2. Java基础的一些课堂笔记
1. Java SE: 标准版,定位在个人计算机。
2.JavaEE: 企业版,定位在服务器。
3.JavaME:微型版,消费性电子产品。
4.Java的核心优势:跨平台。
5. 运行机制:(编译解释型)源文件--->编译器--->字节码文件--->JRE(JVM)--->系统平台
6.JVM:执行字节码(bytecode)的虚拟计算机
7.JRE:包含JVM,库函数,运行java应用程序所必需的文件。
8.JDK:包含JRE,增加了编译器和调试器。
9.标识符:必须以字母、下划线或美元符号$;类名的每个单词的首字母大写,要有驼峰原则。
10. 变量:代表一个“可操作的存储空间”,位置确定,但是放什么值不确定。声明变量时最好一行声明一个变量。变量需要声明,而且必须初始化以后才能使用。
11.局部变量使用前需要初始化,从属于语句块;成员变量不需要初始化,它会被自动初始化,它从属于对象静态变量,使用static定义,从属于类。
12.数据类型: 基本数据类型:数值型:整数类型(byte “1”、short “2”、int “4”、long “8”) 、浮点型(float “4”、double “8”)
字符型:char "2"
布尔型:boolean "1位"
引用数据类型:类 、接口 、 数组 “4”
13. 常量(Constant):一个固定的值。使用大写字母和下划线命名。使用final来定义一个常量。一旦被初始化后不可以改变其值。
14. 二进制以0b或者0B开头,八进制以0开头,十六进制以0x或0X开头。
15. 浮点数不精确,一定不能用于比较。如果要使用精确浮点运算,推荐:BigDecimal。
16.Boolean 型占一位(注意不是一个字节),不可使用0或1代替true和false(与C语言的不同之处)。
17.关于整数运算: (1)如果两个操作数,有一个是long类型,则其结果为long型
(2)没有long时,结果为int。即使操作数全为short、byte,结果也是int。
18.关于浮点运算:(1)如果两个操作数有一个是double,则其结果为double;
(2)只有两个操作数都为float时,结果才是float。
19. 取模操作(%), 余数符号与左边的操作数符号相同。
20. =赋值,==比较
21. 异或 : 相同为false,不同为true
22.短路与(&&):如果第一个为false,则直接输出false,后边的不会运行。
23. 位运算符: 左移1位相当于*2,右移一位相当于除2取商。
24. 运算符优先级:算术运算符>关系运算符>逻辑运算符>赋值运算符,一般使用()来组织。
逻辑非>逻辑与>逻辑或
25. 自动类型转换:容量小的自动转换为容量大的数据类型。整型常量可以直接赋值给byte、short、char等类型。
26. 当操作比较大的数时,要留意是否有溢出;尽量不要用小写的l去命名,容易和数字1混淆。
27.random(): 返回的是[0,1)之间的随机数。
28. 方法是完成一段特定功能的代码块。重载的条件:形参类型、形参个数、形参顺序不同,只有返回值不同时不能够重载。
29. 递归结构: 定义递归头,递归体。尽量避免使用递归。递归会占用大量的系统堆栈,内存耗用多,在递归调用层次多时速度比循环慢得多。
30. 面向过程与面向对象的的区别:
面向过程:怎么按步骤实现,一步一步,最终完成。用以解决简单问题(比如造车,面向过程考虑的是怎么造车)
面向对象:(车有哪些部件)面对复杂问题,宏观上使用面向对象把握,微观上仍是面向过程。
31. 面向对象的内存分析:java 虚拟机的内存分为三个区域:栈(stack),堆(heap),方法区(method area)(属于堆)
参考代码:
public class SxtStu {
//属性
int id;
String sname;
int age;
Computer comp; //计算机
//方法
void study(){
System.out.println("我在认真学习,使用的是");
}
void play(){
System.out.println("我在玩游戏");
}
//构造方法
SxtStu(){
}
//程序执行入口
public static void main(String[] args) {
SxtStu stu = new SxtStu(); //调用了构造方法Sxtstu
stu.id = 1001;
stu.sname = "杜红伟";
stu.age = 18;
Computer c1 = new Computer();
c1.brand = "联想";
stu.comp = c1;
stu.play();
stu.study();
}
}

32.栈的特点:
(1)栈描述的是方法执行的内存模型,每个方法被调用都会产生一个栈帧(存储局部变量,操作数,方法出口等)。
(2)JVM为每个线程创建一个栈,用以存放该线程执行方法的信息(实际参数,局部变量等)
(3)栈属于线程私有,不能实现线程间的共享
(4)栈的存储特性是“先进后出,后进先出”
(5)栈是由系统自动分配的,速度快,栈是一个连续的内存空间
33. 堆的特点:
(1)堆用于存储创建好的对象和数组(数组也是对象)
(2)JVM只有一个堆,被所有线程共享
(3)堆是一个不连续的内存空间,分配灵活,速度慢
34. 方法区(即静态区)的特点:
(1)JVM只有一个方法区,被所有线程共享
(2)方法区实际也是堆,只是用于存储类,常量相关的信息
(3)用来存放程序中永远是不变或唯一的内容(类信息【Class对象】、静态变量、字符串常量等)
35.构造方法(构造器constructor):用于对象的初始化。要点如下:
(1)通过new关键字调用。
(2)构造器虽然有返回值,但是不能定义返回值类型(返回值的类型肯定是本类),不能在构造器里使用return返回某个值。
(3)如果我们没有定义构造器,则编译器会自动定义一个无参的构造函数,如果已定义则编译器不会自动添加。
(4)构造器的方法必须和类名一致。
36.垃圾回收机制(Garbage Collection)
(1)发现无用的对象
(2)回收无用对象占用的内存空间。
相关算法:(1)引用计数法:引用+1,引用的值为null是-1,缺点是对象之间的循环引用。
(2)引用可达法(根搜索算法):把所有的引用关系做一张图,从根节点开始寻找相对应的引用节点,找到这个节点后继续寻找这个节点的引用节点,当所有的引用节点都找完后,剩余的节点则被认为是没有被引用的节点。
37.分代垃圾回收机制:根据不同的对象的生命周期不一样,将对象分为三种状态:年轻代,年老代,持久代。JVM将堆内存分为Eden,survivor(年轻代)和Tenured/Old(年老代)空间。
38.GC:
(1)Minor GC:用于清理年轻代区域,Eden区满了就会触发一次Minor GC.清理无用对象,将有用的对象复制到“survivor1”,“survivor2”中(这两个区的大小空间一样,同一时刻只有一个在用,一个为空)
(2)Majot GC: 用于清理老年代区域。
(3)Full GC: 用于清理年轻代,老年代,成本较高,会对系统性能产生影响。
38. 垃圾回收过程:
(1)新创建的对象一般会存储在Eden区中
(2)当Eden满了(即达到一定比例)不能创建新对象,则触发垃圾回收(GC),将无用的对象清理掉,然后剩余对象复制到某个survivor中,比如s1,同时清空Eden区
(3)当Eden区再次满了的时候,会将s1中不能清空的对象存到如s2另一个Survivor中,例,同时将Eden区中不能清空的对象也复制到s1中,保证Eden区和s1,均被清空。
(4)重复多次(默认15次)Survivor中没有被清理的对象,则会复制到老年代Old(Tenured)区中
(5)当Old区满了。则会触发一个一次完整的垃圾回收(FullGC),之前新生代的垃圾回收称为(minorGC)。
39. JVM调优:一大部分工作就是针对FullGC的调节。有如下原因可能导致Full GC:
(1).年老代(Tenured)被写满
(2).持久代(Perm)被写满
(3).System.gc()被显式调用(程序只是建议GC启动,至于是否启动,仍要看垃圾回收机制,它不是调用GC)
(4).上一次GC之后Heap的各域分配策略动态变化
40. 在开发过程中容易造成内存泄露的操作
(1)创建大量无用对象。比如在进行大量拼接字符串时,使用的是String,而不是StringBuilder。
(2)静态集合类的使用。比如HashMap、Vector、List等,这些静态变量的生命周期和应用程序一致,所有的对象Object也不能被释放。
(3)各种连接对象(IO流对象,数据库连接对象,网络连接对象)未关闭。这些连接对象属于物理连接,和硬盘或者网络连接,不用的时候一定要关闭。
(4)监听器的使用。在释放对象时,没有删除相应的监听器。
41. 几个要点: (1)程序员是无权调用垃圾回收器的。
(2)程序员可以调用System.gc(),该方法只是通知JVM,建议JVM,而不是真正的运行垃圾回收器,尽量少用,申请启动Full GC,成本高,影响系统性能。
(3)funalize 方法,是java提供给程序员用来释放对象和资源的方法,但是尽量少用。
42. 对象创建过程:(1)分配对象空间,并将对象成员变量初始化为0或者空
(2)执行属性值的显式初始化
(3)执行构造方法
(4)返回对象的地址给相关的变量
43. this. this的本质就是“创建好的对象的地址”,在构造方法中也可以使用this代表“当前对象”。
this 用法: (1)在程序中产生二义性处,应使用this来指明当前对象,普通方法中,this总是指向调用该方法的对象。在构造方 法中this总是指向正要初始化的对象。
(2)使用this关键字调用重载的构造方法,避免相同的初始化代码,但只能在构造方法中用,并且必须位于构造方法 的第一句。
(3)this 不能用于static方法中。
44. static修饰的成员变量和方法,从属于类。普通变量和方法从属于对象。 不能在静态方法里边调非静态方法,但是可以在非静态方法里调用静态方法。(就比如图纸和汽车,你不能拿着图纸就去调汽车的轮子,因为轮子还没有造好,相反,如果已经有了轮子,他必定有图纸,不然它是造不出来的),this代表对象本身,所以this可以用以普通的方法里,但是this不可以调用静态方法和静态成员变量,因为静态成员变量属于类,不属于对象。
45. 静态初始化块。构造方法用于对象的初始化;静态初始化块,用于类的初始化操作!
在静态初始化块中不能直接访问非static成员。当程序中出现静态初始化块以及构造方法时,先执行的是静态初始化块,因为先有类再有对象。
46. java中的参数传递都是“值”传递。因为传对象时多个变量会指向同一个对象,所以当一个变量改变了对象的值,在原来的地方由于指向同一个对象,所以值也会发生改变。
47.包(package): 包名:域名倒着写,再加上模块名。
48.继承:java中类只有单继承,接口有多继承。子类可以继承父类,可以得到父类的全部属性和方法(除了父类的构造方法),但是不见得可以直接访问(比如父类的私有属性和方法)。如果定义一个类没有调用extends,则它的父类是Object。可以使用Ctrl+T键来查看类的层次。
49. 方法的重写(override):(1)“==”:方法名、形参列表相同
(2)“≤”:返回值类型和声明异常类型,子类应该小于等于父类
(3)“≥”:访问权限,子类大于等于父类
50. Object类:它是所有java类的根基类,也就是所有的java对象都拥有Object类的属性和方法。
51. “==”: 代表双方是否相同。如果是基本类型则表示值相等,如果是引用类型则表示地址相等即是同一个对象。
“equals()方法”: 判断对象内容相等
52. 关于继承树的追溯: super()永远位于构造器的第一句,写不写都是这样的。构造方法的调用顺序如下:构造方法的第一句总是super()来调用父类对应的构造方法,所以,先向上追溯到Object,然后再依次向下执行类的初始化块和构造方法,直到当前子类为止,静态初始化块的调用顺序也是如此。
53. 封装:提高代码的安全性,提高代码的复用性,高内聚(封装细节,便于修改内部代码,提高系统的可维护性),低耦合(简化外部调用,便于调用者使用,便于扩展和协作)。
54.封装实现的访问控制符:
private:同一个类,(只有自己类才可以访问)
default:同一个类,同一个包,(只有同一个包的类才能访问)
protected:同一个类,同一个包,同一个子类,(可以被同一个包的类和其他包的子类访问)
public: 同一个类,同一个包,同一个子类,所有类(可以被该项目中的所有包中的所有类访问)
55. 关于封装的使用细节:类的属性处理:
(1)一般使用private访问权限
(2)提供相应的get/set方法来访问相关的属性,这些方法通常使用public修饰,以提供对属性的赋值与读取操作(boolean变量的get方法是is开头)
(3)一些只用于本类的辅助性方法使用private来修饰,其他类调用的方法一般使用public修饰。
56.多态(polymorphism):多态指的是同一个方法调用,由于不同的对象有不同的行为,而在现实生活中,同一个方法,具体实现会完全不同。
多态的要点:
(1)多态是方法的多态,不是属性的多态(多态与属性无关)
(2)多态存在要有三个必要条件:继承、方法重写、父类引用指向子类对象
(3)父类引用指向子类对象后,用该父类引用调用子类重写的方法,此时多态就出现了。
57.final 关键字: 可以修饰变量,被修饰后变量不可改变(变成了常量);可以修饰方法,被修饰的方法不可被子类重写,但可以被重载;可以修饰类,被修饰的类不能被继承。
58.数组:
(1)数组也是对象,数组中的每一个元素可以看做是这个对象的成员变量,数组是相同类型数据的有序集合。
(2)每个元素可以通过一个索引(下标)来访问他们。
(3)长度是确定的,一旦创建大小不可改变。
(4)数组类型可以是任何数据类型。
(5)声明一个数组时数组并没有真正的创建,只有在实例化数组对象时,JVM才分配空间
(6)数组的初始化方法有三种:静态初始化,动态初始化,默认初始化
(7)数组的遍历:通过下标来遍历
(8)foreach循环:用于读取数组元素的值,不能修改数组元素的值.
59. 抽象方法、抽象类:
(1)有抽象方法的类只能定义为抽象类
(2)抽象类不能被实例化,即不能用new来实例化抽象类,抽象类只能被继承。
(3)抽象方法必须被子类实现。
(4)抽象类设计的意义就是给子类提供一个统一的,规范的模板,然后让子类去实现相应的抽象方法,必须的!
(5)抽象类可以包含属性、方法,构造方法,但是构造方法不能用new来实例,只能用来被子类调用。
60.接口:
(1)接口中所有的方法都是抽象方法。
(2)接口只定义规范,就像是契约,就像是法律,我们需要遵守
(3)接口可以多继承,子接口可以继承多个父接口,但是类只能单继承
(4)访问修饰符只能是public或者默认,接口中的属性只能是常量,总是public static final 修饰,不写也是。接口中的方法只能是public abstract ,不写也是。
(5)子类通过implements来实现接口中的规范。
(6) 接口不能创建实例,但是可用于声明引用变量类型。
(7)一个类实现了接口,必须实现接口中所有的方法,并且这些方法只能是public的。
(9)区别: 普通类:具体实现
抽象类:具体实现,规范(抽象方法)
接口:规范
61.内部类:成员内部类(非静态内部类,静态内部类)、匿名内部类、局部内部类(基本不用)
(1)非静态内部类(外部类里使用非静态内部类和平时使用其他类没有什么区别)
a: 非静态内部类必须寄存于一个外部类对象里,因此如果有一个非静态内部类对象那么一定存在对象的外部类对象。非静态内部类对象单独属于外部类的某个对象。
b:非静态内部类可以直接访问外部类的成员,但是外部类不能直接访问非静态内部类成员。所以内部类可以提供一个良好的封装,我能用外部类,但是你不能用我。
c: 非静态内部类不能有静态方法,静态属性和静态初始化块
d:关于成员变量的访问格式: 访问内部类里方法的局部变量:变量名
访问内部类属性:this.变量名
访问外部类属性:外部类名.this.变量名
(2)静态内部类:(可看作是外部类的一个静态成员),不需要依托外部类对象,故静态内部类的实例方法不能直接访问外部类的实例方法,通过new 外部类名.内部类名() 来创建内部类对象。
(3)匿名内部类:(适合只需要使用一次的类,如键盘监听操作)
语法:new 父类构造器(实参列表) /实现接口(){ 匿名内部类类体 }
62. String (不可变字符序列):比较字符串一般使用equals()方法。
String 类常用的方法:
(1).CharAt(index) // 提取下标为index的字符
(2) .length() // 字符串长度
(3) .equals(str) //比较两个字符串是否相等
(4) .equalsIgnoreCase(str) //比较两个字符串是否相等(忽略大小写)
(5).indexOf(str) //判断字符串中是否含有str字符串
(6).replace('a ','b ') //将字符串中的a字符替换成b字符
(7).startsWith(str)、.endWith(str) //判断字符串的是否以str开头,或者以str结尾
(8).substring(int)、.substring(int,int) //提取子字符串
(9).toLowerCase() //转小写
(10). toUpperCase() //转大写
(11) . trim() //去除首尾空格,中间空格不能去除
63. 数组拷贝: arraycopy(数组1,数组1起始下标,数组2,数组2起始下标,长度)
删除数组中指定索引位置的某个元素 :arraycopy(s, index+1, s, index, s.length-index-1)
64. Arrays类:
(1)Arrays.toString(a); //输出数组a的内容
(2)Arrays.sort(a); //排序
(3)Arrays.binarySearch(a,key); //查找某值key是否在数组a中
65.二维数组:即数组的元素是数组
66. 二分法查找:前提条件:数组有序
67.包装类: 八种基本数据类型的首字母大写。除了char-->Character,int-->Integer。
包装类的作用是:实现包装类---基本数据类型---字符串三者之间的相互转换
68. 自动装箱、拆箱:
(1)自动装箱:基本数据类型(假)自动转换成对象。
(2)拆箱:对象(假)自动转换成基本数据类型。
69. 字符串的拼接使用StringBuilder的append() 方法. AbstractStringBuilder抽象类的两个子类是:StringBuilder和StringBuffer。AbstractStringBuilder的源码中,内部也是一个字符数组,但这个字符数组没有用final修饰,随时可以修改。
(1)StringBuilder类:线程不安全,效率高。建议使用此类。常用的方法有:public StringBuilder append(…)方法、delete(int start,int end)、deleteCharAt(int index)、 insert(…)、 reverse() 、toString() 等。
(2)StringBuffer类:线程安全,效率低。
70. DateFormat类:把时间对象转换为指定格式的字符串(.format()方法),它是一个抽象类,一般使用它的子类SimpleDateFormat类来实现。把字符串按照“格式字符串指定的格式” 转换成相应的时间对象(.parse()方法),//注意格式一定要匹配。 利用D 获得本时间对象是所处年份的第几天。具体参考格式化字符表。
71. Calendar类:是一个抽象类,为我们提供了日期计算的相关功能,GregorianCalendar是它的一个具体子类。
72.File 类:
(1)访问属性的方法:exist()、isDirectory()、isFile()、lastModified()、length()、getName()、getPath()
(2)创建空文件或目录:createNewFile()、delete()、mkdir()、mkdirs()
73. 异常机制本质就是当程序出现错误时,程序安全退出的机制。
Java采用面向对象的方式来处理异常。
a. 其处理过程:
(1)抛出异常:在执行一个方法时,如果发生异常,则这个方法生成代表该异常的一个对象,停止当前执行路径,并把异常对象提交给JRE。
(2)捕获异常:JRE得到该异常后,寻找相应的代码来处理这个异常。JRE在方法的调用栈中查找,从生成异常的方法开始回溯,直到找到相应的处理异常的代码为止。
b. 分类: Throwable:Error(Unchecked Exception)、
Exception(Checked Exception 已检查异常 、Runtime Exception 运行时异常(Unchecked Exception))
c. Runtime Exception 运行时异常需要我们去处理。
d . 异常通常在高层来处理,层层外抛(throw)。
74.容器(也叫集合(Collection))
(1)泛型:泛型E像一个占位符一样表示“未知的某个数据类型”,我们在真正调用的时候传入这个“数据类型”。
(2)Collection
a. Collection接口的两个子接口是List、Set接口。故所有List、Set的实现类都有下面的方法。
b.Collection接口中定义的方法
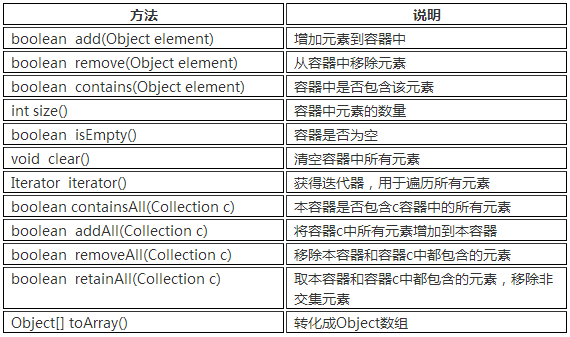
(3)List
a. List是有序、可重复的容器。
b.除了Collection接口中的方法,List多了一些跟顺序(索引)有关的方法
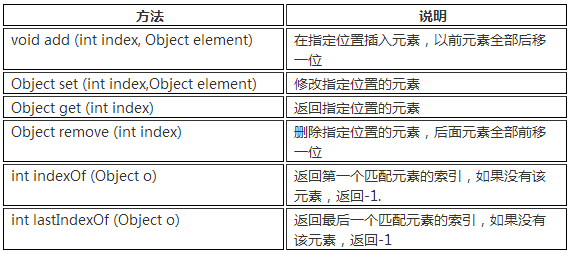
c. List接口常用的实现类有3个:ArrayList、LinkedList和Vector。
aa. ArrayList底层是使用Object数组来存储元素数据。 特点:查询效率高,增删效率低,线程不安全。我们一般使用它。
bb. 数组的扩容:通过定义新的更大的数组,将旧数组中的内容拷贝到新数组,来实现扩容。(length+(length>>1))
cc. LinkedList底层用双向链表实现的存储。特点:查询效率低,增删效率高,线程不安全。
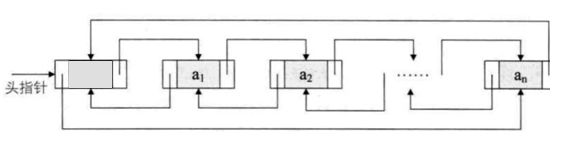
dd. Vector底层是用数组实现的List,相关的方法都加了同步检查,因此“线程安全,效率低”。
d. 如何选用ArrayList、LinkedList、Vector?
1. 需要线程安全时,用Vector。
2. 不存在线程安全问题时,并且查找较多用ArrayList(一般使用它)。
3. 不存在线程安全问题时,增加或删除元素较多用LinkedList。
(4) Map接口
a. Map就是用来存储“键(key)-值(value) 对”的。 Map类中存储的“键值对”通过键来标识,所以“键对象”不能重复。
b. Map接口中常用的方法
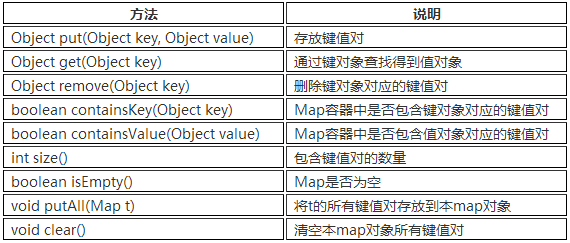
c. Map 接口的实现类有HashMap、TreeMap、HashTable、Properties等。
c.a. HashMap
aa. HashMap采用哈希算法实现,是Map接口最常用的实现类。 由于底层采用了哈希表存储数据,我们要求键不能重复,如果发生重复,新的键值对会替换旧的键值对。
bb. 哈希表的本质就是“数组+链表”。结合了数组和链表的优点。(即查询快,增删效率也高)
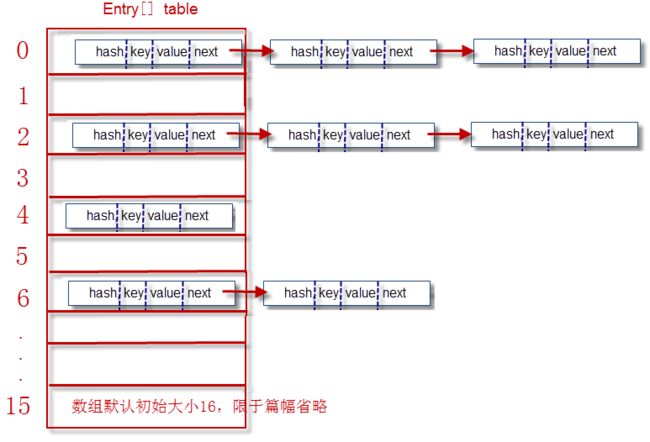
cc. Entry[] table 就是HashMap的核心数组结构,我们也称之为“位桶数组”.
dd. 每一个Entry对象就是一个单向链表结构.
ee. 存储数据过程put(key,value)
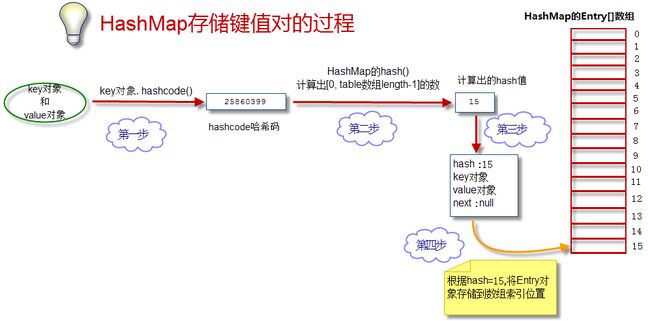
总结如上过程:
当添加一个元素(key-value)时,首先计算key的hash值( hash值 = hashcode%数组长度 或者 hash值 = hashcode&(数组长度-1)。 ),以此确定插入数组中的位置,但是可能存在同一hash值的元素已经被放在数组同一位置了,这时就添加到同一hash值的元素的后面,他们在数组的同一位置,就形成了链表,同一个链表上的Hash值是相同的,所以说数组存放的是链表。 JDK8中,当链表长度大于8时,链表就转换为红黑树,这样又大大提高了查找的效率。
具体过程:
我们的目的是将”key-value两个对象”成对存放到HashMap的Entry[]数组中。参见以下步骤:
(1) 获得key对象的hashcode
首先调用key对象的hashcode()方法,获得hashcode。
(2) 根据hashcode计算出hash值(要求在[0, 数组长度-1]区间)
hashcode是一个整数,我们需要将它转化成[0, 数组长度-1]的范围。我们要求转化后的hash值尽量均匀地分布在[0,数组长度-1]这个区间,减少“hash冲突”
i. 一种极端简单和低下的算法是:
hash值 = hashcode/hashcode;
也就是说,hash值总是1。意味着,键值对对象都会存储到数组索引1位置,这样就形成一个非常长的链表。相当于每存储一个对象都会发生“hash冲突”,HashMap也退化成了一个“链表”。
ii. 一种简单和常用的算法是(相除取余算法):
hash值 = hashcode%数组长度
这种算法可以让hash值均匀的分布在[0,数组长度-1]的区间。 早期的HashTable就是采用这种算法。但是,这种算法由于使用了“除法”,效率低下。JDK后来改进了算法。首先约定数组长度必须为2的整数幂,这样采用位运算即可实现取余的效果:hash值 = hashcode&(数组长度-1)。
(3) 生成Entry对象
如上所述,一个Entry对象包含4部分:key对象、value对象、hash值、指向下一个Entry对象的引用。我们现在算出了hash值。下一个Entry对象的引用为null。
(4) 将Entry对象放到table数组中 (table数组的长度一般定义为2的整数次幂)
如果本Entry对象对应的数组索引位置还没有放Entry对象,则直接将Entry对象存储进数组;如果对应索引位置已经有Entry对象,则将已有Entry对象的next指向本Entry对象,形成链表。
ff. 取数据过程get(key) (hashcode--->hash值--->数组的位置--->equals())
我们需要通过key对象获得“键值对”对象,进而返回value对象。明白了存储数据过程,取数据就比较简单了,参见以下步骤:
(1) 获得key的hashcode,通过hash()散列算法得到hash值,进而定位到数组的位置。
(2) 在链表上挨个比较key对象。 调用equals()方法,将key对象和链表上所有节点的key对象进行比较,直到碰到返回true的节点对象为止。
(3) 返回equals()为true的节点对象的value对象。
明白了存取数据的过程,我们再来看一下hashcode()和equals方法的关系:
Java中规定,两个内容相同(equals()为true)的对象必须具有相等的hashCode。因为如果equals()为true而两个对象的hashcode不同;那在整个存储过程中就发生了悖论。
gg. 扩容
HashMap的位桶数组,初始大小为16。实际使用时,显然大小是可变的。如果位桶数组中的元素达到(0.75*数组 length), 就重新调整数组大小变为原来2倍大小。扩容的本质是定义新的更大的数组,并将旧数组内容挨个拷贝到新数组中。
c.b. HashMap与HashTable的区别
1. HashMap: 线程不安全,效率高。允许key或value为null。
2. HashTable: 线程安全,效率低。不允许key或value为null。
c.c. TreeMap和HashMap实现了同样的接口Map,TreeMap会根据key递增方式排序。如果是自己定义的类,则使用compareTo 方法进行自定义的值排序。
Comparable接口中的CompareTo方法: 负数:小于; 0:等于; 正数:大于;(如果是一个值小于另一个值,则return -1;如果一个值大于另一个值,则return 1; 如果一个值等于另一个值,则return 0;)
(5) Set接口
a. Set容器特点:无序、不可重复。Set中也只能放入一个null元素,不能多个。
b. Set常用的实现类有:HashSet、TreeSet等,我们一般使用HashSet。
c. HashSet是采用哈希算法实现,底层实际是用HashMap实现的(HashSet本质就是一个简化版的HashMap),因此,查询效率和增删效率都比较高。
d. 我们发现里面有个map属性,这就是HashSet的核心秘密。我们再看add()方法,发现增加一个元素说白了就是在map中增加一个键值对,键对象就是这个元素,值对象是名为PRESENT的Object对象。说白了,就是“往set中加入元素,本质就是把这个元素作为key加入到了内部的map中”。由于map中key都是不可重复的,因此,Set天然具 有“不可重复”的特性。
(6) 迭代器
a. 迭代器为我们提供了统一的遍历容器的方式
b. 遍历集合的方法总结
遍历List方法一:普通for循环
| 1 2 3 4 |
|
遍历List方法二:增强for循环(使用泛型!)
| 1 2 3 |
|
遍历List方法三:使用Iterator迭代器(1)
| 1 2 3 4 |
|
遍历List方法四:使用Iterator迭代器(2)
| 1 2 3 4 5 6 |
|
遍历Set方法一:增强for循环
| 1 2 3 |
|
遍历Set方法二:使用Iterator迭代器
| 1 2 3 4 |
|
遍历Map方法一:根据key获取value
| 1 2 3 4 5 |
|
遍历Map方法二:使用entrySet
| 1 2 3 4 |
|
(7) 容器总结
a. Collection 表示一组对象,它是集中、收集的意思,就是把一些数据收集起来。
b. Collection接口的两个子接口:
1) List中的元素有顺序,可重复。常用的实现类有ArrayList、LinkedList和 vector。
Ø ArrayList特点:查询效率高,增删效率低,线程不安全。
Ø LinkedList特点:查询效率低,增删效率高,线程不安全。
Ø vector特点:线程安全,效率低,其它特征类似于ArrayList。
2) Set中的元素没有顺序,不可重复。常用的实现类有HashSet和TreeSet。
Ø HashSet特点:采用哈希算法实现,查询效率和增删效率都比较高。
Ø TreeSet特点:内部需要对存储的元素进行排序。因此,我们对应的类需要实现Comparable接口。这样,才能根 据compareTo()方法比较对象之间的大小,才能进行内部排序。
c. 实现Map接口的类用来存储键(key)-值(value) 对。Map 接口的实现类有HashMap和TreeMap等。Map类中存储的键-值对 通过键来标识,所以键值不能重复。
d. Iterator对象称作迭代器,用以方便的实现对容器内元素的遍历操作。
e. 类 java.util.Collections 提供了对Set、List、Map操作的工具方法。
f. 如下情况,可能需要我们重写equals/hashCode方法:
1) 要将我们自定义的对象放入HashSet中处理。
2) 要将我们自定义的对象作为HashMap的key处理。
3) 放入Collection容器中的自定义对象后,可能会调用remove、contains等方法时。
g. JDK1.5以后增加了泛型。泛型的好处:
1) 向集合添加数据时保证数据安全。
2) 遍历集合元素时不需要强制转换。
h. 使用容器存储表格数据
* 可以是每一行数据使用一个map 或者数组 或者 javaBean
* 整个表格使用一个List 或者map
* ORM思想:对象映射关系
* 总体思想:使用map存储表的每一行数据,然后用list存储整张表 ,然后遍历整张表即可。
思路1:
//使用map存储表中的第一行数据
Map row1 = new HashMap<>();
row1.put("id",1001);
.............
//使用List存储整张表
List> table1 = new ArrayList<>();
table1.add(row1);
..............
//遍历整张表
for (Map row : table1){
Set keyset = row.keySet();
for (String key:keyset){
System.out.print(key+":"+row.get(key)+"\t");
}
system.out.println();
}
思路2:
//使用javaBean存储表数据
static class User { //属性,set/get方法,构造器}
User user1 = new User(1001,"zhangsan",20000,"2020-7-1");
.............
//整张表放在List中
List list = new ArrayList<>();
list.add(user1);
.............
//或者将整张表放在Map或者Set中
Map map = new HashMap<>();
map.put(1001,user1);
.............
Set keyset = map.keySet();
for (Integer key:keyset){
System.out.println(key+"----"+map.get(key));
}
75. IO流技术
(1)Java中IO流类的体系
a. InputStream/OutputStream 字节流的抽象类。
b. Reader/Writer 字符流的抽象类。
c. FileInputStream/FileOutputStream 节点流:以字节为单位直接操作“文件”。
d. ByteArrayInputStream/ByteArrayOutputStream 节点流:以字节为单位直接操作“字节数组对象”。
e. ObjectInputStream/ObjectOutputStream 处理流:以字节为单位直接操作“对象”。
f. DataInputStream/DataOutputStream 处理流:以字节为单位直接操作“基本数据类型与字符串类型”。
g. FileReader/FileWriter 节点流:以字符为单位直接操作“文本文件”(注意:只能读写文本文件)。
h. BufferedReader/BufferedWriter 处理流:将Reader/Writer对象进行包装,增加缓存功能,提高读写效率。
i. BufferedInputStream/BufferedOutputStream 处理流:将InputStream/OutputStream对象进行包装,增加缓存功能,提 高 读写效率。
j. InputStreamReader/OutputStreamWriter 处理流:将字节流对象转化成字符流对象。
k. PrintStream 处理流:将OutputStream进行包装,可以方便地输出字符,更加灵活
(2)相对路径与绝对路径 : * 存在盘符: 绝对路径
* 不存在盘符: 相对路径 相对于当前目录。 user.dir
* 对不存在的路径和文件也会打印出来,
(因为File对象可以构建一个文件,也可以构建一个不存在的路径)
(3)名称或路径 : * getName(): 名称
* getPath(): 构建时是什么路径,就返回什么路径 相对返相对 绝对返绝对
* getAbsolutePath(): 绝对路径
* getParent(): 构建时的上路径, 如果上路径为空,则返回null
(4)文件状态: * 不存在 : exists
* 存在 : * 文件: isFile
* 文件夹:isDirectory
(5)* length():返回的是文件的字节数
* createNewFile();不存在才创建,存在返回false
* delete() :删除
* 补充 :con com 等是操纵系统的设备名,故不能使用这些单词作为名称
(6)创建目录 : * mkdir() :确保上级目录存在,不存在创建失败
* mkdirs() :上级目录可以不存在,不存在时会创建
(7)列出下一级名称 : * list() :列出下一级名称
* listFiles():列出下级File对象
* 列出所有的盘符:listRoots()
(8)文件编码: 编码:字符---->字节
解码:字节---->字符
乱码原因:a. 字节数不够 b.字符集不统一
(9)IO的四大抽象类:
a. InputStream:字节输入流的父类,数据单位为字节。int read();void close();
b. OutputStream:字节输出流的父类,数据单位为字节。void write(int); void flush();void close();
c. Reader:字符输入流的父类,数据单位为字符。int read(); void close();
d.Writer: 字符输出流的父类,数据单位为字符。void write(String); void flush(); void close();
(10) FileInputStream文件字节输入流 * * 四个步骤:分段读取 * 1.创建源 * 2.选择流 * 3.操作 * 4.释放
//1.创建源
File src = new File("E:/abc.txt");
//2. 选择流
InputStream is = new FileInputStream(src);
//3. 操作(分段读取)
byte[] flush = new byte[1024*10]; //缓冲容器,每3个字节一读取,也可以是1K一读取,或者1兆一读取
int len = -1 ; //接收长度
while((len = is.read(flush))!= -1){
//字节数组--->字符串(解码)
String str = new String(flush,0,len); //len拿的是文件中的实际大小
System.out.println(str);
}
//4.释放资源
if (null != is){
is.close();
}(11)FileOutputStream文件字节输出流 * * 四个步骤:分段读取 * 1.创建源 * 2.选择流 * 3.操作(写出内容) * 4.释放资源
//1.创建源
File dest = new File("E:/dest.txt"); //该文件不存在,但是可以创建
//2. 选择流
OutputStream os = null;
try {
//os = new FileOutputStream(dest); //将msg的内容写入到dest文件中
// os = new FileOutputStream(dest,true); //将msg的内容写入到dest文件中,执行多次以后完成追加
os = new FileOutputStream(dest,false); //将msg的内容写入到dest文件中,执行多次以后对之前写入的内容进行覆盖
//3. 操作(写出)
String msg = "learn IO knowledge\r\n"; // 换行
byte[] datas = msg.getBytes(); //字符串--->字节数组(编码)
os.write(datas,0,datas.length);
os.flush();
// 4. 释放资源
if (null != os){
os.close();
}(12) 文件拷贝 : 文件字节输入,输出。
/**
* 文件拷贝方法
* 思考:利用递归 制作文件夹的拷贝
*/
public static void copy(String srcPath, String destPath) {
//1.创建源
File src = new File(srcPath); //源头
File dest = new File(destPath); //目的地
//2. 选择流
InputStream is = null;
OutputStream os = null;
try {
is = new FileInputStream(src);
os = new FileOutputStream(dest); //将msg的内容写入到dest文件中,执行多次以后对之前写入的内容进行覆盖
//3. 操作(分段读取)
byte[] flush = new byte[1024]; //缓冲容器,每3个字节一读取,也可以是1K一读取,或者1兆一读取
int len = -1; //接收长度
while ((len = is.read(flush)) != -1) {
os.write(flush, 0, flush.length); //分段写出
}
os.flush();
} catch (
FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
// 4. 释放资源 分别关闭 先打开的后关闭
if (null != os) {
try {
os.close();
} catch (IOException e) {
e.printStackTrace();
}
try {
if (null != is) {
is.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}(13)FileReader 文件字符输入流
//1.创建源
File src = new File("E:/dest.txt");
//2. 选择流
Reader reader = new FileReader(src);
//3. 操作(分段读取)
char[] flush = new char[1024];
int len = -1;
while((len = reader.read(flush))!= -1){
//字节数组--->字符串
String str = new String(flush,0,len); //len拿的是文件中的实际大小
System.out.println(str);
// 4. 释放资源
if (null != reader){
reader.close();
}(14)FileWriter文件字符输出流
//1.创建源
File dest = new File("E:/dest1.txt"); //该文件不存在,但是可以创建
//2. 选择流
Writer writer = new FileWriter(dest); //将msg的内容写入到dest文件中,执行多次以后对之前写入的内容进行覆盖
//3. 操作(写出)
//写法1
// String msg = "learn IO knowledge 我是杜杜\r\n"; // 换行
// char[] datas = msg.toCharArray(); //字符串--->字节数组
// writer.write(datas,0,datas.length);
//写法2
// String msg = "learn IO knowledge 我是杜杜杜\r\n"; // 换行
// writer.write(msg); //write实现多次写入时只需多写几个Write即可。
//写法3
writer.append("learn IO knowledge ").append(" 我是杜杜杜杜");
writer.flush();
// 4. 释放资源
if (null != writer) {
writer.close();
}
(15)字节数组流 ByteArrayInputStream / ByteArrayOutputStream
a. 注意:字节数组不要过大,同时可以不用处理释放资源操作。
b.代码不同之处:
字节数组输入流:
//1.创建源 byte[] src = "talk is cheap show me the code ".getBytes();//2. 选择流 InputStream is = new ByteArrayInputStream(src);
字节数组输出流:
//1.创建源 byte[] dest = null; //2. 选择流(新增方法) ByteArrayOutputStream baos = null; baos = new ByteArrayOutputStream();/获取数据 dest = baos.toByteArray(); System.out.println(dest.length+"-->"+new String(dest,0,baos.size()));
(16)对接流的小例子
/**
* 1. 图片读取到字节数组中
* 2. 字节数组写出到文件
*/
public class IOTest9 {
public static void main(String[] args) {
//图片转成字节数组
byte[] datas = fileToByteArray("p.png");
System.out.println(datas.length);
byteArrayToFile(datas,"p-byte.png");
}
/**
* 1. 图片读取到字节数组
* (1) 图片到程序 FileInputStream
* (2) 程序到字节数组 ByteArrayOutputStream
*/
public static byte[] fileToByteArray(String filePath){
//1.创建源与目的地
File src = new File(filePath);
byte[] dest = null;
//2. 选择流
InputStream is = null;
ByteArrayOutputStream baos = null;
try {
is = new FileInputStream(src);
baos = new ByteArrayOutputStream();
//3. 操作(分段读取)
byte[] flush = new byte[1024*10]; //缓冲容器,每3个字节一读取,也可以是1K一读取,或者1兆一读取
int len = -1 ; //接收长度
while((len = is.read(flush))!= -1){
baos.write(flush,0,len); //写出到字节数组中
}
baos.flush();
return baos.toByteArray();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally {
//4.释放资源
try {
if (null != is){
is.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
return null;
}
/**
* 2. 字节数组写出到图片
* (1)字节数组读取到程序 ByteArrayInputStream
* (2)程序到文件 FileOutputStream
*/
public static void byteArrayToFile(byte[] src, String filePath){
//1.创建源
File dest = new File(filePath);
//2. 选择流
InputStream is = null;
OutputStream os = null;
try {
is = new ByteArrayInputStream(src);
os = new FileOutputStream(dest);
//3. 操作(分段读取)
byte[] flush = new byte[5]; //缓冲容器,每3个字节一读取,也可以是1K一读取,或者1兆一读取
int len = -1 ; //接收长度
while((len = is.read(flush))!= -1){
os.write(flush,0,len); //写出到文件
}
os.flush();
}catch (IOException e) {
e.printStackTrace();
}finally {
//4.释放资源
if (null != os){
try {
os.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
(17)装饰器设计模式
* 1. 抽象组件:需要装饰的抽象对象(接口或抽象父类) -------- InputStream
* 2. 具体组件:需要装饰的对象 -------- FileInputStream,ByteArrayInputStream这些InputStream类是可以被装饰者包起来的具体组件
* 3. 抽象装饰类:包含了对抽象组件的引用以及装饰者共有的方法 ------- FilterInputStream
* 4. 具体装饰类:被装饰的对象 -------- BufferedInputStream,DataInputStream,ObjectInputStream
*
* 类之间关系
* 具体装饰类(Milk,Suger)继承抽象装饰类(Decorate),
* 具体组件(Coffee)和抽象装饰类(Decorate)实现抽象组件接口(Drink)。(18)字节缓冲流 BufferedInputStream & BufferedOutputStream
用法示例:
InputStream is = new BufferedInputStream(new FileInputStream(src));
OutputStream os = new BufferedOutputStream(new FileOutputStream(dest,false)); (19)字符缓冲流 BufferRead & BufferedWriter
用法示例:
BufferedReader reader = new BufferedReader(new FileReader(src)); (reader.readLine()---逐行读取)
BufferedWriter writer = new BufferedWriter(new FileWriter(dest)); (writer.newLine()----换行)
(20) 转换流 InputStreamReader & InputStreamWriter
作用:a. 将字节流转换成字符流,即以字符流的形式操作字节流(纯文本的)
b. 指定字符集
用法示例:
BufferedReader reader = new BufferedReader(new InputStreamReader(System.in)); //操作System.in和System.out
BufferedWriter writer = new BufferedWriter(new OutputStreamWriter(System.out));
BufferedReader reader = new BufferedReader(new InputStreamReader(new URL("http://www.baidu.com").openStream(),"UTF-8"));
BufferedWriter writer = new BufferedWriter(new OutputStreamWriter(new FileOutputStream("baidu.html"),"UTF-8")); //内容是什么字符集,就指定怎么样的字符集(21)数据流 DataInputStream & DataOutputStream
注意: * 1. 写出后读取
* 2. 读取的顺序与写出保持一致
用法示例:
public static void main(String[] args) throws IOException {
//写出
ByteArrayOutputStream baos = new ByteArrayOutputStream();
DataOutputStream dos = new DataOutputStream(new BufferedOutputStream(baos));
//操作数据类型 + 数据
dos.writeUTF("杜肚肚");
dos.writeInt(18);
dos.writeBoolean(false);
dos.writeChar('d');
dos.flush();
byte[] datas = baos.toByteArray();
System.out.println(datas.length);
//读取
DataInputStream dis = new DataInputStream(new BufferedInputStream(new ByteArrayInputStream(datas)));
//顺序与写出顺序一致
String msg = dis.readUTF();
int age = dis.readInt();
Boolean flag = dis.readBoolean();
char ch = dis.readChar();
System.out.println(flag);
}(22)对象流 ObjectOutputStream & ObjectInputStream
注意:* 1. 写出后读取 (写出到文件中)(持久化)
* 2. 读取的顺序与写出保持一致
* 3. 不是所有的对象都可以序列化,Serializable
public class ObjectTest {
public static void main(String[] args) throws IOException, ClassNotFoundException {
//写出 ---> 对象的序列化
ByteArrayOutputStream baos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(new BufferedOutputStream(baos));
//序列化到文件中
//ObjectOutputStream oos = new ObjectOutputStream(new BufferedOutputStream(new FileOutputStream("obj.ser")));
//操作数据类型 + 数据
oos.writeUTF("杜肚肚");
oos.writeInt(18);
oos.writeBoolean(false);
oos.writeChar('d');
//加入对象
oos.writeObject("嘟嘟嘟嘟嘟");
oos.writeObject(new Date());
Employee1 emp = new Employee1("肚肚",1);
oos.writeObject(emp); //如果不实现Serializable方法,则emp不能够序列化,因为没有继承Serializable
oos.flush();
//关闭流
//oos.close();
byte[] datas = baos.toByteArray();
System.out.println(datas.length);
//读取 ---> 反序列化
ObjectInputStream ois = new ObjectInputStream(new BufferedInputStream(new ByteArrayInputStream(datas)));
//从文件中读取,发序列化
//ObjectInputStream ois = new ObjectInputStream(new BufferedInputStream(new FileInputStream("obj.ser")));
//顺序与写出顺序一致
String msg = ois.readUTF();
int age = ois.readInt();
Boolean flag = ois.readBoolean();
char ch = ois.readChar();
System.out.println(flag);
//对象的数据还原
Object str = ois.readObject();
Object date = ois.readObject();
Object employee = ois.readObject();
if(str instanceof String){ //避免类型转换错误
String strObj = (String)str;
System.out.println(strObj);
}
if(date instanceof Date){
Date dateObj = (Date)date;
System.out.println(dateObj);
}
if(employee instanceof Employee1){
Employee1 employeeObj = (Employee1) employee;
System.out.println(employeeObj.getName()+"--->"+employeeObj.getSalary());
}
//关闭流
//ois.close();
}
}
//javabean 封装数据
class Employee implements java.io.Serializable{
private transient String name; //transient的作用是该数据不需要序列化,在打印时显示为null
private double salary;
public Employee() {
}
public Employee(String name, double salary) {
this.name = name;
this.salary = salary;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getSalary() {
return salary;
}
public void setSalary(double salary) {
this.salary = salary;
}
}
(23)打印流 PrintStream & PrintWriter
public static void main(String[] args) throws FileNotFoundException {
//打印流 System.out
PrintStream ps = System.out; //简化了System.out
ps.println("打印流");
ps.println(true);
ps = new PrintStream(new BufferedOutputStream(new FileOutputStream("print.txt")),true); //true表示自动刷新
//PrintWriter
//PrintWriter pw = new PrintStream(new BufferedOutputStream(new FileOutputStream("print.txt")),true); //true表示自动刷新
ps.println("打印流");
ps.println(true);
ps.close();
//PrintWriter
//pw.println("打印流");
//pw.println(true);
//pw.close();
//pw.flush(); //刷新后print.txt显示内容,或者在PrintStream中加入true,即为自动刷新
//System.out默认输出到控制台,可以重定向输出端,输出到文件里
System.setOut(ps);
System.out.println("change"); //将change输出到print.txt中,而不是在控制台
//重定向回控制台
System.setOut(new PrintStream(new BufferedOutputStream(new FileOutputStream(FileDescriptor.out)),true)); //标准的输入输出端
System.out.println("back");
}(24)随机流:RandomAccessFile 合并流:SequenceInputStream
public class SplitFile {
//源头
private File src;
//目的地(文件夹)
private String destDir;
//所有文件分割后的文件存储路径
private List destPaths;
//每块大小
private int blockSize;
//块数:多少块
private int size;
public SplitFile(String srcPath, String desrDir) {
this(srcPath, desrDir, 1024);
}
public SplitFile(String srcPath, String destDir, int blockSize) {
this.src = new File(srcPath);
this.destDir = destDir;
this.blockSize = blockSize;
this.destPaths = new ArrayList();
//初始化
init();
}
//初始化
private void init() {
//总长度
long len = this.src.length();
//块数:多少块
this.size = (int) (Math.ceil(len * 1.0 / blockSize));
//路径
for (int i = 0; i < size; i++) {
this.destPaths.add(this.destDir + "/" + i + "-" + this.src.getName());
}
}
/**
* 分割
* 1. 计算每一块的起始位置及大小
* 2. 分割
*/
public void split() throws IOException {
//总长度
long len = src.length();
//起始位置和实际大小
int beginPos = 0;
int actualSize = (int) (blockSize > len ? len : blockSize);
for (int i = 0; i < size; i++) {
beginPos = i * blockSize;
if (i == size - 1) { //最后一块
actualSize = (int) len;
} else {//其他
actualSize = blockSize;
len -= actualSize; //剩余量
}
splitDetail(i, beginPos, actualSize);
}
}
/**
* 第i块的起始位置和实际长度
*
* @throws IOException
*/
private void splitDetail(int i, int beginPos, int actualSize) throws IOException {
RandomAccessFile raf = new RandomAccessFile(this.src, "r");
RandomAccessFile raf2 = new RandomAccessFile(this.destPaths.get(i), "rw"); //第几个
//随机读取
raf.seek(beginPos);
//读取
byte[] flush = new byte[1024];
int len = -1; //接收长度
while ((len = raf.read(flush)) != -1) {
if (actualSize > len) { //如果读取的内容长度小于实际大小,则获取本次读取的所有内容
raf2.write(flush, 0, len);
actualSize -= len; //当前的实际大小为读取过后剩余的长度
} else {
raf2.write(flush, 0, actualSize);
break;
}
}
raf2.close();
raf.close();
}
/**
* 文件的合并
*/
public void merge(String destPath) throws IOException {
//输出流
OutputStream os = new BufferedOutputStream(new FileOutputStream(destPath, true)); //一个写出流
Vector vi = new Vector();
SequenceInputStream sis = null;
//输入流
for (int i = 0; i < size; i++) {
vi.add(new BufferedInputStream(new FileInputStream(destPaths.get(i)))); //多个输入流放入到容器里
}
sis = new SequenceInputStream(vi.elements()); //序列流
//拷贝
//3. 操作(分段读取)
byte[] flush = new byte[1024]; //缓冲容器,每3个字节一读取,也可以是1K一读取,或者1兆一读取
int len = -1; //接收长度
while ((len = sis.read(flush)) != -1) {
os.write(flush, 0, len); //分段写出
}
os.flush();
sis.close();
os.close();
}
public static void main(String[] args) throws IOException {
SplitFile sf = new SplitFile("src/com/io/SplitFile.java", "dest");
sf.split();
sf.merge("aaa.java"); //合并
}
} (25)CommonsIO组件-------- FileUtils 的使用
//文件大小
long len = FileUtils.sizeOf(new File("src/com/io/CommonsIOTest1.java")); //底层使用递归操作
//目录大小
len = FileUtils.sizeOf(new File("E:/IdeaProjects/MiniExercise"));
//返回的是一个集合,第二个参数为文件过滤器(内容非空),目录过滤器
Collection files = FileUtils.listFiles(new File("E:/IdeaProjects/MiniExercise"), EmptyFileFilter.NOT_EMPTY,null);
//第二个参数表示只要后缀是Java的文件,第三个参数表示操作子孙级
files = FileUtils.listFiles(new File("E:/IdeaProjects/MiniExercise"), new SuffixFileFilter("java"), DirectoryFileFilter.INSTANCE);
//第二个参数表示只要后缀是Java和class的文件,第三个参数表示操作子孙级
files = FileUtils.listFiles(new File("E:/IdeaProjects/MiniExercise"), FileFilterUtils.or(new SuffixFileFilter("java"),new SuffixFileFilter("class")), DirectoryFileFilter.INSTANCE);
//第二个参数表示只要后缀是Java和class的文件和空文件,第三个参数表示操作子孙级 files = FileUtils.listFiles(new File("E:/IdeaProjects/MiniExercise"), FileFilterUtils.or(new SuffixFileFilter("java"),new SuffixFileFilter("class"),EmptyFileFilter.EMPTY), DirectoryFileFilter.INSTANCE);
//第二个参数表示不为空且后缀是Java的文件,第三个参数表示操作子孙级 files = FileUtils.listFiles(new File("E:/IdeaProjects/MiniExercise"), FileFilterUtils.and(new SuffixFileFilter("java"),EmptyFileFilter.NOT_EMPTY), DirectoryFileFilter.INSTANCE);
for (File file:files){
System.out.println(file.getAbsolutePath());
}
//读取文件
String msg = FileUtils.readFileToString(new File("print.txt"),"UTF-8");
System.out.println(msg);
byte[] datas = FileUtils.readFileToByteArray(new File("print.txt"));
System.out.println(datas.length);
//逐行读取
List msgs = FileUtils.readLines(new File("print.txt"),"UTF-8");
for (String string:msgs){
System.out.println(string);
}
LineIterator it = FileUtils.lineIterator(new File("print.txt"),"UTF-8");
while (it.hasNext()){
System.out.println(it.nextLine());
}
//写出文件
FileUtils.write(new File("happy.txt"),"学习是一件伟大的事业\r\n","UTF-8",true);
FileUtils.writeStringToFile(new File("happy.txt"),"学习是一件辛苦的事情\r\n","UTF-8",true);
FileUtils.writeByteArrayToFile(new File("happy.txt"),"学习是一件幸福的事情".getBytes("UTF-8"),true);
//写出列表
List datas = new ArrayList();
datas.add("马云");
datas.add("马");
datas.add("马华腾");
datas.add("云");
FileUtils.writeLines(new File("happy.txt"),datas,"----",true); //----表示每个元素的连接符
//复制文件
FileUtils.copyFile(new File("aaa.java"),new File("aaa1.jpg"));
//复制文件到目录
FileUtils.copyToDirectory(new File("aaa.java"),new File("lib"));
//复制目录到目录,到目标目录还是目录的形式
FileUtils.copyDirectoryToDirectory(new File("lib"),new File("lib2"));
//复制目录,将目录内容复制到目标目录里
FileUtils.copyDirectory(new File("lib"),new File("lib2"));
拷贝URL内容
//String url = "http://picture.jpg";
//FileUtils.copyURLToFile(new URL(url),new File("picture1.jpg"));
打开网页
//String datas = IOUtils.toString(new URL("http://www.baidu.com"),"UTF-8"); //指定字符集
//System.out.println(datas);
//打开网页
String datas = IOUtils.toString(new URL("http://www.163.com"),"gbk"); //指定字符集
System.out.println(datas);