提出了模型和损失函数
论文名称:扩展卷积密集连接神经网络用于时域实时语音增强
论文代码:https://github.com/ashutosh620/DDAEC
引用:Pandey A, Wang D L. Densely connected neural network with dilated convolutions for real-time speech enhancement in the time domain[C]//ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020: 6629-6633.
摘要
在这项工作中,我们提出了一个全卷积神经网络在时域实时语音增强。提出的网络是一种基于编码器-解码器的结构,具有跳跃连接。编码器和解码器中的层后面是由扩张和因果卷积组成的紧密连接块。扩张卷积有助于不同分辨率的上下文聚合。因果卷积用于避免未来帧的信息流,从而使网络适合于实时应用。我们还提出在解码器中使用亚像素(ub-pixel)卷积层进行上采样。此外,使用具有两个分量的损失函数来训练模型;时域损失和频域损失。提出的损失函数优于时域损失。实验结果表明,该模型在客观可理解性和质量得分方面明显优于其他实时模型
关键词:时域,全卷积,密集网络,时频损失,说话人和噪声无关
1 引言
语音增强涉及改善被附加噪声污染的语音信号的智能性和质量。它被用作许多应用的预处理器,例如自动语音识别、电信、助听器和人工耳蜗植入物。
近年来,语音增强已经被定义为一个有监督的学习问题,深度神经网络也得到了广泛的研究。有监督的语音增强方法通常是将语音信号转换为一个时频(T-F)表示,并根据T-F表示构造一个目标信号作为训练目标。最常用的训练目标是理想比率掩模(IRM)[2]、相位敏感掩模(PSM)[3]和短时傅里叶变换(STFT)幅度。这些训练目标仅用于增强短时傅里叶变换幅度。混合语音相位被原封不动地用于时域信号重构。
噪声语音的相位没有增强,主要是因为它没有清晰的可学习结构[4],并且被认为对语音增强并不重要[5]。最近的一项研究表明,相位对语音的感知质量很重要,特别是在低信噪比条件下[6]。这导致研究人员探索使用深度神经网络来增强相位和幅度的算法。
利用深度学习同时增强相位和幅度的两种流行方法是复数域增强和时域增强。在复数域增强中,通常将DNN训练成将噪声短时傅里叶变换映射到复数IRM(CIRM)或干净的短时傅立叶变换。在文献[4,7,8,9,10]中对其进行了探索,取得了令人满意的结果。时域方法不需要对模型进行频域变换,直接从噪声样本中预测干净的原始样本。此外,时域网络可以学习提取非常适合特定语音增强任务的特征或表示。有代表性的时域方法包括[11,12,13]
在这项工作中,我们提出了一个全卷积神经网络在时域实时语音增强。提出的网络是一种基于编码器-解码器的结构,具有跳跃连接。我们的新贡献是在编码器和解码器的每一层之后添加密集连接(densely connected)的块[14],并进行扩展卷积。此外,我们采用亚像素卷积层代替转置卷积进行上采样。扩张和密集连接的块有助于在信号的不同分辨率上的长范围上下文聚合。我们还建议使用时域损失和频域损失的组合来训练模型。
本文的其余部分组织如下。我们将在第2节描述所建议的方法。实验装置和结果在第3节中给出。第四部分对本文进行总结。
2 模型描述
2.1 扩张(Dilated)卷积
扩张卷积被用来增加卷积神经网络的感受场,作为学习长短期记忆网络(LSTM)的一种有效选择,它正变得越来越受欢迎。在扩张率为$r$的扩张卷积中,$r−1个零被插入在过滤的连续系数之间。在大小为$M$的滤波器中,$r$的扩张率将感受野从$M$增加到$(M−1)∗(r−1)+M$。通过在网络内使用指数增加的扩张率,可以将感受野设置为任意大小。一般做法是使用{1,2,4,8,16,...}形式的扩张率序列。在我们的模型中,dense block由扩张卷积和因果卷积组成。在各帧之间使用因果卷积,以确保不会有来自未来帧的信息泄漏。请注意,我们在一个框架内不使用因果卷积。图1中显示了膨胀卷积和因果卷积的示意图。

图1 具有大小滤波器的扩张因果卷积的示例
2.2 密集连接的卷积神经网络
密集连接网络(Dense connected networks, DCN)是最近在文献[14]中提出的。在DCN中,网络中给定层的输入是所有先前层的输出的级联。这种方法有两个主要优点。首先,对前面的所有层进行去连接,避免了消失的梯度问题。其次,发现较薄的密集网络的性能优于较宽的正常网络,从而提高了网络的参数效率。在我们的模型中,我们提出了一种在模型的编码器和解码器的每一层之后使用的扩张Dense块。建议的dense块的示意图如图2所示。
每个dense块由五层二维卷积组成。帧之间的卷积是因果的,因果卷积保证了所提出的方法适合实时实现。每次卷积之后是层归一化[15]和参数ReLU(PReLU)非线性[16]。每个dense块的扩张率设置为1、2、4、8和16,如图所示。
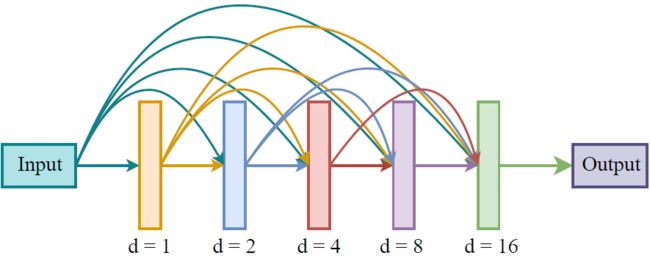
图2:提出的膨胀密块。扩张率从1成倍增加到16
2.3 sub-pixel卷积
在卷积神经网络中,sub-pixel卷积被用作可学习的上采样层。文献[17]提出了图像超分辨率的概念。在这项工作中,我们使用sub-pixel卷积作为转置卷积的一种更好的选择,以避免棋盘状伪影[18]。在转置卷积中,输入信号首先通过在随后的卷积层的连续采样之间插入零来进行上采样,以获得具有非零条目的信号。如果过滤的跨度不能被滤波器长度整除,这就导致了不对称的配置,从而造成了棋盘状的假象[18]。在亚像素卷积中,对原始信号进行卷积(不加零),输出通道数增加上采样率的倍数。对额外的信道进行整形以获得所需的上采样信号。图3中示出了使用子像素卷积将1D信号上采样2倍的说明性图

图3:用于将1D信号上采样2倍的子像素卷积的图示
2.4 模型架构
模型体系结构示意图如图4左侧所示。该模型由输入层、编码器、dilated和dense块、解码器和输出层组成。除输出层外的所有卷积都遵循层归一化和PReLU nonlinearity(非线性特征)。模型的输入尺寸为[batch_size, 1, num_frames, frame_size)。输入层使用大小为(1,1)的滤波器将通道数量增加到64个。输入层后面跟着一个密集的块。所有密集块中的卷积使用大小为(2,3)的滤波器,具有64个输出通道。编码器中的每一层使用步长为(1,2)的卷积和大小为(1,3)的滤波器,沿帧轴(最后一个轴)将尺寸的前半部分(下采样)。下采样之后是一个dense块。编码器中每一层后的dense块有助于不同分辨率的上下文聚合。编码器中有6个这样的层,编码器的最终输出大小为[batch size, 64, num frames, frame size/64]。
解码器使用亚像素卷积和dense块,依次将信号重构到原始大小。解码器中每一层的输入是前一层输出和编码器中相应对称层输出的连接(沿通道轴)。亚像素卷积使用尺寸为(1,3)的滤波器沿帧轴使输入尺寸加倍。最后,输出层使用大小为(1,1)的滤波器输出带有一个通道的增强帧。
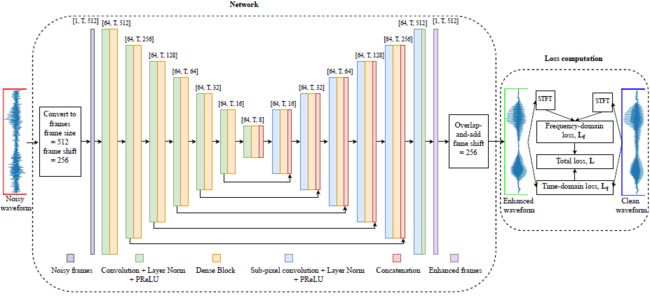
图4 提出了模型和损失函数
2.5 损失函数
我们使用两个损失的组合来进行模型训练。首先,使用重叠加方法将数据帧转换成波形。使用增强发音和干净发音之间的均方误差在时域中计算发音电平损失。时域损耗定义为
$$公式1:L_{l}(x, \hat{x})=\frac{1}{M} \sum_{n=0}^{M-1}\left(x_{i}[n]-\hat{x}_{i}[n]\right)^{2}$$
其中$x[n]$和$\hat{x}[n]$分别表示纯净和增强语音的第n个样本,而M是语音长度。
其次,我们采用语音的STFT,并且像在[20,11]中那样在STFT系数的L1范数上使用L1 损失[19]。频域损失由下式给出
$$公式2:\begin{array}{r}
L_{f}(\boldsymbol{x}, \hat{\boldsymbol{x}})=\frac{1}{T \cdot F} \sum_{t=1}^{T} \sum_{\delta=1}^{F} \mid\left(\left|X(t, f)_{r}\right|+\left|X(t, f)_{i}\right|\right)-
\left(\left|\hat{X}(t, f)_{r}\right|+\left|\hat{X}(t, f)_{i}\right|\right) \mid
\end{array}$$
其中$X(t,f)$和$\hat{X}(t,f)$分别是x和$\hat{x}$的STFT的T-F单位。T是帧数,F是频段数。$X_r$和$X_i$分别表示复变量X的实部和虚部。
最后,将时域损耗和频域损失按以下方式组合:
$$公式3:L(\boldsymbol{x}, \hat{\boldsymbol{x}})=\alpha * L_{l}(\boldsymbol{x}, \hat{\boldsymbol{x}})+(1-\alpha) * L_{f}(\boldsymbol{x}, \hat{\boldsymbol{x}})$$
其中$\alpha$是在验证集上调优的超参数。损失计算的示意图如图4的右侧所示。
3 实验
3.1 数据集
我们通过在大量的噪声和扬声器上训练我们的系统,以一种与扬声器和扬声器无关的方式对我们的系统进行评估,我们使用了来自WSJ0SI-84数据集的7138个话语[21]。共83人(男42人,女41人),其中76人用于培训,其余6人(男3人,女3人)用于评估。
为了进行训练,我们使用了音效库(www.ound-ideas.com)[22]中的10000个非语音,在-5dB、-4dB、-3dB、-2dB、-1dB和0dB的信噪比下生成了320000个语音。嘈杂的话语是通过以下方式产生的。首先,随机选择来自训练说话者的发音、SNR和噪声类型。然后,在所选SNR处将所选话语与所选噪声类型的随机分段混合。
对于测试集,我们使用AuditecCD(可在http://www.auditec.com),购买)的两种噪声(杂音和咖啡音),分别在-5dB、-2dB、0dB、2dB和5dB的信噪比下生成150种混音。对于验证集,我们使用训练集(150个话语)中的6个说话者,并在-5dB的信噪比下将其与工厂噪声混合。
3.2 基线
对于基线,我们训练了4个不同的模型。首先,我们训练了文献[8]中提出的基于复数谱映射的模型,为了便于比较,我们将该模型称为CRN。其次,我们训练时域模型,这是一个基于帧的系统,具有较大的帧大小(1.024秒),并使用超过STFT幅度的损失进行训练[20]。我们称这种模型为AECNN-SM。最后,我们训练了文献[13]中提出的TCNN模型。
3.3 实验步骤
所有的声音都被重新采样到16 kHz。使用大小为32ms且重叠为16ms的矩形窗口来提取帧。在训练的每个时期,如果话语大于4秒,我们就从话语中去除4秒的随机片段。较短的语音是该batch中最长语音的大小的零填充匹配。AdamOptimizer用于基于随机梯度下降(SGD)的优化。我们用表2给出的学习速率时间表和4个话语的批量对该模型进行了15个时期的训练。在训练时,我们观察每次训练后验证集上的短时客观信息(STOI)[23]得分,并用STOI最大的模型进行评估。我们将等式3中的α设置为0.8.
我们在https://github.com/ashutosh620/DDAEC.为我们的实现提供了代码
3.4 实验结果
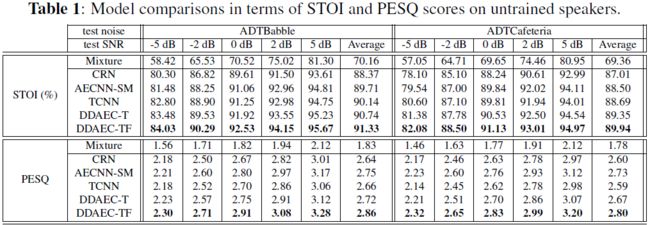
我们从STOI(典型的取值范围为0到1)和感知语音质量评价(PESQ)(取值范围为-0.5到4.5[24])对所有模型进行了比较。结果如表2所示。我们称提出的模型为DDAEC,代表膨胀和密集的自动编码器。我们报告了两个关于DDAEC的结果,一个是只使用时域损失(DDAEC-T)训练的,另一个是使用建议的时频损失(DDAEC-TF)训练的。

首先,我们观察到DDAEC-T模型在STOI方面优于所有的基线模型。对于PESQ,它的性能优于除AECNN-SM以外的所有基线模型,AECNN-SM是一种基于帧的模型,帧长较大,因此不适合实时实现。但是,当使用时频损失时,DDAEC在得分和所有信噪比条件下都优于所有基线模型。对于STOI,最好的基线是TCNN,对于胡言乱语和食堂噪声分别获得1.19%和1.24%的平均改善。对于PESQ,最好的基线是AECNN-SM,对于两种噪声,分别获得了0.11和0.17的改善。DDAEC-T和DDAEC-TF的性能明显优于CRN模型,CRN模型是复谱图映射的主要频率模型。这说明了时域模型比频域模型的优越性。类似地,DDAEC-T和DDAEC-TF都优于另一个时域模型TCNN
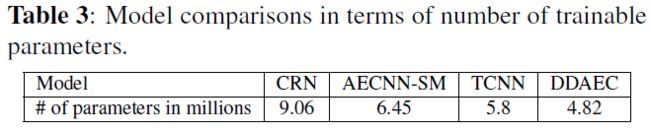
接下来,我们根据表 3 中列出的参数数量来比较所提出的模型。所提出的模型具有最少的参数数量,其次是 TCNN。 尽管 CRN 使用组 LSTM 来减少参数数量,但它具有最大数量的参数
4 结论
我们提出了一种新颖的全卷积神经网络用于语音增强。该模型利用带扩张卷积的去二次关联进行远程上下文聚合。该模型适用于实时实现,在客观清晰度和质量得分方面优于其他先进的模型。未来的工作包括探索所提出的多通道语音增强模型和其他语音预处理任务,如说话人分离和语音去混响
5 参考文献
[1] D. Wang and J. Chen, Supervised speech separation based on deep learning: An overview, IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 26, pp. 1702 1726, 2018.
[2] Y. Wang, A. Narayanan, and D. Wang, On training targets for supervised speech separation, IEEE/ACM Transactions on Audio, Speech and Language Processing, vol. 22, no. 12, pp. 1849 1858, 2014.
[3] H. Erdogan, J. R. Hershey, S.Watanabe, and J. Le Roux, Phase-sensitive and recognition-boosted speech separation using deep recurrent neural networks, in ICASSP, 2015, pp. 708 712.
[4] D. S. Williamson, Y. Wang, and D. Wang, Complex ratio masking for monaural speech separation, IEEE/ACM Transactions on Audio, Speech and Language Processing, vol. 24, no. 3, pp. 483 492, 2016.
[5] D. Wang and J. Lim, The unimportance of phase in speech enhancement, IEEE Transactions on Acoustics, Speech, and Signal Processing, vol. 30, no. 4, pp. 679 681, 1982.
[6] K. Paliwal, K. W ojcicki, and B. Shannon, The importance of phase in speech enhancement, speech communication, vol. 53, no. 4, pp. 465 494, 2011.
[7] S.-W. Fu, T.-y. Hu, Y. Tsao, and X. Lu, Complex spectrogram enhancement by convolutional neural network with multi-metrics learning, in International Workshop on Machine Learning for Signal Processing, 2017, pp. 1 6.
[8] K. Tan and D. Wang, Complex spectral mapping with a convolutional recurrent network for monaural speech enhancement, in ICASSP, 2019, pp. 6865 6869.
[9] H.-S. Choi, J.-H. Kim, J. Huh, A. Kim, J.-W. Ha, and K. Lee, Phase-aware speech enhancement with deep complex U-Net, arXiv preprint arXiv:1903.03107, 2019.
[10] A. Pandey and D. Wang, Exploring deep complex networks for complex spectrogram enhancement, in ICASSP, 2019, pp. 6885 6889.
[11] , A new framework for supervised speech enhancement in the time domain, in INTERSPEECH, 2018, pp. 1136 1140.
[12] S.-W. Fu, T.-W. Wang, Y. Tsao, X. Lu, and H. Kawai, End-to-end waveform utterance enhancement for direct evaluation metrics optimization by fully convolutional neural networks, IEEE/ACM Transactions on Audio, Speech and Language Processing, vol. 26, no. 9, pp. 1570 1584, 2018.
[13] A. Pandey and D. Wang, TCNN: Temporal convolutional neural network for real-time speech enhancement in the time domain, in ICASSP, 2019, pp. 6875 6879.
[14] G. Huang, Z. Liu, L. Van Der Maaten, and K. Q. Weinberger, Densely connected convolutional networks, in IEEE conference on computer vision and pattern recognition, 2017, pp. 4700 4708.
[15] J. L. Ba, J. R. Kiros, and G. E. Hinton, Layer normalization, arXiv preprint arXiv:1607.06450, 2016.
[16] K. He, X. Zhang, S. Ren, and J. Sun, Delving deep into rectifiers: Surpassing human-level performance on imagenet classification, in IEEE International Conference on Computer Vision, 2015, pp. 1026 1034.
[17] W. Shi, J. Caballero, F. Husz ar, J. Totz, A. P. Aitken, R. Bishop, D. Rueckert, and Z.Wang, Real-time single image and video super-resolution using an efficient subpixel convolutional neural network, in IEEE conference on computer vision and pattern recognition, 2016, pp. 1874 1883.
[18] A. Odena, V. Dumoulin, and C. Olah, Deconvolution and checkerboard artifacts, Distill, 2016. [Online]. Available: http://distill.pub/2016/deconv-checkerboard
[19] A. Pandey and D. Wang, On adversarial training and loss functions for speech enhancement, in ICASSP, 2018, pp. 5414 5418.
[20] , A new framework for cnn-based speech enhancement in the time domain, IEEE/ACM Transactions on Audio, Speech and Language Processing (TASLP), vol. 27, no. 7, pp. 1179 1188, 2019.
[21] D. B. Paul and J. M. Baker, The design for the wall street journal-based CSR corpus, in Workshop on Speech and Natural Language, 1992, pp. 357 362.
[22] J. Chen, Y. Wang, S. E. Yoho, D. Wang, and E. W. Healy, Large-scale training to increase speech intelligibility for hearing-impaired listeners in novel noises, The Journal of the Acoustical Society of America, vol. 139, no. 5, pp. 2604 2612, 2016.
[23] C. H. Taal, R. C. Hendriks, R. Heusdens, and J. Jensen, An algorithm for intelligibility prediction of time frequency weighted noisy speech, IEEE Transactions on Audio, Speech, and Language Processing, vol. 19, no. 7, pp. 2125 2136, 2011.
[24] A. W. Rix, J. G. Beerends, M. P. Hollier, and A. P. Hekstra, Perceptual evaluation of speech quality (PESQ) - a new method for speech quality assessment of telephone networks and codecs, in ICASSP, 2001, pp. 749 752.