反爬虫与反反爬虫
1.反爬虫技术
首先我们来思考一下,为什么要反爬虫?
网络中充斥大量爬虫的情况下,会使得整个网络的数据不可靠。
网站在面对高并发爬虫的攻击时,很容易被击溃。
版权数据被爬取,对于网站来说是巨大的损失。
基于以上原因,反爬虫技术孕育而生,主要包含以下最常用的反爬技术:
封IP
后台对访问进行统计,如果单个IP访问超过阈值,则封锁该IP。
封UserAgent
后台对访问进行统计,如果单个UserAgent访问超过阈值,则封锁该UserAgent。
封Cookie
后台对访问进行统计,如果单个cookies访问超过阈值,则封锁该cookie.
设置请求时间间隔
设置请求时间间隔,规避过于频繁的请求访问,避免爬虫短时间爬取大量数据。
robots.txt协议
robots.txt是一个限制爬虫的规范,该文件是用来声明哪些东西不能被爬取; 设置robots.txt协议,位于robots.txt中的UserAgent不可请求网站数据。
验证码验证
发生大量请求时,弹出验证码验证,通过验证方可继续访问。
JavaScript渲染网页
将重要信息放在网页中但不写入html标签中,而浏览器会自动渲染标签中的js代码,将信息展现在浏览器当中,而爬虫是不具备执行js代码的能力,所以无法将js事件产生的信息读取出来。
ajax异步传输
访问网页的时候服务器将网页框架返回给客户端,在与客户端交互的过程中通过异步ajax技术传输数据包到客户端,呈现在网页上,爬虫直接抓取的话信息为空。
网页iframe框架嵌套
在下载框处再内嵌一个窗口,使得爬虫提取不到内层窗口的数据。
2.反反爬虫技术
有反爬虫技术,就会有反反爬虫技术存在,这是两种相互对抗的技术;这两种技术也在相互对抗中不断发展。
我们在编写爬虫时,要对获取海量的免费数据心怀感恩,而不是恶意攻击网站,这是一种害人害己的形为。
常用的反反爬虫技术有以下这些:
*降低请求频率
对于基于scrapy框架构建的爬虫,在配置文件settings.py中设置DOWN-LAOD_DELAY即可。
以下代码设置下载延迟时间为4秒,即两次请求间隔4秒。
DWONLOAD_DELAY = 4
或设置RANDOMIZE_DOWNLOAD_DELAY,定义一个随机的请求延迟时间。
RANDOMIZE_DOWNLOAD_DELAY = True
*修改请求头

*禁用Cookie
有些网站会通过Cookie来发现爬虫的轨迹,如非特殊需要,禁用Cookie可以切断网站通过Cookie发现爬虫的途径。
对于基于scrapy框架构建的爬虫,在配置文件settings.py中设置COOKIES_ENABLED即可。
#Disable cookies (enabled by default)
COOKIES_ENABLED = False
*伪装成不同的浏览器
Scrapy自带专门设置User-Agent的中间件UserAgentMiddleware,在爬虫运行中,会自动将User-Agent添加到HTTP请求中,并且可以设置多个浏览器,请求时可以随机添加不同的浏览器。
1.设定浏览器列表。
将浏览器列表定义至settings.py文件中:
MY_USER_AGENT = ["Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NETCLR 1.1.4322; .NET CLR 2.0.50727)", \
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser;SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)", \
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; WindowsNT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
]
2.在中间件UserAgentMiddleware中从浏览器列表中随机获取一个浏览器。
#导入UserAgentMiddleware组件模块
from scrapy.downloadermiddlewares.useragent import UserAgentMiddleware
import random #导入随机模块
from qidian_hot.settings import MY_USER_AGENT #导入浏览器列表
#定义类QidianHotUserAgentMiddleware,用于设置随机设置user-agent
#继承于UserAgentMiddleware
class QidianHotUserAgentMiddleware(UserAgentMiddleware):
#处理Request请求函数
def process_request(self, request, spider):
#使用random模块的choice函数从列表MY_USER_AGENT中随机获取一个浏览器类型
agent = random.choice(list(MY_USER_AGENT))
print("user-agent:", agent)
#将User-Agent附加到Reqeust对象的headers中
request.headers.setdefault('User-Agent', agent)
3.启用中间件UserAgentMiddleware。
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'qidian_hot.middlewares.QidianHotDownloaderMiddleware': None,
'qidian_hot.middlewares.QidianHotUserAgentMiddleware': 100,
}
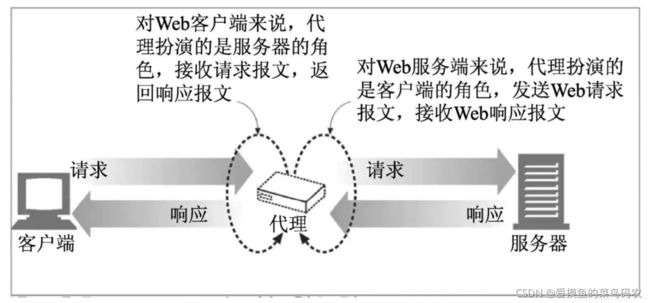
*使用HTTP代理服务器
HTTP代理服务器功能就是代理网络用户取获取网络信息,它相当于客户端浏览器和网站服务器之间的信息中转站。
在爬虫中采用大量的随机代理服务器访问某个网站,则该网站很难检测出爬虫。
学习Python最重要的就是心态。我们在学习过程中必然会遇到很多难题,可能自己想破脑袋都无法解决。这都是正常的,千万别急着否定自己,怀疑自己。如果大家在刚开始学习中遇到困难,想找一个python学习交流环境,可以加入我们的【python裙】,领取学习资料,一起讨论,会节约很多时间,减少很多遇到的难题。