前言
本文介绍了现有实例分割方法的一些缺陷,以及transformer用于实例分割的困难,提出了一个基于transformer的高质量实例分割模型SOTR。
经实验表明,SOTR不仅为实例分割提供了一个新的框架,还在MS Coco数据集上超过了SOTA实例分割方法。
本文来自公众号CV技术指南的
关注公众号CV技术指南 ,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读。

论文:SOTR: Segmenting Objects with Transformers
代码:https://github.com/easton-cau/SOTR
Background
现代实例分割方法通常建立在CNN上,并遵循先检测后分割的范式,该范式由用于识别和定位所有对象的检测器和用于生成分割掩码的掩码分支组成。这种分割思想的成功归功于以下优点,即translation equivariance和location,但面临以下障碍:1)由于感受野有限,CNN在高层视觉语义信息中相对缺乏特征的连贯性来关联实例,导致在大对象上的分割结果次优;2)分割质量和推理速度都严重依赖目标检测器,在复杂场景下性能较差。
为了克服这些缺点,最近的许多研究倾向于摆脱先检测后分割的方式,转向自下而上的策略,该策略学习每个像素的嵌入和实例感知特征,然后使用后处理技术根据嵌入特性将它们连续分组为实例。因此,这些方法可以很好地保留位置和局部相干信息。然而,自下而上模型的主要缺点是聚类不稳定(如fragmented和joint masks),对不同场景的数据集的泛化能力较差。
此外,transformer能够容易地捕获全局特征,并自然地建模远程语义依赖。特别是,self-attention是transformer的关键机制,它广泛地聚合了来自整个输入域的特征和位置信息。因此,基于transformer的模型可以更好地区分具有相同语义类别的重叠实例,这使得它们比CNN更适合于高层视觉任务。
然而,这些基于transformer的方法仍然存在不足。一方面,transformer在提取低层特征时表现不佳,导致对小目标的错误预测。另一方面,由于特征映射的广泛性,需要大量的内存和时间,特别是在训练阶段。
Contributions
为了克服这些缺点,论文提出了一种创新的自下而上模型SOTR,该模型巧妙地结合了CNN和transformer的优点。
SOTR的重点是研究如何更好地利用transformer提取的语义信息。为了降低传统self-attention机制的存储和计算复杂度,论文提出了双注意力,它采用了传统注意力矩阵的稀疏表示。
1.论文提出了一种创新的CNN-Transformer-hybrid实例分割框架,称为SOTR。它可以有效地对局部连接和远程依赖进行建模,利用输入域中的CNN主干和transformer编码器,使它们具有高度的表现力。更重要的是,SOTR通过直接分割对象实例而不依赖于box检测,大大简化了整个流水线。
2.设计了双注意力,这是一种新的position-sensitive self-attention机制,是为transformer量身定做的。与原来的transformer相比,SOTR这种设计良好的结构在计算量和内存上都有很大的节省,特别是对于像实例分割这样的密集预测的大输入。
3.除了纯粹基于transformer的模型外,提出的SOTR不需要在大数据集上进行预训练,就可以很好地推广归纳偏差。因此,SOTR更容易应用于数据量不足的情况。
4.在MS Coco基准上,SOTR的性能达到了使用ResNet-101-FPN主干的AP的40.2%,在精确度上超过了大多数最SOTA方法。此外,由于twin transformer对全局信息的提取,SOTR在中型物体(59.0%)和大型物体(73.0%)上表现出明显更好的性能。
Methods
SOTR是一种CNN-Transformer混合实例分割模型,它可以同时学习2D表示并轻松捕获远程信息。它遵循直接分割的范例,首先将输入特征映射划分为patches,然后在动态分割每个实例的同时预测每个patch的类别。
具体地说,该模型主要由三部分组成:1)骨干模块,用于从输入图像中提取图像特征,特别是低层特征和局部特征;2)transformer,用于建模全局和语义依赖关系;3)多级上采样模块,用于将生成的特征图与相应的卷积核进行动态卷积运算,生成最终的分割掩模。
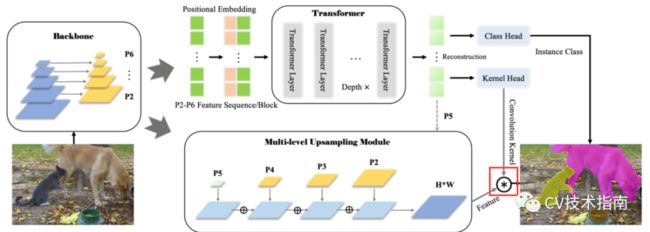
SOTR构建在简单的FPN主干上,只需最少的修改。该模型将FPN特征P2-P6展平,并在将它们送入transformer之前用位置嵌入来补充它们。在transformer之后增加了两个头,用于预测实例类并产生动态卷积核。多级上采样模块将FPN中的P2-P4特征和变压器中的P5特征作为输入,使用图中红框内所示的动态卷积操作生成最终的预测。
Twin attention
self-attention在时间和内存上的计算量都是二次方,在图像等高维序列上会产生更高的计算代价,并且阻碍了模型在不同环境下的可伸缩性。为了缓解这个问题,论文提出了twin attention(孪生注意力)机制,将注意矩阵简化为稀疏表示。
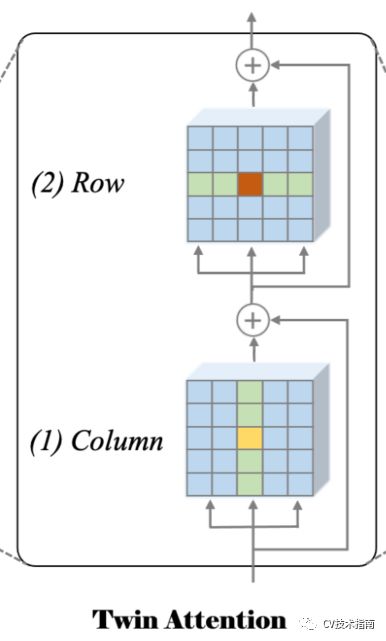
策略主要是将感受野限制在设计好的固定步幅的区块模式上。它首先计算每列中的attention,同时保持不同列中的元素独立。该策略可以在水平尺度上聚合元素之间的上下文信息(如图(1))。然后,在每一行中执行类似的注意,以充分利用垂直范围内的特性交互(如图(2))。这两个尺度中的注意力依次相连,成为最后一个,它有一个全局接受场,覆盖了两个维度上的信息。
给定FPN的特征图Fi为H×W×C(FPN的第i层),SOTR首先将特征图Fi切分成N∗N个patches ,其中Pi为N×N×C,然后沿垂直和水平方向将它们堆叠成固定的块。将位置嵌入添加到块中以保留位置信息,即列和行的位置嵌入空间为1∗N∗C和N∗1∗C。两个attention层都采用多头注意机制。为了便于多层连接和后处理,twin attention中的所有子层都产生N×N×C输出。
孪生注意机制能有效地把内存和计算复杂度从O((H×W)^2)降低到(H×W^2+W×H^2)。
Transformer layer
基于编码器的三个不同的transformer 层作为基本构建块(如下图所示)。原始transformer层类似于NLP(图(a))中使用的编码器,它由两部分组成:1)层归一化后的多头自我注意机制;2)层归一化后的多层感知。此外,使用残差连接来连接这两个部分。最后,可以得到多维序列特征,作为这些transformer层的K串联连接的输出,以便在不同的功能头中进行后续预测。
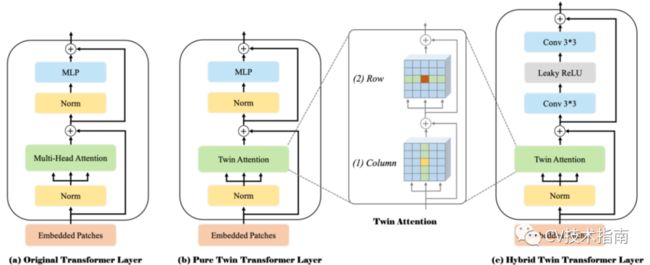
为了在计算成本和特征提取效果之间取得最佳折中,作者遵循了最初的transformer层设计,在pure twin transformer层中只用双注意力代替多头注意力(图(b))。
为了进一步提高twin transformer的性能,还设计了hybrid twin transformer 层,如图3(C)所示。它在每个孪生注意模块上增加了两个3×3的卷积层,由一个Leaky RELU层连接。通过引入卷积运算,可以对注意机制进行有益的补充,更好地捕捉局部信息,增强特征表示能力。
Functional head
来自transformer模块的特征图被输入到不同的functional head以进行后续预测。所述class head包括单层线性层,用于输出N×N×M的分类结果,其中M为类的个数。
由于每个patches只为中心落在patch中的单个对象分配一个类别,如YOLO,论文使用多级预测,并在不同的特征级别上共享头部,以进一步提高不同尺度对象的模型性能和效率。
kernel head也由线性层组成,与class head平行,以输出N×N×D张量用于后续掩码生成,其中张量表示具有D个参数的N×N卷积核。
在训练期间,Focal loss被应用于分类,而对这些卷积核的所有监督来自最终的掩模损失。
Mask
要构造掩码特征表示用于实例感知和位置敏感的分割,一种简单的方法是对不同尺度的每个特征图进行预测。然而,这会增加时间和资源。受Panoptic FPN的启发,论文设计了多级上采样模块,将FPN的每层和transformer的特征合并成一个统一的掩模特征。
首先,从transformer中获取具有位置信息的相对低分辨率特征图P5,并与FPN中的P2-P4相结合进行融合。对于每个尺度的特征图,分3×3Conv、Group Norm和ReLU几个阶段进行操作。然后,P3-P5对(H/4,W/4)分辨率分别进行2×、4×、8×的双线性上采样。最后,在处理后的P2-P5相加后,执行逐点卷积和上采样,以产生最终的统一的H×W特征图。
例如掩码预测,SOTR通过对上述统一特征映射执行动态卷积运算来为每个patch生成掩码。从kernel head给定预测的卷积内核K(N×N×d),每个kernel负责相应patch中实例的掩码生成。具体操作如下:
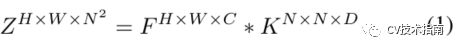
其中,∗表示卷积运算,Z是最终生成的掩码。应该注意的是,D的值取决于卷积核的形状,也就是说,D=λ^2C,其中λ是kernel大小。最终实例分割掩码可以由Matrix NMS产生,并且每个掩码由Dice Loss独立地监督。
Conclusion
1.原始transformer、pure twin transformer和hybrid twin transformer之间的对比
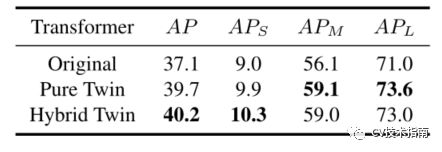
如上表所示,提出的pure hybrid twin transformers在所有指标上都大大超过了原始transformer,这意味着twin transformer架构不仅成功地捕获了垂直和水平维度上的远程依赖关系,而且更适合与CNN主干相结合来学习图像的特征和表示。
对于pure transformer和twin transformer,后者的效果要好得多。论文认为这是因为3∗3Conv能够提取局部信息并改进特征表达,从而提高了twin transformer的合理性。
2.mask的可视化
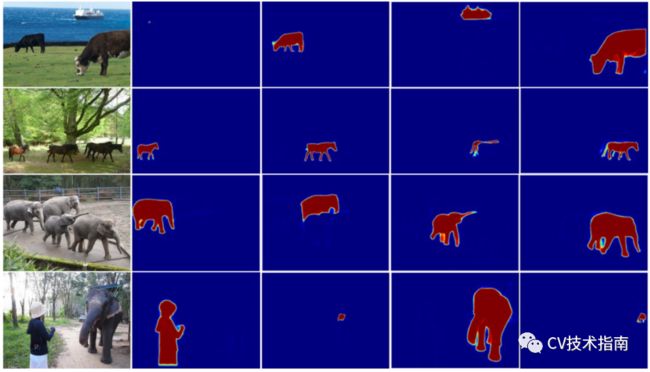
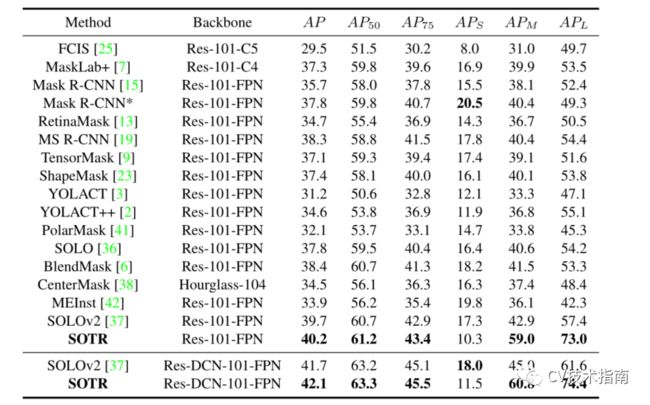
3.与其他方法的详细比较
在两种情况下,SOTR比Mask R-CNN和BlendMask的性能更好:
1)形状复杂、容易被其他模型遗漏的物体(例如火车前的胡萝卜、卧象、小车厢里的司机),Mask R-CNN和BlendMask无法将其检测为阳性实例。
2)相互重叠的物体(例如列车前面的人),两者不能用准确的边界将它们分开。SOTR能够用更清晰的边界预测掩模,而SOLOv2倾向于将目标分割成单独的部分(例如,将列车分为头部和身体),有时无法从图像中排除背景。由于transformer的引入,SOTR可以更好地获得全面的全局信息,避免了物体上的这种分裂。
此外,与SOTR相比,SOLOv2通过将不存在的对象指定为实例,具有较高的误报率。
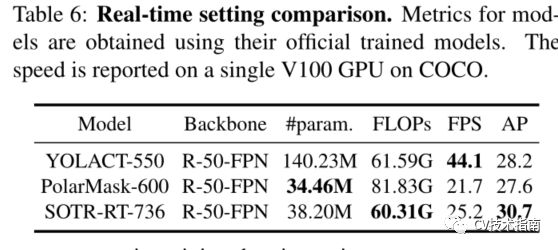
4.实时性比较
相关文章阅读
欢迎关注公众号 CV技术指南 ,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读。
在公众号中回复关键字 “入门指南“可获取计算机视觉入门所有必备资料。

其它文章