基于推荐算法的电影系统——具体实现(3)
界面效果展示
后端管理界面视频展示
电影推荐系统前端用户界面视频展示
普通用户
在普通用户网页实现中,重点在于如何根据给定数据生成多个网页,本设计采用Flask自带的jinja模板渲染模块实现。其次是评论功能,点击评论,弹出一个模态框,发表完评论后,可以在右侧看到自己刚发表的评论。
电影详情页
首先定义一个静态模板页面,对于要显示的信息分别定义变量,且引用类型为data.name。因此在后端向前端传数据时数据类型是字典类型,因此在前端定义变量时要注意变量的书写。当点击电影首页的详情时,调用url ”/template”,该路由绑定template()函数,在该函数中,首先从前端获取数据—电影名称,然后去存储空间中获取该电影的各种信息,将这些信息存储在字典中,然后调用Jinja模板render_template(‘templat.html’,data=data)其中templa.html就是前面设计的模板文件,而data是一个字典,就是要在前端显示的信息。最终实现效果如图所示。
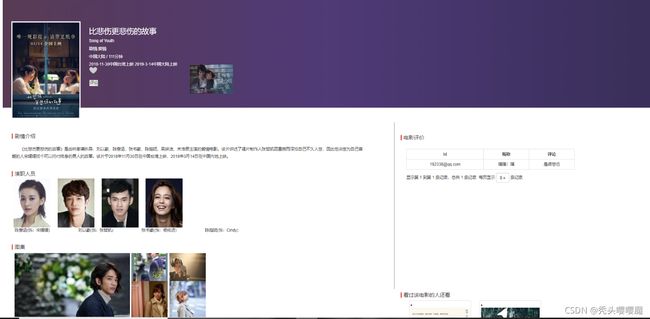
评论
评论发表完在右侧实现,本设计采用的是bootstrap table实现,表格共3列,分别显示用户ID、用户昵称和用户发表的评论。在第三章数据库设置中,在评论表格中,主键为(用户ID,电影名),因此如果一个用户对同一个电影发表多次评论,系统只会保存最近一次的评论。
function insert(){
data = $('#deblock_udid').val()
d = {"comment":data,'mv':'我不是药神'}
$.ajax({
url: "/add_comment",
type: "get",
data: d,
contentType: 'application/json;charset=utf-8',
success : function(data){
alert("发表成功!")
$('#table').bootstrapTable('destroy');
load("/comment_for")
}
});
}
当点击提交评论时,会触发insert()函数,获取到用户评论的信息,发起请求将电影名和评论信息一起通过Ajax异步传送到后端,如果请求成功,即表示已经完成了数据库操作,则页面提示发表成功,同时更新评论区。
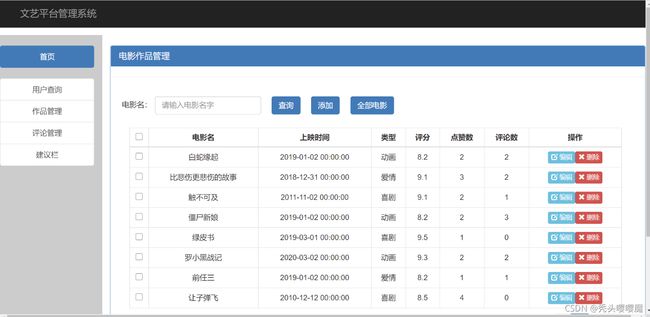
管理员
boostrap table初始化
管理员界面实现动态只需要对数据库进行操作,在前面讲过使用boostrap table进行信息管理十分方便,在前面只需要定义一行代码即可解决。关于表的初始化即表的各列名称、最多显示行数等都在js代码里完成,主要参数如下:
$('#table').bootstrapTable({
url: url, // 请求数据源的路由
dataType: "json",
pagination: true, //前端处理分页
singleSelect: true,//是否只能单选
toolbar: '#toolbar', //工具按钮用哪个容器
pageNumber: 1, //初始化加载第10页,默认第一页
pageSize: 8, //每页的记录行数(*)
pageList: [8, 20, 50, 100], //可供选择的每页的行数(*)
minimumCountColumns: 2, //当列数小于此值时,将隐藏内容列下拉框
clickToSelect: true, //设置true, 将在点击某行时,自动勾选
uniqueId: "id", //每一行的唯一标识,一般为主键列
sidePagination: "server", //分页方式:client客户端分页,server服务端分
首先url是表格请求数据源的路由,该路由绑定一个函数,函数和数据库进行连接,并执行相关操作后,将得到的数据返回,用于显示在表格中。Datatype表示返回的数据类型是json类型,bootstrap table自带搜索等功能,但是本设计考虑到页面的美观性,选择使用自定义查询。pagination设置的是前端分页还是后端分页,前端分页是指一次性从后端将数据取到前端,然后一页一页显示;而后端分页则是指,每次前端根据页号从后端取一页的数据,考虑到我们的数据量并不大,所以采用前端分页,一次性取所有数据。ClickToSelect为单击某一行时,是否选中,由于电影信息管理员需要做修改,因此选择true。
boostrap table查询
对于自定义查询,需要将输入的查询参数传输到后端,因此就需要用到boostrap table里的参数。请求服务器数据时,通过重写参数的方式添加一些额外的参数,例如 toolbar 中的参数 如果queryParamsType = ‘limit’ ,返回参数必须包含limit, offset, search, sort, order ,queryParamsType = ‘undefined’, 返回参数必须包含: pageSize, pageNumber, searchText, sortName, sortOrder. 返回false将会终止请求,这里的params是table提供的。
queryParamsType : "limit",//设置为 ‘limit’ 则会发送符合 RESTFul 格式的参数.
queryParams: function (params) {//自定义参数,这里的参数是传给后台的
//
var data = {
offset: params.offset,//从数据库第几条记录开始
limit: params.limit,//找多少条
mv_name: $("#mv_name").val(), //搜索框中的内容
type: $("type").value,
date: $("date").value
};
return data;
},
定义一个输入框id为“mv_name”,将该输入框输入的值传给后端进行查询,并将查询结果返回到前端显示。在更新表格时,需要注意的是需要加上这行代码,将之前的表格先销毁,才能进行更新。$(’#table’).bootstrapTable(‘destroy’);
模态框
在对表格进行添加和修改操作时,需要弹出一个模态框,在模态框中输入我们需要添加或修改的内容,然后传到后端进行更新。向后端传递模态框数据时通过KaTeX parse error: Expected 'EOF', got '#' at position 3: ('#̲i_mv').val()获取,…(’#i_mv’).val(mv_name)实现。
爬虫获取电影信息
爬虫程序
实现爬取猫眼电影top100榜的爬虫程序,首先就需要获得猫眼电影的top100榜的网页信息,通过百度搜索可以得到其网页为https://maoyan.com/board/4?offset=x,其中x是数字,这个数字就代表了在top100排行榜的位置,通过后期的分析发现,每次获取这个网页时,会获得一共十个电影的片名、主演、评分的信息,还有电影自身的链接,因此在爬取top100榜的总榜单时,分十次爬取即可获得100部电影的基本信息。
初步分析爬虫获取的网页后,发现网页信息并不全面,例如电影的类型就无法在这个网页获得,因此必须爬取电影本身的页面,从中获取电影的类型,但这无疑会加大工作量,并且可能会触发服务器防火墙,所以就引出了模拟浏览器的操作,后文会介绍。通过对top100榜中的电影本身链接的剥离,获取电影的链接,再通过后续的爬虫程序爬取其类型信息。
网页分析
获取到top100榜的十个网页之后,则需要对获取的网页进行进一步分析。首先,通过chrome对网页源代码进行分析,发现每个电影在同名的模块中,这就降低了爬取难度。使用beautifulsoup对网页进行解构,获取soup类型的容器,再用re包中的compile函数进行正则表达式匹配,获取我们想要的网页中的电影的信息,在获取信息后发现信息的格式并不尽如人意,因此再次使用re包,调用sub函数将获取的信息修剪成所需的格式,将过滤好的信息储存。
在分析top100榜的同时,针对每个电影的信息的爬取也在进行。从top100榜的页面剥离各个电影自身的网址之后,建立新的爬虫再去分别获取各个电影自身的网页信息,从中剥离出我们想要的电影的类型信息,和top100榜网页中获取的信息放在一起,将这些信息返回给主函数并写入文件中以便后续使用。
模拟用户
因为疫情原因,猫眼电影专业版的资源暂时不可以获得,因此不得不细分电影,使用爬虫从每个电影的主页上获取其类型,这个工作相对繁琐。而且由于猫眼电影本身服务器具有反爬机制,因此直接一次性爬取这些电影种类并不可取,所以爬虫机制必须添加一定的伪装,在失败了几次之后,决定使用等待机制模拟用户操作,也就是加入Python的休眠设置,引入time包,调用sleep函数,使得每次获取页面后等待20秒,再进行获取下一个页面的操作,借以模拟用户的操作。尽管这样确实大大的增长了程序运行的时间,但是确实将爬虫获取的数据大大增加,也不会过早的触发猫眼电影服务器的反爬取机制的注意,保证了爬取的顺利进行。
推荐算法
基于用户的协同过滤算法步骤,在实现过程中考虑的是如何将其嵌入到前端中及时推荐给用户。ml-latest是一个有关movie 的数据集,数据包含138,000 个用户对27,000 个电影的评价,评价分为0-5。本设计使用该数据集进行推荐算法的编写,将验证成功的算法用户电影交流平台的构建。
首先导入pandas包,读取用户对电影的评价信息,然后读取电影信息,通过电影的movie_id对读取的两个数据集进行合并,并保存合并的数据集方便后面分析使用,该数据存储的是每个用户对电影的评价和评分。读取该数据,将用户对电影的评分保存在字典data中。计算所有用户之间的相似度,因此不同用户评价的电影大不相同,因此找出用户共同评价过的电影,基于此计算两个用户的欧式距离,使用该距离衡量两个用户的相似度,即距离越小,相似度越大。最后选取相似度最大的用户,找出该用户看过的所有电影,将目标用户没看过的电影推荐给目标用户,推荐算法结束。
将带算法过程引入到电影推荐平台的使用中,因为本设计提供了用户对电影的点赞功能,因此当对于某个用户进行推荐时,首先找到所有的喜爱电影(即点赞过的),然后依据这个来计算用户之间的相似度,其他过程基本同上。
总结
1、动态生成每个电影详情页,调用Flask的Jinja模板传入相关数据实现。
2、后台管理员进行信息管理时,和boostrap table的动态交互。
3、详细地介绍了利用爬虫技术,从猫眼网站获取电影信息用于本平台的构建,并将爬取结果进行了可视化。
4、介绍了基于用户的协同过滤算法的具体实现过程
详细代码可见:此处