机器学习之模型评估
模型适用于新样本的能力,称为“泛化能力“
数据集划分有留出法、交叉验证法和自助法
用训练集建立模型,基于验证集上的性能来进行模型选择和调参
用测试集上的判别效果来估计模型在实际使用时的泛化能力
泛化性能是由学习算法的能力、数据的充分性以及学习任务本身的难度共同决定
性能度量是衡量模型泛化能力的评价标准
混淆矩阵、查准查全率是分类问题上重要的评价指标
把一个正样本分对的概率称为真正例率,把一个负样本当成正样本的概率称为假正例率
ROC是以TPR为纵坐标,FPR为横坐标的曲线,它与横坐标的面积是AUC得分
模型在不平衡数据集上的性能评估最好使用AUC而不是Accuray
偏差度量了学习算法期望预测与真实结果的偏离程度
方差刻画了数据扰动所造成的影响
出现低偏差而高方差的现象称为过拟合;高偏差而方差较低称为欠拟合
学习曲线与验证曲线有助于观察模型的欠拟合与过拟合情况
机器学习,是指在给定任务(T)下,对数据集(D)做一定特征工程(F)后建立相应的模型(M),并通过模型评估(E)来评价模型好坏。
首先,我们要说明一下为什么要有模型评估这一步。
机器学习的目标是使学得的模型(假设hypothesis、学习器)能很好地适用于“新样本”,学得模型适用于新样本的能力,称为“泛化能力“(generalization).
因此,我们把模型实际预测输出与样本的真实输出之间的差异称为“误差”(error),模型在训练集上的误差称为“训练误差”(training error)或“经验误差”(empirical error),在新样本上的误差称为“泛化误差”(generalizatin error)。显然,我们希望得到泛化误差小的模型。然而,我们事先并不知道新样本是什么样的,实际能做的只是努力使经验误差最小化。在这种背景下,就需要一些标准来评估模型的好坏。
模型评估需要有评估方法及性能度量,下面分别介绍。
1.评估方法
通常情况下,我们把数据集抽出一部分,作为评估模型的好坏,抽出来的数据集叫做“测试集”,而用余下的数据集用作训练,称为“训练集”。
实际中,我们可能会对同一堆数据建立不同的模型,不同的算法,有些算法需要通过调节和选择算法“超参数”来找到最优的模型,因此,在研究对比不同算法的泛化性能时,我们用测试集上的判别效果来估计模型在实际使用时的泛化能力,而把训练集两外划分为训练集和验证集,基于验证集上的性能来进行模型选择和调参。
下面一张图展示这个训练集(training set)、验证集(validation set)和测试集(testing set)的差异:
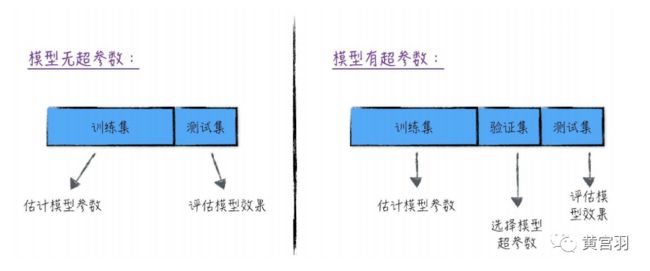
那么实际中如何划分训练集、验证集和测试集呢,一般有三种方法,下面分别介绍。
a.留出法(hold-out)
原理:将数据集D划分为两个互斥的集合,其中一个作为训练集S(70%),另一个作为测试集T(30%)。在S上训练模型,在T上评估测试误差,作为对泛化误差的评估
使用方法:单次使用留出法得到的估计结果往往不够稳定可靠,一般采用若干次随机划分、重复进行实验评估后取平均值作为留出法的评估效果
b.交叉验证法(k折交叉验证)
k通常取值为10,常用的还有5、20等
原理:将数据集D划分为k个大小相似的互斥子集,用k-1个子集的并集作为训练集,余下的那个子集作为测试集,获得k组训练/测试集,从而可进行k次训练和测试,返回k个测试结果的均值。
若k取数据集的样本个数m,就得到特例:留一法(Leave-One-Out,简称LOO),优点是被实际评估的模型与期望评估的模型(用D训练)很相似,评估结果往往被认为比较准确;缺点是当数据集比较大时,训练m个模型的计算开销是巨大的。
c.自助法(bootstrapping)
适用于数据集较小、难以有效划分训练/测试集的情况
方法:给定一个数据集D,对它采样产生一个新的数据集D':每次随机从D中挑选一个样本,将其拷贝到D',然后把该样本放回数据集D,这个过程重复执行m次后,得到包含m个样本的数据集D'。这就是自助采样。用D'作为训练集,D\D'作为测试集,这样的测试结果,称为外包估计(out-of-bag-estimate)
样本在m次采样中始终不被采集到的概率是(1-1/m)^m,取极限得到:
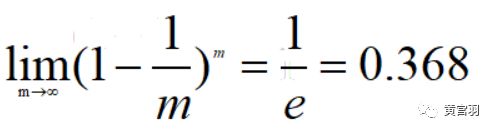
即数据集D中约有36.8%的样本未出现在D'数据集上。
以下代码实现了三种划分方法:
#留出法
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3)
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3,stratify=y) #实现分层抽样
#交叉验证
from sklearn.model_selection import KFold
kf = KFold(n_splits=5,random_state=0,shuffle=True)
for index in kf.split(data): #因为是5等分,即5折交叉,一共循环5次
pass #index[0]是每一折的训练集,index[1]是每一折的测试集
#还有其他的交叉验证划分方法
from sklearn.model_selection import GroupKFold,StratifiedKFold
from sklearn.model_selection import LeaveOneGroupOut,LeavePGroupsOut,LeaveOneOut,LeavePOut
#自助法
# train = df.sample(frac=1.0,replace=True,random_state=0)
# cross_vad = df.loc[df.index.difference(train.index)].copy()
2.性能度量
衡量模型泛化能力的评价标准,就是性能度量。
回归任务中最常用的性能度量是均方误差,这个也称为“损失函数”,关于损失函数,我们会专门出一篇文章讲解,这里介绍的性能度量是除去一些常用的损失函数外的评价标准。主要包括:错误率与精度、查全查准、ROC和AUC、方差与偏差以及关于与其对应的过拟合和欠拟合
2.1 错误率与精度
这两个比较好理解,错误率(accuray)就是预测错误的样本占总样本的比例,精度=1-错误率
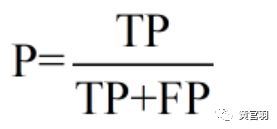
2.2 查准率P(准确率,precision)和查全率R(召回率,recall)
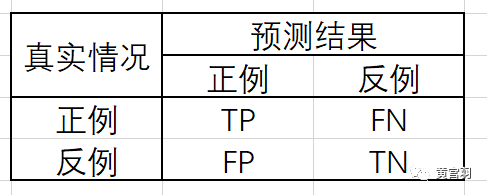
对于二分类问题,根据真实类别与学习器预测类别的组合划分为真正例(true positive)、假正例(false positive)、真反例(true negative)、假反例(false negative)四种情形,分别记为TP、FP、TN、FN。分类结果的”混淆矩阵“(confusion matrix)用如下表所示:
查准率数学定义:
查全率数学定义:
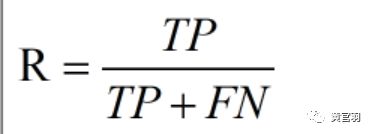
度量查准率和查全率性能的指标:
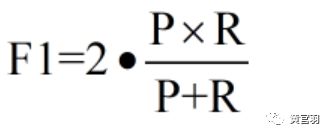
在具体应用场景中,有时候对两者的偏重不一样,比如,商品推荐系统中,为了尽可能少打扰用户,更希望推荐内容确是用户感兴趣的,此时用查准率更重要;而在逃犯追逃信息检索中,更希望尽可能少漏掉逃犯,此时查全率更重要。因此,采取F1度量的一般形式:
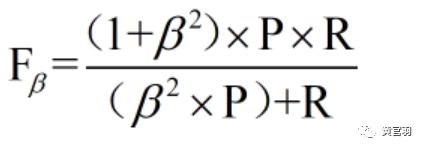

进行多次训练/测试后得到一系列混淆矩阵,有两个计算方法综合考察查准率和查全率:
第一种,计算各个混淆矩阵的查准率和查全率,再计算平均值,这样得到宏查准率(macro-P),宏查全率(macro-R),以及相应的宏F1(macro-F1)。
第二种,将各个混淆矩阵的对应元素进行平均,得到相应的TP、FN、FP、TN的平均值,再基于这些均值计算微查准率(micro-P),微查全率(micro-R),以及相应的微F1(micro-F1)。
2.3 ROC和AUC
首先引进正正例率和假正例率。
真正例率定义(把一个正样本分对的概率):
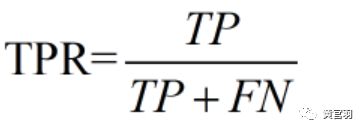
假正例率定义(把一个负样本当成正样本的概率):
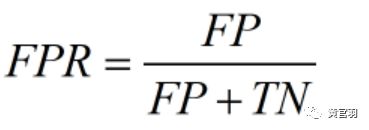
根据以上定义,我们知道,FPR越低越好,TPR越高越好。
ROC曲线(Receiver Operating Characteristic)
ROC曲线全称是“受试者工作特征”,它根据学习器的预测结果进行排序,然后逐个样本以正例为预测,每次计算相应的真正例率和假正例率,并以TPR为纵坐标,FPR为横坐标作图,得到的曲线,它具备以下两个性质:
a.ROC曲线必须是凹函数,否则该学习器的泛化能力很差,甚至欠拟合程度过高
b.衡量两条ROC曲线的好坏,分为两种情况,一种是若一条ROC曲线完全”包住“另一条,则前者对应的学习器性能高;另一种是直接计算ROC曲线在横轴上的积分(面积大小)
AUC得分(Area Under ROC Curve):
计算:ROC曲线在横轴上的积分。
AUC值越大,其对应的ROC曲线性能越高。
AUC值是一个概率值,当你随机挑选一个正样本以及负样本,当前的分类算法根据计算得到的Score值将这个正样本排在负样本前面的概率就是AUC值,AUC值越大,当前分类算法越有可能将正样本排在负样本前面,从而能够更好地分类。
AUC的一般判断标准:
* 0.1 - 0.5:模型的表现比随机猜测还差
* 0.5 - 0.7:效果较低,但用于预测股票已经很不错了
* 0.7 - 0.85:效果一般
* 0.85 - 0.95:效果很好
* 0.95 - 1:效果非常好,但一般不太可能
拓展:
关于AUC,我们需要有更深一步的理解,主要是要记住下面一个结论:
模型在不平衡数据集上的性能评估最好使用AUC而不是Accuray
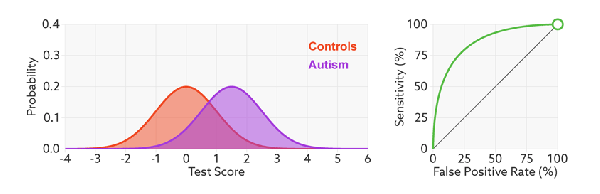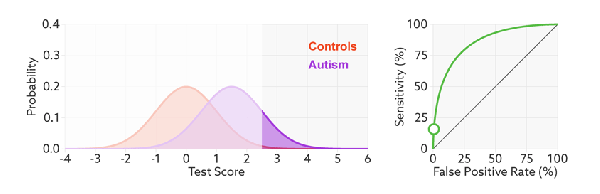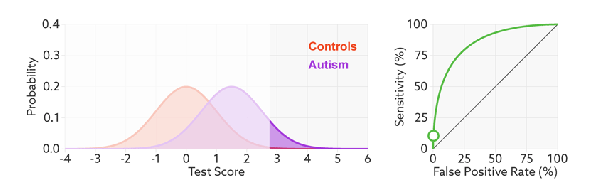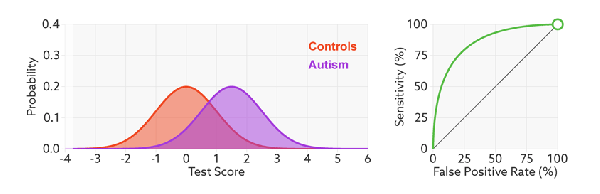
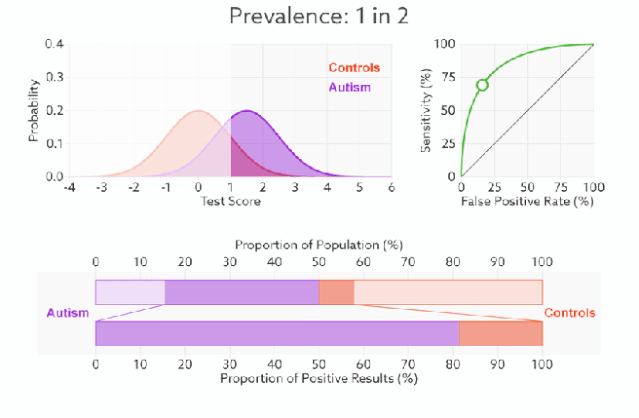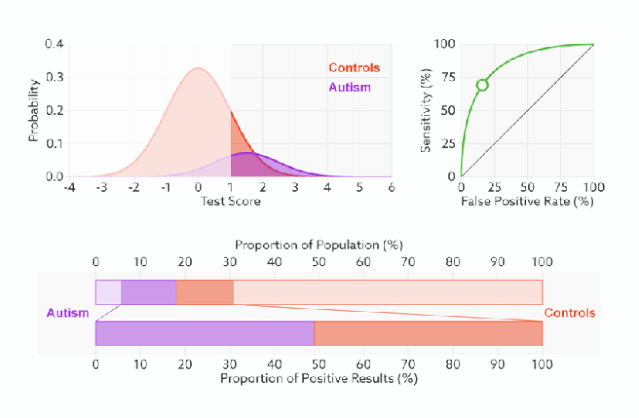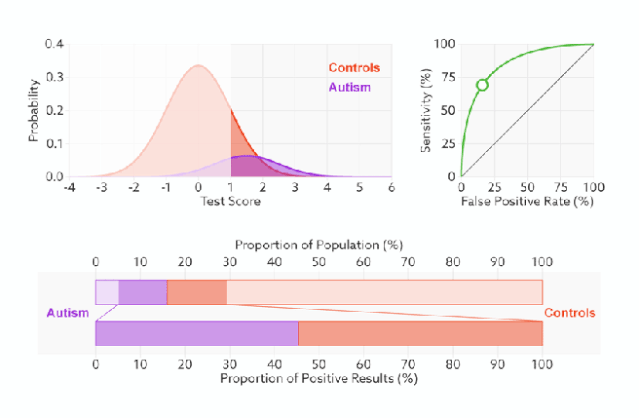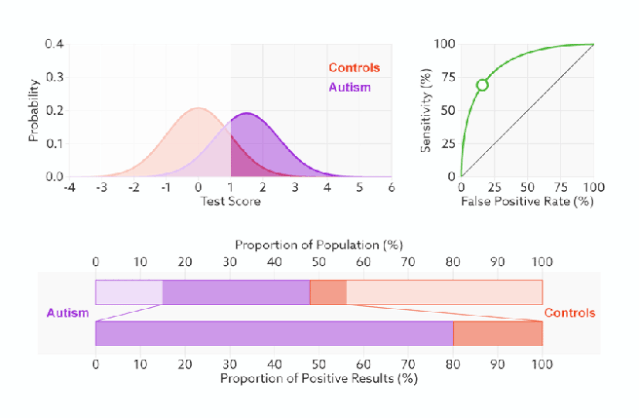
1)橙色的曲线是指负样本(多数类)的分布,紫色的曲线是指正样本(少数类)的分布,两条曲线中间透明的边界就是模型用于把概率转换为0/1的阈值.
分类器的分类性能越好,即把正负样本分开能力越强时,真正例率越高,假正例率越低,这样ROC曲线就越往左上方偏斜,当ROC曲线为一条45度直线时,表示模型的区分能力等同于随机乱猜
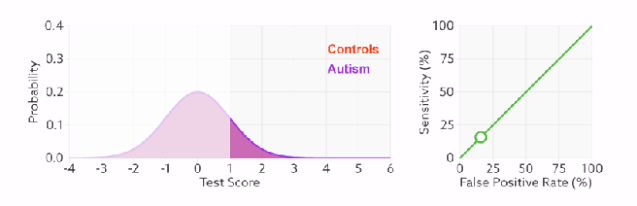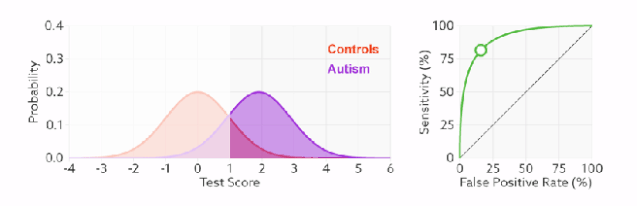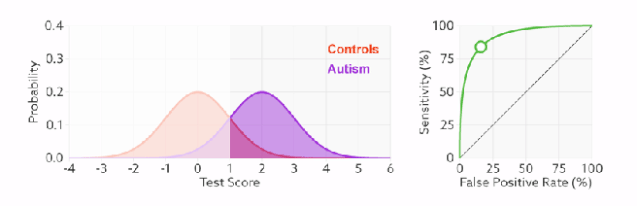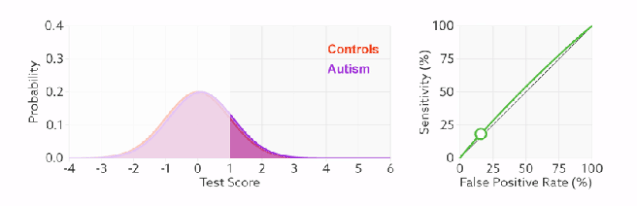
2).判断正负样本概率阈值的变化不会影响模型的AUC
3).面临不平衡的数据集的时候,ROC曲线无视样本不均衡的情况,只考虑模型的分类能力
2.4方差与偏差以及过拟合欠拟合

我们假定噪声期望为零,则对算法的期望泛化误差进行分解:
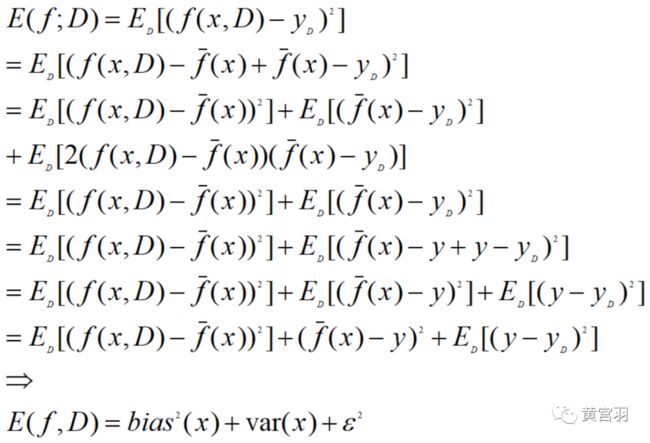
因此,泛化误差可分解为偏差、方差与噪声之和.
偏差度量了学习算法期望预测与真实结果的偏离程度,刻画了学习算法本身的拟合能力;
方差度量了同样大小的训练集的变动所导致的学习能力的变化,刻画了数据扰动所造成的影响;
噪声表达了学习算法所能达到的期望泛化误差的下界,即刻画学习问题本身的难度。
因此,泛化性能是由学习算法的能力、数据的充分性以及学习任务本身的难度共同决定。
注:对于分类问题,方差与偏差可以简单的理解为:
偏差指模型在训练数据集上表现出的错误率
方差指模型在测试集上的表现比训练集上差多少
基于方差和偏差的概念,我们得出过拟合与欠拟合的概念:
欠拟合:训练误差(高偏差)和验证误差都很大,这种情况称为欠拟合。出现欠拟合的原因是模型尚未学习到数据的真实结构。因此,模拟在训练集和验证集上的性能都很差。
过拟合:模型在训练集上表现很好,但是在验证集上却不能保持准确,也就是模型泛化能力很差。这种情况很可能是模型过拟合。
下面给出四种情况以便更好的理解过拟合与欠拟合:
情况1:
* 训练错误率 = 1%
* 测试错误率 = 11%
估计偏差为 1%,方差为 10%(=11%-1%)。因此,它有一个很高的方差(high variance)。虽然分类器的训练误差非常低,但是并没有成功泛化到开发集上。这也被叫做过拟合(overfitting)
情况2:
* 训练错误率 = 15%
* 测试错误率 = 16%
估计偏差为 15%,方差为 1%。该分类器的错误率为 15%,没有很好地拟合训练集,但它在开发集上的误差不比在训练集上的误差高多少。因此,该分类器具有较高的偏差(highbias),而方差较低。我们称该算法是欠拟合(underfitting)的。
情况3:
* 训练错误率 = 15%
* 测试错误率 = 30%
估计偏差为 15%,方差为 15%。该分类器有高偏差和高方差(high bias and highvariance):它在训练集上表现得很差,因此有较高的偏差,而它在开发集上表现更差,因此方差同样较高。由于该分类器同时过拟合和欠拟合,过拟合/欠拟合术语很难准确应用于此。
情况4:
* 训练错误率 = 0.5%
* 测试错误率 = 1%
该分类器效果很好,它具有低偏差和低方差
模型如果出现了欠拟合或者过拟合怎么办呢,笔者也总结了一些经验,分享给大家。
欠拟合解决办法:
1. 加大模型规模(如增加输入特征):这项技术能够使算法更好地拟合训练集,从而减少偏差。
2. 根据误差分析结果修改输入特征:假设误差分析结果鼓励你增加额外的特征,从而帮助算法消除某个特定类别的误差。
3. 减少或者去除正则化(L2 正则化,L1 正则化):这将减少可避免偏差,但会增大方差。
4. 修改模型架构
5. 集成学习方法boosting(如GBDT)能有效解决high bias
* 添加更多的特征将增大方差;当这种情况发生时,你可以加入正则化来抵消方差的增加
* 添加更多的训练数据:这项技术可以帮助解决方差问题,但它对于偏差通常没有明显的影响
过拟合解决办法:
1. 添加更多的训练数据:这是最简单最可靠的一种处理方差的策略,只要你有大量的数据和对应的计算能力来处理他们
2. 加入正则化(L2 正则化,L1 正则化):这项技术可以降低方差,但却增大了偏差
3. 加入提前终止(例如提前终止梯度下降):可以降低方差但却增大了偏差。提前终止(Early stopping)有点像正则化理论,它是正则化技术之一
4. 通过特征选择减少输入特征的数量和种类:这种技术或许有助于解决方差问题,但也可能增加偏差
5. 减小模型规模:谨慎使用
6. 集成学习方法bagging(如随机森林)能有效防止过拟合。
以上就是模型评估的内容,这里我们还需要做一个拓展,介绍学习曲线和验证曲线,它主要是用来观察模型的偏差与方差,便于更好发现模型是否过拟合或者欠拟合。
拓展
学习曲线
学习曲线是表示样本大小与准确率之间的函数关系
先给图形,再做解释。
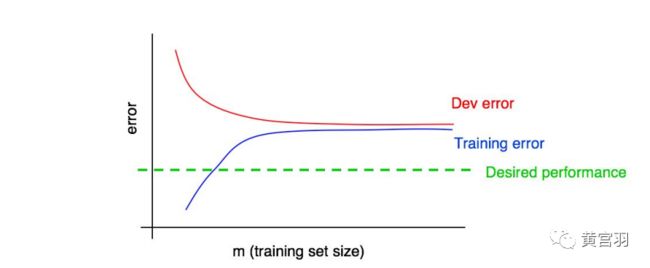
* 随着训练集大小的增加,测试集误差应该降低。图中红色曲线
* 希望学习算法最终能够达到的最有错误率:期望错误率。图中绿色曲线
* 训练误差曲线来协助评估添加数据所带来的影响。图中蓝色曲线
* 根据红色的“开发误差”曲线的走势来推测,在添加一定量的数据后,曲线距离期望的性能接近了多少
* 蓝色的“训练误差”曲线随着训练集大小的增加而上升,而且算法在训练集上通常比在测试集上表现得更好。
* 红色的开发误差曲线通常严格位于蓝色训练错误曲线之上
有了这个曲线,我们就可以通过观察来诊断模型是否过拟合了
高偏差情形:
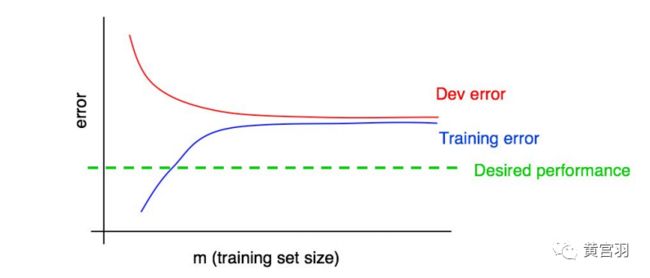
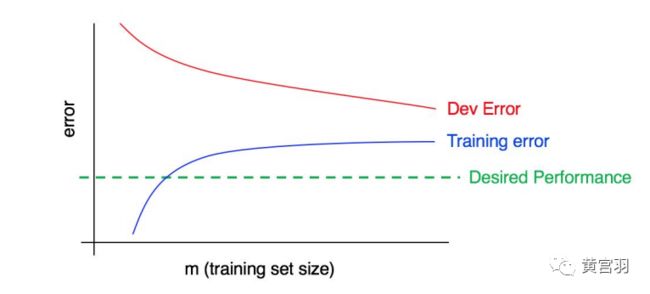
高方差情形:
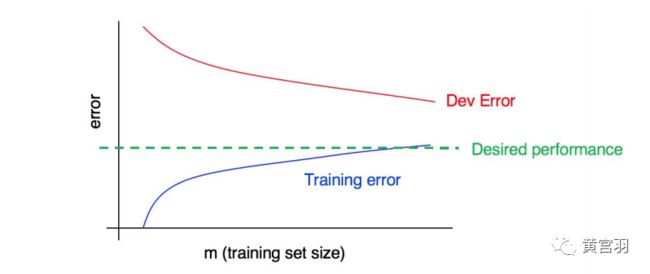
高偏差&高方差:
绘制学习曲线注意的坑
1. 在较小规模的训练集上,曲线看起来带有点噪声。
2. 机器学习应用程序很倾向于某一个类,或者说有大量的类。那么选择一个“非代表性”或糟糕的特殊训练集的几率也将更大
例如,假设你的整个样本中有 80% 是负样本(y=0),只有20% 是正样本(y=1),那么一个含有 10 个样本的训练集就有可能只包含负样本,因而算法很难从中学到有意义的东西。
存在训练集噪声致使难以正确理解曲线的变化时,有两种解决方案:
与其只使用 10 个样本训练单个模型,不如从你原来的 100 个样本中进行随机有放回抽样,选择几批(比如 3-10 )不同的 10 个样本进行组合。在这些数据上训练不同的模型,并计算每个模型的训练和开发错误。最终,计算和绘制平均训练集误差和平均开发集误差。
如果你的训练集偏向于一个类,或者它有许多类,那么选择一个“平衡”子集,而不是从100 个样本中随机抽取 10 个训练样本。例如,你可以确保这些样本中的 2/10是正样本,8/10 是负样本。更常见的做法是,确保每个类的样本比例尽可能地接近原始训练集的总体比例。
验证曲线
验证曲线是准确率与模型超参数之间的关系
从验证曲线上可以看到随着超参数设置的改变,模型可能从欠拟合到合适再到过拟合的过程,进而选择一个合适的位置,来提高模型的性能。
需要注意的是如果我们使用验证分数来优化超参数,那么该验证分数是有偏差的,它无法再代表模型的泛化能力,我们就需要使用其他测试集来重新评估模型的泛化能力。
from sklearn.model_selection import validation_curve #学习器参数对性能的影响
f = make_scorer(mean_squared_error)
li = np.linspace(1,500,50)
train_scores,test_scores = validation_curve(Ridge(fit_intercept=False),
X_train,y_train,param_name='alpha',param_range=li,cv=5,scoring=f)
train_mse = np.mean(train_scores,axis=1)
test_mse = np.mean(test_scores,axis=1)
plt.figure()
plt.plot(li,train_mse,'o-',color = 'g',label = 'training')
plt.plot(li,test_mse,'o-',color = 'r',label = 'cv')
plt.legend(loc='best')
plt.xlabel('value')
plt.ylabel('error')
plt.title('验证曲线')
plt.show()
参考资料:
《机器学习(周志华著)》
https://mp.weixin.qq.com/s/HiJXaOjGOnSaKiMoTRjXFA