HanLP在IDEA中的配置及使用
HanLP在IDEA中的配置及使用
HanLP介绍

HanLP是一款面向生产环境的自然语言处理工具包。
中文分词中有众多分词工具,如jieba、hanlp、盘古分词器、庖丁解牛分词等;其中庖丁解牛分词仅仅支持java,分词是HanLP最基础的功能,HanLP实现了许多种分词算法,每个分词器都支持特定的配置。接下来我将介绍如何配置Hanlp来开启自然语言处理之旅,每个工具包都是一个非常强大的算法集合。
- 具有如下功能:
中文分词 词性标注 命名实体识别 依存句法分析 语义依存分析 新词发现 关键词短语提取 自动摘要 文本分类聚类 拼音简繁 自然语言处理
【官方地址】HanLP
【GitHUb地址】源码
- 类似于Python中的jieba中文分词库,在Java中被封装成为HanLP
HanLP安装
①引入Maven仓库
在
pom.xml文件中添加依赖
<dependency>
<groupId>com.hankcsgroupId>
<artifactId>hanlpartifactId>
<version>portable-1.7.7version>
dependency>
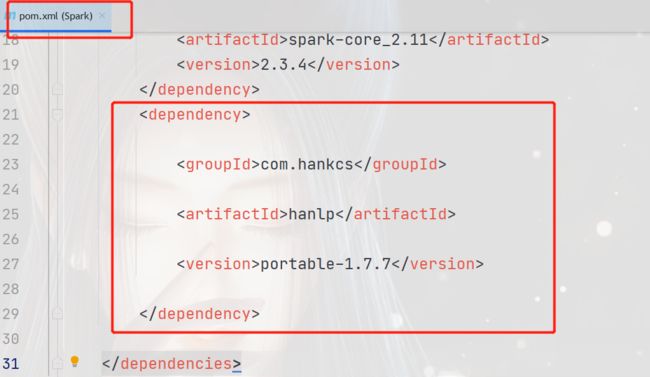
引入IDEA中的Maven项目,重新加载完成后即可使用基本功能(除由字构词、依存句法分析外的全部功能)
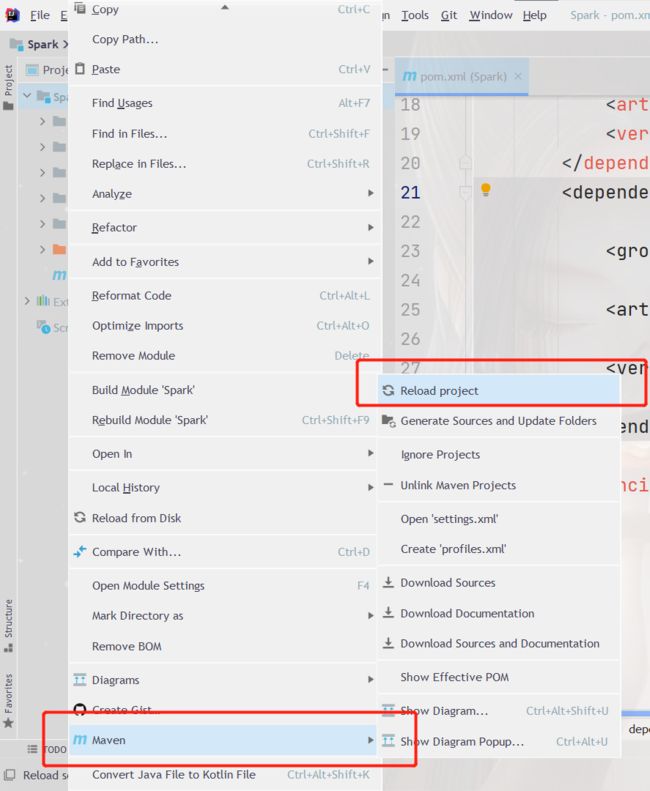
Maven中自带的依赖下载较缓慢,如未更改戳下配置
IDEA更改Maven镜像源
以上的HanLP配置仅仅满足基本使用,当处理的分词量较大,较杂需要更多的依赖时则失效,翻阅了各类论坛,搜寻资料,踩坑整理,写在了第二模块做为拓展部分,仅作记录,有需求的朋友目光下移。
②完整配置
问题引申
对于分词来说,StandardTokenizer标准分词器可用,但是NLPTokenizer分词器会出错,需要data包才能支持hanlp.properties,也就是可配置data,无需手动引入jar包
依赖获取
下载jar、data、hanlp.properties,
如下已给出HanLP1.7.6下载的依赖,追求更高版本的朋友,自行去官网搜寻即可
data.zip包含
dictionary和mode文件夹。
lhanlp-release.zip包含
hanlp-1.7.6.jar、hanlp-1.7.6-sources.jar以及最重要的hanlp.properties。
解决问题
解压data.zip得到data文件夹。
将解压后的data文件夹、hanlp.properties移动到java项目中,有开发经验的朋友默认选择放在resources目录下
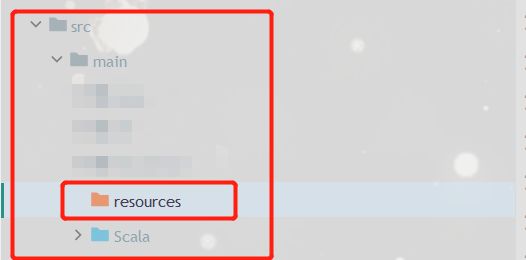
修改hanlp.properties中的root路径(data的父目录):
root=./src/main/resources
注:引入jar包(如果同时在Maven项目中引入就不需要此步骤),日常使用中配置Maven项目有个基础依赖即可解决大多数问题,完整配置在这里只是做个扩展,帮助有需求的朋友解决需求,避免去各类帖子踩坑,了解更多自行百度,不同IDAE配置方式不同。
HanLP使用
HanLP分词
import java.util
import com.hankcs.hanlp.HanLP
import com.hankcs.hanlp.seg.common.Term
import com.hankcs.hanlp.tokenizer.StandardTokenizer
import scala.collection.JavaConverters._
/**
* HanLP 入门案例,基本使用
*/
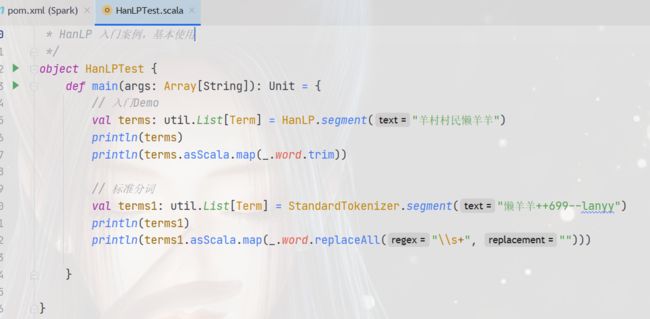
object HanLPTest {
def main(args: Array[String]): Unit = {
// 入门Demo
val terms: util.List[Term] = HanLP.segment("羊村村民懒羊羊")
println(terms)
//处理为数组展示
println(terms.asScala.map(_.word.trim))
// 标准分词
val terms1: util.List[Term] = StandardTokenizer.segment("懒羊羊++699--lanyy")
println(terms1)
println(terms1.asScala.map(_.word.replaceAll("\\s+", "")))
}
}
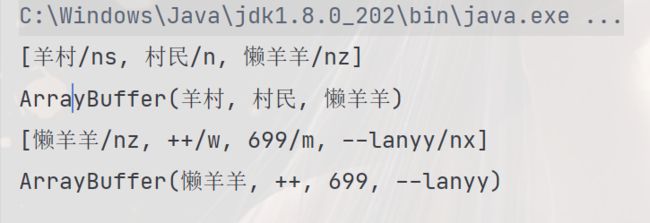
结果展示
[羊村/ns, 村民/n, 懒羊羊/nz]
ArrayBuffer(羊村, 村民, 懒羊羊)
[懒羊羊/nz, ++/w, 699/m, --lanyy/nx]
ArrayBuffer(懒羊羊, ++, 699, --lanyy)
更多实例请移步【官方GitHub-Demo】

了解更多知识请戳下:
@Author:懒羊羊