python识别图片中的文字、数值并转文档
最近工作中有把图片中的文字和数字识别出来的需求,但是网上的图片转excel有些直接收费,有些网址每天前几次免费,后续依然要收费。想着趁周末有时间,倒腾一下,如果后续这种需求多的话,可以节省一点成本,也可以提升自己编程的能力。而且在一些爬虫登录时,字符识别自动填写也需要。

一、安装pytesseract库和OCR识别软件
打开cmd,在里面输入
pip install pytesseract
即可成功安装pytesseract库,但是这时直接调用该库会出现如下错误:
从网上搜索原因发现要实现图片识别,要先安装OCR识别软件:tesseract-ocr,有需要的可以到如下官网自行下载:
https://github.com/UB-Mannheim/tesseract/wiki
不过这个网址下载速度特别慢,电脑是 windows64 位的朋友,可以到公众号中回复 “OCR软件” 免费获取网盘下载地址,提高下载速度。安装 OCR 识别软件时,一路默认即可,如果怕 C 盘内存占用太多,影响电脑速度,也可以选择别的盘安装,我就是安装在 D:\tpsb 文件夹中。
软件装完后需配置环境变量: 我的电脑 ->属性 -> 高级系统设置 ->环境变量 ->系统变量 ,在 path 中添加 OCR 安装路径,具体如下:
我的OCR软件是安装在D:\tpsb文件夹中,你在添加的时候要改成你的安装目录。由于OCR默认识别英文和数字,不能识别中文,所以需要将语言字库文件夹添加到系统变量中。
即需在新建变量中增加一个TESSDATA_PREFIX变量名,变量值为你的安装路径加tessdata,比如D:\tpsb\tessdata,具体如下:

配置完后就可以在命令行输入 WIN+R 打开cmd :输入 tesseract -v ,出现版本信息,则配置成功。
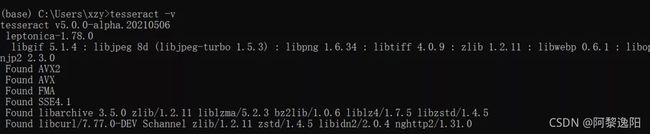
但是有些朋友在python中调用tesseract进行图片识别时还是会报错,建议把pytesseract.py文件中的tesseract_cmd做如下修改:

其中tesseract_cmd中的路径为你安装tesseract软件的路径。
二、识别英文和数字
软件安装和配置好后,就可以进行图片识别啦。首先来看下用python识别简单的数字图片,效果怎么样,具体图片如下:
![]()
python语句如下:
import os
import sys
import pytesseract
from PIL import Image
os.chdir(r'F:\公众号\25.图片识别')
text=pytesseract.image_to_string(Image.open('2_date.png'))
print(text)
得到结果:

可以发现数字的识别结果和原图是完全一致的,这种数字识别可以应用在验证码的识别中。接下来看下常见的由英文表头和数字内容组成的图片表格,这种类型图片的识别效果。
python识别语句如下:
text=pytesseract.image_to_string(Image.open('4_date.png'))
print(text)
得到结果:

查看text类型会发现text是一个字符串,需要进一步处理成我们分析用的表格。具体语句如下:
import pandas as pd
data = pd.DataFrame(text.split('\n'))
data_1 = pd.DataFrame((x.split(' ') for x in data[0]))
得到结果:
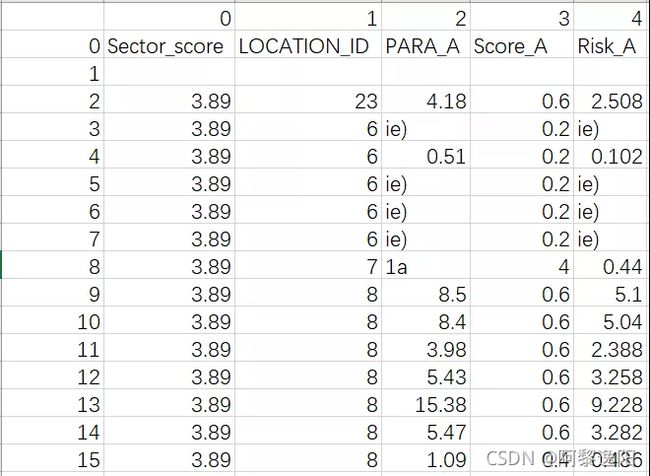
从以上图片可以发现,识别的结果还是存在一些问题,比如把0识别成了ie),多加了一些行等。所以最终的结果可能需要人工智能一下。对比一下我常用的图片转excel网站结果,感兴趣的可以自己测试一下,网址如下:
https://xpdf.net/ocr-images-to-excel
得到结果:
会发现网上自动识别结果也存在一些问题,不过比一个一个手敲数据要好很多。以上讲的都是英文和数字的识别,要想识别中文可以选择加载相应的中文包,也可以调用百度API。
三、识别中文
本文介绍加载相应的中文包进行中文识别,可以选择到官网https://github.com/tesseract-ocr/tessdata/blob/master/chi_sim.traineddata去下载,可是速度实在是太慢,有时根本打不开。
也可以选择到公众号中回复“文字识别中文包”免费获取网盘下载链接,速度依然慢,我测试过要半小时左右。下载后解压缩,把文件夹中的东西复制到安装目录“D:\tpsb\tessdata”下即可(你复制的路径要替换成安装目录)。
假设我们要识别的图片如下:

python识别代码:
import os
import sys
import pytesseract
from PIL import Image
os.chdir(r'F:\公众号\25.图片识别')
text=pytesseract.image_to_string(Image.open('1_诗.png'),lang='chi_sim')
print(text)
识别结果:

可以发现猿啸哀的啸识别成了喝,长江滚滚来识别成了长江木,最后一句也存在一定的问题。下一篇文章我们一起来探索调用百度AI的文字识别功能,对比来看哪一种方式的识别效果好。
参考文献
https://blog.csdn.net/xiaxianba/article/details/89450855
https://blog.csdn.net/qiushi_1990/article/details/78041375
https://www.cnblogs.com/my-blogs-for-everone/p/10637225.html
你可能感兴趣:
用Python绘制皮卡丘
用Python绘制词云图
Python人脸识别—我的眼里只有你
Python画好看的星空图(唯美的背景)
【Python】情人节表白烟花(带声音和文字)
用Python中的py2neo库操作neo4j,搭建关联图谱
Python浪漫表白源码合集(爱心、玫瑰花、照片墙、星空下的告白)
