web自动化测试:xpath/css选择器元素定位和等待
1.xpath元素定位
1.1 为什么要用它?
没有id,name属性
通过class或者tag_name找到的不是唯一的
link_text,partial_link_text只能定位a标签
xpath为什么功能强:
- 支持所有的元素属性
- 支持text文本
- 可以通过标签名
- 可以通过元素之间的关系
- 要素和要素之间可以进行任意形式的组合
1.2 实战当中采取什么样的策略去编写xpath表达式
方法1:通过浏览器找到元素的xpath路径:首先F12,选中元素的html定义代码,鼠标右键->copy,复制Copy XPath相对路径即可。

方法2:使用插件,chrome浏览器的插件chropath可以实现快速查找xpath
建议刚开始学时,自己动手写写,而不要依赖快捷途径获取。
1.3 xpath基础语法
1)绝对路径,相对路径
绝对路径:/开头,不建议使用;
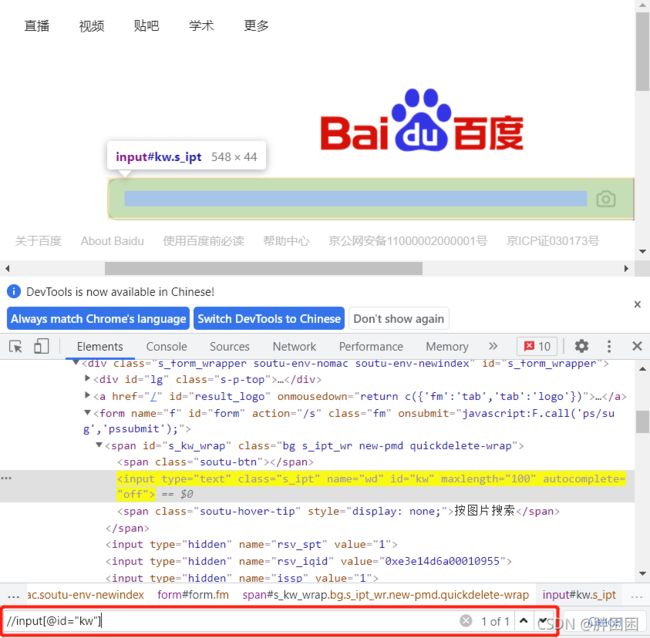
相对路径://开头,//*[@id="kw"],*号代表任意的标签名称,//input[@id="kw"]
[ ]表示条件,@表示属性,id属性名,kw属性值
基本语法://标签名[@属性="属性值"]
xpath验证:在网页中F12后,选中源代码,按键ctrl+ cf,出现xpath输入框,输入需要验证的xpath后回车即可。
2)标签
//input[@id="kw"]
3)属性
//input[@id="kw"]
4)text文本
//a[text()="文本值"]
包含某个文本,contains
//a[contains(text(), "文本值")],以免文本中含有空格等不易察觉的元素
如果返回多个,则可以使用多个条件的组合,
属性或text组合://a[text()="文本值" and @id="属性值" and @name="属性值"]
5)函数
//a[text()="文本值"]
6)索引
如果还是返回多个,则可以通过索引获取(注意:xpath的索引是从1开始的),通过索引获取时,表达式要使用中括号(提高运算优先级),
(//a[text()="文本值"])[1]
7)元素之间的关系
- 父子,//span[@id="s_kw_wrap"]/input[@name="wd"]
通过儿子找父亲,爷爷,//sub/../..
//input[@name="wd"]/../.. ,每向上一层,都要加一个 /..
- 祖先和子孙后代,//form[@id="form"]//input[@name="wd"]
- 同辈

8)轴运算
ancestor,选取当前节点的所有先辈(父、祖父等)。
//input[@name="wd"]/ancestor::form[@id="form"]
following-sibling,选取当前节点之后的所有同级节点(弟弟妹妹)。
//input[@name="wd"]/following-sibling::span[@属性="value"]
preceding-sibling,选取当前节点之前的所有同级节点(哥哥姐姐)。
//input[@name="wd"]/preceding-sibling::span[@属性="value"]
1.4 练习
引入By,方便我们使用元素定位方式。
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
class TestDemo:
def test_01(self):
with webdriver.Chrome(executable_path='chromedriver96.exe') as browser:
# 设置隐性等待的时间
browser.implicitly_wait(10)
browser.get("http://www.baidu.com")
# input_el = browser.find_element('xpath', '//input[@id="kw"]')
# 引入By,会有相应提示,不容易出错
input_el = browser.find_element(By.XPATH, '//input[@id="kw"]')
input_el.send_keys('柠檬班')
# 找到搜索按钮
search_btn = browser.find_element(By.XPATH, '//input[@id="su"]')
# 点击搜索按钮
search_btn.click()
# 让程序休息3秒
time.sleep(3)浏览器界面:

如果我们在返回的搜索界面,需要点击第一个链接内容进行搜索,
from selenium import webdriver
from selenium.webdriver.common.by import By
class TestDemo:
def test_01(self):
with webdriver.Chrome(executable_path='chromedriver96.exe') as browser:
browser.get("http://www.baidu.com")
# input_el = browser.find_element('xpath', '//input[@id="kw"]')
# 引入By,会有相应提示,不容易出错
input_el = browser.find_element(By.XPATH, '//input[@id="kw"]')
input_el.send_keys('柠檬班')
# 找到搜索按钮
search_btn = browser.find_element(By.XPATH, '//input[@id="su"]')
# 点击搜索按钮
search_btn.click()
lemon_link = browser.find_element(By.LINK_TEXT,'lemon.ke.qq.com/')
lemon_link.click()上面的代码运行后,运行结果会报错:NoSuchElementException,报错找不到元素
一般这样报错有两个原因,一是查找元素的路径写的有问题,二是页面没加载出来,页面不存在,找元素当然找不到,验证问题1我们可以进行xpath验证,问题2我们可以看出来上面的代码运行时,浏览器很快关闭,还未加载出来第一个页面,就进行第二次点击当然找不到元素了,这时就引入等待,我们需要等待元素加载完成之后,再运行第二次的点击事件。
2.等待
2.1强制等待
time.sleep(10),不管是否能找到元素,都要等待10秒返回结果,找不到,则会报错。每次找元素就需要设置sleep。
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
class TestDemo:
def test_01(self):
with webdriver.Chrome(executable_path='chromedriver96.exe') as browser:
browser.get("http://www.baidu.com")
# input_el = browser.find_element('xpath', '//input[@id="kw"]')
# 引入By,会有相应提示,不容易出错
input_el = browser.find_element(By.XPATH, '//input[@id="kw"]')
input_el.send_keys('柠檬班')
# 找到搜索按钮
search_btn = browser.find_element(By.XPATH, '//input[@id="su"]')
# 点击搜索按钮
search_btn.click()
# 等待元素加载完成之后,再运行下面的代码
# 让程序休息10秒
time.sleep(10)
lemon_link = browser.find_element(By.LINK_TEXT,'lemon.ke.qq.com/')
lemon_link.click()
time.sleep(3)2.2 隐性等待
browser.implicitly_wait(10),如果在10秒内找到元素,剩下的时间就会跳过,直接返回,如果找不到元素,则会报错。每个浏览器只需要设置一次就可以,每次查找元素前都会去执行即智能等待元素被加载,全局只需要设置一次。只能等待元素被加载,如果时间到了,而元素刚好被加载,就会返回了,你不能看到这个元素是否能点击等动态效果。
from selenium import webdriver
from selenium.webdriver.common.by import By
class TestDemo:
def test_01(self):
with webdriver.Chrome(executable_path='chromedriver96.exe') as browser:
# 设置隐性等待的时间
browser.implicitly_wait(10)
browser.get("http://www.baidu.com")
# input_el = browser.find_element('xpath', '//input[@id="kw"]')
# 引入By,会有相应提示,不容易出错
input_el = browser.find_element(By.XPATH, '//input[@id="kw"]')
input_el.send_keys('柠檬班')
# 找到搜索按钮
search_btn = browser.find_element(By.XPATH, '//input[@id="su"]')
# 点击搜索按钮
search_btn.click()
# 等待元素加载完成之后,再运行下面的代码
lemon_link = browser.find_element(By.LINK_TEXT,'lemon.ke.qq.com/')
lemon_link.click()
2.3 显性等待
真的很麻烦,不容易理解。 你可以自己设置某种条件,如果条件满足了,就返回,如果条件不满足,就继续去执行,直到超出时间为止; 等待某个元素可以被点击; 或者某个元素可见; 等待某个url=''的出现。 引入WebDriverWait,expected_conditions
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as when
class TestDemo:
def test_01(self):
with webdriver.Chrome(executable_path='chromedriver96.exe') as browser:
browser.get("http://www.baidu.com")
# input_el = browser.find_element('xpath', '//input[@id="kw"]')
# 引入By,会有相应提示,不容易出错
input_el = browser.find_element(By.XPATH, '//input[@id="kw"]')
input_el.send_keys('柠檬班')
# 找到搜索按钮
search_btn = browser.find_element(By.XPATH, '//input[@id="su"]')
# 点击搜索按钮
search_btn.click()
# 等待元素加载完成之后,再运行下面的代码
# 显性等待
# 1.获得等待器,设置倒计时
# 2.等待的条件出现
# 3.在超时前,如果等待条件出现了,就返回;如果等待条件没出现,就一直查找,直到报超时额错误
wait = WebDriverWait(browser, timeout=10)
# 元组形式传进去
condition = when.element_to_be_clickable((By.LINK_TEXT, 'lemon.ke.qq.com/'))
lemon_link = wait.until(condition)
# lemon_link = browser.find_element(By.LINK_TEXT, 'lemon.ke.qq.com/')
lemon_link.click()
2.4 封装
from selenium.webdriver import Chrome
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as when
class Page:
host = 'http://www.baidu.com'
# driver: Chrome 解释driver的类型。方面后续使用时有提示
def __init__(self, driver: Chrome):
self.driver = driver
def goto(self, url):
"""去哪个url地址"""
# find()找不到子字符串返回-1
if url.find('http://') != -1:
return self.driver.get(url)
return self.driver.get(self.host + url)
def fill(self, locator, words):
"""输入框内输入信息"""
# locator是元组,*locator解包
el = self.driver.find_element(*locator)
el.send_keys(words)
def click(self, locator):
"""点击"""
wait = WebDriverWait(self.driver, timeout=10)
# 元组形式传进去
condition = when.element_to_be_clickable(locator)
element = wait.until(condition)
element.click()
if __name__ == '__main__':
with Chrome(executable_path='chromedriver96.exe') as browser:
b = Page(browser)
b.goto('/')
b.fill((By.XPATH, '//input[@id="kw"]'), "柠檬班")
b.click((By.XPATH, '//input[@id="su"]'))
b.click((By.LINK_TEXT, 'lemon.ke.qq.com/'))
这样,显性等待的代码可以调用封装后的代码:
from selenium import webdriver
from selenium.webdriver.common.by import By
from browser import Page
class TestDemo:
def test_01(self):
with webdriver.Chrome(executable_path='chromedriver96.exe') as browser:
page = Page(browser)
page.goto('/')
page.fill((By.XPATH, '//input[@id="kw"]'), "柠檬班")
page.click((By.XPATH, '//input[@id="su"]'))
page.click((By.LINK_TEXT, 'lemon.ke.qq.com/'))
封装后,其他类似操作都可以调用封装后的类和方法了。
3. xpath vs CSS选择器
前面讲解了xpath的元素定位方式,CSS选择器用于选择你想要的元素的样式的模式。
css选择器的基本语法:
id属性:
xpath写法://input[@id="kw"]
css选择器:input#kw 或者 #kw ,#表示id
class属性:
xpath写法://imput[@class="s_ipt"]
css选择器:input.s_ipt 或者 .s_ipt
属性:
xpath://input[@name="wd"]
css选择器:input[name=wd]
xpath vs css选择器(面试题):
css选择器整体上来说比xpath的表示更简洁;
css选择器查找速度比xpath要快;
xpath的功能比css选择器更强;
对于复杂元素xpath反而会更简洁;
css选择器目前不支持通过文本查找元素,xpath可以。