我免费为公司搭建了一套人脸识别打卡系统
打卡,是踩点上班人的噩梦。
由于我们公司是老土的指纹机打卡,对于踩点上班的“我们”打卡浪费的时间实在是太多了,
难免会出现迟到的状况
所以,我打算干一件大事,就是为公司搭建一套人脸识别打卡系统
人脸识别的实际应用
人脸识别目前正被用于让世界更安全、更智能、更方便。
有几个用例:
- 寻找失踪人员
- 零售犯罪
- 安全标识
- 识别社交媒体上的帐户
- 考勤系统
- 识别汽车中的驾驶员
根据性能和复杂性,有多种方法可以执行面部识别。
传统人脸识别算法:
在 1990 年代,整体方法被用于人脸识别。手工制作的局部描述符在 1920 年代初期开始流行,然后在 2000 年代后期采用局部特征学习方法。目前广泛使用并在OpenCV中实现的算法如下:
- Eigenfaces (1991)
- Local Binary Patterns Histograms (LBPH) (1996)
- Fisherfaces (1997)
- Scale Invariant Feature Transform (SIFT) (1999)
- Speed Up Robust Features (SURF) (2006)
每种方法都遵循不同的方法来提取图像信息并将其与输入图像进行匹配。
Fischer-faces和Eigenfaces与 SURF 和 SIFT 具有几乎相似的方法。
LBPH 是一种简单但非常有效的方法,但与现代人脸识别器相比,速度较慢。
与现代人脸识别算法相比,这些算法并不快。传统算法不能仅通过拍摄一个人的单张照片来训练。
人脸识别深度学习:
一些广泛使用的基于深度学习的人脸识别系统如下:
- DeepFace
- DeepID series of systems
- VGGFace
- FaceNet
人脸识别器一般采用人脸图像,找出重要的点,如嘴角、眉毛、眼睛、鼻子、嘴唇等。这些点的坐标称为五官点,这样的点有66个。这样,寻找特征点的不同技术给出不同的结果。
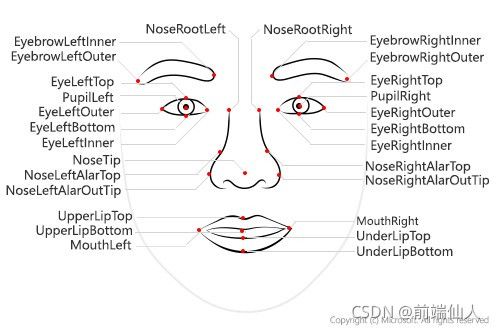
人脸识别模型涉及的步骤:
- 人脸检测:定位人脸并在人脸周围绘制边界框并保留边界框的坐标。
- 人脸对齐:标准化人脸以与训练数据库一致。
- 特征提取:提取将用于训练和识别任务的人脸特征。
- 人脸识别: 将人脸与准备好的数据库中的一张或多张已知人脸进行匹配。
在传统的人脸识别方法中,我们有单独的模块来执行这 4 个步骤,这很痛苦。- 在本文中,您将看到一个将所有这 4 个步骤组合在一个步骤中的库。
构建人脸识别系统的步骤
安装库
我们需要安装 2 个库来实现人脸识别。
dlib : Dlib
是一个现代 C++ 工具包,包含机器学习算法和
工具,用于在 C++ 中创建复杂的软件以解决实际问题。
# 安装 dlib
pip install dlib
脸部识别:将face_recognition库,创建和维护 Adam Geitgey,包裹周围 DLIB面部识别功能。
# 安装人脸识别
pip install face recognition
Opencv用于一些图像预处理。
#安装opencv
pip install opencv
注意:如果在安装dlib 时遇到任何错误 ,我建议你使用vs_code 社区安装 C++ 开发工具包
导入库
现在您已经下载了所有重要的库,让我们导入它们来构建系统。
import cv2
import numpy as np
import face_recognition
加载图像
导入库后,你需要加载图像。
face_recognition库以 BGR 的形式加载图像,为了打印图像,你应该使用 OpenCV 将其转换为 RGB。
imgelon_bgr = face_recognition.load_image_file('elon.jpg')
imgelon_rgb = cv2.cvtColor(imgelon_bgr,cv2.COLOR_BGR2RGB)
cv2.imshow ('bgr', imgelon_bgr)
cv2.imshow('rgb', imgelon_rgb)
cv2.waitKey(0)
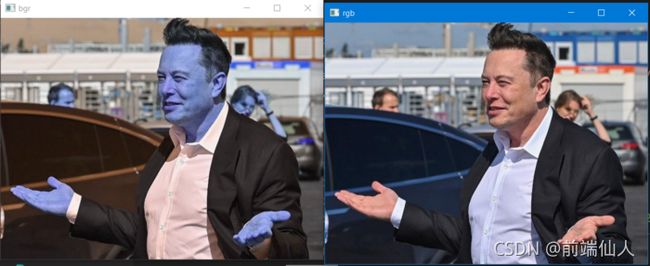
如你所见,RGB 看起来很自然,因此你将始终将通道更改为 RGB。
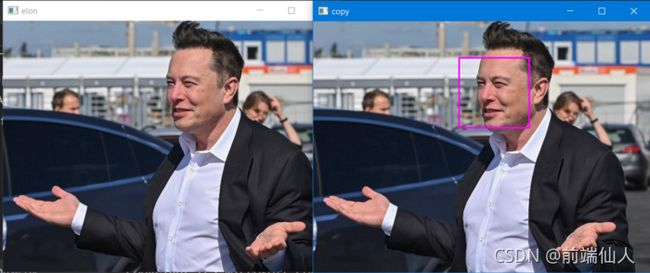
查找人脸位置并绘制边界框
你需要在人脸周围绘制一个边界框,以显示是否已检测到人脸。
imgelon =face_recognition.load_image_file('elon.jpg')
imgelon = cv2.cvtColor(imgelon,cv2.COLOR_BGR2RGB)
#----------为绘制边界框寻找人脸位置-------
face = face_recognition.face_locations(imgelon_rgb)[0]
copy = imgelon.copy()
#-------------------绘制矩形-------------------------
cv2.rectangle(copy, (face[3], face[0]),(face[1], face[2]), (255,0,255), 2)
cv2.imshow('copy', copy)
cv2.imshow('elon',imgelon)
cv2.waitKey(0)
为人脸识别训练图像
该库的制作方式是自动查找人脸并仅处理人脸,因此您无需从
图片中裁剪人脸。
训练:
在这个阶段,我们将训练图像转换为一些编码,并使用该图像的人名存储编码。
train_elon_encodings = face_recognition.face_encodings(imgelon)[0]
测试:
为了测试,我们加载图像并将其转换为编码,然后在训练期间将编码与存储的编码进行匹配,这种匹配基于寻找最大相似度。当您找到与测试图像匹配的编码时,您将获得与训练编码相关联的名称。
# 测试一个图像
test = face_recognition.load_image_file('elon_2.jpg')
test = cv2.cvtColor(test, cv2.COLOR_BGR2RGB)
test_encode = face_recognition.face_encodings(test)[0]
print(face_recognition.compare_faces([train_encode],test_encode))
face_recognition.compare_faces返回True如果两个图像中的人相同,则返回False。
构建人脸识别系统
导入必要的库
import cv2
import face_recognition
import os
import numpy as np
from datetime import datetime
import pickle
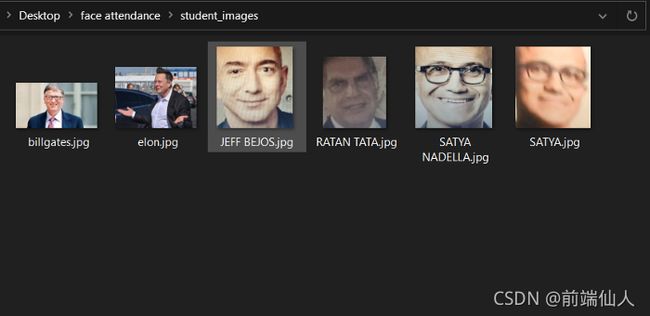
定义将存储训练图像数据集的文件夹路径
path = 'student_images'
注意:对于训练,我们只需要将训练图片放到path目录下,图片名称必须是
person_name.jpg/jpeg格式。
例如:
正如您在我的 student_images 路径中看到的,我有 6 个人。因此我们的模型只能识别这 6 个人。您可以在此目录中添加更多图片,以便更多人识别
- 现在创建一个列表来存储 person_name 和图像数组。
- 遍历路径目录中存在的所有图像文件,读取图像,并将图像数组附加到图像列表,并将文件名附加到classNames。
images = []
classNames = []mylist = os.listdir(path)
for cl in mylist:
curImg = cv2.imread(f'{
path}/{
cl}')
images.append(curImg)
classNames.append(os.path.splitext(cl)[0])
- 创建一个函数来对所有训练图像进行编码并将它们存储在一个变量encoding_face_train 中。
def findEncodings(images):
encodeList = []
for img in images:
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
encoded_face = face_recognition.face_encodings(img)[0]
encodeList.append(encoded_face)
return encodeList
encoded_face_train = findEncodings(images)
- 创建一个函数,该函数将创建一个 Attendance.csv文件来存储考勤时间。
注意:这里需要手动创建Attendance.csv文件并在函数中给出路径
def markAttendance(name):
with open('Attendance.csv','r+') as f:
myDataList = f.readlines()
nameList = []
for line in myDataList:
entry = line.split(',')
nameList.append(entry[0])
if name not in nameList:
now = datetime.now()
time = now.strftime('%I:%M:%S:%p')
date = now.strftime('%d-%B-%Y')
f.writelines(f'n{
name}, {
time}, {
date}')
with open(“filename.csv”,'r+')创建一个文件,'r+'模式用于打开文件进行读写。
我们首先检查参加者的姓名是否已经在参加者的姓名中,我们不会再写出勤了。
如果参加者姓名在参加者.csv 中不可用,我们将写入参加者姓名和函数调用时间。
阅读网络摄像头进行实时识别
# take pictures from webcam
cap = cv2.VideoCapture(0)while True:
success, img = cap.read()
imgS = cv2.resize(img, (0,0), None, 0.25,0.25)
imgS = cv2.cvtColor(imgS, cv2.COLOR_BGR2RGB)
faces_in_frame = face_recognition.face_locations(imgS)
encoded_faces = face_recognition.face_encodings(imgS, faces_in_frame)for encode_face, faceloc in zip(encoded_faces,faces_in_frame):
matches = face_recognition.compare_faces(encoded_face_train, encode_face)
faceDist = face_recognition.face_distance(encoded_face_train, encode_face)
matchIndex = np.argmin(faceDist)
print(matchIndex)
if matches[matchIndex]:
name = classNames[matchIndex].upper().lower()
y1,x2,y2,x1 = faceloc
# since we scaled down by 4 times
y1, x2,y2,x1 = y1*4,x2*4,y2*4,x1*4
cv2.rectangle(img,(x1,y1),(x2,y2),(0,255,0),2)
cv2.rectangle(img, (x1,y2-35),(x2,y2), (0,255,0), cv2.FILLED)
cv2.putText(img,name, (x1+6,y2-5), cv2.FONT_HERSHEY_COMPLEX,1,(255,255,255),2)
markAttendance(name)
cv2.imshow('webcam', img)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
- 仅将识别部分的图像大小调整为 1/4。输出帧将是原始大小。
- 调整大小可提高每秒帧数。
face_recognition.face_locations()在调整大小的图像(imgS)上被调用。对于人脸边界框坐标必须乘以 4 才能覆盖在输出帧上。face_recognition.distance()返回测试图像的距离数组,其中包含我们训练目录中存在的所有图像。- 最小人脸距离的索引将是匹配的人脸。
- 找到匹配的名称后,我们调用
markAttendance函数。 - 使用
cv2.rectangle()绘制边界框。 - 我们使用
cv2.putText()将匹配的名称放在输出帧上。
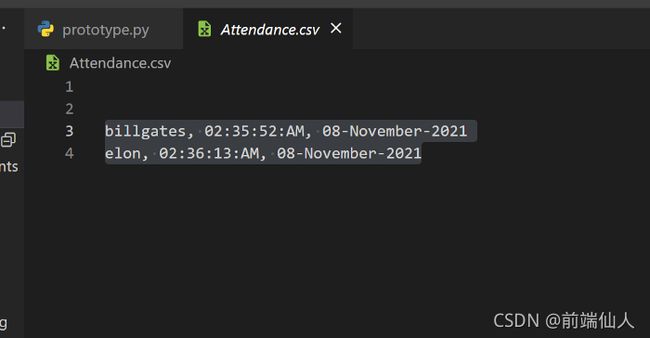
考勤报告
人脸识别系统面临的挑战
尽管构建面部识别看起来很容易,但在没有任何限制的情况下拍摄的现实世界图像中却并不容易。面部识别系统面临的几个挑战如下:
- 照明:它极大地改变了面部外观,观察到照明条件的轻微变化对其结果产生重大影响。
- 姿势:面部识别系统对姿势高度敏感,如果数据库仅在正面视图上进行训练,可能会导致识别错误或无法识别。
- 面部表情:同一个人的不同表情是另一个需要考虑的重要因素。不过,现代识别器可以轻松处理它。
- 低分辨率:识别器的训练必须在分辨率好的图片上进行,否则模型将无法提取特征。
- 老化:随着年龄的增长,人脸的形状、线条、纹理变化是另一个挑战。
结论
在本文中,我们讨论了如何使用face_recognition库创建人脸识别系统并制作了考勤系统。你可以使用Tkinter或Pyqt进一步设计用于人脸识别考勤系统的GUI 。