elasticsearch、ik分词器的安装及初步使用
-
elasticsearch定义
Elasticsearch 是一个分布式的免费开源搜索和分析引擎,它可以快速的存储、搜索和分析适用于包括文本、数字、地理空间、结构化和非结构化数据等在内的所有类型的海量数据.它以其简单的 REST 风格 API、分布式特性、速度和可扩展性而闻名. -
elasticsearch中的index(索引)、type(类型,在elasticsearch7及之后版本移除type概念)、document(文档)
- index如果当作名词相当于mysql中的database,如果当作动词相当于mysql中的insert
- type相当于mysql中的table
- document相当于mysql中某个table下的内容,格式是json.
-
为什么在elasticsearch7中去掉type概念
elasticsearch是基于Lucence开发的搜索引擎,在ES中不同type下名称相同的field最终在Lucence中处理方式是一样的.
比如两个不同type下的两个user_name,在ES同一个索引下被认为是同一个field,你必须在两个不同的type中定义相同的field映射,否则不同type中的相同字段名称就会在处理过程中出现冲突,导致Lucence处理效率下降.
解决办法: 将索引从多类型迁移到单类型,每种类型文档一个独立索引.
注: 在elasticsearch7.x中type参数可选,在elasticsearch8.x中不再支持URL中的type参数. -
docker下的elasticsearch安装
# 下载镜像文件 docker pull elasticsearch:7.4.2 # 在主机中创建与elasticsearch容器下的目录进行映射的目录,修改elasticsearch中的文件只需在主机上修改即可 mkdir -p /mydata/elasticsearch/config mkdir -p /mydata/elasticsearch/data # 配置elasticsearch.yml,使得所有主机都能够访问elasticsearch echo "http.host:0.0.0.0" >> /mydata/elasticsearch/config/elasticsearch.yml # 创建elasticsearch新容器并进行端口映射、内存配置以及目录映射等操作 sudo docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \ -e "discovery.type=single-node" -e ES_JAVA_OPTS="-Xms64m -Xmx128m" \ -v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \ -v /mydata/elasticsearch/data:/usr/share/elasticsearch/data \ -v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins \ -d elasticsearch:7.4.2 # docker中查询容器日志文件命令 docker logs 容器名称/id # 创建新容器后通过docker ps命令查看不到新启动的elasticsearch容器,通过一下命令查看日志信息 docker logs elasticsearch # 核心报错信息如下: "Caused by: java.nio.file.AccessDeniedException: /usr/share/elasticsearch/data/nodes" # 原因是与/usr/share/elasticsearch/data目录映射的本机/mydata/elasticsearch目录权限不够,普通用户无法访问,解决办法如下: chmod -R 777 /mydata/elasticsearch/ -
docker下的kibana(elasticsearch可视化)安装
# 下载镜像文件 docker pull kibana:7.4.2 # 创建kibana新容器并进行配置、端口映射、目录映射等操作 docker run --name kibana -e ELASTICSEARCH_HOSTS=http://192.168.145.8:9200 -p 5601:5601 -d kibana:7.4.2 -
elasticsearch安装是否成功测试
主机ip:9200,如下图展示表示安装成功
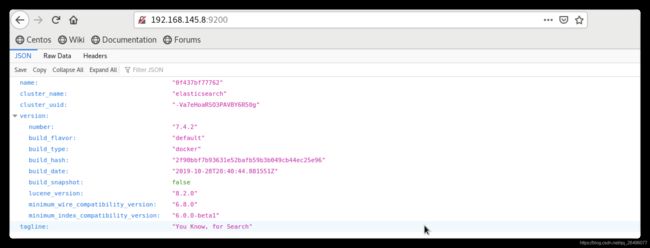
-
kibana安装是否成功测试
主机ip:5601,如下图展示表示安装成功

-
elasticsearch常用命令
-
查看节点信息:
http://192.168.145.8:9200/_cat/nodes

-
查看节点健康状况
http://192.168.145.8:9200/_cat/health

-
查看主节点信息
http://192.168.145.8:9200/_cat/master

-
查看所有索引
http://192.168.145.8:9200/_cat/indices

-
put带id的保存(发送多次是更新操作)

注: put请求中customer位置为索引名称、external位置为类型名称,1位置为数据唯一标识.
返回结果中前面带’_'的字段都为元数据. -
post请求(带id的话和put类似,第一次为新建,以后为更新;不带id的话会自动生成id,每次都是新建)
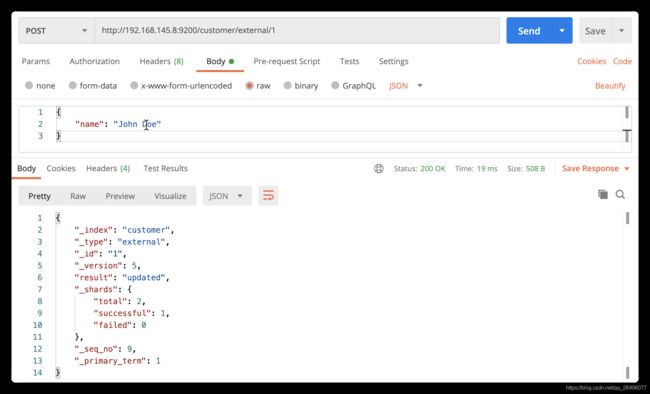
-
get查询数据
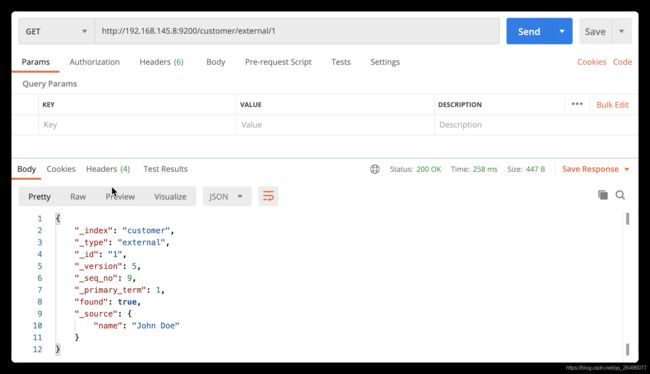
注: _seq_no: 并发控制字段,每次更新就会+1,用来做乐观锁
_primary_term: 同上,主分片会重新分配,如重启,就会发生变化. -
乐观锁修改
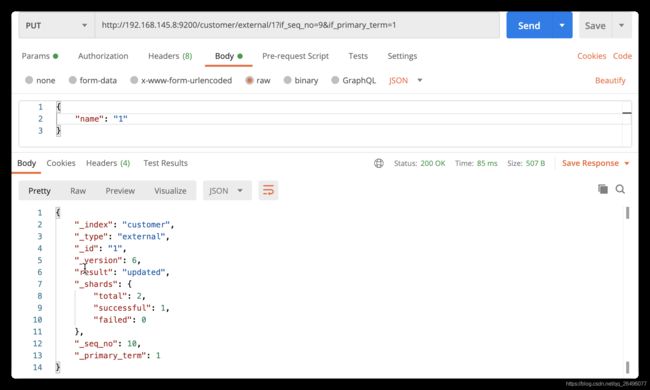
注: 只有当_seq_no和_primary_term同时满足时才会修改数据.由于每次修改或重启这两个字段值中至少有一个值会发生变化,所以可以防止并发修改. -
带_update的post更新(校验原数据,数据不发生变化则不更新)
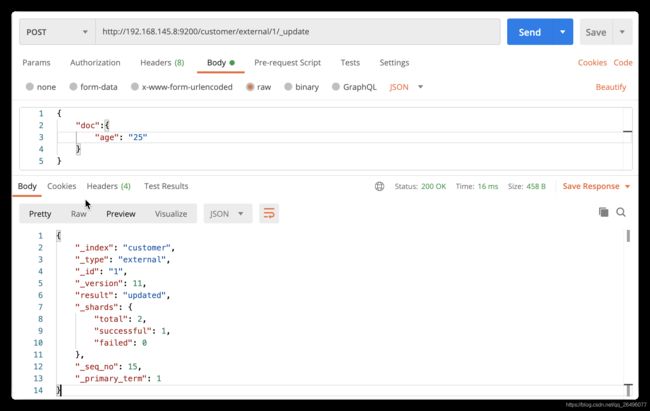
注: 带_update的更新json数据要带上“doc”,并且会校验原数据,如果数据没有发生变化,则执行该操作后也不会变化(包括_seq_no、_primary_term等都不会变). -
delete删除数据(可以删除文档和索引,但是不能直接删除类型)
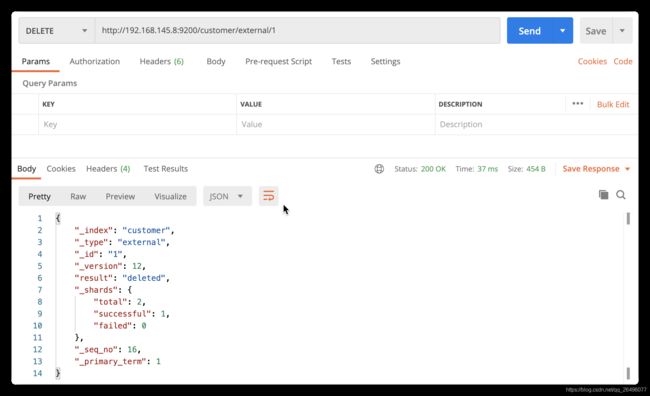

-
bulk批量操作(使用kibana,下面这种类型的json数据的POST请求postman不支持)
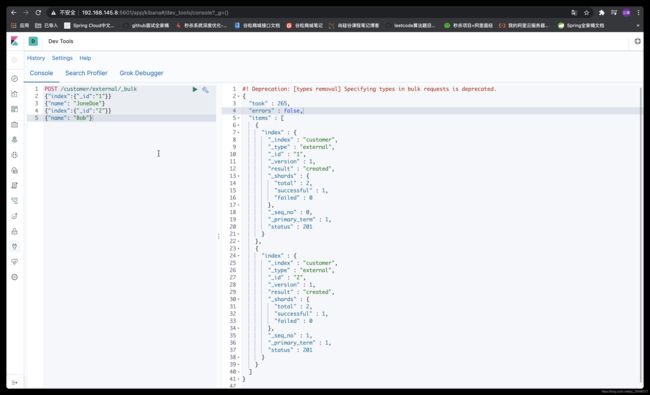
- 复杂数据的查询处理
-
银行账户测试数据
-
第一种查询方式
GET bank/_search?q=*&sort=account_number:asc -
第二种查询方式: Query DSL(domain-specific language 领域特定语言)
GET bank/_search { "query": { "match_all": { } }, "sort": [ { "account_number": { "order": "desc" } } ], "from": 0, "size": 5, "_source": ["firstname", "lastname", "balance"] }
- match字段匹配(相当于where语句)
-
match进行模糊查询(如下面的例子中“balance”字段需要包含16418,“address”字段需要包含Kings)
GET bank/_search { "query": { "match": { "balance": 16418 } } }GET bank/_search { "query": { "match": { "address": "Kings" } } } -
match_phrase进行短语匹配(将需要匹配的值当成一个整体单词进行检索)
GET bank/_search { "query": { "match_phrase": { "address": "mill road" } } }注: 检索结果中的“address”字段必须包括“mill road”,不能只包括其中一个或者“mill"和“road”没有紧挨.也就是把"mill road"看成一个单词就行.
-
match中使用keyword进行精确匹配查询
GET bank/_search { "query": { "match": { "address.keyword": "mill road" } } }注: address字段值就是"mill road".
-
match_multi多字段匹配
GET bank/_search { "query": { "multi_match": { "query": "mill movico", "fields": ["address", "city"] } } }注: 会对“query”进行分词匹配,也就是说只要“address”或city字段至少包含“mill”或"movico"中的一个即可.
-
bool复合查询
GET bank/_search { "query": { "bool": { "must": [ { "match": { "gender": "M" }}, { "match": { "address": "mill" }} ], "must_not": [ { "match": { "age": "28" }} ], "should": [ { "match": { "firstname": "Winnie" }} ] } } }注: must中是必须满足的条件,must_not中是必须不满足的条件,should中是最好满足的条件(满足的话得分高),不满足也可以.
-
filter结果过滤
GET bank/_search { "query": { "bool": { "must": [ { "match": { "gender": "M" }}, { "match": { "address": "mill" }} ], "should": [ { "match": { "firstname": "Winnie" }} ], "filter": { "range": { "age": { "gte": 20, "lte": 50 } } } } } } -
term字段查询
和match一样,匹配某个属性的值.全文检索字段(text字段)使用match,其他的非text字段匹配使用term. -
aggregations执行聚合(提供了从数据中分组和提取数据的能力)
-
场景1: 搜索address中包含mill的所有人的年龄分布以及平均年龄和平均薪资
GET bank/_search { "query": { "match": { "address": "mill" } }, "aggs": { # "ageAgg"为聚合名称 "ageAgg": { # "terms"为聚合类型 "terms": { "field": "age", "size": 10 } }, # 聚合名称 "ageAvg": { # 聚合类型 "avg": { "field": "age" } }, "balanceAvg": { "avg": { "field": "balance" } } }, # 命中的数据不显示,只显示聚合结果 "size": 0 }结果展示(address中包含mill的所有人的平均年龄为34,平均薪资为25208):
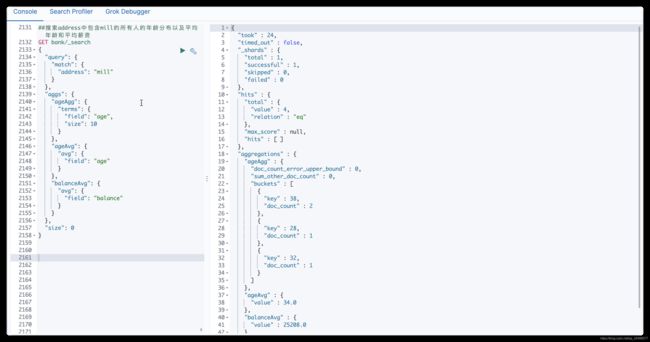
-
场景2: 按照年龄聚合,并且展示年龄分布以及每个年龄段的人的平均薪资
GET bank/_search { "query": { "match_all": { } }, "aggs": { # 聚合名称 "ageAgg": { # 聚合类型 "terms": { # 聚合文档(即字段) "field": "age", # 只对10个年龄段的数据进行操作 "size": 10 }, # 子聚合 "aggs": { # 子聚合名称 "ageAvg": { # 子聚合类型 "avg": { "field": "balance" } } } } } } -
场景3: 查出所有年龄分布,并且这些年龄段中M男性的平均薪资和F女性的平均薪资以及这个年龄段的总体平均薪资
GET bank/_search { "query": { "match_all": { } }, "aggs": { # 聚合名称(对年龄进行聚合) "ageAgg": { # 聚合类型 "terms": { "field": "age", "size": 10 }, "aggs": { # 子聚合名称(再对性别进行聚合) "genderAvg": { # 子聚合类型 "terms": { # 由于gender文档(字段)为text类型,所以要加上.keyword "field": "gender.keyword", "size": 10 }, # 再次聚合,对每个年龄段下的性别的薪资再进行聚合 "aggs": { "ageGenderAvg": { "avg": { "field": "balance" } } } }, # 对每个年龄段的薪资进行聚合 "aggAvg": { "avg": { "field": "balance" } } } } } }部分结果展示:

- elasticsearch映射(mapping)的创建(定义索引的字段名称和数据类型)
-
创建索引及字段映射
PUT /my_index { "mappings": { "properties": { "age": { "type": "integer"}, # 类型为keyword,只能进行精确检索 "email": { "type": "keyword"}, # 类型为text,会进行分词处理,可以进行模糊查询 "name": { "type": "text"} } } } -
添加新的字段映射
PUT /my_index/_mapping { "properties": { "employee_id": { "type": "keyword" } } } PUT /my_index/_mapping { "properties": { "sex": { "type": "keyword", # 默认为true,设置为false的话,该字段不能被检索到 "index": false } } }
-
数据迁移(elasticsearch无法在原来的基础上修改某个字段的映射,只能创建新的索引和映射,然后进行数据迁移)
# 创建新的索引和映射 PUT /newbank { "mappings": { "properties": { "account_number": { "type": "long" }, "address": { "type": "text" }, "age": { "type": "integer" }, "balance": { "type": "long" }, "city": { "type": "keyword" }, "email": { "type": "keyword" }, "employer": { "type": "keyword" }, "firstname": { "type": "text" }, "gender": { "type": "keyword" }, "lastname": { "type": "text" }, "state": { "type": "keyword" } } } } # 数据迁移 POST _reindex { "source": { "index": "bank", # elasticsearch7.x及之后就没有type了,下面这行也就不用写了 "type": "account" }, "dest": { "index": "newbank" } }数据迁移后查询,可以看到type为_doc,说明没有type了.
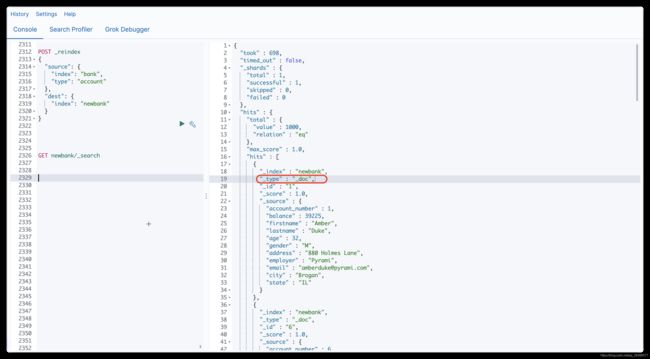
-
ik分词器
-
ik分词器github链接,下载的版本一定要和elasticsearch版本一致.
-
ik分词器的安装
1. unzip解压 2. 重启elasticsearch 容器 docker restart elasticsearch -
使用ik_smart分词器进行分词
POST _analyze { "analyzer": "ik_smart", "text": "她的歌曲很好听" }
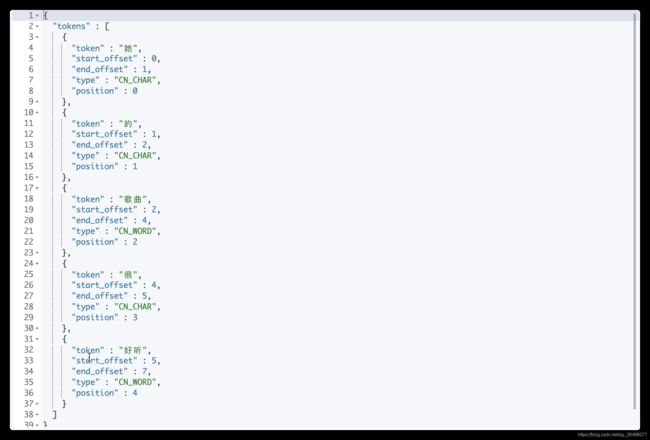
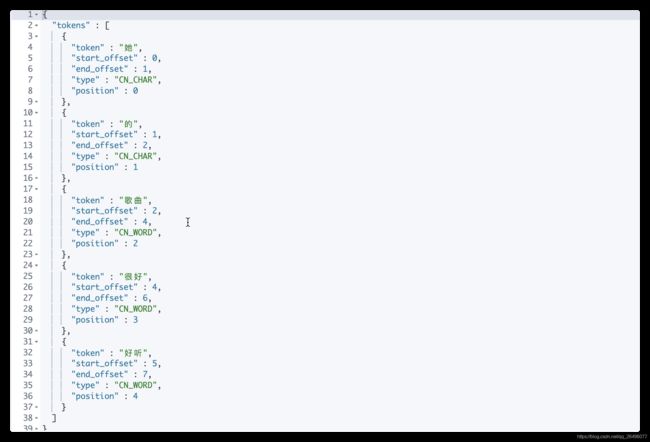
- 使用ik_max_word分词器进行分词(获取最大单词组合)
POST _analyze { "analyzer": "ik_max_word", "text": "她的歌曲很好听" }
18. 通过nginx配置ik分词器的远程词库
# 运行一个nginx容器(主要是为了获取nginx的配置文件)
docker run -p 80:80 --name nginx -d nginx:1.10
cd /mydata
# 将docker的nginx容器中的/etc/nginx目录及其中的内容拷贝到/mydata目录下
docker container cp nginx:/etc/nginx .
# 停止nginx容器
docker stop nginx
# 删除nginx容器(nginx的配置文件已经拷贝完成,该容器已经没有用处了)
docker rm nginx
# 将nginx重命名为conf
mv nginx conf
# 新建nginx目录,并将conf目录拷贝到nginx目录下
mkdir nginx
mv conf nginx/
# 运行一个新的nginx容器,并进行数据卷文件映射
# 上面的所有操作都是为/mydata/nginx/conf目录的映射做铺垫,如果直接运行下面命令,会报没有nginx.conf配置文件错误
docker run -p 80:80 --name nginx -v /mydata/nginx/html:/usr/share/nginx/html -v /mydata/nginx/logs:/var/log/nginx -v /mydata/nginx/conf:/etc/nginx -d nginx:1.10
cd /mydata/nginx/html
mkdir es
cd es
vim fenci.txt
# 输入自定义的分词,并:wq保存退出
# 修改elasticsearch中ik分词器插件的配置文件
vim /mydata/elasticsearch/plugins/ik/config/IKAnalyzer.cfg.xml
# 配置ik分词器的远程扩展字典(nginx的默认端口号为80,也就是说远程扩展字典位置是本机上的/mydata/nginx/html/es/fenci.txt,当然由于做了数据卷映射,nginx容器中也有相应的位置)
# 如果把nginx放其他主机上,做出上面配置后,修改主机ip即可达到使用真正的远程扩展字典
<entry key="remote_ext_dict">http://192.168.145.8/es/fenci.txt</entry>
# 重启elasticsearch容器
docker restart elasticsearch
# 设置elasticsearch容器开机自启动(可选)
docker update elasticsearch --restart=always
测试结果(可看到已经能够按照远程扩展字典中词汇进行分词,原来是分不了的):
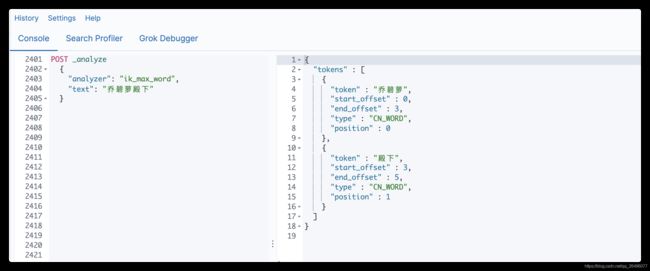
19. elasticsearch在项目中的使用
-
在pom.xml中导入依赖
<properties> <elasticsearch.version>7.4.2elasticsearch.version> properties> <dependency> <groupId>org.elasticsearch.clientgroupId> <artifactId>elasticsearch-rest-high-level-clientartifactId> <version>7.4.2version> dependency> -
编写elasticsearch配置类
package com.kenai.gulimall.search.config; import org.apache.http.HttpHost; import org.elasticsearch.client.RestClient; import org.elasticsearch.client.RestHighLevelClient; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; @Configuration public class GulimallElasticSearchConfig { @Bean // 给容器中注入一个RestHighLevelClient public RestHighLevelClient esRestClient(){ RestHighLevelClient client = new RestHighLevelClient( RestClient.builder(new HttpHost("192.168.145.8", 9200, "http")) ); return client; } } -
配置application.yml文件
spring: cloud: nacos: discovery: server-addr: localhost:8848 application: name: gulimall-search