MYSQL 基础篇
一、mysql 的初识
MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,属于 Oracle 旗下产品。MySQL 是最流行的关系型数据库管理系统之一,在 WEB 应用方面,MySQL是最好的 RDBMS (Relational Database Management System,关系数据库管理系统) 应用软件之一。
MySQL是一种关系型数据库管理系统,关系数据库将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高了灵活性。【以上内容来之百度百科】
MYSQL 数据库是我在日常用的最多的数据库。
二、MYSQL 默认数据库
mysql 默认数据库分类:
- information_schema
- performance_schema
- mysql
1、informance_schema
- 保存了MySQL服务所有数据库的信息;
- 具体MySQL服务有多少个数据库,各个数据库有哪些表,各个表中的字段是什么数据类型,各个表中有哪些索引,各个数据库要什么权限才能访问;
2、mysql
- 保存MySQL的权限、参数、对象和状态信息;
- 如哪些user可以访问这个数据、DB参数、插件、主从;
3、performance_schema
- 主要用于收集数据库服务器性能参数;
- 提供进程等待的详细信息,包括锁、互斥变量、文件信息;
- 保存历史的事件汇总信息,为提供MySQL服务器性能做出详细的判断;
- 对于新增和删除监控事件点都非常容易,并可以随意改变mysql服务器的监控周期,例如(CYCLE、MICROSECOND);
三、MYSQL 的数据类型
主要有五大类:
- 整数类型:BIT、BOOL、TINY INT、SMALL INT、MEDIUM INT、 INT、 BIG INT
- 浮点数类型:FLOAT、DOUBLE、DECIMAL
- 字符串类型:CHAR、VARCHAR、TINY TEXT、TEXT、MEDIUM TEXT、LONGTEXT、TINY BLOB、BLOB、MEDIUM BLOB、LONG BLOB
- 日期类型:Date、DateTime、TimeStamp、Time、Year
- 其他数据类型:BINARY、VARBINARY、ENUM、SET、Geometry、Point、MultiPoint、LineString、MultiLineString、Polygon、GeometryCollection等
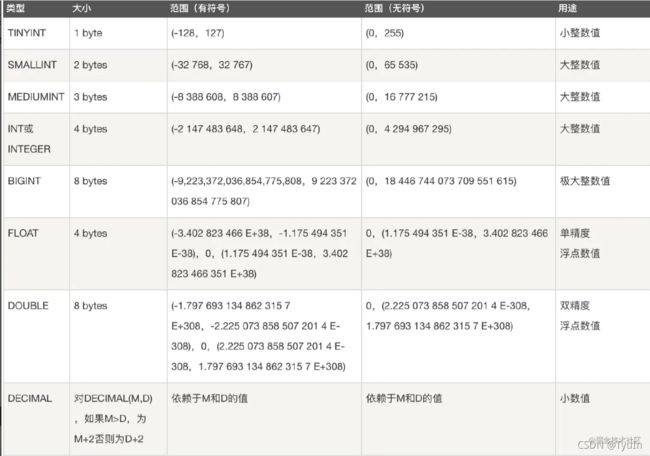
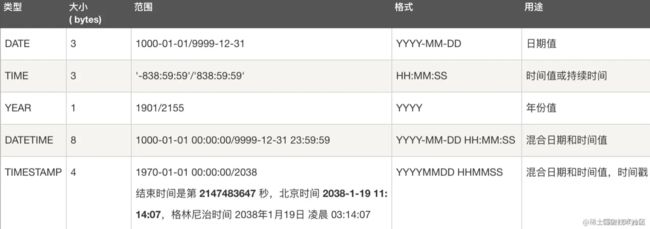

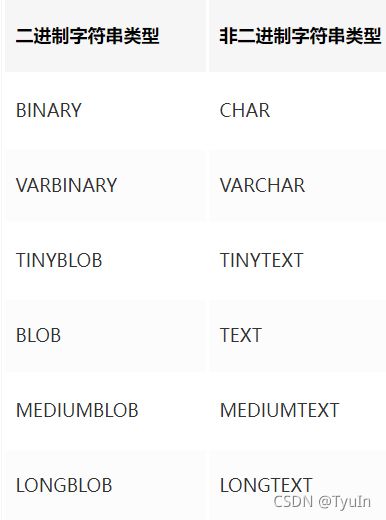
这里就不展开说了,下面简单说一下下面的两点知识:
(1)UNSIGNED
一般整数都支持正负值,不过可以使用可选的属性UNSIGNED,使其不允许负值,这样的话,可以使用存储的正数上限提高一倍,比如TINYINT的范围由-128~127变为0~255。
CREATE TABLE test_int(
id int unsigned not null ## 范围 0~255
);
(2)AUTO_INCREMENT
对整数类型,在创建数据表时,可以指定AUTO_INCRMENT属性,让该字段可以变成一个可以自动增长的序列,如:
CREATE TABLE test_int(
id INT UNSIGNED NOT NULL AUTO_INCRMENT PRIMARY KEY,
name VARCHAR(32) NOT NULL
);
三、DDL、DML、DCL、DQL及TCL
(1)数据定义语言(Data Definition Language),即SQL DDL,用于定义SQL模式、基本表、视图、索引等结构。
关键词: create,alter, drop, truncate(删除当前表再新建一个一模一样的表结构)
(2)数据操纵语言(Data Manipulation Language),即SQL DML。数据操纵分成数据查询和数据更新两类。
关键词:insert update delete
(3)数据查询语言(Data Query Language),即SQL DQL。
select ...
from student
where 条件
group by 分组字段
having 条件
order by 排序字段
执行顺序: from -> where -> group by -> having -> order by -> select
(4)数据控制语言(Data Control Language),即SQL DCL,这一部分包括对基本表和视图的授权、完整性规则的描述、事务
(5)TCL(Transaction Control Language):事务控制语言
set autocommit=0、start transaction、savepoint、commit、rollback
四、创建和使用数据库
1、查看命令
SHOW DATABASES; # 查看所有数据
use userdb; # 使用数据库
CREATE DATABASE menagerie; # 创建数据库
# CREATE DATABASE 数据库名称 DEFAULT CHARSET utf8 COLLATE utf8_general_ci; # utf-8
SHOW TABLES; # 查看当前使用的数据库中的所有表
查看表的创建语句:show create table 表名;
2、数据库表的基本操作
CREATE TABLE pet (
pid int primary key auto_increment comment '宠物id', # 设置id为主键,自动增长
name VARCHAR(20) not null comment '宠物名', # 设置非空
owner VARCHAR(20) comment '宠物主人',
species VARCHAR(20) comment '宠物类别',
sex CHAR(1) defalut '男' comment '宠物性别', # 设置默认值
birth DATE comment '宠物生日'
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
# 创建pet表,表的字段信息 指定对应的存储引擎【可不写,默认使用的就是 InnoDB 】及编码格式
# 对于自增可以设置步长和起始值
-- 下面的代码是对 session 会话变量的操作
-- 服务器为每个连接的客户端维护一系列会话变量。在客户端连接时,使用相应全局变量的当前值对客户端的会话变量进行初始化。会话变量的作用域与用户变量一样,仅限于当前连接。
show session variables like 'auto_inc%';
set session auto_increment_increment=2;
set session auto_increment_offset=10;
-- 下面的代码是对 global 全局变量的操作,全局变量影响服务器整体操作。当服务器启动时,它将所有全局变量初始化为默认值。
show global variables like 'auto_inc%';
set global auto_increment_increment=2;
set global auto_increment_offset=10;
-- 查询任意的
show variables like 'auto_inc%';
# 主键,一种特殊的唯一索引,不允许有空值,如果主键使用单个列,则它的值必须唯一,如果是多列,则其组合必须唯一。
如: nid int primary key auto_increment
或: primary key(nid)
# 外键,一个特殊的索引,只能是指定内容
语法: constraint 外键名 foreign key (给该表的哪个字段设置外键) references 关联的数据表(对应的字段)
注意: 关联表中的字段必须为 主键
如: constraint fk_cc foreign key (color_id) references color(nid)
- 创建表成功后通过下面的命令查看表的结构
DESCRIBE pet; # 查看数据库表的结构 desribe
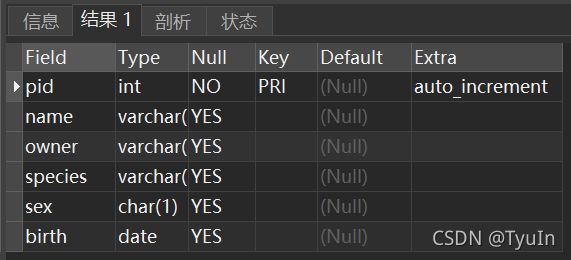
- 删除数据库表和清空数据库表
drop table 表名 # 删除表
delete from 表名 # 清空表
truncate table 表名 # 清空表
-- 具体的写法如下:
1、 drop table 表名称 eg: drop table dbo.Sys_Test
2、 truncate table 表名称 eg: truncate table dbo.Sys_Test
3、 delete from 表名称 where 列名称 = 值 eg: delete from dbo.Sys_Test where test='test'
三者的比较
1、drop(删除表):删除内容和定义,释放空间。简单来说就是把整个表去掉.以后要新增数据是不可能的,除非新增一个表。 drop 语句将删除表的结构被依赖的约束( constrain ),触发器( trigger ),索引( index );依赖于该表的存储过程/函数将被保留,但其状态会变为: invalid 。
2、truncate(清空表中的数据):删除内容、释放空间但不删除定义(保留表的数据结构)。与 drop 不同的是,只是清空表数据而已。
注意: truncate 不能删除行数据,要删就要把表清空。
3、delete(删除表中的数据): delete 语句用于删除表中的行。 delete 语句执行删除的过程是每次从表中删除一行,并且同时将该行的删除操作作为事务记录在日志中保存,以便进行进行回滚操作。
truncate 与 不带 where 的 delete :只删除数据,而不删除表的结构(定义)
4、truncate table删除表中的所有行,但表结构及其列、约束、索引等保持不变。新行标识所用的计数值重置为该列的种子。如果想保留标识计数值,请改用 delete。
如果要删除表定义及其数据,请使用 drop table 语句。
5、对于由 foreign key 约束引用的表,不能使用 truncate table ,而应使用不带 where 子句的 delete 语句。由于 truncate table 记录在日志中,所以它不能激活触发器。
6、执行速度,一般来说:drop> truncate > delete。
7、delete语句是数据库操作语言(DML),这个操作会放到 rollback segement 中,事务提交之后才生效;如果有相应的 trigger,执行的时候将被触发。
truncate、 drop是数据库定义语言(DDL),操作立即生效,原数据不放到 rollback segment 中,不能回滚,操作不触发 trigger。
- 修改表信息
添加列: alter table 表名 add 列名 类型
删除列: alter table 表名 drop column 列名
修改列: alter table 表名 modify column 列名 类型; -- 类型
alter table 表名 change 原列名 新列名 类型; -- 列名,类型
# 例子
alter table MyClass add passtest int(4) default '0';
alter table Person drop column age,drop column address;
# 修改字段的注释
alter table `student` modify column `id` comment '学号';
添加主键: alter table 表名 add primary key(列名);
删除主键: alter table 表名 drop primary key;
alter table 表名 modify 列名 int, drop primary key;
添加外键: alter table 从表 add constraint 外键名称(形如:FK_从表_主表) foreign key 从表(外键字段) references 主表(主键字段);
删除外键: alter table 表名 drop foreign key 外键名称
修改默认值: alter TABLE testalter_tbl ALTER i SET DEFAULT 1000;
删除默认值: alter TABLE testalter_tbl ALTER i DROP DEFAULT;
# 加索引
# alter table 表名 add index 索引名 (字段名1[,字段名2 …]);
alter table employee add index emp_name (name);
# 加主关键字的索引
# alter table 表名 add primary key (字段名);
alter table employee add primary key(id);
# 加唯一限制条件的索引
# alter table 表名 add unique 索引名 (字段名);
alter table employee add unique emp_name2(cardnumber);
# 删除某个索引
# alter table 表名 drop index 索引名;
alter table employee drop index emp_name;
3、数据库表的关系
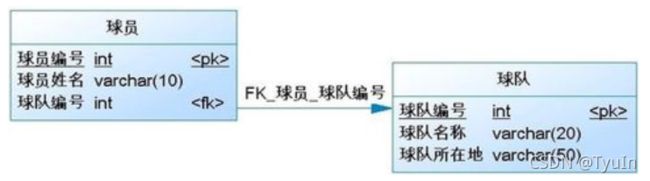
3.1 关联映射:一对多/多对一
存在最普遍的映射关系,简单来讲就如球员与球队的关系;
一对多:从球队角度来说一个球队拥有多个球员 即为一对多
多对一:从球员角度来说多个球员属于一个球队 即为多对一
数据表间一对多关系如下图:
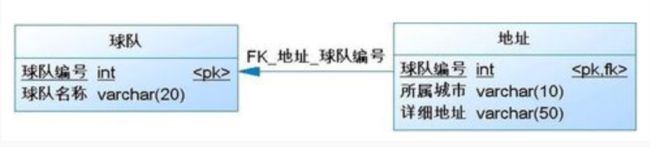
3.2 关联映射:一对一
一对一关系就如球队与球队所在地址之间的关系,一支球队仅有一个地址,而一个地址区也仅有一支球队。
数据表间一对一关系的表现有两种,一种是外键关联,一种是主键关联。图示如下:
- 一对一外键关联:
- 一对一主键关联:要求两个表的主键必须完全一致,通过两个表的主键建立关联关系

3.3 关联映射:多对多
多对多关系也很常见,例如学生与选修课之间的关系,一个学生可以选择多门选修课,而每个选修课又可以被多名学生选择。
数据库中的多对多关联关系一般需采用中间表的方式处理,将多对多转化为两个一对多:
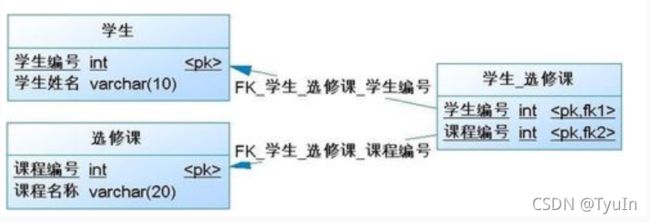
4、数据表之间的约束
约束是一种限制,它通过对表的行或列的数据做出限制,来确保表的数据的完整性、唯一性。
常见的几种约束:

主键(PRIMARY KEY)是用于约束表中的一行,作为这一行的标识符,在一张表中通过主键就能准确定位到一行,因此主键十分重要。主键要求这一行的数据不能有重复且不能为空。
还有一种特殊的主键——复合主键。主键不仅可以是表中的一列,也可以由表中的两列或多列来共同标识
默认值约束(DEFAULT)规定,当有DEFAULT约束的列,插入数据为空时该怎么办。
DEFAULT约束只会在使用INSERT语句时体现出来,INSERT语句中,如果被DEFAULT约束的位置没有值,那么这个位置将会被DEFAULT的值填充
唯一约束(UNIQUE)比较简单,它规定一张表中指定的一列的值必须不能有重复值,即这一列每个值都是唯一的。
当INSERT语句新插入的数据和已有数据重复的时候,如果有UNIQUE约束,则INSERT失败。
外键(FOREIGN KEY)既能确保数据完整性,也能表现表之间的关系。
一个表可以有多个外键,每个外键必须REFERENCES(参考)另一个表的主键,被外键约束的列,取值必须在它参考的列中有对应值。
在INSERT时,如果被外键约束的值没有在参考列中有对应,比如以下命令,参考列(department表的dpt_name)中没有dpt3,则INSERT失败。
非空约束(NOT NULL)听名字就能理解,被非空约束的列,在插入值时必须非空。
在MySQL中违反非空约束,不会报错,只会有警告。
五、数据库表的基本操作(增删查改)
1、 增
# 插入单行数据
insert into 表 (列名,列名...) values (值,值,值...)
# 插入多行数据
insert into 表 (列名,列名...) values (值,值,值...),(值,值,值...)
# 复制子表数据
insert into 表 (列名,列名...) select (列名,列名...) from 表
# 简化写法 (下面的写法需要将所有字段都赋值)
insert into 表 values (值,值...)
2、删
# 清空表的数据
delete from 表
# 根据条件删除表中对应的数据
delete from 表 where id=1 and name='alex'
3、改
# 根据条件修改对应的数据
update 表 set name = 'alex' where id>1
4、查
select <目标列表达式列表>
[into 新表名]
from 表名或视图名
[where <条件>]
[group by <分组表达式>]
[having <条件>]
[order by <排序表达式>[ASC|DESC]]
# 查询表中所有的数据
select * from 表
# 根据条件进行查询
select * from 表 where id > 1
# 根据条件查询表对应字段信息
select nid,name,gender as gg from 表 where id > 1
# 多个条件查询
select * from 表 where id > 1 and name != 'alex' and num = 12;
# 范围查询 between ... and ...
select * from 表 where id between 5 and 16;
# 范围查询 in(...)
select * from 表 where id in (11,22,33)
select * from 表 where id not in (11,22,33)
select * from 表 where id in (select nid from 表)
# 限制 limit
select * from 表 limit 5; # 前5行
select * from 表 limit 4,5; # 从第4行开始的5行
select * from 表 limit 5 offset 4 # 从第4行开始的5行
# 消除查询结果中的重复行
select distinct <字符型字段>[,<字符型字段>,...] from tb_name;
# 使用null的查询
select * from tb_name where <字符型字段> is [not] null;
# 数据排序(查询) order by
select * from 表 order by 列 asc # 根据 “列” 从小到大排列
select * from 表 order by 列 desc # 根据 “列” 从大到小排列
select * from 表 order by 列1 desc,列2 asc # 根据 “列1” 从大到小排列,如果相同则按列2从小到大排序
# 模糊查询 like
select * from 表 where name like 'ale%' # ale开头的所有(多个字符串) 如:alekkkk alek
select * from 表 where name like '%ale' # 以ale结尾的所有 如:kkale aaaale
select * from 表 where name like '%al%' # 查询含有 al 的所有 如:ccale acaleaa
select * from 表 where name like 'ale_' # ale开头的所有(一个字符) 如:alea alek
# 聚集函数查询
COUNT(e1) # e1为一个表达式,可以是任意的数据类型 -> 返回e1指定列不为空的记录总数
SUM(e1) # 对e1指定的列进行求和计算
MIN(e1) # MIN(e1)返回e1表达式指定的列中最小值;
MAX(e1) # MAX(e1)返回e1表达式指定的列中最大值;
AVG(e1) # 对e1表达式指定的列,求平均值。
# 首先,根据e1表达式指定的列,对值进行排序;
# 若排序后,总记录为奇数,则返回排序队列中,位于中间的值;
# 若排序后,总记录为偶数,则对位于排序队列中,中间两个值进行求平均,返回这个平均值;
MEDIAN(e1)
# 通用数据库函数
1、 CONCAT(A, B) – 连接两个字符串值以创建单个字符串输出。通常用于将两个或多个字段合并为一个字段。
2、 FORMAT(X, D)- 格式化数字 X 到 D 有效数字。
3、 CURRDATE(), CURRTIME()- 返回当前日期或时间。
4、 NOW() – 将当前日期和时间作为一个值返回。
5、 MONTH(), DAY( ), YEAR(), WEEK(), WEEKDAY() – 从日期值中提取给定数据。
6、 HOUR(), MINUTE(), SECOND() – 从时间值中提取给定数据。
7、 DATEDIFF( A, B) – 确定两个日期之间的差异, 通常用于计算年龄
8、 SUBTIMES( A, B) – 确定两次之间的差异。
9、 FROMDAYS( INT) – 将整数天数转换为日期值。
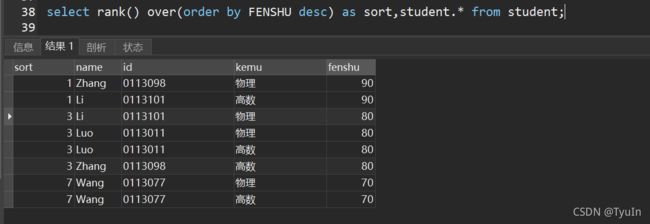
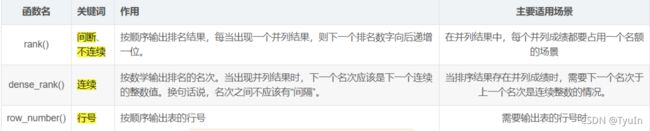
- RANK
1)用法1:RANK OVER
语法:RANK() OVER ([PARTITION BY column1] ORDER BY column2 [ASC|DESC])
为分析函数,为每条记录产生一个序列号,并返回。
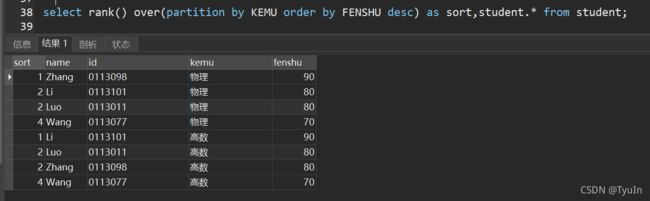
参数:column1为列名,指定按照哪一列进行分类(分组)
column2为列名,指定根据哪列排序,默认为升序;
若指定了分类子句(PARTITION BY),则对每类进行排序(每个分类单独排序)
返回:返回一个数值类型数据,作为该记录的序号!
作用:为分析函数,对记录先按column1分类,再对每个分类进行排序,并为每条记录分配一个序号(每个分类单独排序)
注意:排序字段值相同的记录,分配相同的序号。存在序号不连续的情况
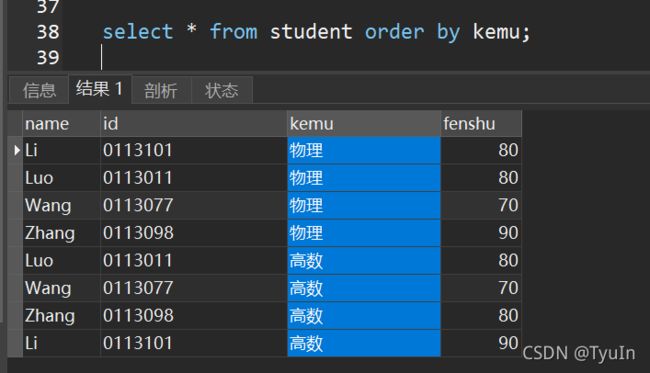
# row_number() 它是将某字段按照顺序依次添加行号。如1、2、3、4
SELECT Score,row_number() over(ORDER BY Score desc) as 'Rank' FROM score;
# 分组排序
SELECT Score,row_number() over(partition by xxx ORDER BY Score desc) as 'Rank' FROM score;
# dense_rank() dense_rank() 排序数字是连续的、不间断。当有相同的分数时,它们的排名结果是并列的,例如,1、2、2、3、4。
SELECT Score,dense_rank() over(ORDER BY Score desc) as 'Rank' FROM score;
# 分组排序
SELECT Score,dense_rank() over(partition by xxx ORDER BY Score desc) as 'Rank' FROM score;
# 分组查询
- 分组
select num from 表 group by num
select num,nid from 表 group by num,nid
select num,nid from 表 where nid > 10 group by num,nid order nid desc
select num,nid,count(*),sum(score),max(score),min(score) from 表 group by num,nid
select num from 表 group by num having max(id) > 10
特别的:group by 必须在where之后,order by之前
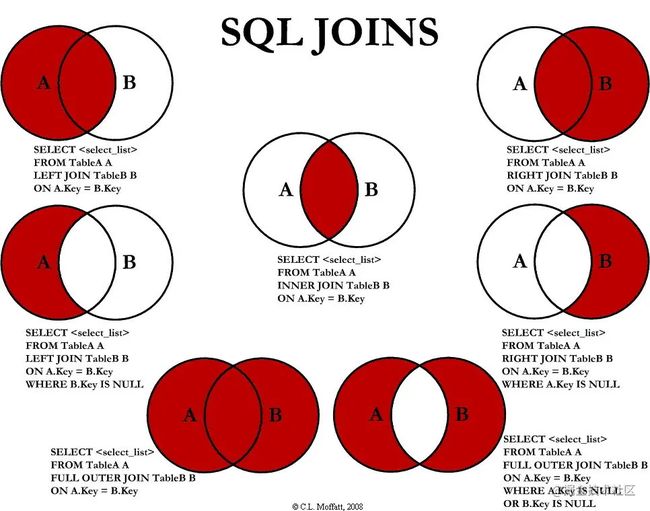
# 多表查询
a、连表
无对应关系则不显示
select A.num, A.name, B.name
from A,B
Where A.nid = B.nid
无对应关系则不显示
select A.num, A.name, B.name
from A inner join B
on A.nid = B.nid
A表所有显示,如果B中无对应关系,则值为null
select A.num, A.name, B.name
from A left join B
on A.nid = B.nid
B表所有显示,如果B中无对应关系,则值为null
select A.num, A.name, B.name
from A right join B
on A.nid = B.nid
b、组合
组合,自动处理重合
select nickname
from A
union
select name
from B
组合,不处理重合
select nickname
from A
union all
select name
from B