PS:要转载请注明出处,本人版权所有。
PS: 这个只是基于《我自己》的理解,
如果和你的原则及想法相冲突,请谅解,勿喷。
前置说明
本文作为本人csdn blog的主站的备份。(BlogID=114)
环境说明
- MLU220 开发板
- Ubuntu18.04 + MLU270开发主机一台
- aarch64-linux-gnu-gcc 6.x 交叉编译环境
前言
阅读本文前,请务必须知以下前置文章概念:
- 《寒武纪加速平台(MLU200系列) 摸鱼指南(一)--- 基本概念及相关介绍》 ( https://blog.csdn.net/u011728480/article/details/121194076 )
- 《寒武纪加速平台(MLU200系列) 摸鱼指南(二)--- 模型移植-环境搭建》 ( https://blog.csdn.net/u011728480/article/details/121320982 )
- 《寒武纪加速平台(MLU200系列) 摸鱼指南(三)--- 模型移植-分割网络实例》 ( https://blog.csdn.net/u011728480/article/details/121456789 )
这里再次回顾一下《寒武纪加速平台(MLU200系列) 摸鱼指南(一)--- 基本概念及相关介绍》的内容,寒武纪加速卡是一个硬件平台,是最底层的存在,在硬件平台之上,有驱动,在驱动之上,有运行时。本文的离线模型就是基于运行时的api进行调用和处理,得到模型结果。
本文作为本系列的终篇,将会从上文的离线模型开始,从头开始搭建我们的离线模型推理代码结构,经过合理的部署,能够在MLU220开发板正常的运行。
若文中引用部分存在侵权,请及时联系我删除。
离线模型推理前置须知
经过前文相关的介绍,我们可以知道我们主要调用的是运行时相关的api。这里存在两套api可以使用,一个是cnrt,一个是easydk。easydk是基于cnrt封装的api,大大简化了离线模型推理的开发流程。但是我们的开发主线是一致的,就是初始化mlu设备,加载模型,预处理,模型推理,后处理,处理结果。
此外,寒武纪还提供了CNStream程序框架,基于EasyDk开发,以pipeline+observer的方式,提供了一个简单易用的框架,如果有兴趣,请查看其官网 https://github.com/Cambricon/CNStream 。
我们其实要用的是EasyDK+CNRT的这种开发方式,构造一个类似CNStream这样的程序。
EasyDK简介与编译
首先其官网是:https://github.com/Cambricon/easydk。
其除了CNToolKit的依赖(neuware)之外,还依赖于glog,gflags,opencv,这些需要提前安装好。至于CNToolKit x86的版本的相关介绍已经在模型移植环境部分介绍过了。
由于我们要开发边缘端离线模型推理程序,一般来说,我们主要还是使用到EasyDK里面的EasyInfer部分的内容。其编译流程的话就如其官方介绍:
- cmake ..
- make
如果熟悉cmake的编译流程的话,其实就知道上面的流程是非常普遍的。对于EasyDK的编译来说,在x86下面进行编译是很简单的,但是如果要进行交叉编译的话,最好只生成核心库,其他的sample和test都关闭。
完成离线模型在MLU270上的运行
还记得在《寒武纪加速平台(MLU200系列) 摸鱼指南(三)--- 模型移植-分割网络实例》一文中,我们可以看到,通过torch_mlu.core.mlu_model.set_core_version('MLU220'),我们可以调整生成的离线模型运行的平台,可以是边缘端MLU220,可以是服务器部署端的MLU270。对的,没有看错,MLU270既可以做模型移植,也可以做离线模型的部署,就如同本系列的开篇所讲,这几个平台仅仅是部署场景的差异。
为什么我们需要在MLU270上调试离线模型呢?因为方便。因为MLU220一般来说都需要交叉编译,特别是相关的依赖库的生成比较麻烦,如果MLU220的板卡也方便调试的话,那也可以直接基于MLU220进行开发和调试。
由于我这边是EasyDK+CNRT混合调用的形式,因此我主要根据其官方的CNRT推理代码进行注释和介绍,并在相关位置标注哪些内容是EasyDK可以一步到位的。这里简单的回答几个疑问。为什么需要EasyDK这个库呢?为什么不直接基于CNRT进行开发?我的回答是根据项目推进的需要做出的选择。关于这种程序的最终形态,其实我还是期待直接基于CNRT开发,因为其有效,但是代价是你必须很熟悉的了解相关的内容。
下面是官方推理代码介绍(可能会在顺序上做一些变更,其官方代码未处理一些返回值,自己编写的时候需要注意,此外,官方的代码有些遗漏的地方,我进行了修改):
/* Copyright (C) [2019] by Cambricon, Inc. */
/* offline_test */
/*
* A test which shows how to load and run an offline model.
* This test consists of one operation --mlp.
*
* This example is used for MLU270 and MLU220.
*
*/
#include "cnrt.h"
#include
#include
#include
int offline_test(const char *name) {
// This example is used for MLU270 and MLU220. You need to choose the corresponding offline model.
// when generating an offline model, u need cnml and cnrt both
// when running an offline model, u need cnrt only
// 第一步,你必须调用cnrtInit()初始化运行时环境
cnrtInit(0);
// 第二步, 就是检查MLU设备,并设定当前设备,这一步其实是为多设备推理准备的
cnrtDev_t dev;
cnrtGetDeviceHandle(&dev, 0);
cnrtSetCurrentDevice(dev);
// 这里的第一二步其实可能创建一个EasyInfer对象就完成了,而且具备了完整的错误检查。
//
// prepare model name
// load model
// 第三步,就是加载模型
cnrtModel_t model;
cnrtLoadModel(&model, "test.cambricon");
// get model total memory
// 第四步,就是获取模型的一些属性,比如内存占用,并行性这些,这一步是可选的。
int64_t totalMem;
cnrtGetModelMemUsed(model, &totalMem);
printf("total memory used: %ld Bytes\n", totalMem);
// get model parallelism
int model_parallelism;
cnrtQueryModelParallelism(model, &model_parallelism);
printf("model parallelism: %d.\n", model_parallelism);
// 第五步,是建立推理逻辑流,这一步就是根据离线模型,在内存中动态生成模型推理结构。这里的"subnet0"是一个 kernel-func 名字,非固定,但是常见的名字都是subnet0,
// 在.cambricon_twins配套文件中有相关定义。
// 他这个和cuda编程其实比较类似,我们刚刚生成的模型推理结构其实被当做一个内核函数,函数名就是这个。
// load extract function
cnrtFunction_t function;
cnrtCreateFunction(&function);
cnrtExtractFunction(&function, model, "subnet0");
// 第六步,获取输入输出节点个数和输入输出数据size。注意许多网络中有多个输入,也可能有多个输出。在次注意这个概念,后续的操作都在多个输入和多个输出的基础上设计的。
int inputNum, outputNum;
int64_t *inputSizeS, *outputSizeS;
cnrtGetInputDataSize(&inputSizeS, &inputNum, function);
cnrtGetOutputDataSize(&outputSizeS, &outputNum, function);
// prepare data on cpu
// 第7步,申请cpu上的输入输出内存,这里是二维指针哈,代表多个输入输出
void **inputCpuPtrS = (void **)malloc(inputNum * sizeof(void *));
void **outputCpuPtrS = (void **)malloc(outputNum * sizeof(void *));
// allocate I/O data memory on MLU
// 第8步,申请mlu上的输入输出内存,这里是二维指针哈,代表多个输入输出。
// 此时还未真正申请数据内存,只是申请了数据节点的句柄(指针)
void **inputMluPtrS = (void **)malloc(inputNum * sizeof(void *));
void **outputMluPtrS = (void **)malloc(outputNum * sizeof(void *));
// prepare input buffer
// 第9步,分别对第8步的数据节点句柄申请真正的内存空间。这里的inputCpuPtrS和inputMluPtrS是一一对应的,这是内存地址不一样,内存管理者不一样。对输出也是同理。
// malloc是标准c申请堆内存接口
// cnrtMalloc是申请mlu所管理的内存接口,类比cuda的话,可以直接理解为申请显存
for (int i = 0; i < inputNum; i++) {
// converts data format when using new interface model
inputCpuPtrS[i] = malloc(inputSizeS[i]);
// malloc mlu memory
cnrtMalloc(&(inputMluPtrS[i]), inputSizeS[i]);
cnrtMemcpy(inputMluPtrS[i], inputCpuPtrS[i], inputSizeS[i], CNRT_MEM_TRANS_DIR_HOST2DEV);
}
// prepare output buffer
for (int i = 0; i < outputNum; i++) {
outputCpuPtrS[i] = malloc(outputSizeS[i]);
// malloc mlu memory
cnrtMalloc(&(outputMluPtrS[i]), outputSizeS[i]);
}
// 第10步,首先将预处理好的图像数据填充inputCpuPtrS, 拷贝cpu输入数据内存到mlu输入数据内存
cv::Mat _in_img;
_in_img = cv::imread("test.jpg");
_in_img.convertTo(_in_img, CV_32FC3);
for (int i = 0; i < inputNum; i++) {
// 注意这里的memcpy是我添加的,一般来说,模型的数据输入都是fp16或者fp32,但是一般我们的opencv生成的uint8。需要转换成fp32,或者fp16。
// 重要是事情发3次,注意图片的预处理后的数据格式以及模型输入的数据格式,不同的话,需要经过转换,官方提供了cnrtCastDataType来辅助转换过程。
// 重要是事情发3次,注意图片的预处理后的数据格式以及模型输入的数据格式,不同的话,需要经过转换,官方提供了cnrtCastDataType来辅助转换过程。
// 重要是事情发3次,注意图片的预处理后的数据格式以及模型输入的数据格式,不同的话,需要经过转换,官方提供了cnrtCastDataType来辅助转换过程。
::memcpy( inputCpuPtrS[i], _in_img.data, inputSizeS[i]);
cnrtMemcpy(inputMluPtrS[i], inputCpuPtrS[i], inputSizeS[i], CNRT_MEM_TRANS_DIR_HOST2DEV);
}
// 第10步,主要就是图像预处理,将图像数据传输到mlu上面去。
// 第11步,主要是开始设置推理参数
// prepare parameters for cnrtInvokeRuntimeContext
void **param = (void **)malloc(sizeof(void *) * (inputNum + outputNum));
for (int i = 0; i < inputNum; ++i) {
param[i] = inputMluPtrS[i];
}
for (int i = 0; i < outputNum; ++i) {
param[inputNum + i] = outputMluPtrS[i];
}
// 第12步,绑定设备和设置推理context
// setup runtime ctx
cnrtRuntimeContext_t ctx;
cnrtCreateRuntimeContext(&ctx, function, NULL);
// compute offline
cnrtQueue_t queue;
cnrtRuntimeContextCreateQueue(ctx, &queue);
// bind device
cnrtSetRuntimeContextDeviceId(ctx, 0);
cnrtInitRuntimeContext(ctx, NULL);
// 第13步,推理并等待推理结束。
// invoke
cnrtInvokeRuntimeContext(ctx, param, queue, NULL);
// sync
cnrtSyncQueue(queue);
// 第14步,将数据从mlu拷贝回cpu,然后进行后续的后处理
// copy mlu result to cpu
for (int i = 0; i < outputNum; i++) {
cnrtMemcpy(outputCpuPtrS[i], outputMluPtrS[i], outputSizeS[i], CNRT_MEM_TRANS_DIR_DEV2HOST);
}
// 第15步,清理环境。
// free memory space
for (int i = 0; i < inputNum; i++) {
free(inputCpuPtrS[i]);
cnrtFree(inputMluPtrS[i]);
}
for (int i = 0; i < outputNum; i++) {
free(outputCpuPtrS[i]);
cnrtFree(outputMluPtrS[i]);
}
free(inputCpuPtrS);
free(outputCpuPtrS);
free(param);
cnrtDestroyQueue(queue);
cnrtDestroyRuntimeContext(ctx);
cnrtDestroyFunction(function);
cnrtUnloadModel(model);
cnrtDestroy();
return 0;
}
int main() {
printf("mlp offline test\n");
offline_test("mlp");
return 0;
}
下面我简单列出一些EasyDK的操作顺序:
- 上文的第三四五步其实对应的是EasyInfer下面的ModelLoader模块,当初始化ModelLoader模块,并传参给EasyInfer实例,就完成了三四五步的内容。其实前面这些内容都是固定形式的,并不是重点。重点是后面的数据输入、推理、数据输出部分。
- 上文的第6,7,8,9步其实都是在为模型在cpu和mlu上申请相关的内存空间。在EasyDk中有对应的接口直接完成内存申请。
- 注意上文的第10步,是比较重要的一步,包含了图像数据预处理,到图像数据类型转换,再到图像数据输入到mlu内存。
- 上文的第11,12步是为推理准备参数
- 上文的第13步开始推理
- 上文的第14步从mlu内存中拷贝出推理结果到cpu内存,然后进行后处理。
- 上文的第15步,清理环境。
离线模型在MLU220上的部署
前一小节,主要还是完成离线模型推理的程序开发,并在MLU270上运行测试。本小节的主要内容是怎么将我们调好的程序部署到MLU220。
部署到MLU220,我们面临的第一个问题就是交叉编译生成AARCH64的程序。这里包含3个部分依赖,CNToolkit-aarch64,easydk-aarch64,其他第三方库如opencv-aarch64等。这时,我们得到了aarch64的离线推理程序,并配合之前我们转换得到的mlu220版本的离线模型。
当我们把生成好的程序放到mlu220板卡,这个时候,可能程序还是无法跑起来,因为可能驱动未加载,这个时候,建议找到驱动和固件,让mlu220运行起来。然后运行程序即可。
下面是无mlu设备的报错示例:

下面是加载驱动的最后日志:

下面是运行程序的输出:
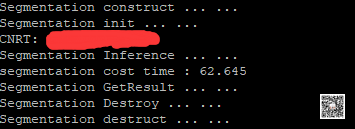
后记
对于RK3399pro和寒武纪MLU220平台来说,一些出来时间较为长久的模型,由于优化的比较到位,速度相较于RK3399pro可能有个300%+的性能提升。但是对于一些新的模型和一些非经典(非大众)的模型,由于自带的优化或者网络结构的原因,可能只有30%+的性能提升,但是这也是令人高兴的事情,毕竟硬件升级之后,好多事情可以达到准实时。
本系列的基本介绍就这些了,完结撒花~~~ ~~~。
参考文献
- 《寒武纪加速平台(MLU200系列) 摸鱼指南(一)--- 基本概念及相关介绍》 ( https://blog.csdn.net/u011728480/article/details/121194076 )
- 《寒武纪加速平台(MLU200系列) 摸鱼指南(二)--- 模型移植-环境搭建》 ( https://blog.csdn.net/u011728480/article/details/121320982 )
- 《寒武纪加速平台(MLU200系列) 摸鱼指南(三)--- 模型移植-分割网络实例》 ( https://blog.csdn.net/u011728480/article/details/121456789 )
- https://www.cambricon.com/
- https://www.cambricon.com/docs/cnrt/user_guide_html/example/offline_mode.html
- 其他相关保密资料。

PS: 请尊重原创,不喜勿喷。
PS: 要转载请注明出处,本人版权所有。
PS: 有问题请留言,看到后我会第一时间回复。