CPU内存飙高,linux系统排查
前段时间一直运行的模型因为访问量激增,突然出现了CPU内存翻倍无法自己下降的情况,必须重启服务器。虽然平时负责算法研发和移植工作多,但是自己一直对高性能系统都很感兴趣。所以当时除了配合服务端的人排查问题,也去请教了公司一直做后台开发的大佬,学习了一番。对于Linux系统,程序功能执行结束而内存一直无法释放,本质的原因是该程序的进程尚未结束。但Linux系统的内存管理其实是非常复杂的一个系统,当初系统内存回收机制的设计本身就是有一定的概率会找不到无用内存的。因此,当发现CPU内存飙高无法自降时,需要从代码以及系统层面去分析和确定问题。然而,目前来说,对于linux系统,没有非常好的内存查找工具可用。所以更多的时候是靠自己的经验以及对操作系统的理解。这篇文章,有很多也是借鉴了大牛的知识,写得不对的地方,欢迎大家过来补充和修正。
首先,来看看Linux系统资源消耗点的分布:

一般来说,CPU,load以及IO都是比较耗内存的地方。在2.6版本后的内核里,进程一般有7种状态。分别是:不可中断睡眠态(TASK_UNINTERRUPTIBLE)、可执行态(TASK_RUNNING)、可中断睡眠态(TASK_INTERRUPTIBLE)、暂停&跟踪状态(__TASK_STOPPED & __TASK_TRACED)、僵尸态(EXIT_ZOMBIE)和死亡态(EXIT_DEAD)。
各状态的含义如下:
不可中断睡眠态:位于这种状态的进程处于睡眠中,并且不允许被其他进程或中断(异步信号)打断。因此这种状态的进程,是无法使用kill -9杀死的(kill也是一种信号),除非重启系统(没错,就是这么头硬)。不过这种状态一般由I/O等待(比如磁盘I/O、网络I/O、外设I/O等)引起,出现时间非常短暂,大多很难被PS或者TOP命令捕获(除非I/O HANG死)。SLEEP态进程不会占用任何CPU资源。
可中断睡眠态:这种状态的进程虽然也处于睡眠中,但是是允许被中断的。这种进程一般在等待某事件的发生(比如socket连接、信号量等),而被挂起。一旦这些时间完成,进程将被唤醒转为R态。如果不在高负载时期,系统中大部分进程都处于S态。SLEEP态进程不会占用任何CPU资源。
可执行态:这种状态的进程都位于CPU的可执行队列中,正在运行或者正在等待运行。
暂停&跟踪状态:这种两种状态的进程都处于运行停止的状态。不同之处是暂停态一般由于收到SIGSTOP、SIGTSTP、SIGTTIN、SIGTTOUT四种信号被停止,而跟踪态是由于进程被另一个进程跟踪引起(比如gdb断点)。暂停态进程会释放所有占用资源。
僵尸态:这种状态的进程实际上已经结束了,但是父进程还没有回收它的资源(比如进程的描述符、PID等)。僵尸态进程会释放除进程入口之外的所有资源。我之前遇到的就是这种。代码bug其实已经抛出异常,但是进程没有结束。导致了多次运算后CPU内存直接翻倍。
死亡态:进程的真正结束态,这种状态一般在正常系统中捕获不到。当时查找BUG的时候比较头疼的一点是,服务器已经重启过,线上生产环境服务器环境和线下的服务器环境不一样,这样有可能不同的底层回收实现和系统初始化机制不一样,尤其是这种偶发事件,未必能够在本地复现。对于这种问题,唯一的做法就是保持代码不变,本地模拟生产环境不同数据多次运行。运气好可能很快就复现,运气不好的可能一直都不会复现。在这里也想说一句:上线代码必须要有代码审核和完整的测试才能上线!为了所谓的快速迭代和上线忽略这两个过程的都是耍流氓。
Load Average & CPU使用率问题
谈到系统性能,Load和CPU使用率是最直观的两个指标,那么这两个指标是怎么被计算出来的呢?是否能互相等价呢?
在linux系统中,Load Average的计算方法为:
在前文 Linux进程状态 中有提到过,不可中断睡眠态的进程(TASK_UNINTERRUTED)一般都在进行I/O等待,比如磁盘、网络或者其他外设等待。由此我们可以看出,Load Average在Linux中体现的是整体系统负载,即CPU负载 + Disk负载 + 网络负载 + 其余外设负载,并不能完全等同于CPU使用率(这种情况只出现在Linux中,其余系统比如Unix,Load还是只代表CPU负载)![]()
在 Linux进程状态 中,不可中断睡眠态的进程(TASK_UNINTERRUTED)一般都在进行I/O等待,比如磁盘、网络或者其他外设等待。由此我们可以看出,Load Average在Linux中体现的是整体系统负载,即CPU负载 + Disk负载 + 网络负载 + 其余外设负载,并不能完全等同于CPU使用率(这种情况只出现在Linux中,其余系统比如Unix,Load还是只代表CPU负载)。
CPU的使用率:
CPU的时间分片一般可分为4大类:用户进程运行时间 - User Time, 系统内核运行时间 - System Time, 空闲时间 - Idle Time, 被抢占时间 - Steal Time。除了Idle Time外,其余时间CPU都处于工作运行状态。如图所示:
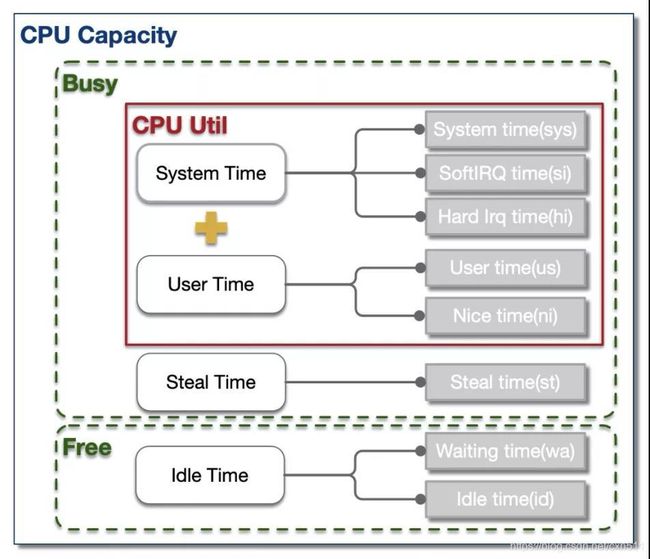
通常而言,我们泛指的整体CPU使用率为User Time 和 Systime占比之和(例如tsar中CPU util),即:
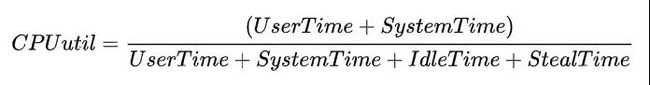
为了便于定位问题,大多数性能统计工具都将这4类时间片进一步细化成了8类,如下为TOP对CPU时间片的分类。

us:用户进程空间中未改变过优先级的进程占用CPU百分比
sy:内核空间占用CPU百分比
ni:用户进程空间内改变过优先级的进程占用CPU百分比
id:空闲时间百分比
wa:空闲&等待I/O的时间百分比
hi:硬中断时间百分比
si:软中断时间百分比
st:虚拟化时被其余VM窃取时间百分比
资源&瓶颈分析
从图1中可以看到,Load Average和CPU使用率可被细分为不同的子域指标,指向不同的资源瓶颈。总体来说,指标与资源瓶颈的对应关系基本如图1所示。
这是我们最常遇到的一类情况,即load上涨是CPU负载上升导致。根据CPU具体资源分配表现,可分为以下几类:
1、CPU sys高
这种情况CPU主要开销在于系统内核,可进一步查看上下文切换情况。
1)如果非自愿上下文切换较多,说明CPU抢占较为激烈,大量进程由于时间片已到等原因,被系统强制调度,进而发生的上下文切换。
2)如果自愿上下文切换较多,说明可能存在I/O、内存等系统资源瓶颈,大量进程无法获取所需资源,导致的上下文切换。
如果不了解上下文切换相关内容的,可以看这篇博客:https://cloud.tencent.com/developer/article/1695233
2、CPU si高
这种情况说明资源主要消耗在应用进程,可能引发的原因有以下几类:
1)死循环或代码中存在CPU密集计算。这种情况多核CPU us会同时上涨。
2)内存问题,导致大量FULLGC,阻塞线程。这种情况一般只有一核CPU us上涨。
3)资源等待造成线程池满,连带引发CPU上涨。这种情况下,线程池满等异常会同时出现。
3、CPU us高
这种情况说明资源主要消耗在应用进程,可能引发的原因有以下几类:
1)死循环或代码中存在CPU密集计算。这种情况多核CPU us会同时上涨。
2)内存问题,导致大量FULLGC,阻塞线程。这种情况一般只有一核CPU us上涨。
3)资源等待造成线程池满,连带引发CPU上涨。这种情况下,线程池满等异常会同时出现。
4、Load高 & CPU低
这种情况出现的根本原因在于不可中断睡眠态(TASK_UNINTERRUPTIBLE)进程数较多,即CPU负载不高,但I/O负载较高。可进一步定位是磁盘I/O还是网络I/O导致。
排查策略
虽然没有专门的linux内存泄漏排查工具,但是仍然可以借助一些工具来帮助排查。同时,排查还是有一定套路的。
第一步:资源瓶颈定位,先看看是哪个模块。这一步通过全局性能检测工具,初步定位资源消耗异常位点。常用的工具有:top、vmstat、tsar(历史);中断:/proc/softirqs、/proc/interrupts;I/O:iostat、dstat。
第二步:热点进程定位
定位到资源瓶颈后,可进一步分析具体进程资源消耗情况,找到热点进程。常用的工具有:上下文切换:pidstat -w、CPU:pidstat -u、I/O:iotop、pidstat -d、僵尸进程:ps
第三步:线程&进程内部资源定位
找到具体进程后,可细化分析进程内部资源开销情况。常用工具有:上下文切换:pidstat -w -p [pid]、CPU:pidstat -u -p [pid]、I/O: lsof
第四步:热点事件&方法分析
获取到热点线程后,我们可用trace或者dump工具,将线程反向关联,将问题范围定位到具体方法&堆栈。常用的工具有:perf:Linux自带性能分析工具,功能类似hotmethod,基于事件采样原理,以性能事件为基础,支持针对处理器相关性能指标与操作系统相关性能指标的性能剖析。jstack:1)结合ps -Lp或者pidstat -p一起使用,可初步定位热点线程。2)结合zprofile-threaddump一起使用,可统计线程分布、等锁情况,常用与线程数增加分析。strace:跟踪进程执行时的系统调用和所接收的信号。tcpdump:抓包分析,常用于网络I/O瓶颈定位。