Impala metrics详解之Jvm篇
文章目录
-
- Jvm metrics模板
-
- Memory usage模板
- Peak memory usage模板
- GC相关的模板
- Jvm metrics相关的thrift结构体
- 代码流程
-
- TJvmMemoryPool获取
-
- Memory Pool获取
- Heap和non heap获取
- Total获取
- Jvm GC metrics获取
-
- JvmPauseMonitor metrics
- 其他GC metrics
- BE端初始化metrics
- 关于Metrics的更新
- 总结
Impala的web页面提供了非常丰富的信息,其中就包括各种metrics信息。这些metrics非常多,但是官方也没有专门文档解释,所以有时候也看不明白是什么意思。笔者在早期的文章 Impala metrics参数介绍(一)介绍了一些关于admission controller相关的metrics。时隔两年多,今天将跟大家一起来学习下Jvm相关的metrics信息。
Jvm metrics模板
Impala的metrics模板都定义在文件common/thrift/metrics.json文件中,我们可以很快搜到Jvm相关的metrics模板。主要分为三大类:memory usage、peak memory usage和gc相关的。下面我们就分别来看一下这三类模板。
Memory usage模板
Memory usage主要包括了如下四个模板:
jvm.$0.committed-usage-bytes
jvm.$0.current-usage-bytes
jvm.$0.init-usage-bytes
jvm.$0.max-usage-bytes
其中$0表示占位符。从字面意思看,就是不同的内存使用,包括committed、current、init和max。
Peak memory usage模板
Peak memory usage模板与memory usage模板很相似,只是每个前面多了一个peak值:
jvm.$0.peak-committed-usage-bytes
jvm.$0.peak-current-usage-bytes
jvm.$0.peak-init-usage-bytes
jvm.$0.peak-max-usage-bytes
从字面来看,就是不同字节使用的峰值,也包含了占位符。
GC相关的模板
最后是几个gc相关的模板,这几个模板都是固定的名称,没有符占位:
jvm.gc_time_millis
jvm.gc_count
jvm.gc_num_warn_threshold_exceeded
jvm.gc_num_info_threshold_exceeded
jvm.gc_total_extra_sleep_time_millis
Jvm metrics相关的thrift结构体
上面我们介绍了Jvm相关的metrics模板,接下来我们看下Jvm metrics相关的thrift结构体。Impala首先会在FE端通过Java代码获取Jvm相关的信息,然后转换为相应的thrift结构体传到BE端,这里主要就是TGetJvmMemoryMetricsResponse这个结构体,我们简单来看下这个结构体相关的信息:
struct TGetJvmMemoryMetricsResponse {
1: required list memory_pools
2: required i64 gc_num_warn_threshold_exceeded
3: required i64 gc_num_info_threshold_exceeded
4: required i64 gc_total_extra_sleep_time_millis
5: required i64 gc_count
6: required i64 gc_time_millis
}
可以看到,TGetJvmMemoryMetricsResponse主要分为两个部分:TJvmMemoryPool集合以及Jvm GC相关的信息。其中TJvmMemoryPool如下所示:
struct TJvmMemoryPool {
1: required i64 committed
2: required i64 init
3: required i64 max
4: required i64 used
5: required i64 peak_committed
6: required i64 peak_init
7: required i64 peak_max
8: required i64 peak_used
9: required string name
}
这个TJvmMemoryPool对象又可以分为usage和peak usage两部分,也正好对应了我们在上节介绍的前两类模板。下面我们结合代码来看下,Impala是如何获取Jvm的metrics信息。
代码流程
这里我们以Impalad节点为例,相关的代码调用如下所示:
ImpaladMain(impalad-main.cc):72
-Init(exec-env.cc):312
--InitMetrics(memory-metrics.cc):202
---GetPoolNames(memory-metrics.cc):344
----GrabMetricsIfNecessary(memory-metrics.cc):294
-----GetJvmMemoryMetrics(jni-util.cc)
...JNI...
------getJvmMemoryMetrics(JniUtil.java)
可以看到最终会通过JNI调用FE端的代码来获取metrics信息,主要的处理逻辑就在getJvmMemoryMetrics()函数中。这个函数代码主体主要分为三个部分,分别对应我们上面提到的三种metrics对应的模板。这里我们使用Impala自带的mini cluster进行远程调试,可以看到一次Jvm的获取,返回信息如下所示:

第一部分的TJvmMemoryPool集合,一共有9个成员,分别是:code-cache、compressed-class-space、heap、metaspace、non-heap、ps-eden-space、ps-old-gen、ps-survivor-space和total;第二部分是GC相关的metrics对应的成员也有了相应的值。下面我们就看下这些成员值是如何获取的。
TJvmMemoryPool获取
上面我们提到的9个TJvmMemoryPool成员,根据获取方式又可以分为三类,分别来看下。
Memory Pool获取
第一种就是通过官方提供的ManagementFactory.getMemoryPoolMXBeans()来获取当前Jvm包含的一系列memory pools,返回的类型是MemoryPoolMXBean对象,Impala会将该对象转换为一个TJvmMemoryPool,相关代码如下所示:
for (MemoryPoolMXBean memBean: ManagementFactory.getMemoryPoolMXBeans()) {
TJvmMemoryPool usage = new TJvmMemoryPool();
MemoryUsage beanUsage = memBean.getUsage();
usage.setCommitted(beanUsage.getCommitted());
usage.setInit(beanUsage.getInit());
usage.setMax(beanUsage.getMax());
usage.setUsed(beanUsage.getUsed());
usage.setName(memBean.getName());
//省略部分代码
MemoryUsage peakUsage = memBean.getPeakUsage();
usage.setPeak_committed(peakUsage.getCommitted());
usage.setPeak_init(peakUsage.getInit());
usage.setPeak_max(peakUsage.getMax());
usage.setPeak_used(peakUsage.getUsed());
//省略部分代码
jvmMetrics.getMemory_pools().add(usage);
}
这里主要包含了两种内存使用情况:memory usage和peak memory usage,我们分别看下官方的解释:
//Returns an estimate of the memory usage of this memory pool.
MemoryUsage getUsage()
//Returns the peak memory usage of this memory pool since the Java virtual machine was started or since the peak was reset.
MemoryUsage getPeakUsage()
可以看到,这两种情况分别表示该memory pool当前的内存使用和自jvm启动之后的内存使用最大值。这两种内存使用,都是用一个MemoryUsage对象来表示,这个对象本身有包含了四个成员,分别是:committed、init、max和used。关于这四个成员,官方解释如下所示:
- init: represents the initial amount of memory (in bytes) that the Java virtual machine requests from the operating system for memory management during startup. The Java virtual machine may request additional memory from the operating system and may also release memory to the system over time. The value of init may be undefined.
- used: represents the amount of memory currently used (in bytes).
- committed: represents the amount of memory (in bytes) that is guaranteed to be available for use by the Java virtual machine. The amount of committed memory may change over time (increase or decrease). The Java virtual machine may release memory to the system and committed could be less than init. committed will always be greater than or equal to used.
- max: represents the maximum amount of memory (in bytes) that can be used for memory management. Its value may be undefined. The maximum amount of memory may change over time if defined. The amount of used and committed memory will always be less than or equal to max if max is defined. A memory allocation may fail if it attempts to increase the used memory such that used > committed even if used <= max would still be true (for example, when the system is low on virtual memory).
官方文档关于这四个值,也提供了一个简单的图,如下所示:

关于init、used和max都比较好理解,这里主要是committed。从字面意思看,就是OS保证能给到的JVM使用的内存大小,这个值总是大于等于used的值,也就是说committed的值不一定就是JVM当前使用的,可能也会包含一些OS预留给JVM的内存大小,所以这个值是可能大于used的;同时,这是值也有可能小于init,这就表示JVM归还了一些资源给OS;最后,如果定义了max,那么used和committed总是会小于max的。
上节中提到的code-cache、compressed-class-space、metaspace、ps-eden-space、ps-old-gen、ps-survivor-space,这6个memory pools都是通过当前这种方式获取到的。这里我们以ps-eden-space为例,这个表示Jvm的Eden space的内存使用情况。我们参考Impala与内嵌Jvm之间的交互一文中的设置,在启动mini cluster的时候,带上参数’–jvm_args=-Xmn100m -XX:SurvivorRatio=8’。此时新生代被设置为100m,Eden区域占8/10,所以ps-eden-space的init和max应该都是80m,如下所示:

Heap和non heap获取
第二种是通过官方提供的ManagementFactory.getMemoryMXBean()来获取heap和non heap的使用,相关代码如下所示:
MemoryMXBean mBean = ManagementFactory.getMemoryMXBean();
TJvmMemoryPool heap = new TJvmMemoryPool();
MemoryUsage heapUsage = mBean.getHeapMemoryUsage();
heap.setCommitted(heapUsage.getCommitted());
heap.setInit(heapUsage.getInit());
heap.setMax(heapUsage.getMax());
heap.setUsed(heapUsage.getUsed());
heap.setName("heap");
heap.setPeak_committed(0);
heap.setPeak_init(0);
heap.setPeak_max(0);
heap.setPeak_used(0);
jvmMetrics.getMemory_pools().add(heap);
TJvmMemoryPool nonHeap = new TJvmMemoryPool();
MemoryUsage nonHeapUsage = mBean.getNonHeapMemoryUsage();
nonHeap.setCommitted(nonHeapUsage.getCommitted());
nonHeap.setInit(nonHeapUsage.getInit());
nonHeap.setMax(nonHeapUsage.getMax());
nonHeap.setUsed(nonHeapUsage.getUsed());
nonHeap.setName("non-heap");
nonHeap.setPeak_committed(0);
nonHeap.setPeak_init(0);
nonHeap.setPeak_max(0);
nonHeap.setPeak_used(0);
jvmMetrics.getMemory_pools().add(nonHeap);
这里分别是通过getHeapMemoryUsage()和getNonHeapMemoryUsage()来获取这两个memory pool对应的信息的,官方文档解释如下:
MemoryUsage getHeapMemoryUsage()
Returns the current memory usage of the heap that is used for object allocation.
MemoryUsage getNonHeapMemoryUsage()
Returns the current memory usage of non-heap memory that is used by the Java virtual machine.
由于heap和non heap没有peak memory usage,所以相关的参数都设置为0。
Total获取
最后我们来看一下关于total的获取,该过程其实就在memory pools的循环中一并处理的。我们在上上节的介绍中,省略了无关的代码,这里我们展示出来:
相关代码如下所示:
TJvmMemoryPool totalUsage = new TJvmMemoryPool();
totalUsage.setName("total");
jvmMetrics.getMemory_pools().add(totalUsage);
for (MemoryPoolMXBean memBean: ManagementFactory.getMemoryPoolMXBeans()) {
TJvmMemoryPool usage = new TJvmMemoryPool();
MemoryUsage beanUsage = memBean.getUsage();
//省略部分代码
totalUsage.committed += beanUsage.getCommitted();
totalUsage.init += beanUsage.getInit();
totalUsage.max += beanUsage.getMax();
totalUsage.used += beanUsage.getUsed();
MemoryUsage peakUsage = memBean.getPeakUsage();
//省略部分代码
totalUsage.peak_committed += peakUsage.getCommitted();
totalUsage.peak_init += peakUsage.getInit();
totalUsage.peak_max += peakUsage.getMax();
totalUsage.peak_used += peakUsage.getUsed();
jvmMetrics.getMemory_pools().add(usage);
}
可以看到,total就是把上上节中的6个memory pools对应的参数进行了累计求和,不包括heap和non heap这两个。笔者以自己的测试环境为例,我们查看所有“current”相关的metrics值:
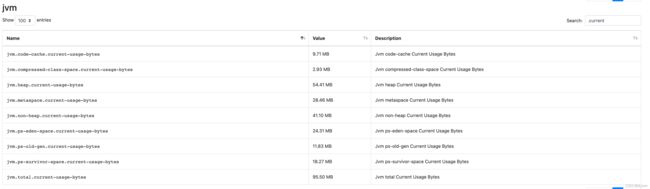
可以看到,我们将heap和non heap除外的其他current相加,结果是95.51MB,基本等于jvm.total.current-usage-bytes的95.50MB。同样,我们查看所有“peak-current”相关的metric:
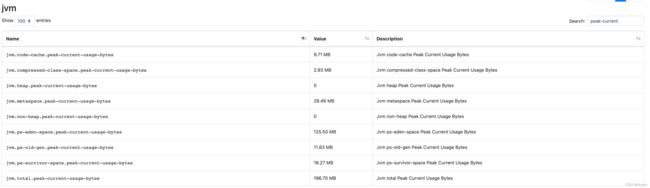
可以看到,我们将heap和non heap除外的其他peak-current相加,结果是196.7MB,与jvm.total.peak-current-usage-bytes的196.70MB是一致的。
Jvm GC metrics获取
关于memory usage的metrics介绍完了。下面我们看下GC相关的metrics,主要也可以分为两类,我们继续结合代码看一下。
JvmPauseMonitor metrics
第一类metrics主要有三个,都是与Jvm的pause检测相关的,计算方式如下:
// Populate JvmPauseMonitor metrics
jvmMetrics.setGc_num_warn_threshold_exceeded(
JvmPauseMonitor.INSTANCE.getNumGcWarnThresholdExceeded());
jvmMetrics.setGc_num_info_threshold_exceeded(
JvmPauseMonitor.INSTANCE.getNumGcInfoThresholdExceeded());
jvmMetrics.setGc_total_extra_sleep_time_millis(
JvmPauseMonitor.INSTANCE.getTotalGcExtraSleepTime());
可以看到,主要就是通过JvmPauseMonitor这个类来统计的。在Impala启动之后,Jvm会专门启动一个线程来进行Jvm pause的检测,相关代码如下所示:
ImpaladMain(impalad-main.cc):60
-InitCommonRuntime(init.cc):426
--InitJvmPauseMonitor(jni-util.cc):251
...JNI...
---initPauseMonitor(JvmPauseMonitor.java):80
----init(JvmPauseMonitor.java)
线程启动之后,就会执行JvmPauseMonitor.Monitor中重载的run方法,该方法的主要逻辑就是通过一个while循环来检测Jvm的gc停顿时间,判断是否超过了指定的阈值,每次检测间隔时500ms。这里的阈值分为两种情况:
//如果GC的停顿时间超过这个warn threshold,那么就会将gc_num_info_threshold_exceeded加1,并且输入一条warn内容
private static final long WARN_THRESHOLD_MS = 10000;
//如果GC的停顿时间超过这个info threshold,那么就会将gc_num_info_threshold_exceeded加1,并且输入一条info内容
private static final long INFO_THRESHOLD_MS = 1000;
两种日志的内容格式都是一样,只是log level不同,具体的日志格式位于JvmPauseMonitor.formatMessage()函数中。每循环一次,都会累积本次的循环处理时间(sleep的500ms不算)到gc_total_extra_sleep_time_millis。
以上就是Jvm pause相关的三个metrics。除此之外,Impala在启动的时候,BE端也会启动一个专门的线程来进行程序的pause检测,如下所示:
//InitCommonRuntime(init.cc)
thread_spawn_status =
Thread::Create("common", "pause-monitor", &PauseMonitorLoop, &pause_monitor);
主要的处理逻辑位于函数PauseMonitorLoop()中,相关代码如下所示:
static void PauseMonitorLoop() {
if (FLAGS_pause_monitor_warn_threshold_ms <= 0) return;
int64_t time_before_sleep = MonotonicMillis();
while (true) {
SleepForMs(FLAGS_pause_monitor_sleep_time_ms);
int64_t sleep_time = MonotonicMillis() - time_before_sleep;
time_before_sleep += sleep_time;
if (sleep_time > FLAGS_pause_monitor_warn_threshold_ms) {
LOG(WARNING) << "A process pause was detected for approximately " <<
PrettyPrinter::Print(sleep_time, TUnit::TIME_MS);
}
}
}
代码本身也比较简单,如果将pause_monitor_warn_threshold_ms配置为0,则不开启程序pause的检测,默认值是10000ms。如果某次循环处理时间(sleep的不算)超过该阈值,则会打印一条warn日志。Sleep时间可以通过pause_monitor_sleep_time_ms来配置,默认是500ms。
我们可以通过web页面分别看到这两个检测线程:


Jvm pause检测线程需要在“JVM”标签页下面查看,程序pause检测线程可以在“Common”或者“All”里面搜索看到。
其他GC metrics
剩下的还有两个metrics,分别表示gc的次数和持续时间,计算方式如下:
long gcCount = 0;
long gcTimeMillis = 0;
for (GarbageCollectorMXBean bean : ManagementFactory.getGarbageCollectorMXBeans()) {
gcCount += bean.getCollectionCount();
gcTimeMillis += bean.getCollectionTime();
}
jvmMetrics.setGc_count(gcCount);
jvmMetrics.setGc_time_millis(gcTimeMillis);
可以看到,主要也是通过官方提供的方法来获取当前Jvm所有的GarbageCollectorMXBean对象,然后将每个bean对象的gc次数和持续时间分别进行累加,这样就得到了最终的gc_count和gc_time_millis。
BE端初始化metrics
从FE端返回之后,BE端就会初始化相关的metrics,主要处理逻辑位于InitMetrics()函数中。我们简单看一下部分代码:
//memory-metrics.cc
void JvmMemoryMetric::InitMetrics(MetricGroup* parent) {
if (initialized_) return;
MetricGroup* metrics = parent->GetOrCreateChildGroup("jvm");
vector names = JvmMetricCache::GetInstance()->GetPoolNames();
for (const string& name : names) {
JvmMemoryMetric* pool_max_usage =
JvmMemoryMetric::CreateAndRegister(metrics, "jvm.$0.max-usage-bytes", name, MAX);
if (name == "heap") HEAP_MAX_USAGE = pool_max_usage;
JvmMemoryMetric::CreateAndRegister(
metrics, "jvm.$0.current-usage-bytes", name, CURRENT);
//省略其余的代码
}
首先注册一个jvm的metric组,然后遍历我们在上面提到的各个memory pool。对于每个memory pool,都会按照memory usage和peak memory usage两类模板进行注册,这里仍然以mini cluster环境为例,看一下ps eden space的相关metrics:
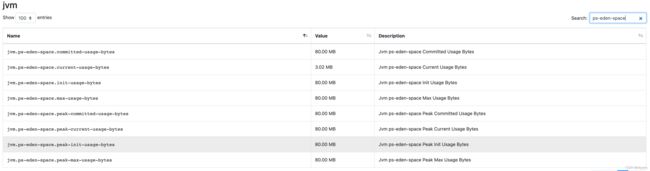
在CreateAndRegister方法中,会将memory pool中的空格替换为“-”,所以模板中的占位符就是“ps-eden-space”。相关的metrics一共有8个,刚好对应我们在最开始介绍的前两类模板。对于gc相关的metrics,是Jvm级别的,模板中也没有占位符,所以直接注册对应名称的metric,如下所示:
JvmMemoryCounterMetric::GC_TIME_MILLIS =
JvmMemoryCounterMetric::CreateAndRegister(metrics,
"jvm.gc_time_millis",
[](const TGetJvmMemoryMetricsResponse& r) {
return r.gc_time_millis;
});
直接通过TGetJvmMemoryMetricsResponse对象获取指定的成员变量即可,我们也可以在页面上看到所有gc相关的metrics:

关于Metrics的更新
最后我们来看一下Jvm metrics的更新。前面我们介绍过,Impala在BE端是通过JNI调用获取Jvm metrics信息,这个调用触发的情况有两种:1)系统刚刚启动的时候,初始化metrics;2)获取Jvm的metrics时,例如通过Web页面查看。但并不是每次在Web页面查看,Impala就会立马调用JNI。Impala设置了一个缓存时间,如果距离上次获取时间间隔还没到这个缓存时间,那么就直接使用当前的缓存,时间间隔是1s:
//memory-metrics.h
static const int64_t CACHE_PERIOD_MILLIS = 1000;
/// Last available metrics.
TGetJvmMemoryMetricsResponse last_response_;
这样就可以防止短时间内频繁获取metrics时,对Jvm产生较大的开销。上述的判断逻辑位于GrabMetricsIfNecessary()函数中,这个函数在前面的调用栈中也出现过。该函数的主要在以下三个函数中被调用:
JvmMemoryCounterMetric::GetValue()
-JvmMetricCache::GetCounterMetric()
--JvmMetricCache::GrabMetricsIfNecessary()
JvmMemoryMetric::GetValue()
-JvmMetricCache::GetPoolMetric()
--JvmMetricCache::GrabMetricsIfNecessary()
JvmMetricCache::GetPoolNames()
-JvmMetricCache::GrabMetricsIfNecessary()
前两种就是获取Jvm的metrics情况,第三种就是初始化metrics时用到的。
总结
到这里,关于Impala的Jvm metrics就已经介绍完毕。总结一下,本文首先介绍了Jvm的metrics种类,大致可以分为三类,即memory usage、peak memory usage和gc相关的metrics,然后结合代码学习了一下,这些metrics是如何更新的,最后我们介绍了这些metrics是如何更新的。Impala提供了非常详细的metrics,后续有机会,笔者再跟大家一起学习其他的metrics信息。本文是笔者基于社区4.0.0代码的分析而来,如有错误,欢迎批评指正。