算法-分支限界法
回溯法是深度优先策略遍历问题的解空间树。分支限界法按广度优先策略遍历问题的解空间树,在遍历过程中对已经处理的每一个节点根据衔接函数估算目标函数的可能取值,从中选取使目标函数取得极值(极大或极小)的节点优先进行广度优先搜索,从而不断调整搜索方向,尽快找到问题的解。
概述
解空间树的动态搜索
分支限界法首先确定一个合理的限界函数,并根据限界函数确定目标函数的界[down,up],然后,按照广度优先策略遍历问题的解空间树,在分支节点上,一次搜索该节点的所有孩子节点,分别估算这些孩子节点的目标函数的可能取值,如果某孩子节点的目标函数可能取得的值超出目标函数的界,则将其丢弃,因为从某个节点生成的解不会比目前已经得到的解更好;否则,将其加入待处理节点表(简称为PT)中。依次从表PT中选取使目标函数的值取得极值的节点成为当前的扩展节点,重复上述过程,直到找到最优解。
使用分支限界法求解0/1问题

- 按照物品单位重量价值从大到小排序
- 目标函数:ub=v + (W - w)*(vi+1/wi+1),代表价值的上限
- 从物品1开始,不断选择物品放入背包,需要检查空间是否合适,如果空间合适,计算目标函数和节点一同放入PT中。然后从PT中选择目标函数最大的节点,继续选择物品,直到计算出结果。
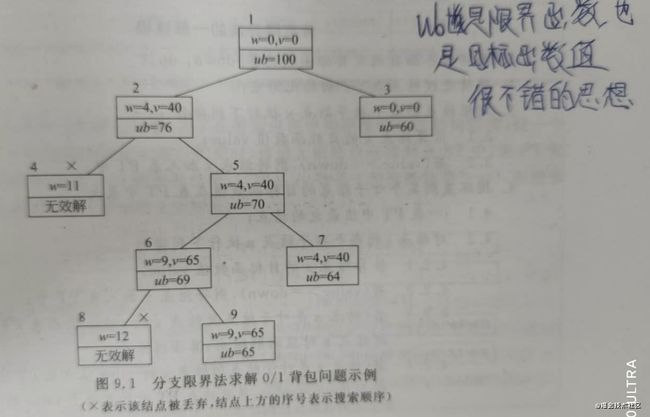
分支限界法的设计思想
假设求解最大化问题,问题的解向量为X=(x1,x2,……,xn),其中,xi的取值范围为某个有穷集合Si,|Si|=ri(1<=i<=n)。在使用分支限界法搜索问题的解空间树时,首先根据限界函数估算目标函数的界[down,up],然后从根节点出发,扩展根节点的r1个孩子节点,从而构成分量x1的r1种可能的取值方式。对这r1个孩子几点分别估算可能取得的目标函数值bound(x1),其含义是以该孩子节点为根的子树锁可能取得的目标函数值不大于bound(x1),也就是部分解应满足:
bound(x1)>=bound(x1,x2)>=……>=bound(x1,x2,……,xn)
若某孩子节点的目标函数值超出目标函数的界,则将该孩子节点丢弃;否则,将该孩子节点保存在待处理节点表PT中。从表PT中选取使目标函数取得极大值的节点作为下一次扩展的根节点,重复上述过程,当到达一个叶子节点时,就得到了一个可行解X=(x1,x2,……,xn)及其目标函数值bound(x1,x2,……,xn)。如果bound(x1,x2,……,xn)是表PT中目标函数值最大的节点,则bound(x1,x2,……,xn)就是所求问题的最大值,(x1,x2,……,xn)就是问题的最优解;如果bound(x1,x2,……,xn)不是表PT中目标函数值最大的节点,说明还存在某个部分解对应的节点,其上界大于bound(x1,x2,……,xn)。于是,用bound(x1,x2,……,xn)调整目标函数的下界,即令down=bound(x1,x2,……,xn),并将表PT中超出目标函数下界down的节点删除,然后选取目标函数值取得极大值的节点作为下一次扩展的根节点,继续搜索,直到某个叶子节点的目标函数值在表PT中最大。
这个设计思想讲述了分支限界法的本质,大家一定要充分的理解。
应用分支限界法的关键问题是:
-
如何确定合适的限界函数
分支限界法在遍历过程中根据限界函数估算某节点的目标函数的可能取值,一定要设计出好的限界函数。
-
如何组织待处理节点表
表PT可以采用堆的形式,也可以采用优先队列的形式
-
如何确定最优解中的各个分量
- 对每个扩展节点保存根节点到该节点的路径
- 在搜索过程中构建搜索经过的树结构,在求得最优解时,从叶子节点不断回溯到根节点,以确定最优解中的各个分量。
图问题中的分支限界法
TSP问题
TSP问题是指旅行家要旅行n个城市,要求各个城市经历且仅经历一次,然后回到出发城市,并要求所走的路程最短。
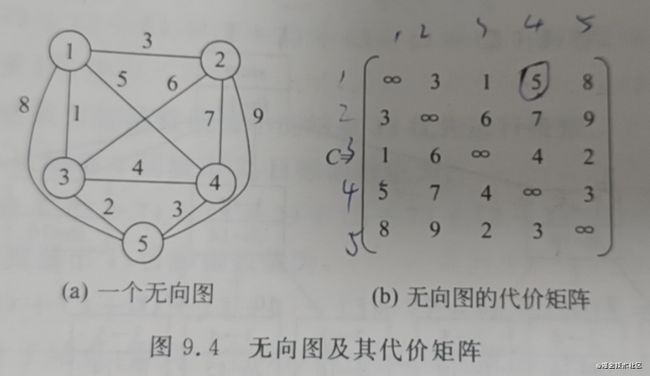
一般情况下,对于一个正在生成的路径,假设已确定的顶点集合U=(r1,r2,……,rk),即路径上已确定了k个顶点,此时,该部分解的目标函数值的计算方法如下:

所以lb的下限为((1+3)+(3+6)+(1+2)+(3+4)+(2+3))/2=14,上限使用贪心法,计算出数值为16,所以限界函数的界为[14,16]。
为什么限界函数是这样的,是因为
- 容易计算,因为每个点都有一条出边,一条入边,计算的时候两倍相加,然后相除,计算起来比较容易
- 可以计算出下限,如果有边(1,3),那么1至3的距离确定了,但是1需要有一条出去的边,一条回来的边,所以,下限是除了到3距离之外的,最小的另一条边。
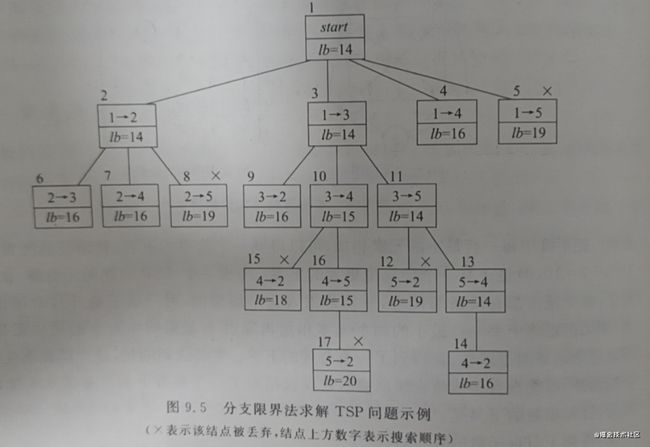
解题过程和伪代码如下:

- 107. 二叉树的层次遍历 II - 简单 代码 这是最简单的广度优先遍历,都没有用到限界函数
多段图的最短路径问题
设图G=(V,E)是一个带权有向连通图,如果把顶点集合V划分成k个互不相交的子集Vi(2<=k<=n,1<=i<=k),使得E中的任何一条边(u,v),必有u属于Vi,v属于Vi+m(1<=i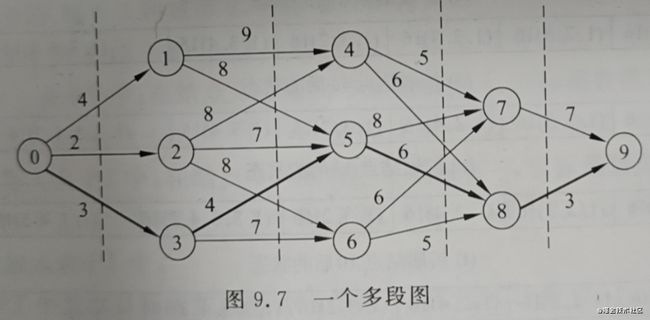
-
确定上下界,下界计算每一段的最小值,2+4+5+3=14,上界使用贪心法0->2->5->8->9,路径代价为18,所以目标函数界为[14,18]
-
假设已经确定了i段,其路径为(r1,r2,……,ri,ri+1),此时限界函数:
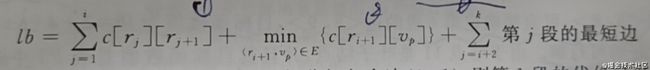
该公式含义是将已经确定的路段相加,然后找到下一个路段最短的连接,然后将再后面每组最短边相加。例如,如果已经确定了走边(0,1),则目标函数为4(已确定的边)+8(从1到4、5的最短边)+5(第三组最小边)+3(第四组最小边) -
每次选取边,如果lb超出了18,则舍弃,如果在范围之内,则放入以lb位置的最小堆结构中,每次选取lb最小节点,进行广度优先遍历,直到获得最终结果。
例题:
- 815. 公交路线 - 困难 代码 这道题也没有使用到限界函数,而且既可以用深度优先也可以用广度优先来实现
组合问题中的分支限界法
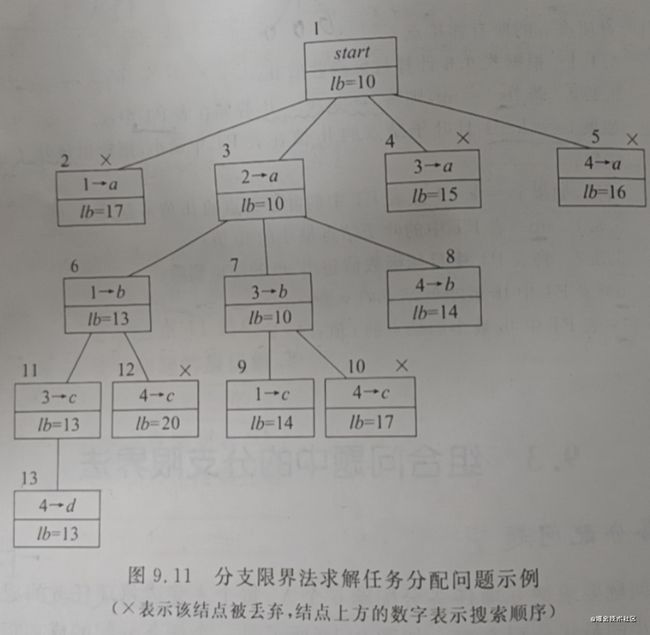
任务分配问题
任务分配问题要求把n项任务分配给n个人,每个人完成每项任务的成本不同,要求分配总成本最小的最优分配分案。

-
确定上下界,下界是每一行最小值2+3+1+4=10,上界使用贪心法计算2+3+5+4=14,所以范围为[10,14]
-
限界函数:设当前已对人员1~i分配了任务,并且获得了成本v,则限界函数可以定义为,
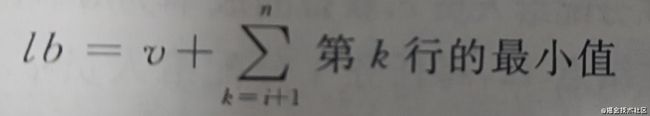
-
使用广度优先遍历,计算lb,如果lb超过上界,则丢弃,如果在范围内,放入最小堆中,每次从中选取最小的lb进行广度优先遍历,直到计算完所有值。
例题
- 690. 员工的重要性 - 简单 代码 这道题也没有用到限界函数,也没有用堆做排序,例题较少
批处理作业调度问题
给定n个作业的集合J={J1,J2,……,Jn},每个作业都有3项任务分别在3台机器上完成,作业Ji需要机器j的处理时间为tij(1<=i<=n,1<=j<=3),每个作业必须先由机器1处理,再由机器2处理,最后由机器3处理。批处理作业调度问题要求确定这n个作业的最优处理顺序,使得从第1个作业在机器1上处理开始,到最优一个作业在机器3上处理结束所需的时间最少。

举个实现的例子,以(J2,J3,J1,J4)的顺序执行,总完成时间为54

另外大家思考一个问题,如果以Ji开始处理,估计处理的最短时间为:
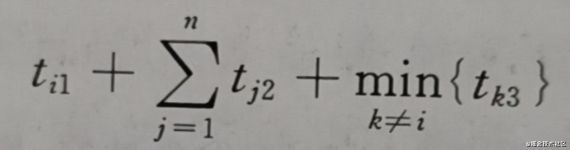
这个公式其实很容易理解,机器1开始工作,需要ti1的时间,然后机器2才能处理J1,这时候机器2不空闲,时间最短,当所有任务在机器2完成后,最后完成的任务,在机器3上执行。所以最短时间由这三段组成。
大家如果了解了这个,那么目标函数值就很容易理解了。
对于一个已安排的作业集合M是{1,2,……,n}的子集,|M|=k,即已安排了k个作业,设sum1[k]表示机器1完成k个作业的处理时间,sum2[k]表示机器2完成k个作业的处理时间,现在要处理作业k+1,此时,该部分解的目标函数值的下界计算方法如下:
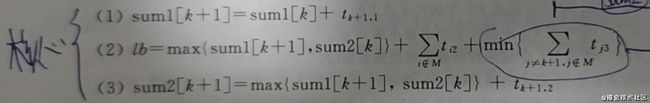
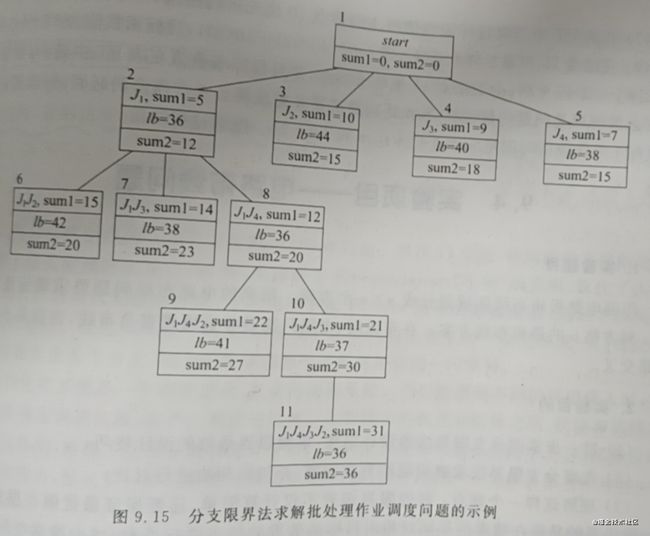
分支限界法的搜索过程为:
- 207. 课程表 - 中等 代码
总结
分支限界法也是有套路,先确认上下界,然后找出合理的限界函数,最后就是使用广度优先遍历,按照限界函数计算出的数值进行排序,每次选取最小/最大值进行下一次的广度优先遍历。
乐扣里的题目很少有需要使用到限界函数的,不过有一些题需要更多的技巧。本章中的题大家可以联系一下,中等难度的题就问题不大了。
最后
大家如果喜欢我的文章,可以关注我的公众号(程序员麻辣烫)
我的个人博客为:https://shidawuhen.github.io/

往期文章回顾:
算法
- 算法学习计划
- 蛮力法
- 分治法
- 减治法
- 动态规划法
- 贪心法
- 回溯法
- 分支限界法
- 算法总结
技术
- 微服务之服务框架和注册中心
- Beego框架使用
- 浅谈微服务
- TCP性能优化
- 限流实现1
- Redis实现分布式锁
- Golang源码BUG追查
- 事务原子性、一致性、持久性的实现原理
- CDN请求过程详解
- 记博客服务被压垮的历程
- 常用缓存技巧
- 如何高效对接第三方支付
- Gin框架简洁版
- InnoDB锁与事务简析
读书笔记
- 敏捷革命
- 如何锻炼自己的记忆力
- 简单的逻辑学-读后感
- 热风-读后感
- 论语-读后感
- 孙子兵法-读后感
思考
- 对项目管理的一些看法
- 对产品经理的一些思考
- 关于程序员职业发展的思考
- 关于代码review的思考
- Markdown编辑器推荐-typora