两种情况下,智能手机都被锁定在欺骗信号上,而没有掉一次。 假位置序列以10赫兹的更新频率平稳地输入手机。尽管在GoogleMaps中嵌入了标题和过滤器的潜在交叉,导航指示国家统计局被及时触发。
第四组论文:With Great Training Comes Great Vulnerability: Practical Attacks against Transfer Learning
迁移学习
现在很多企业都在做深度学习,但是高质量模型的训练需要非常大的标记数据集,比如在视觉领域ImageNet模型的训练集包含了1400万个标记图像,但是小型公司没有条件训练这么大的数据集或者无法得到这么大的数据集。为了解决上述问题,普遍的解决方案就是迁移学习:一个小型公司借用大公司预训练好的模型来完成自己的任务。我们称大公司的模型为“教师模型“,小公司迁移教师模型并加入自己的小数据集进行训练,得到属于自己的高质量模型”学生模型”。
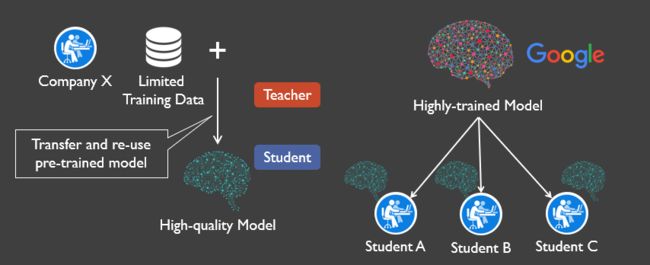
迁移学习过程
学生模型通过复制教师模型的前N-1层来初始化,并增加了一层全连接用于分类,之后使用自己的数据集对学生模型进行训练,训练过程中,前K层是被冻结的,即它们的权重是固定的,只有最后N-K层的权重才会被更新。前K层之所以在训练期间要被冻结,是因为这些层的输出已经代表了学生任务中的有意义的特征,学生模型可以直接使用这些特征,冻结它们可以降低训练成本和减少所需的训练数据集。
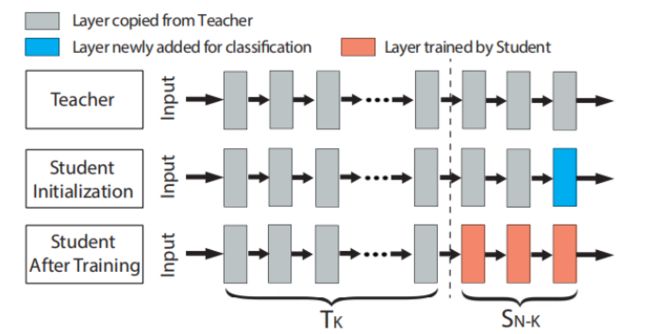
迁移学习方法分类
根据训练过程中被冻结的层数k,可以把迁移学习分为以下3中方法:
- 深层特征提取器 学生任务与教师任务非常相似,需要训练成本最小
- 中层特征提取器 允许更新更多层,有助于学生为自己的任务进行更多的优化
- 全模型微调 学生任务和教师任务存在显著差异,所有层都需要微调
迁移学习方法安全性问题
但迁移学习并不十分安全,因为迁移学习缺乏多样性,用户只能从很少的教师模型中进行选择,同一个教师模型可能被很多个公司迁移,攻击者如果知道了教师模型就可以攻击它的所有学生模型。
迁移学习的攻击方法
现有的针对机器学习算法的对抗性攻击主要有:白盒攻击和黑盒攻击
由于当前模型的默认访问方式是:教师模型被深度学习服务平台公开;学生模型离线训练且不公开。因为论文提出的攻击方式是对教师模型白盒攻击,对学生模型黑盒攻击。攻击者知道教师模型的内部结构以及所有权重,但不知道学生模型的所有权值和训练数据集
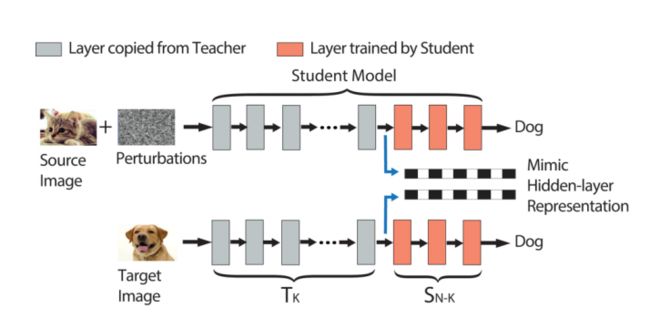
本文中的攻击方法:模拟神经元输出
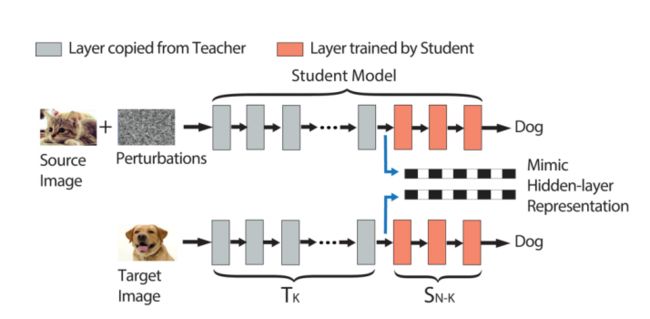
攻击目标:把source图猫误识别为target图狗
攻击思路:首先将target图狗输入到教师模型中,捕获target图在教师模型第K层的输出向量。之后对source图加入扰动,使得加过扰动的source图(即对抗样本)在输入教师模型后,在第K层产生非常相似的输出向量。由于前馈网络每一层只观察它的前一层,所以如果我们的对抗样本在第K层的输出向量可以完美匹配到target图的相应的输出向量,那么无论第K层之后的层的权值如何变化,它都会被误分类到和target图相同的标签。
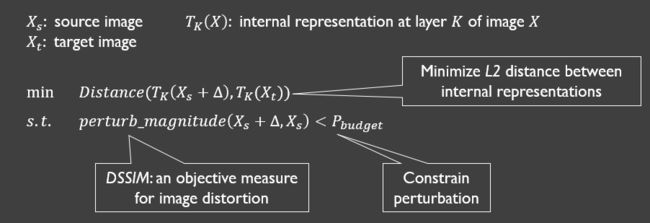
计算扰动
论文中求解一个有约束的最优化问题来计算扰动。
- 目标:模拟隐藏层第K层的输出向量。
- 约束:扰动不易被人眼察觉。
DSSIM

攻击方式:目标攻击/非目标攻击
目标攻击:将source image x_s 误分类成target s_t所属标签
非目标攻击:将source image x_s误分类成任意其他的source image所属标签
影响攻击效果的因素
- 扰动预算P
- P的选择将会直接关系到攻击的隐蔽性。P越小攻击成功率越低
- 距离度量方法
- 迁移学习方法
防御方法
论文还提出了3种针对本文攻击的防御方法,其中最可行的是修改学生模型,更新层权值,确定一个新的局部最优值,在提供相当的或者更好的分类效果的前提下扩大它和教师模型之间的差异。这又是一个求解有约束的最优化问题,约束是对于每个训练集中的x,让教师模型第K层的输出向量和学生模型第K层的输出向量之间的欧氏距离大于一个阈值,在这个前提下,让预测结果和真实结果的交叉熵损失最小。

第五组论文:SafeInit: Comprehensive and Practical Mitigation of Uninitialized Read Vulnerabilities
背景知识
未初始化值的使用仍然是C / C ++代码中的常见错误。这不仅导致未定义的和通常不期望的行为,而且还导致信息泄露和其他安全漏洞。我们都知道C/C++中的局部变量,在未初始化的情况下,初值为随机值。
以C++中局部变量的初始化和未初始化为例:
编译器在编译的时候针对这两种情况会产生两种符号放在目标文件的符号表中,对于初始化的,叫强符号,未初始化的,叫弱符号。连接器在连接目标文件的时候,如果遇到两个重名符号,会有以下处理规则:
- 如果有多个重名的强符号,则报错。
- 如果有一个强符号,多个弱符号,则以强符号为准。
- 如果没有强符号,但有多个重名的弱符号,则任选一个弱符号。
LLVM框架
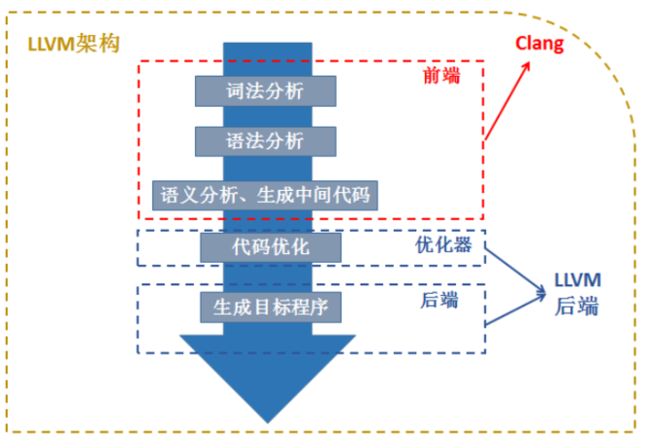
在理解LLVM时,我们可以认为它包括了一个狭义的LLVM和一个广义的LLVM。广义的LLVM其实就是指整个LLVM编译器架构,包括了前端、后端、优化器、众多的库函数以及很多的模块;而狭义的LLVM其实就是聚焦于编译器后端功能(代码生成、代码优化等)的一系列模块和库。
Clang是一个C++编写、基于LLVM的C/C++/Objective-C/Objective-C++编译器。Clang是一个高度模块化开发的轻量级编译器,它的编译速度快、占用内存小、非常方便进行二次开发。
上图是LLVM和Clang的关系:Clang其实大致上可以对应到编译器的前端,主要处理一些和具体机器无关的针对语言的分析操作;编译器的优化器部分和后端部分其实就是我们之前谈到的LLVM后端(狭义的LLVM);而整体的Compiler架构就是LLVM架构。
论文实现成果
由于C/C++不会像C#或JAVA语言,确保变量的有限分配,要求在所有可能执行的路径上对它们进行初始化。所以,C/C++代码可能容易受到未初始化的攻击读取。同时C/C++编译器可以在利用读取未初始化的内存是“未定义行为”时引入新的漏洞。
在本文中,提出了一种全面而实用的解决方案,通过调整工具链(什么是工具链)来确保所有栈和堆分配始终初始化,从而减轻通用程序中的这些错误。 SafeInit在编译器级别实现。
本文实现了:
- 提出了safeinit,一种基于编译器的解决方案,结合强化分配器,确保堆和栈上的初始化来自动减轻未初始化值读取。
- 提出的优化可以将解决方案的开销降到最低水平(< 5%)并可以在现代编译器中实现
- 基于clang和LLVM的SafeInit原型实现,并表明它可以应用于大多数真实的C / C ++应用程序而无需任何额外的手动工作。
- CPU-intensive 、 I/O intensive (server) applications 和 Linux kernel测试验证了现实世界的漏洞确实被缓解
现存威胁
敏感数据泄露
由于未初始化数据而导致信息泄露的最明显危险是直接敏感数据的泄露。
- 数据生命周期持续时间长于预期,可能会产生许多无意的数据副本。
- 不是所有情况下编译器可以提供memset优化调用,如果数据不再有效并且因此在该点之后不再使用,编译器可以通过调用memset来优化这些调用。但是如果之后的数据还有效,禁止编译器优化的替代函数(例如memset_s和explicit_bzero)并不是普遍可用的。
- 未初始化数据的使用受到不可信输入的影响,必须考虑各种潜在的攻击媒介,这种不同的攻击面意味着应该认真对待所有未初始化的数据漏洞。
绕过安全防御
现代软件防御依赖于敏感元数据的保密性,同时,未初始化的值提供了指针公开的丰富资源。
例如地址空间布局随机化之类的防御一般取决于指针的保密性,并且由于通常仅仅随机化一个及基地址来完成,因此攻击者仅需要获取单个指针以完全抵消保护。这样的指针可以是代码,堆栈或堆指针,并且这些指针通常存储在栈和堆上,因此未初始化的值错误提供了阻止这种信息隐藏所需的指针公开的丰富源。
软件开发
未初始化数据导致的其他漏洞允许攻击者直接劫持控制流。常见的软件开发的错误是:无法在遇到错误时在执行路径上初始化变量或缓冲区。
检测工具
有些工具试图在开发过程中检测未初始化变量,而不是试图减轻未初始化的值错误,允许它们由程序员手动校正。有些工具试图在开发过程中检测它们,而不是试图减轻未初始化的值错误,允许它们由程序员手动校正。更重要的是,编译器警告和检测工具只报告问题,而不是解决问题。 这可能会导致错误和危险的错误。
堆栈变量
函数堆栈帧:在堆栈中为当前正在运行的函数分配的区域、传入的参数。返回地址以及函数所用的内部存储单元都存储在堆栈帧中。
函数堆栈帧包含局部变量的副本,或具有被忽略的局部变量,同时还包含其他局部变量和编译器生成的临时变量的溢出副本,以及函数参数,帧指针和返回地址。 鉴于堆栈内存的不断重用,这些帧提供了丰富的敏感数据源。
现代编译器使用复杂的算法进行寄存器和堆栈帧分配,这种方式减少了内存使用并改善了缓存局部性,但意味着即使在函数调用之前/之后清除寄存器和堆栈帧也不足以避免所有潜在的未初始化变量。
未定义行为
当C / C ++程序无法遵循该语言强加的规则时,会发生未定义的行为。在我们讨论的环境中,未定义行为是指在代码读取未初始化的堆栈变量或者是未初始化的堆分配。
为了实现最大数量的优化,特别是在可能从模板和宏扩展的代码中,并最终被大部分丢弃为无法访问,现代编译器转换利用了大规模的未定义的行为。这样的转换可以将未定义的值(以及因此也未初始化的值)解释为使得优化更方便的任何值,即使这使得程序逻辑不一致。
safeinit的工作方式
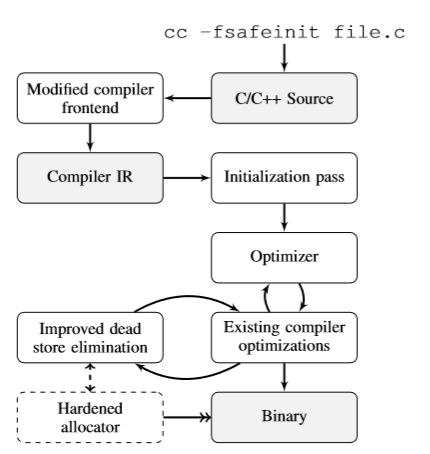
上图是利用额外的编译器传递,从而增加了必要的初始化
种简单的初始化方法会导致过多的运行开销,而我们系统的一个重要元素是专门的强化分配器。 在许多情况下,通过利用额外的信息并结合我们的编译器工具,可以避免初始化问题。
可以看到编译器在获得C/C++文件后,编译器前端将源文件转换为中间语言(IR),通过初始化、代码优化结合现存编译器的优化器,之后通过无效数据消除、强化分配器最后获得二进制文件。Safeinit在整个过程中所添加的就是 初始化全部变量、优化以及强化分配器,来避免或缓解未初始化值。
环境未定义变量的几种方式
- 初始化
- SafeInit在首次使用之前初始化所有局部变量,作为新分配变量的作用域处理。SafeInit通过修改编译器编译代码的中间表示(IR),在每个变量进入作用域后进行初始化(例如内置memset)。
- 强化分配器
- SafeInit的强化分配器可确保在返回应用程序之前将所有新分配的内存清零。我们通过修改现代高性能堆分配器tcmalloc来实现我们的强化分配器。同时还修改了LLVM,以便在启用SafeInit时将来自新分配的内存的读取视为返回零而不是undef。
- 优化器
- 目的:可在提高效率和非侵入性的同时提高SafeInit的性能。优化器的主要目标是更改现有编译器中可用的其他标准优化,以消除任何不必要的初始化。
- 存储下沉:存储到本地的变量应尽可能接近它的用途。

- 无效存储消除
- “无效存储消除”(DSE)优化,它可以删除总是被另一个存储覆盖而不被读取的存储。
- 堆清除:所有堆分配都保证初始化为零,如果有存储到新分配堆内存中的零值都会被删除
- 非恒定长度存储清除:为了删除动态堆栈分配和堆分配的不必要初始化
- 交叉块DSE:可以跨多个基本块执行无效存储消除
- 只写缓冲区:通过指定该缓冲区只用来存储而不是删除,就可以将该缓冲区删除。
- “无效存储消除”(DSE)优化,它可以删除总是被另一个存储覆盖而不被读取的存储。
实施方法
- 初始化
- LLVM中的局部变量是使用alloca指令定义的; 我们的pass通过在每条指令之后添加对LLVM memset内部的调用来执行初始化。可以保证清除整个分配,并在适当的时候转换为存储指令。
- 强化分配器
- 通过修改现代高性能堆分配器tcmalloc来实现我们的强化分配器。 只需清除在分配器返回指针之前,所有其他堆分配为零。还修改了LLVM,以便在启用SafeInit时将来自新分配的内存的读取视为返回零而不是undef。 如上所述,这对于避免未定义值的不可预测后果至关重要。
- 优化
- 通过添加一个新的内部函数“initialized”来实现初始化检测优化,该函数具有与memset相同的存储杀死副作用,但是被代码生成忽略。 通过扩展诸如LLVM的循环习语检测之类的组件来生成这种新的内在函数,其中无法用memset替换代码,我们允许其他现有的优化传递利用这些信息而无需单独修改它们。
- 无效存储消除
- 我们通过扩展现有的LLVM代码实现了上述其他优化,尽可能减少我们的更改。 我们对只写缓冲区的实现使用了D18714中的补丁(自合并以来),它为writeonly属性添加了基本框架。
评估
- SPEC CPU2006
使用LTO和-O3在SPEC CPU2006中构建了所有C / C ++基准测试。 我们使用参考数据集提供3次运行中值的开销图。
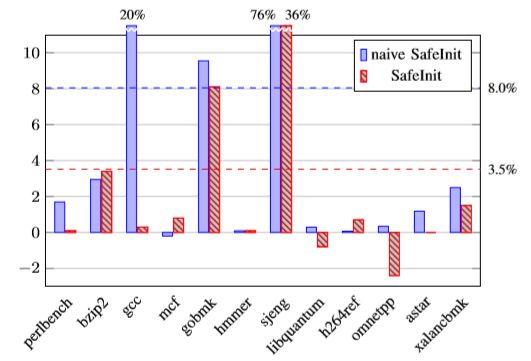
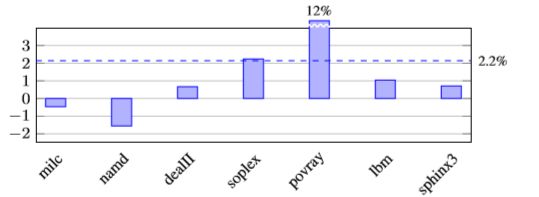
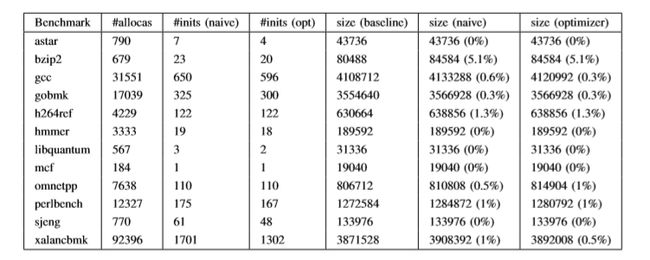
表I提供了每个基准测试的allocas数量(表示局部变量的数量,偶尔的参数副本或动态分配)的详细信息。 该表还提供了(剥离的)二进制大小; 在许多情况下,初始化的影响对最终的二进制大小没有任何影响,并且在最坏的情况下它是最小的。#INITS是现有编译器优化之后剩余的大量初始化数量,并且我们的优化器已经分别运行。
- linux
使用我们的工具链构建了最新的LLVM Linux内核树。 我们定制了构建系统,以允许使用LTO,重新启用内置clang函数,并修改gold链接器以解决我们在符号排序时遇到的一些LTO代码生成问题。
由于Linux内核执行自己的内存管理,因此它不会与用户空间强化分配器链接; 我们的自动加固仅保护局部变量。
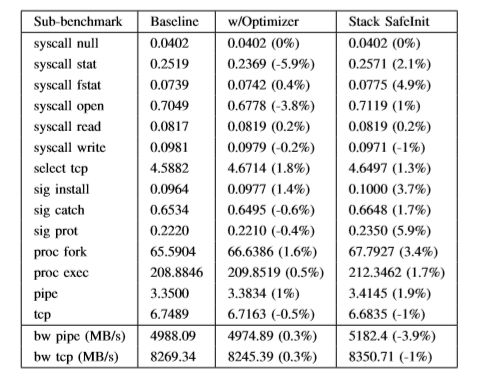
下表提供了使用内核微基准测试工具LMbench的典型系统调用的延迟和带宽选择。 我们运行了每个基准测试10次,每次运行的预热时间很短,迭代次数很多(100次),并提供中位数结果。 TCP连接是localhost,其他参数是默认LMbench脚本使用的参数。
- 安全
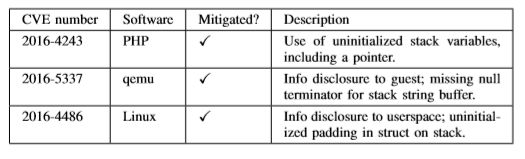
为了验证SafeInit是否按预期工作,不仅考虑了各种现实漏洞,例如下表中的漏洞,还创建了一套单独的测试用例。 我们手动检查了为相关代码生成的bitcode和机器代码,并使用我们上面描述的检测系统运行我们的测试套件。 我们还用valgrind来验证我们的硬化; 例如,我们确认当使用SafeInit强化OpenSSL 0.8.9a时,来自valgrind的所有未初始化的值警告都会消失。
结论
本文通过在clang/LLVM编译器架构上,通过修改代码,实现了safeinit原型,在编译C/C++源代码时,传递一个标记即可使用safeinit实现优化编译,缓解未定义变量。使用了强化分配器的safeinit可以进一步优化代码的同时,保证所有需要初始化的变量进行初始化,删除多余初始化代码进行优化,这样既保证缓解了未定义变量漏洞的威胁,同时与其他现有方法相比,提升了性能。
第六组论文:操纵机器学习:回归学习的中毒攻击与对策
背景
在本文中,作者对线性回归模型进行了第一次中毒攻击的系统研究及其对策。在中毒攻击中,攻击者故意影响训练数据以操纵预测模型的结果。作者提出了一个专门为线性回归设计的理论基础优化框架,并展示了它在一系列数据集和模型上的有效性。随着越来越多具有巨大社会影响的应用程序依赖于机器学习来实现自动化决策,已经出现了一些关于机器学习算法引入的潜在漏洞的担忧。复杂的攻击者有强烈的动机来操纵机器学习算法生成的结果和模型来实现他们的目标。
在此考虑设置中毒攻击,其中攻击者在训练过程中注入少量损坏的点。此类中毒攻击已经在蠕虫签名生成被实际证明,垃圾邮件过滤器,DoS攻击检测,PDF恶意软件分类 ,手写体数字识别 ,和情绪分析。
系统架构
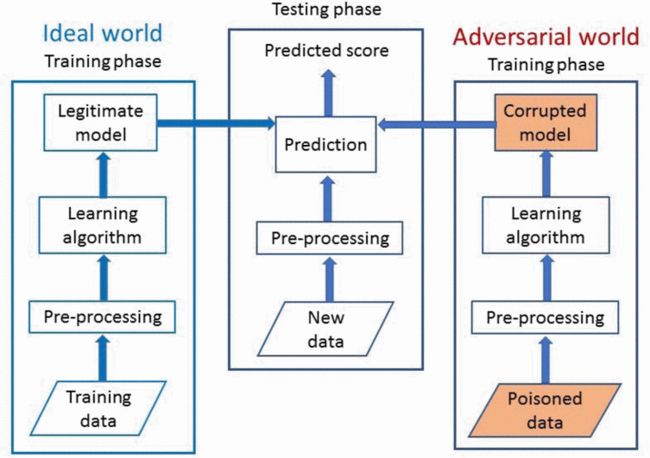
上图中,分为三个阶段
- 理想世界
- 学习过程包括执行数据清理和标准化的数据预处理阶段,之后可以表示训练数据。
- 测试阶段
- 模型在预处理后应用于新数据,并使用在训练中学习的回归模型生成数值预测值。
- 对抗性世界
- 在中毒攻击中,攻击者在训练回归模型之前将中毒点注入训练集。
攻击方法
由于这些攻击最初是在分类问题的背景下提出的,因此攻击样本的类标签被任意初始化,然后在优化过程中保持固定(回想一下ÿ是分类中的分类变量)。正如作者将在本工作的其余部分中展示的那样,作者在此提出的对当前攻击推导的重大改进是同时优化每个中毒点的响应变量及其特征值。作者随后重点介绍了在基于梯度的优化过程中如何更新每个中毒样本的一些理论见解。这将导致作者在Sect中提出更快的攻击。它只利用数据的某些统计特性,并且只需要对目标模型进行最小的黑盒访问。
基于优化的中毒攻击

- 梯度计算 具有线搜索的标准梯度算法
- 目标函数 总是使用MSE作为损失函数
- 初始化策略 选择初始集Dp中毒点作为输入
- 基线攻击 定义基线攻击为来自xiao等人的攻击
- 响应变量优化 响应变量采用连续值而不是分类值
- 理论见解 关于Eqs的双层优化的一些理论见解
防御方法
描述了针对中毒攻击的现有防御建议,并解释了为什么它们在训练数据中的对抗性腐败中可能无效。提出了一种名为TRIM的新方法,专门用于增强针对一系列中毒攻击的鲁棒性。
- 现有防御算法
- 噪音回归
- 这些方法背后的主要思想是识别和删除数据集中的异常值
- 对抗性攻击
- 对抗弹性回归算法通常在强有力的数据和噪声分布假设下提供保证
- 噪音回归
所有这些方法都具有可证明的鲁棒性保证,但它们所依赖的假设在实践中通常并不令人满意。
TRIM算法
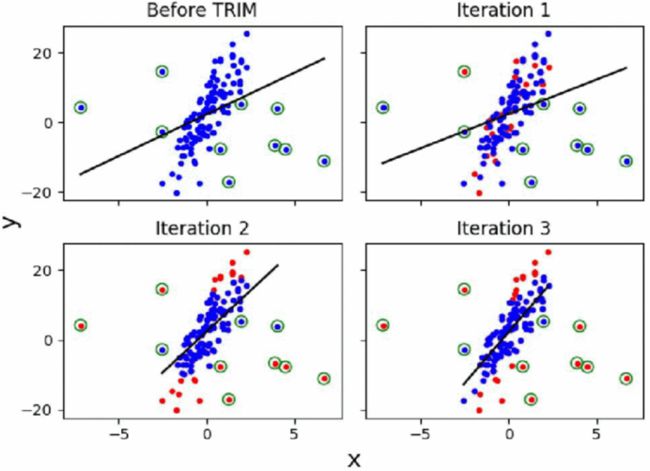
- 修建损失函数 针对不同残差子集计算的修建损失函数
- 迭代估计回归参数 同时训练每个迭代中具有最低残差的点的子集
- 正则化线性回归 证明它们与一系列模型和真实世界数据集上的其他防御相比的有效性
实验评估
作者在四台32核Intel(R)Xeon(R)CPU E5-2440 v2 @ 1.90GHz机器上进行了实验。作者将基于优化的攻击实现并行化,以利用多核功能。作者使用标准的交叉验证方法将数据集分成1/3用于训练,1/3用于测试,1/3用于验证,并将结果报告为5次运行的平均值。作者使用两个主要指标来评估作者的算法:MSE用于攻击和防御的有效性,以及运行时间的成本。
哪种优化策略对于中毒回归最有效?
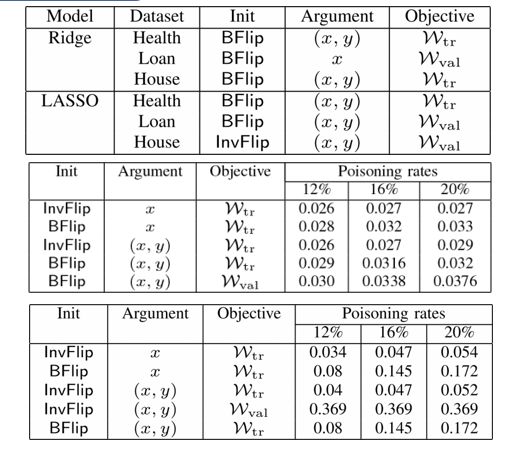
优化和统计攻击如何在有效性和性能方面进行比较?
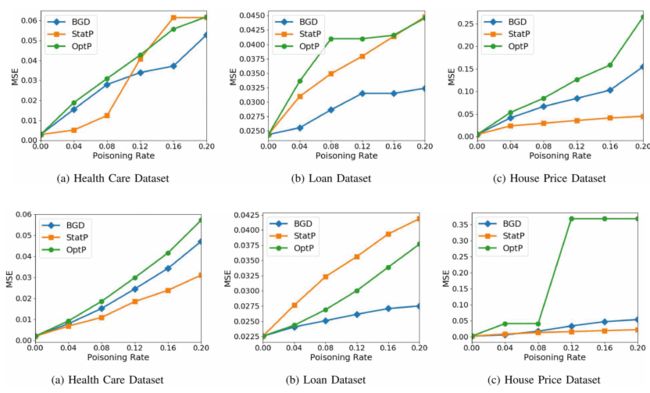
在实际应用中中毒的潜在危害是什么?
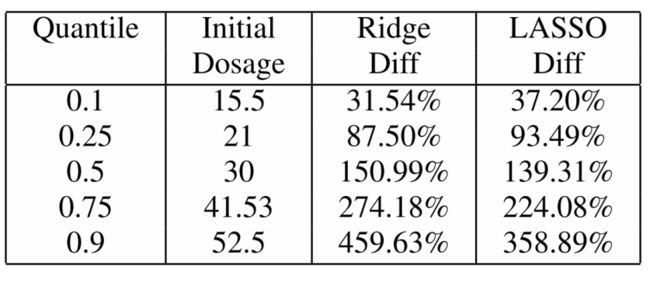
作者的攻击的可转移性属性是什么?
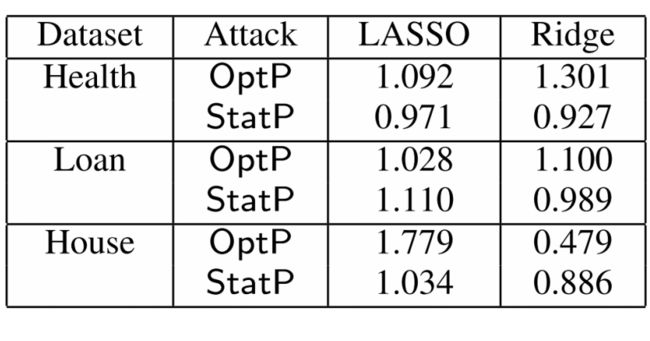
防御算法评估
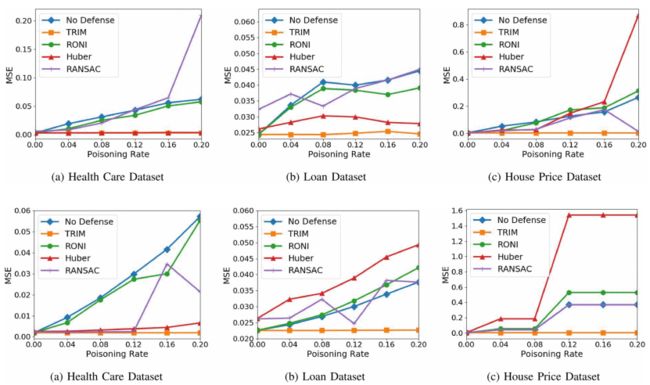
- 防御结果
- 作者发现以前的防御(RANSAC,Huber,Chen和RONI)对作者的中毒攻击不起作用。
- 作者提出的防御措施TRIM与现有的防御措施相比,效果非常好并且显着改善了MSE。对于所有攻击,模型和数据集,TRIM 的MSE在未中毒的模型MSE的1%以内。在某些情况下,TRIM实现的MSE低于未中毒的模型(6.42%)
- 作者测试的所有防御都运行得相当快。TRIM是最快的,在房价数据集上平均运行0.02秒。
第六组论文:Convolutional Neural Networks for Sentence Classification(卷积神经网络用于句子分类)
背景
使用卷积神经网络对句子进行分类的原因:
- 特征提取的高效性
- 神经网络的出现不需要做大量的特征工作,可以直接把数据灌进去,让神经网络自己训练,自我“修正”,可得到一个较好的效果。
- 数据格式的简易性
- 传统机器学习分类问题中,,我们“灌”进去的数据是不能直接灌进去的,需要对数据进行一些处理,譬如量纲的归一化,格式的转化等等,不过在神经网络里我们不需要额外的对数据做过多的处理。
- 参数数目的少量性
- 对于一个基本的三层神经网络来说(输入-隐含-输出),我们只需要初始化时给每一个神经元上随机的赋予一个权重w和偏置项b,在训练过程中,这两个参数会不断的修正,调整到最优质,使模型的误差最小。尤其是在图像领域,用传统的神经网络并不合适。
模型介绍
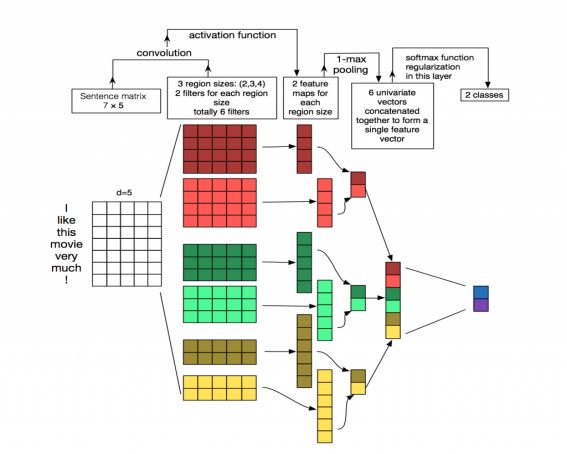
- 输入矩阵
- 句子长度
- 每个字符的长度
- 卷积过程
- 文中使用了2种过滤器(卷积核),每种过滤器有三种高度(区域大小),即有6种卷积结构。每个卷积核的大小为filter_sizeembedding_size。
- filter_size代表卷积核纵向上包含单词个数。
- embedding_size就是词向量的维数。

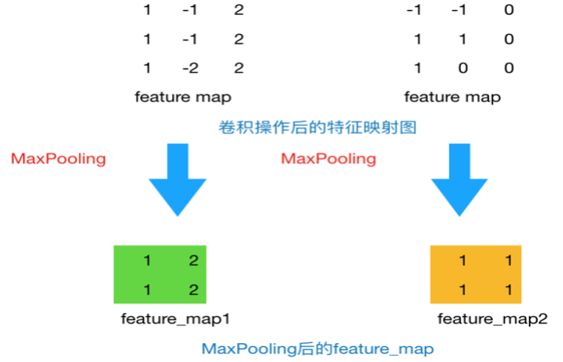
- 池化过程
- 这篇文章使用MaxPooling的方法对Filter提取的特征进行降维操作,形成最终的特征。每个卷积的结果将变为一个特征值,最终生成一个特征向量。
- 全连接层
- 要处理的问题:正面评价和负面评价
- 全连接层
- 把权重矩阵与输入向量相乘再加上偏置,实际上就是三层神经网络的隐层到输出层的映射。 y = w*z + b
- 添加Dropout
- 由于实验中所用的数据集相对较小,很容易就会发生过拟合现象,所以要引入Dropout来减少过拟合现象。
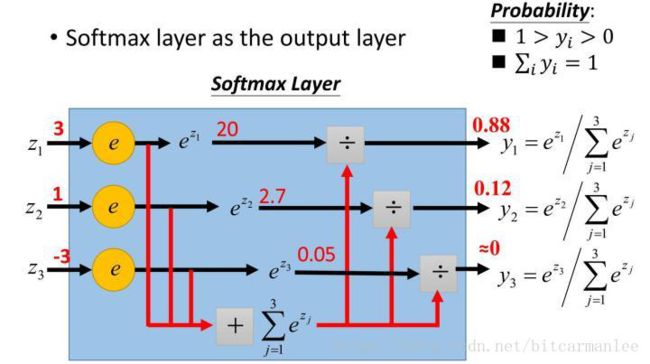
- Softmax分类层
- 可以应用Softmax函数来将原始分数转换为归一化概率,从而得到概率最大的输出,最终达到预测的目的。
数据集
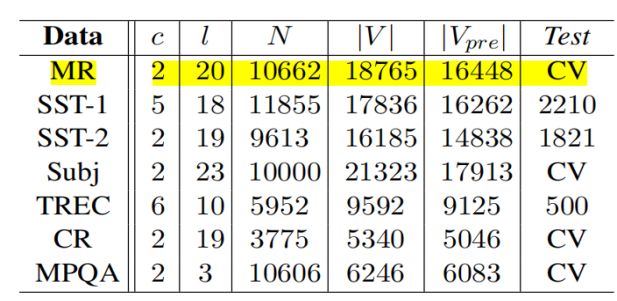
文章中使用的数据集包括
- MR:电影评论,每次评论一句话。分类包括检测积极/消极的评论。
- SST-1:Stanford Perfection Treebank是MR的扩展,但提供了train/dev/test分割和细粒度标签(非常积极、积极、中立、消极、非常消极)。
- SST-2:与SST-1相同,但删除中立评论。•Subj:主观性数据集,将句子分类为主观性或客观性两种。
- TREC:数据集将问题分为6种类型(是否涉及人员、位置、数字信息)。
- CR:客户对各种产品(相机、MP3等)的正面/负面评论。
- MPQA:用于意见极性检测。
实验结论
model Variations
本文实现的CNN模型及其变体在不同的数据集上和前人方法的比较:
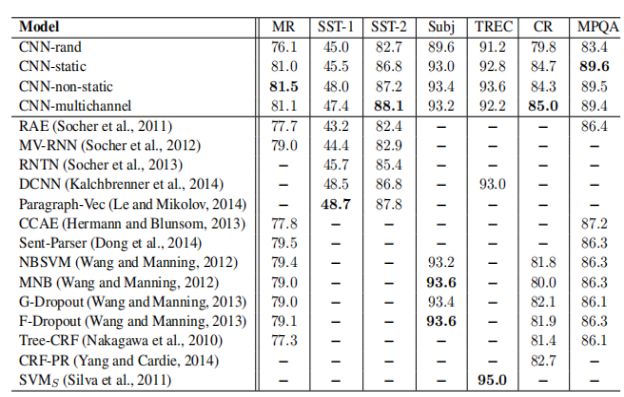
- CNN-rand:所有的word vector都是随机初始化的,同时当做训练过程中优化的参数;
- CNN-static:所有的word vector直接使用无监督学习即Google的word2vector工具得到的结果,并且是固定不变的;
- CNN-non-static:所有的word vector直接使用无监督学习即Google的word2vector工具得到的结果,但是会在训练过程中被微调;
- CNN-multichannel:CNN-static和CNN-non-static的混合版本,即两种类型的输入。
结论
- CNN-static优于CNN-rand,因为采用训练好的word2vector向量利用了更大规模的文本信息,提高acc;
- CNN-non-static优于CNN-static,因为BP算法微调参数使得word2vector更加贴近于某一个具体的任务,提高acc;
- CNN-multichannel在小规模数据集上的表现优于CNN-single。它体现的是一种折中思想,即既不希望微调参数后的word2vector距离原始值太远,但同时保留其一定的变化空间。
第一次课 —— web安全与信息安全
老师通过例子向我们介绍了web安全的重要性,同时介绍了常见的web漏洞以及隐私安全。
信息化发展凸显的信息安全问题
- 攻防技术非对称
- 信息技术属于高科技技术,但大量自动化攻击工具的出现,使得入侵网络与信息系统的门槛降到极低
- 国内外“肉鸡”的价格也不一样,发达国家相比发展中国家,价格更高
- 攻防成本非对称
- 攻防技术的非对称带来了攻防成本的非对称
- 风险成本低
- 网络攻击有很好的隐藏性,易于掩饰隐藏身份和位置
- 对国家安全而言,攻防成本的非对称性具有特殊意义
- 攻防主体非对称
- 弱小一方与超级大国之间的实力得到了大大的弥补,个人拥有了挑战弱势群体的机会
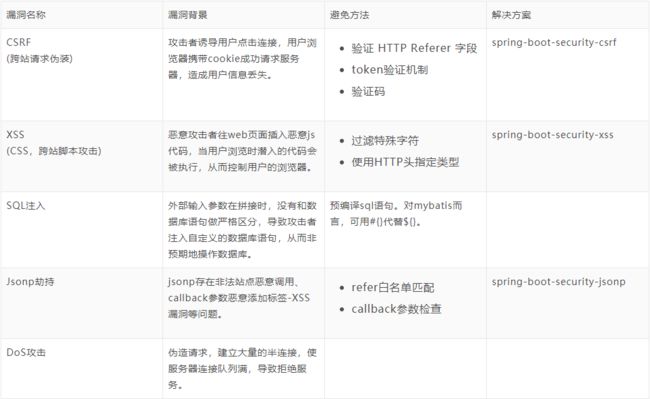
常见web漏洞
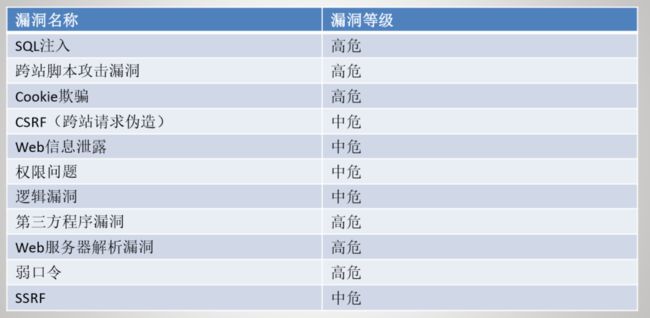
SQL注入
由于程序中对用户输入检查不严格,用户可以提交一段数 据库查询代码,根据程序返回的结果,获得某些他想得知 的数据,这就是所谓的SQL Injection,即SQL注入。
- 按提交字符类型可分为: 数字型 字符型 搜索型
- 按HTTP提交方式可分为: GET、POST、Cookie javascript:alert(document.cookie="id="+escape("x"))
- 按注入方式可分为: 盲注 、 union注入、 报错注入
- 编码问题:宽字节注入(构造[`])
XSS跨站脚本攻击
恶意攻击者往Web页面里插入恶意html代码,当用户浏览该页之时,嵌入其中Web里面的html代码会被执行,从而达到恶意攻击用户的特殊目的。
XSS, 即为(Cross Site Scripting), 中文名为跨站脚本, 是发生在目标用户的浏览器层面上的,当渲染DOM树的过程成发生了不在预期内执行的JS代码时,就发生了XSS攻击。
跨站脚本的重点不在‘跨站’上,而在于‘脚本’上。大多数XSS攻击的主要方式是嵌入一段远程或者第三方域上的JS代码。实际上是在目标网站的作用域下执行了这段js代码。
分类
- 反射型XSS
- 存储型XSS
CSRF跨站请求伪造
CSRF(Cross-site request forgery)跨站请求伪造 。
攻击者盗用了你的身份,以你的名义发送恶意请求。CSRF能够 做的事情包括:以你名义发送邮件,发消息,盗取你的账号, 甚至于购买商品,虚拟货币转账......造成的问题包括:个人隐私 泄露以及财产安全。
验证不充分之上传漏洞
- 客户端检测(javascript扩展名检测)
- 浏览器禁用JavaScript
- 浏览器禁用JavaScript
- 服务端检测(MIME类型检测)
- 伪造Content-type: image/gif
- 伪造Content-type: image/gif
- 服务端检测(文件头检测)
- 伪造文件头(GIF89a)
- 服务端检测(目录路径检测)
- %00截断
- 服务端检测(文件扩展名检测)
- ①白名单 ②黑名单
解析漏洞
解析漏洞就是web容器将其他格式的文件解析为可执行脚本语言,攻击者可以利用这个特征去执行一些攻击行为。
- IIS 6.0解析漏洞
- ①目录解析 /test.asp/test.jpg
- ②文件解析 /test.asp;1.jpg
- IIS6.0 默认的可执行文件除了asp还包含这三种
- ①/test.asa
- ②/test.cer
- ③/test.cdx
- Apache解析漏洞
Apache 是从右到左开始判断解析,如果为不可识别解析,就再往左判断。- /test.php.xxx
- /test.php.rar
- Nginx解析漏洞
- 影响版本:0.5.,0.6., 0.7 <= 0.7.65, 0.8 <= 0.8.37
- /test.jpg/1.php
- /test.jpg%00.php
第三方漏洞
Struts2远程命令执行
弱口令
弱口令(weak password) 没有严格和准确的定义,通常认为容易被别人(他们有可能对你很了解)猜测到或被破解工具破解的口令均为弱口令。
弱口令指的是仅包含简单数字和字母的口令,例如“123”、 “abc”等,因为这样的口令很容易被别人破解,从而使用户的计 算机面临风险,因此不推荐用户使用。
社会工程学
机器学习与web漏洞
- 鱼叉
- AI可以通过从电子邮件中捕获元数据来检测网络钓鱼这些威胁,并不影响用户隐私。
- 水坑式攻击
- 机器学习可以通过分析诸如路径/目录遍历统计等数据来帮助机构对网络应 用程序服务进行基准测试。随着时间推移不断学习的算法可以识别出攻击者或恶意网站和应用程序的常见互动。
- 内网漫游
- 机器学习了解数据的语境,可以动态地提供正常通信数据的视图。有了对典型通信流的更好理解,算法可以完成变化点检测,以此监测潜在的威胁。
- 隐蔽信道检测
- 机器学习技术可以摄取并分析有关稀有领域的统计数据。有了这些信息,安全操作团队可以更轻松地让云端攻击者现形。
- 注入攻击
- 机构可以使用机器学习算法来构建数据库用户组的统计概况。算法学习了解了这些组如何访问企业中的各个应用程序,并学习发现这些访问模式中出现的异常。
- 网页木马
- 攻击者通过这些平台来瞄准购物者的个人信息。机器学习算法可以聚焦正常购物车行为的统计,然后帮助识别出不应该以这种频率发生的异常值或行为。
- 凭证盗窃
- 网站和应用程序可以跟踪位置和登录时间。机器学习技术可以跟踪这些模式以及包含这些模式的数据,以了解什么样的用户行为是正常的,哪些行为则代表了可能有害的活动。
第二次课 —— 量子密码
量子密码简介
- 使用的密码体制:
- 用公钥密码体制分发会话秘钥
- 用对称密码体制加密数据
- 量子密码
- Shor算法:大数分解算法
- 多项式时间内解决大数分解难题
- 受影响密码体制:RSA等大多数公钥密码
- qGrover算法:快速搜索算法
- 可以加速搜索密钥
- 受影响密码体制:DES,AES等对称密码
- Shor算法:大数分解算法
- 计算能力对比:
- 经典方法:运算时间随输入长度指数增长
- 量子方法:运算时间按多项式增长
- 量子密码
结合 量子秘钥的不可窃听性和一次一密的不可破译性 实现 无条件安全的保密通信。
量子密码采用的典型协议和基本模型
BB84量子秘钥分配协议
- 量子通信:采用BB84协议,传送量子态光子(量子密钥),运用一次一密的加密手段。为了实现量子通信,采用经典信道和量子信道同时使用的模式。
- 经典信道:传送同步信号、对照数据等。
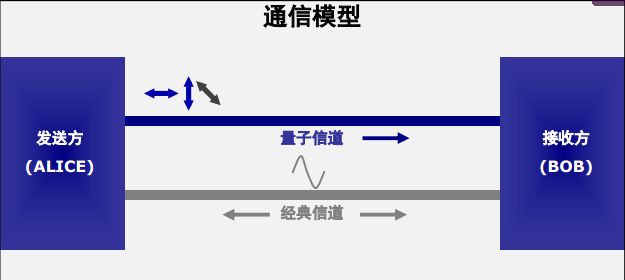
- 第一阶段:量子通信
Alice从四种偏振态中随机选择发送给Bob。
接收者Bob接受信息发送方Alice传输的信息,并从两组测量基中随机选择一个对接收到的光子的偏振态进行测量。
- 第二阶段:经典通信
接收者Bob发送信息给信息发送方Alice并告知他自己在哪些量子比特位上使用了哪一个测量基。信息发送方Alice 在接收到Bob发送的消息之后,与本人发送时采用的基逐一比对并通知接收者Bob在哪些位置上选择的基是正确的。
信息发送方Alice和接收者Bob丢掉测量基选择有分歧的部分并保存下来使用了同一测量基的粒子比特位,并从保存的信息中选取相同部分在经典信道中作对比。信道安全的情况下信息发送方Alice和接收者Bob的数据应当是没有分歧的。若存在窃听,则Alice和Bob的数据会出现不同的部分。
- 如果没有窃听,双方将保留下来的剩余的位作为最终密钥。
假如Eve进行窃听,根据物理学中的测不准原理等基本物理规律窃听者的窃听行为肯定会使Bob的QBER值发生变化,这时,通信双方通过误码率的分析就能发现窃听者是否存在。
第三次课 —— 基于深度学习的密码分析与设计
机器学习
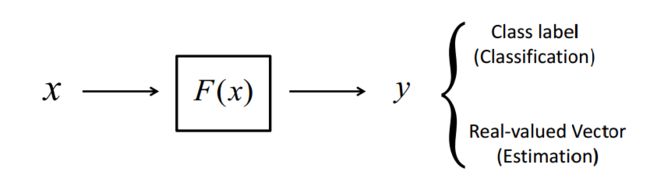
机器学习(Machine Learning, ML)是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。它是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域,它主要使用归纳、综合而不是演绎。机器学习的研究人员也是试图从多个样本与标签配对来进行机器学习模型的求解(训练)。
可以看到,机器学习是利用样本x,输入函数中,得到结果y,利用已有样本x y训练F(x) ,能够达到,输入一个不包含在样本集的x'可以得到正确的y',保证正确率能够保持在一个较高的水平,这就是我根据老师上的的理解,只是比较浅的理解,在以后的学习中继续加深我对机器学习的理解。
机器学习与密码分析
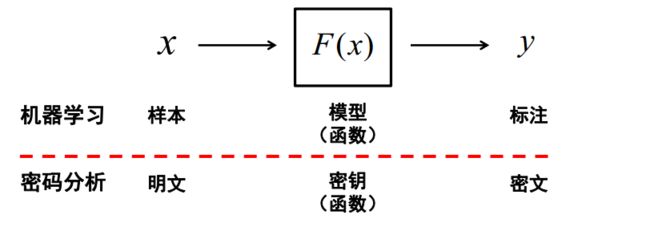
密码分析与机器学习之间有天然的相似性,在密码分析中,攻击者试图通过推算出密钥来破解密码系统。解密函数是从一个由密钥索引的已知函数空间(解空间)求解出。攻击者的目的是发现解密函数的精确解。如果攻击者能够获取多个获取密文与明文配对来进行密码分析,其与机器学习的概念相似:机器学习的研究人员也是试图从多个样本与标签配对来进行机器学习模型的求解(训练)。所以可以将二者进行结合,研究利用机器学习如何进行密码分析。
深度学习
深度学习是机器学习中一种基于对数据进行表征学习的方法。观测值(例如一幅图像)可以使用多种方式来表示,如每个像素强度值的向量,或者更抽象地表示成一系列边、特定形状的区域等。而使用某些特定的表示方法更容易从实例中学习任务(例如,人脸识别或面部表情识别)。深度学习的好处是用非监督式或半监督式的特征学习和分层特征提取高效算法来替代手工获取特征。
深度学习是属于机器学习中的一个分支,度学习技术掀起了人工智能研究与应用的新一轮浪潮,深度学习技术在多个方面取得了较大突破,其在人工智能系统中所占的比例日趋增大,已经应用于多项实际场景业务系统中。
- 人工神经网络
- 人工神经网络的内部是一个黑盒子,就像我们人类的大脑一样,我们不知道它内部的分析过程,我们不知道它是如何识别出人脸的,也不知道它是如何打败围棋世界冠军的。我们只是为它构造了一个躯壳而已。人工神经网络是受到人类大脑结构的启发而创造,下图是一个人工神经网络的构造图。
- x是神经元的输入,w是对应的权重,影响着每个输入x的刺激强度,网络的结构越复杂,也就是深度神经网络,训练深度神经网络的过程就称为深度学习。
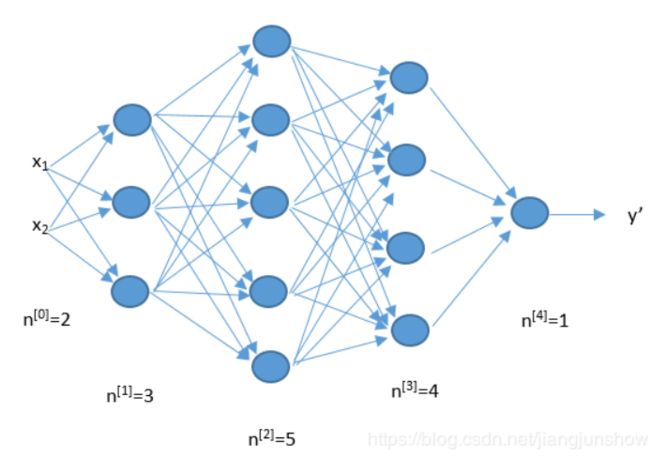
- 深度神经网络( DNN: Deep Neural Networks )也有许多类型,例如:
- 卷积神经网络( CNN: Convolutional Neural
Networks) - 循环神经网络( RNN: Recurrent Neural Networks)
- 生成对抗网络( GAN: Generative Adversarial Networks)
- 卷积神经网络( CNN: Convolutional Neural
深度学习与密码分析
深度学习与密码分析可以分为以下四类:
- 基于卷积神经网络的侧信道攻击
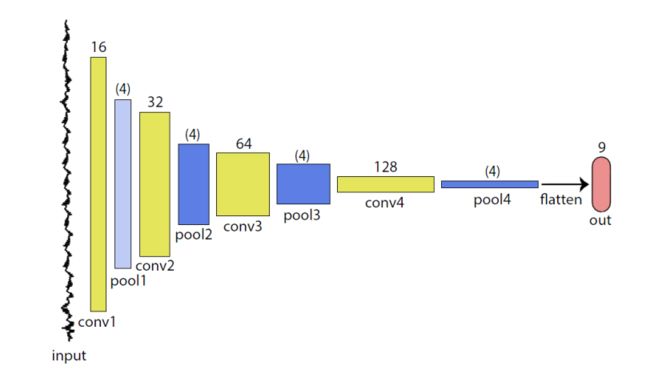
- 基于循环神经网络的明文破译
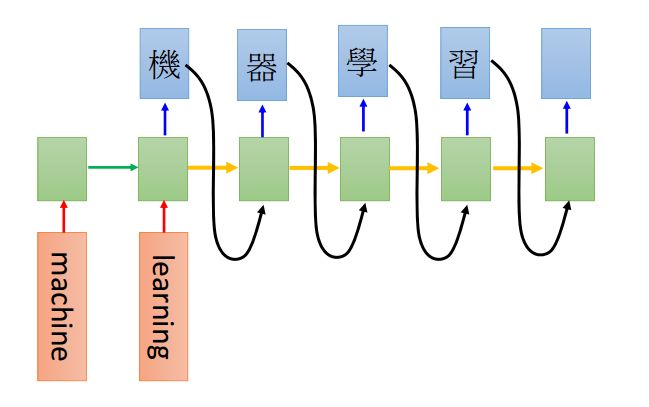
基于生成对抗网络的口令破解
- 通过测试集训练对抗网络判别口令的正确与错误,可以实现破解口令的功能。
对抗网络
生成式对抗网络(GAN, Generative Adversarial Networks )是一种深度学习模型,是近年来复杂分布上无监督学习最具前景的方法之一。模型通过框架中(至少)两个模块:生成模型(Generative Model)和判别模型(Discriminative Model)的互相博弈学习产生相当好的输出。
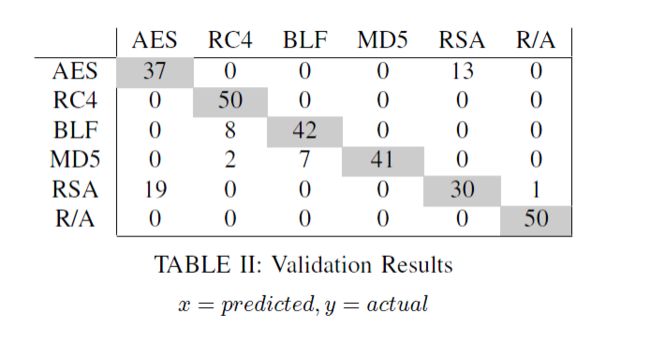
基于深度神经网络的密码基元识别
随着加密算法的复杂性以及秘钥长度的增加,明文破译的难度也随之增加,发展不如其他方面那么好,基于深度神经网络的密码基元可以识别出加密所使用的的算法。
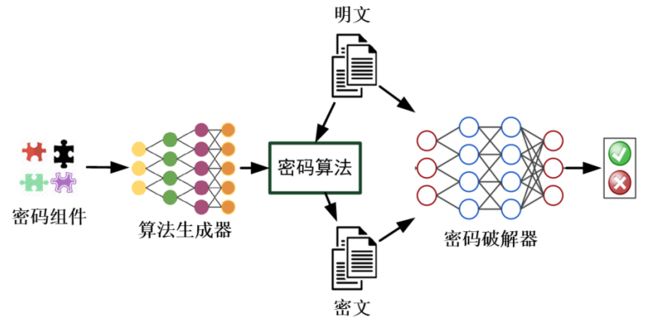
深度学习与密码设计
密码分析在深度学习领域的发展会随着量子技术的出现而阻碍,由于量子技术对于离散对数、整数分解的公钥密码体制将被快速攻破,意味着网络信息系统不再安全。“组件化可变密码算法设计与安全性评估”,“密文可编程数据安全存储与计算”,两大问题是解决现在密码技术收到威胁的方法。因此,设计更为安全的密码算法是如今更为重要的课题。
对于新密码算法的设计需求将与日俱增,但目前人工设计密码算法耗时耗力,难以适应未来密码算法设计的需求,我们提出————让机器自动设计密码算法
第四次课 —— 信息隐藏
隐写
- LSB嵌入
- 最简单且最普遍的隐写算法,采用最低有效位嵌入的算法(The Least Significant Bit, LSB)
基本步骤
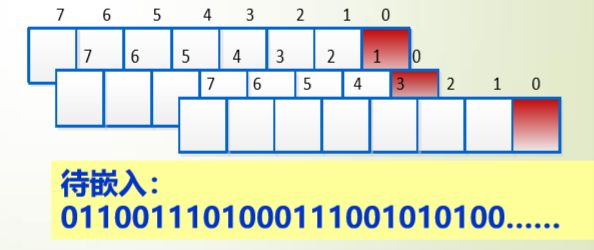
1 将原始载体图像的空域像素值由十进制转换成二进制;
2 用二进制秘密信息中的每一比特信息替换与之相对应的载体数据的最低有效位;
3 将得到的含秘密信息的二进制数据转换为十进制像素值,从而获得含秘密信息的图像。
- 矩阵嵌入
- 以最小的嵌入修改数目达到嵌入要传递消息的目的,可提高嵌入效率,即利用较少的嵌入修改嵌入同样数量的秘密消息。
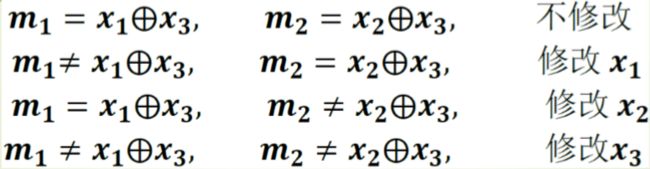
如上图所示,矩阵嵌入是在LSB嵌入的基础上对嵌入修改数目的减少,
- 自适应隐写
自适应隐写的特点在于不考虑载体的图像内容,同时在图片中属于随机嵌入消息。
实现方法:嵌入失真函数+STCs编码
根据构造的嵌入失真函数计算载体图像中元素发生更改所引起的失真,利用隐写编码控制密码信息的嵌入位置,在最小化图像总体嵌入失真的同时保证秘密信息的准确提取。
- 空域自适应隐写
- WOW (Wavelet Obtained Weights)
- S-UNIWARD(Spatial UNIversal WAvelet Relative Distortion)
- HILL (HIgh-pass, Low-pass, and Low-pass)
- JPEG域自适应隐写
- UED(Uniform Embedding Distortion)
- SC-UED(Single Coefficient UED)
- JC-UED(Joint Coefficients UED)
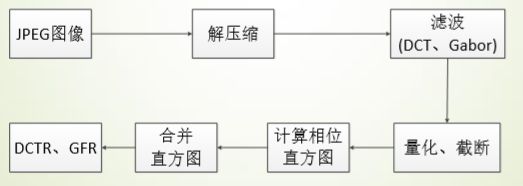
- J-UNIWARD(JPEG UNIversal WAvelet Relative Distortion) 隐写分析
高维特征
- 高维隐写分析特征 高维隐写分析特征可以尽可能多地捕获隐写对图像统计特征的影响
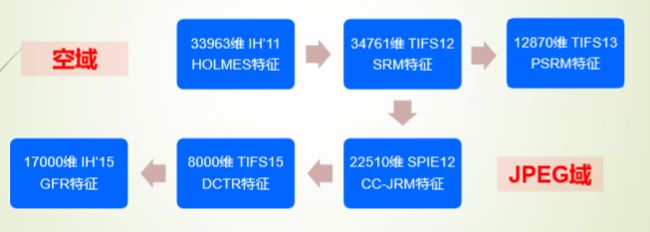
- 空域高维隐写分析特征
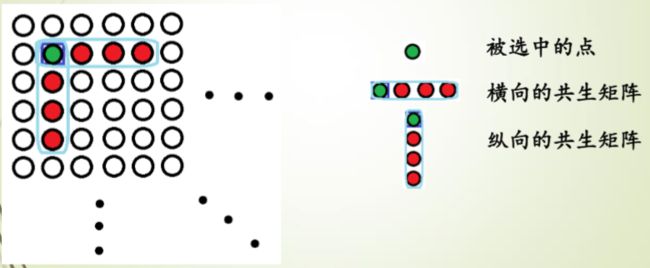
- 34761维 SRM (残差图像+共生矩阵)
- 12870维 PSRM (残差投影+直方图)
- 8000维 DCTR
- 12600维 PHARM
- 17000维 GFR
隐写选择信道
选择信道高维隐写分析特征,以下是其发展历程:
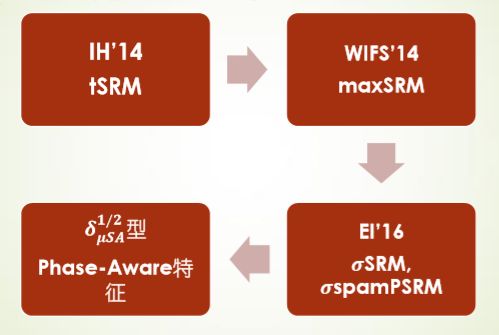
- tSRM 非全局提取特征,从代价较小的像素上提取SRM特征
- maxSRM SRM在统计共生矩阵时,乘以该共生矩阵中对应像素的最大嵌入修改概率。
- σSRM, σspamPSRM
- 特征是从残差系数上提取的,嵌入修改概率是像素上的
- 但是两者并不一一对应
- 嵌入修改对残差图像系数的影响作为累加值
- SCA-DCTR, SCA-PHARM, SCA-GFR
- DCT域的嵌入修改对滤波图像的影响作为累加值
人工智能在隐写分析上的应用
- Li Bin的“Auto-Encoder”
- Qian系列:系统地提出了“GNCNN”
- XuNet系列
- NiJQ最新:YeNet,新结构
- XuGuanShuo:Res on J-UNIWARD
第五次课 —— 区块链
比特币
比特币的交易方式
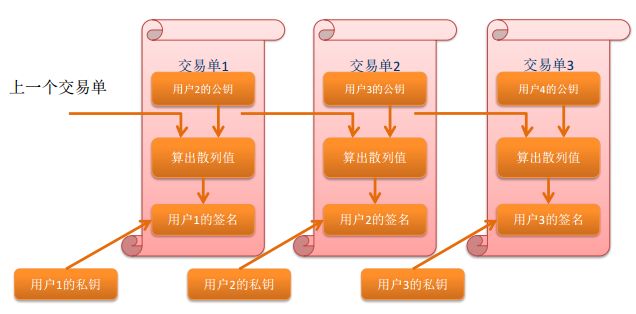
每一位所有者(A)利用他的私钥对前一次交易T1和下一位所有者(B)的公钥(俗称:地址)签署一个随机散列的数字签名, A将此数据签名制作为交易单T2并将其(交易单T2)广播全网,电子货币就发送给了下一位所有者。
【注意】前一次交易是指 这里比特币是如何到达现在这位用户手中的,前一份表单。
特点:
- 交易发起者的私钥:只为个人所知,他人无从知晓
- 前一次交易:前一次交易说明了该次交易的货币的来源
- 下一位所有者的公钥:即交易接收方的地址,次数据说明了当前交易的目标是谁
- 数字签名:发起方将前一次交易数据和接收方公钥连接起来并对其求Hash值x,再利用自己的私钥对x加密,得到这份数字签名
验证交易:
- 利用交易T2中交易的发起方A的公钥对签名进行解密,得到整数x。
- 将T1交易数据和B的公钥连接起来,用同样的Hash算法计算Hash值y。
- 若x==y,说明:
- 这笔交易确实是A本人发起的,因为只有A本人的私钥才可以生成此签名(A同时也无法否认自己曾签署了此份交易)。
- 交易的目的方确实是B。
- 发起方确实是打算把交易T1中A获得的货币发送给B。
比特币网络中,数据以文件的形式被永久记录,被称之为区块(Block)。
区块链
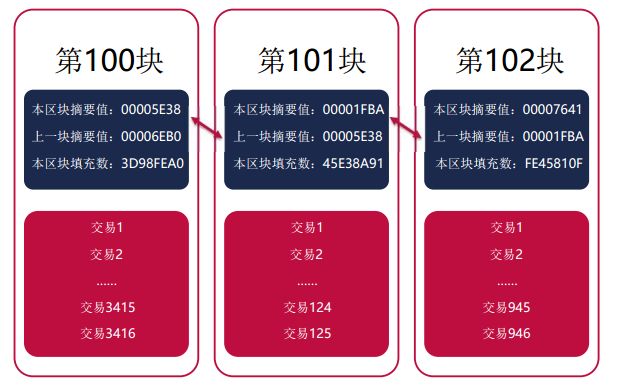
许多的区块构成了区块链,Block之间以双向链表的方式链接起来,并且每个Block都会保存其上一个Block的Hash值,只有一个Block没有上一个节点,即创世Block。Block有很多份, 每个Block只记录比特币全网10分钟内的交易信息,每约10分钟产生一个新的Block。产生Block的过程,也被称为“挖矿”。
区块链的核心技术
- 分布式账本
- 交易记账由分布在不同地方的多个节点共同完成,而且每一个节点都记录的是完整的账目,因此它们都可以参与监督交易合法性,同时也可以共同为其作证。
- 非对称加密和授权技术
- 存储在区块链上的交易信息是公开的,但是账户身份信息是高度加密的,只有在数据拥有者授权的情况下才能访问到,从而保证了数据的安全和个人的隐私。
- 共识机制
- 所有记账节点之间怎么达成共识,去认定一个记录的有效性,这既是认定的手段,也是防止篡改的手段。区块链提出了四种不同的共识机制,适用于不同的应用场景,在效率和安全性之间取得平衡。
- 区块链的共识机制具备“少数服从多数”以及“人人平等”的特点
- 智能合约
- 智能合约是基于这些可信的不可篡改的数据,可以自动化的执行一些预先定义好的规则和条款。以保险为例,如果说每个人的信息都是真实可信的,那就很容易的在一些标准化的保险产品中,去进行自动化的理赔。
工作量证明
工作量证明系统主要特征是客户端需要做一定难度的工作得出一个结果,验证方却很容易通过结果来检查出客户端是不是做了相应的工作。下图表示的是工作量证明的流程:
51%攻击
- 将手中的BTC充值各大交易所,然后卖掉,提现;或者也可以直接卖给某人或某一群人;
- 运用手中的算力,从自己对外付款交易之前的区块开始,忽略自己所有对外的付款交易,重新构造后面的区块,利用算力优势与全网赛跑,当最终创建的区块长度超过原主分支区块,成为新的主分支,至此,攻击完成;
第六次课 —— 漏洞挖掘与攻防技术
常见的安全漏洞及漏洞挖掘技术
- 手工测试
- 定义:由测试人员手工分析和测试被测目标,发现漏洞的过程,是最原始的漏洞挖掘方法。
- 补丁对比
- 定义:补丁比对技术主要用于黑客或竞争对手找出软件发布者已修正但未尚公开的漏洞,是黑客利用漏洞前经常使用的技术手段。
- 程序分析 (包含静态和动态程序分析)
- 定义::是指在不运行计算机程序的条件下,通过词法分析、语法分析、语义分析、控制流分析、污点分析等技术对程序代码进行扫描,验证代码是否满足规范性、安全性等指标的一种代码分析技术。
- 二进制审核
- 定义:源代码不可得,通过逆向获取二进制代码,在二进制代码层次上进行安全评估
- 模糊测试
- 定义:通过向被测目标输入大量的畸形数据并监测其异常来发现漏洞
程序分析
- 基于静态分析的漏洞挖掘技术
- 数据流分析:Foritify SCA、Coverity Pervent、FindBugs等
- 污点分析:Pixy、TAJ
- 符号执行:Clang、KLEE
- 模型检测:BLAST、MAGIC、MOPS
- 基于动态分析的漏洞挖掘技术
- 插桩技术:插桩技术是指在保证被测程序逻辑完整性的基础上在程序的关键位置插入一些“桩”,即加入一些测试代码,然后执行插桩后的程序,通过“桩”的执行获取程序的控制流和数据流信息进而分析程序的异常行为
- 工具:Android: Xposed
漏洞挖掘技术进展
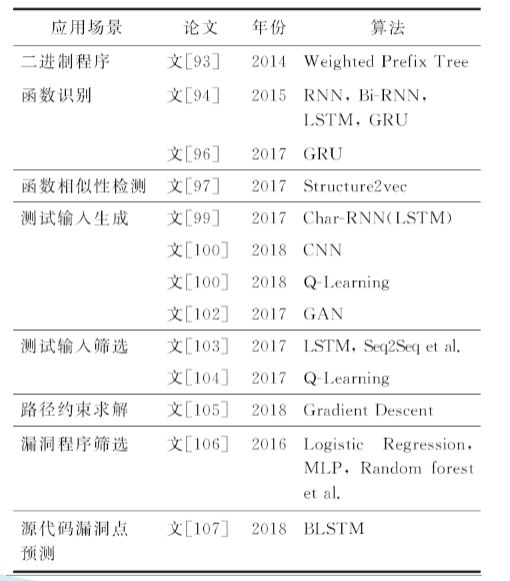
从图中可以看到,主要应用场景在:二进制程序函数识别、函数相似性检测、测试输入生成、测试输入筛选、路径约束求解、漏洞程序筛选、源代码漏洞点预测。
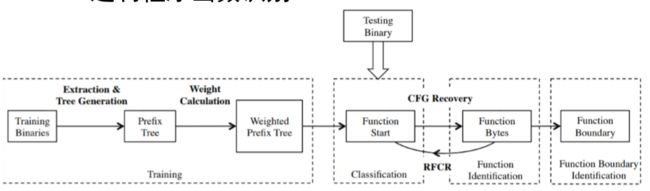
二进制程序函数识别
二进制程序函数识别是二进制分析的基础,对于软件漏洞分析与修复,甚至恶意软件检测、协议逆向等都至关重要。由于二进制代码缺少高级语言程序中的信息,函数的识别往往比较困难,现有的反汇编分析工具具有识别正确率低的缺陷。
测试用例生成
在软件漏洞挖掘中,构造代码覆盖率高或脆弱性导向型的测试输入能提高漏洞挖掘的效率和针对性,利用机器学习知道生成更高质量的测试输入样本。Godefroid等首次把模糊测试中的高结构化样本生成问题转换成了NLP领域的文本生成问题。接下来不断提出了深度神经网络指导磨合测试输入样本。
路径约束求解
模糊测试,特别是代码覆盖率指导的模糊测试,侧重于筛选可以覆盖新路径的样本为种子文件,但对种子文件变异时并没有充分利用程序数据流等信息指导变异,这使得变异盲目低效,生成样本冗余。
具备路径约束求解能力是符号执行比模糊测试等漏洞挖掘技术更先进的体现,也使得符号执行在理论上具备了系统性探索程序执行路径的能力。
但约束求解也存在着路径爆炸,效率较低等问题。Chen等提出了Angora,采用污点追踪测试输入中影响条件分支的字节,然后使用梯度下降的方式对变异后生成的路径约束进行求解。
2.感想和体会
时间总是过得飞快,而本学期认真地说,这门课是让我获益最大的两门课之一,特别是每一次的讲座,不同的老师有自己不同的方向,邀请这些老师进行分享是一件非常有意义的事情,我们不了解的可以向老师请教,同时,也可以通过老师的分享,学习和了解在这个方向如何有效学习、最新的研究都涉及哪些方面等等。
从这门课中,最令我受益匪浅的应该是顶会论文的学习,以往可能更多会关注中文论文,觉得英文论文自己也看不懂;而且,也学会了如何查找某一领域内的顶会论文,从这些大神的论文中,学习到的更多是逻辑思维,写论文的方式,层层递进的写作手法,可能有些内容或公式我看不太懂,但是有些研究成果真的十分新颖。
现在很多技术都可以和密码学相结合,交叉学科才是未来发展的方向,综合应用自己所学知识,并不断探索新的领域,这门课也是在帮我们拓宽视野,拓宽思路,解决问题的方法并不是单一的,更重要的是关注解决问题的过程,就像前面每次课的总结博客,寻找问题的答案并解决的过程是一个令人快乐的过程,总结出来自己的收获才更有意义。
这门课不仅仅是在和老师学习,同时也是在和同学们学习,特别是顶会论文复现的时候,我十分佩服各组同学的学习能力,能在短短几周内研究透顶会论文并复现,而且很多同学的PPT做的十分有逻辑,也是我日后要加强的方面。
3.对本课程的建议和意见
- 老师可以在以后的课程中,提前建群,和同学沟通了解同学们感兴趣的方向,充分利用这种沟通机制,及时了解同学们感兴趣的方向。
- 顶会论文的学习和复现,希望老师可以早点布置下来,这样同学们也有机会充分寻找到自己感兴趣的论文,适合自己能力的论文等等。
- 总体来说这门课程十分有意义,为以后的学习和工作打下了良好的基础,谢谢各位讲座的老师,谢谢王老师,各位老师辛苦了!
致谢!(`・ω・´)ゞ(`・ω・´)ゞ