当我们做技术预研/业务起步的时候,功能性(Functionality)是最重要的,能跑通就行。对于最流行的C/S架构来说,下面的架构就是能满足功能需求的最简模式:
但随着的业务的发展,量级越来越大的时候,可伸缩性(Scalability)和高可用性(HighAvailability)都会逐渐变成非常重要的议题,除此以外可管理性(Manageability)和成本效益(Cost-effectiveness)都会在我们的考虑范围之内。本文重点关注业务发展中的高可用建设。
其实考虑到上面这些因素,LVS这个强大的模块几乎就是我们的必选项(有些场景中,LVS不是最佳选择,比如内网负载均衡),也是业务同学接触到最多的模块。下面让我们从LVS体验开始,一步步扩大视野看高可用是怎么做的。
注:本文不会讲解LVS的基础知识,欠缺的地方请大家自行Google。
LVS初体验
要一大堆机器做实验是不现实的,所以我们就在docker里面做实验。
第一步:创建网络:
docker network create south然后用 docker network inspect south 得到网络信息 "Subnet": "172.19.0.0/16","Gateway": "172.19.0.1"。也可以选择在 create 的时候用 --subnet 自行指定子网,就不用去查了。
第二步:创建RS
两台real server,rs1和rs2。Dockerfile如下
FROM nginx:stable
ARG RS=default_rs
RUN apt-get update \
&& apt-get install -y net-tools \
&& apt-get install -y tcpdump \
&& echo $RS > /usr/share/nginx/html/index.html分别构建和启动
docker build --build-arg RS=rs1 -t mageek/ospf:rs1 .
docker run -itd --name rs1 --hostname rs1 --privileged=true --net south -p 8888:80 --ip 172.19.0.5 mageek/ospf:rs1
docker build --build-arg RS=rs2 -t mageek/ospf:rs2 .
docker run -itd --name rs2 --hostname rs2 --privileged=true --net south -p 9999:80 --ip 172.19.0.6 mageek/ospf:rs2这里面比较重要的是privileged,没有这个参数,我们在容器内是没法绑定vip的(权限不够)。此外,启动时候固定ip也是便于后续lvs配置简单可重复
第三步:创建LVS
Dockerfile如下
FROM debian:stretch
RUN apt-get update \
&& apt-get install -y net-tools telnet quagga quagga-doc ipvsadm kmod curl tcpdump这里面比较重要的quagga是用来运行动态路由协议的,ipvsadm是lvs的管理软件。
启动lvs:
docker run -itd --name lvs1 --hostname lvs1 --privileged=true --net south --ip 172.19.0.3 mageek/ospf:lvs1依然需要privileged和固定ip。
第四步:VIP配置
LVS配置
docker exec -it lvs1 bash 进入容器。我们直接采用LVS最高效的模式,DR模式,以及最常见的负载策略:round_robin:
ipvsadm -A -t 172.19.0.100:80 -s rr
ipvsadm -a -t 172.19.0.100:80 -r 172.19.0.5 -g
ipvsadm -a -t 172.19.0.100:80 -r 172.19.0.6 -g
# 查看配置的规则
ipvsadm -Ln
# 启用
ifconfig eth0:0 172.19.0.100/32 upRS配置
ifconfig lo:0 172.19.0.100/32 up
echo "1">/proc/sys/net/ipv4/conf/all/arp_ignore
echo "1">/proc/sys/net/ipv4/conf/lo/arp_ignore
echo "2">/proc/sys/net/ipv4/conf/all/arp_announce
echo "2">/proc/sys/net/ipv4/conf/lo/arp_announce其中
arp_ignore是为了避免 rs 响应 arp 请求,确保 dst ip 是 vip 的包一定会路由到 lvs 上arp_announce是为了避免 r s在发起 arp 请求时用 vip 污染局域网中其它设备的 arp 表- 同一个配置写两遍,是为了确保生效,因为内核会选择 all 和具体网卡中的较大值
第五步:观察
进入 south 网络的另一个容器 switch(不要介意名字),访问 vip
> for a in {1..10}
> do
> curl 172.19.0.100
> done
rs2
rs1
rs2
rs1
rs2
rs1
rs2
rs1
rs2
rs1可见是 round robin 的模式。
再看看是否是 DR 模式
root@switch:/# curl 172.19.0.100
rs2
root@switch:/# curl 172.19.0.100
rs1
root@lvs1:/# tcpdump host 172.19.0.100
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
14:52:47.967790 IP switch.south.35044 > 172.19.0.100.http: Flags [S], seq 3154059648, win 64240, options [mss 1460,sackOK,TS val 1945546875 ecr 0,nop,wscale 7], length 0
14:52:47.967826 IP switch.south.35044 > 172.19.0.100.http: Flags [S], seq 3154059648, win 64240, options [mss 1460,sackOK,TS val 1945546875 ecr 0,nop,wscale 7], length 0
14:52:47.967865 IP switch.south.35044 > 172.19.0.100.http: Flags [.], ack 3324362778, win 502, options [nop,nop,TS val 1945546875 ecr 1321587858], length 0
14:52:47.967868 IP switch.south.35044 > 172.19.0.100.http: Flags [.], ack 1, win 502, options [nop,nop,TS val 1945546875 ecr 1321587858], length 0
14:52:47.967905 IP switch.south.35044 > 172.19.0.100.http: Flags [P.], seq 0:76, ack 1, win 502, options [nop,nop,TS val 1945546875 ecr 1321587858], length 76: HTTP: GET / HTTP/1.1
14:52:47.967907 IP switch.south.35044 > 172.19.0.100.http: Flags [P.], seq 0:76, ack 1, win 502, options [nop,nop,TS val 1945546875 ecr 1321587858], length 76: HTTP: GET / HTTP/1.1
14:52:47.968053 IP switch.south.35044 > 172.19.0.100.http: Flags [.], ack 235, win 501, options [nop,nop,TS val 1945546875 ecr 1321587858], length 0
14:53:15.037813 IP switch.south.35046 > 172.19.0.100.http: Flags [S], seq 2797683020, win 64240, options [mss 1460,sackOK,TS val 1945573945 ecr 0,nop,wscale 7], length 0
14:53:15.037844 IP switch.south.35046 > 172.19.0.100.http: Flags [S], seq 2797683020, win 64240, options [mss 1460,sackOK,TS val 1945573945 ecr 0,nop,wscale 7], length 0
14:53:15.037884 IP switch.south.35046 > 172.19.0.100.http: Flags [.], ack 1300058730, win 502, options [nop,nop,TS val 1945573945 ecr 1321614928], length 0
14:53:15.037887 IP switch.south.35046 > 172.19.0.100.http: Flags [.], ack 1, win 502, options [nop,nop,TS val 1945573945 ecr 1321614928], length 0
14:53:15.037925 IP switch.south.35046 > 172.19.0.100.http: Flags [P.], seq 0:76, ack 1, win 502, options [nop,nop,TS val 1945573945 ecr 1321614928], length 76: HTTP: GET / HTTP/1.1
14:53:15.037942 IP switch.south.35046 > 172.19.0.100.http: Flags [P.], seq 0:76, ack 1, win 502, options [nop,nop,TS val 1945573945 ecr 1321614928], length 76: HTTP: GET / HTTP/1.1
14:53:15.038023 IP switch.south.35046 > 172.19.0.100.http: Flags [.], ack 235, win 501, options [nop,nop,TS val 1945573945 ecr 1321614928], length 0
root@rs1:/# tcpdump host 172.19.0.100
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
14:53:15.037848 IP switch.south.35046 > 172.19.0.100.80: Flags [S], seq 2797683020, win 64240, options [mss 1460,sackOK,TS val 1945573945 ecr 0,nop,wscale 7], length 0
14:53:15.037873 IP 172.19.0.100.80 > switch.south.35046: Flags [S.], seq 1300058729, ack 2797683021, win 65160, options [mss 1460,sackOK,TS val 1321614928 ecr 1945573945,nop,wscale 7], length 0
14:53:15.037888 IP switch.south.35046 > 172.19.0.100.80: Flags [.], ack 1, win 502, options [nop,nop,TS val 1945573945 ecr 1321614928], length 0
14:53:15.037944 IP switch.south.35046 > 172.19.0.100.80: Flags [P.], seq 1:77, ack 1, win 502, options [nop,nop,TS val 1945573945 ecr 1321614928], length 76: HTTP: GET / HTTP/1.1
14:53:15.037947 IP 172.19.0.100.80 > switch.south.35046: Flags [.], ack 77, win 509, options [nop,nop,TS val 1321614928 ecr 1945573945], length 0
14:53:15.037995 IP 172.19.0.100.80 > switch.south.35046: Flags [P.], seq 1:235, ack 77, win 509, options [nop,nop,TS val 1321614928 ecr 1945573945], length 234: HTTP: HTTP/1.1 200 OK
14:53:15.038043 IP switch.south.35046 > 172.19.0.100.80: Flags [.], ack 235, win 501, options [nop,nop,TS val 1945573945 ecr 1321614928], length 0
root@rs2:/# tcpdump host 172.19.0.100
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
14:52:47.967830 IP switch.south.35044 > 172.19.0.100.80: Flags [S], seq 3154059648, win 64240, options [mss 1460,sackOK,TS val 1945546875 ecr 0,nop,wscale 7], length 0
14:52:47.967853 IP 172.19.0.100.80 > switch.south.35044: Flags [S.], seq 3324362777, ack 3154059649, win 65160, options [mss 1460,sackOK,TS val 1321587858 ecr 1945546875,nop,wscale 7], length 0
14:52:47.967869 IP switch.south.35044 > 172.19.0.100.80: Flags [.], ack 1, win 502, options [nop,nop,TS val 1945546875 ecr 1321587858], length 0
14:52:47.967908 IP switch.south.35044 > 172.19.0.100.80: Flags [P.], seq 1:77, ack 1, win 502, options [nop,nop,TS val 1945546875 ecr 1321587858], length 76: HTTP: GET / HTTP/1.1
14:52:47.967910 IP 172.19.0.100.80 > switch.south.35044: Flags [.], ack 77, win 509, options [nop,nop,TS val 1321587858 ecr 1945546875], length 0
14:52:47.967990 IP 172.19.0.100.80 > switch.south.35044: Flags [P.], seq 1:235, ack 77, win 509, options [nop,nop,TS val 1321587858 ecr 1945546875], length 234: HTTP: HTTP/1.1 200 OK
14:52:47.968060 IP switch.south.35044 > 172.19.0.100.80: Flags [.], ack 235, win 501, options [nop,nop,TS val 1945546875 ecr 1321587858], length 0
可见确实 lvs1 只会收到 switch 的包并转发给 rs(有来无回),而 rs1 和 rs2 和 switch 就是正常的三步握手后再进行 http 报文的传输(有来有回),是 DR 模式。
细心的同学发现了,lvs1 中怎么报文都出现了两次?
这是因为 DR 收到 IP 报文后,不修改也不封装 IP 报文,而是将数据帧的 MAC 地址改为选出服务器的 MAC 地址,再将修改后的数据帧在与服务器组相同的局域网上发送,如图所示: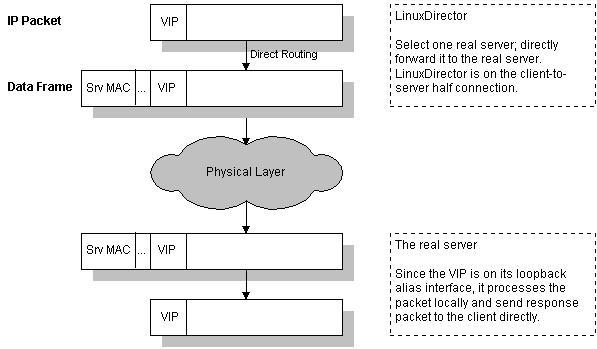
tcpdump是能抓到修改前后的包的,所以有两条。实际上,在tcpdump命令加上-e参数后,就能看到mac地址变化。
root@lvs1:/# tcpdump host 172.19.0.100 -e
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
15:58:57.245917 02:42:ac:13:00:02 (oui Unknown) > 02:42:ac:13:00:03 (oui Unknown), ethertype IPv4 (0x0800), length 74: switch.south.35070 > 172.19.0.100.http: Flags [S], seq 422105942, win 64240, options [mss 1460,sackOK,TS val 1949516153 ecr 0,nop,wscale 7], length 0
15:58:57.245950 02:42:ac:13:00:03 (oui Unknown) > 02:42:ac:13:00:05 (oui Unknown), ethertype IPv4 (0x0800), length 74: switch.south.35070 > 172.19.0.100.http: Flags [S], seq 422105942, win 64240, options [mss 1460,sackOK,TS val 1949516153 ecr 0,nop,wscale 7], length 0最后得到的架构如图:
RS高可用
上面我们配置了 LVS 后面两个 RS,这样能起到增大吞吐量的作用(伸缩性),但其实并没有做到 RS 的高可用,因为一台 RS 挂了后,LVS 依然会往该 RS 上打流量,造成这部分请求失败。所以我们还需要配置健康检查,当 LVS 检查到 RS 不健康的时候,主动剔除这台 RS,让流量不往这里打。这样就做到了RS的高可用,也就是说,RS 挂了一台后不影响业务(当然,实际场景还要考虑吞吐量、建连风暴、数据等问题)。
首先安装keepalived,装好后配置如下
global_defs {
lvs_id LVS1
}
virtual_server 172.19.0.100 80 {
delay_loop 5
lb_algo rr
lb_kind DR
persistence_timeout 50
protocol TCP
real_server 172.19.0.5 80 {
weight 2
HTTP_GET {
url {
path /
}
connect_timeout 3
retry 3
delay_before_retry 2
}
}
real_server 172.19.0.6 80 {
weight 2
HTTP_GET {
url {
path /
}
connect_timeout 3
retry 3
delay_before_retry 2
}
}
}然后启动:
chmod 644 /etc/keepalived/keepalived.conf
# 添加keepalived专用的用户
groupadd -r keepalived_script
useradd -r -s /sbin/nologin -g keepalived_script -M keepalived_script
# 启动
keepalived -C -D -d注意这里只用了 keepalived 的健康检查功能,没有用 VRRP 功能。
关闭 rs2 后,访问 vip 可以发现,vip 只会导向 rs1
root@switch:/# curl 172.19.0.100
rs1
root@switch:/# curl 172.19.0.100
rs1
root@switch:/# curl 172.19.0.100
rs1
root@switch:/# curl 172.19.0.100
rs1
root@switch:/# curl 172.19.0.100
rs1
root@switch:/# curl 172.19.0.100
rs1然后 lvs1 的 ipvs 配置也发生了变化
root@lvs1:/# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 172.19.0.100:80 rr
-> 172.19.0.5:80 Route 1 0 1当恢复 rs2 后,ipvs 配置恢复如初,针对 vip 发起的请求也在 rs1 和 rs2 之间均匀响应,实现了 RS 的高可用。
root@lvs1:/# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 172.19.0.100:80 rr
-> 172.19.0.5:80 Route 1 0 4
-> 172.19.0.6:80 Route 2 0 0LVS高可用
所谓高可用,其实核心就是冗余(当然,不止是冗余),所以我们可以用多台LVS来做高可用。这里又会有两种选择:一是主备模式,可以利用 Keepalived 的 VRRP 功能,但是大规模生产环境中,用集群模式更好,因为其同时提高了伸缩性和可用性,而前者只解决了可用性(当然,也更简单)。
架构分别如图:
| 主备模式 | 集群模式 |
|---|---|
 |
 |
简要说明一下原理:
- 主备模式: lvs主备之间运行 VRR P协议,日常态流量都从主走,当备检测到主挂了(停止收到主发来的VRRP通告后一段时间),便通过发送 free arp 来抢占vip,使得所有流量都从自己走,实现 failover
- 集群模式: lvs集群和上联交换机运行 OSPF,生成该 vip 的多路等价路由 ecmp,这样流量就能根据用户自定义的策略流向 lvs。当某台lvs挂了,交换机会将其从路由表中剔除,实现 failover
动态路由协议的配置过程比较复杂,限于篇幅这里就不展开了,大家感兴趣的可以自行Google。
到这里LVS相关的就看的差不多了,我们再往外延伸一下,看看其它领域是怎么做高可用的。
交换机/链路高可用
上面可以看到,做了 LVS 的高可用后,交换机又成了单点。实际上,交换机有很多方法做高可用,分为二层和三层:
三层
跟上面的LVS一样,利用VRRP实现交换机的主备高可用,也可以利用OSPF/ECMP实现集群高可用(当然,仅针对三层交换机)。
二层
这里简单举个例子,传统园区网络采用三层网络架构模型,如图所示
汇聚交换机和接入交换机之间通常就使用 STP/ MSTP(Spanning Tree Protocol),该协议算法在交换机有多条可达链路时只保留一条链路,其它链路在故障时启用。
另外还有 Smartlink,也能实现二层链路的主备模式。
此外,为了避免单台交换机故障,可以在服务器上挂主备网卡,双上联,当主网卡所在链路故障时,服务器启用备网卡所在链路即可,如图:
设备高可用
不管是交换机还是服务器、路由器等,最终都是放在机房机柜中,作为物理设备存在的,它们是怎么做高可用的呢?
物理设备,其可用性核心就是电源供应:
- 首先用到了UPS,主要就是储能技术:在市电供应时,给蓄电池充电;在市电断电时,将电池放电,给机柜供能。
- 其次用到了双路供电,也就是说,市电直接来源于两个供电系统,避免单个供电系统故障造成不可用
机房高可用
上面的过程保证了机房内部的可用性,那么整个机房挂了该怎么办?有不少方法能解决这个问题
DNS轮询
假设我们的业务域名为a.example.com,给他添加两条A记录,分别指向机房a和机房b。当a机房挂了,我们将a机房的A记录删除,这样所有用户就都只能拿到b机房的A记录,从而访问到b机房,实现高可用。
这种方式的问题在于 DNS 的 TTL 是不可控的,一般os、localDNS、权威DNS都会做缓存,尤其是其中的localDNS,一般都在运营商手中,尤为难控(运营商不一定严格按照TTL进行更新)。退一步来说,即使TTL都可控(比如用httpDNS),但这个TTL的设置比较难把握:太长则故障 failover 时间太长;太短则用户频繁发起 DNS 解析请求,影响性能。
所以目前这种方式都只作为高可用的辅助手段,而不是主要手段。
值得一提的是,F5 的 GTM 可以实现此功能,通过动态地给客户返回域名解析记录,实现就近、容错等效果。
优先级路由
主和备的地址都在路由范围内,但是优先级不同。这样日常情况流量都到主,当主挂掉并被检测到的时候,主的路由被删除,备的路由自动生效,这样就实现了主备failover。
路由优先级有几个理解:
- 不同协议形成的路由表是有优先级的,比如直连路由为0,OSPF 为 110,IBGP 为 200,当同一个目标地址有多个下一跳时,使用优先级更高的路由表。实践中,我还没见到过这种做法实现主备的。
- 同一个协议内,不同的路径是有优先级的,比如 OPSF 协议的 cost,日常主备路径的 cost 设置不一样,cost小的为主并被写入路由表走所有流量,当主挂掉了,其路径被路由表删除,备路径自动进入路由表。实践中,F5 LTM 的 route health injection 是利用这个原理实现主备的。
- 同一个协议内,路由匹配是讲究最长前缀的,比如路由表中有两个条目,172.16.1.0/24、172.16.2.0/24,当收到 dst ip 为 172.16.2.1 的包时,出于最长前缀匹配原则(越长越精准),就应该走172.16.2.0/24这一条路由。实践中,阿里云 SLB 利用此原理来做同城容灾。
Anycast
上面讲到了用 DNS 来高可用,那 DNS 本身也是需要做高可用的。DNS 高可用的一个重要手段就是 Anycast,这个手段也能被其他业务借鉴,所以我们也来看看。
互联网上目前真正落地的 EGP 就是 BGP(这也是互联网能互联互通的基石协议),通过不同的 AS 对外宣告同一个 IP,用户在访问这个IP的时候就能依据特定的策略访问到最佳的 AS(比如就近访问策略)。当某个 AS 中的服务挂掉且被 BGP 路由器检测到了,BGP 路由器会自动停止该 IP 对上联 AS 的广播,这样到该 IP 的用户流量就不会被路由到这个 AS 来,从而实现故障的 failover。
对于DNS来说,逻辑上,根域名服务器只有13个,但是利用Anycast,实际部署数量是远不止13的,不同国家和地区都可以自行部署根域名服务器的镜像,并且具备同样的IP,从而实现本地就近访问、冗余、安全等特性。
业务高可用
上面讲了一大堆的高可用,有这些方案后,业务是不是直接多地部署就实现了高可用了呢?当然不是。
仍以 DNS 为例,虽然全球都能部署根域名镜像服务器,但是真实的域名解析数据还是要从根域名服务器同步,这里面就有数据一致性问题,虽然 DNS 本身是个对数据一致性没那么高的服务,但是我们更多的服务都对数据一致性有要求(比如库存、余额等)。这也是上面说的,高可用虽然和冗余关系很大,但也不只是冗余,还要关注数据一致性等方面(也就是 CAP 定理)。这方面,不同的业务有不同的做法。
对于常见的web服务,可以通过对业务做自顶向下的流量隔离来实现高可用:将单个的用户的流量尽可能在一个单元处理完毕(单元封闭),这样当这个单元发生故障时,就能快速地将流量切到另一个单元,实现 failover,如图:
写在最后
上面每一个环节的高可用,其实并不需要每个企业自己投入。很多环节都已经有相当专业的云产品了。
企业全链路自建的话,既不专业(做不好),还会造成浪费(精力集中于主业,才不会错过商机)。
可用的产品有:
- LVS产品:阿里云ALB,华为ELB,腾讯CLB;
- DNS产品:阿里云/华为云解析DNS,腾讯云DNSPod;
- Anycast产品:阿里云Anycast EIP,腾讯云Anycast公网加速,
- 业务高可用产品:阿里云MSHA;
- 等等
最后,本文撰写过程中,思路比较发散,梳理不全面的地方,请大家批评指正。
参考
- Linux服务器集群系统(三)--LVS集群中的IP负载均衡技术: http://www.linuxvirtualserver...
- https://www.kernel.org/doc/Do...
- Case Study: Healthcheck — Keepalived 1.4.3 documentation: https://www.keepalived.org/do...
- VIPServer:阿里智能地址映射及环境管理系统详解_CSDN 人工智能-CSDN博客: https://blog.csdn.net/heyc861...
- 数据中心网络高可用架构-新华三集团-H3C: http://www.h3c.com/cn/d_20100...
- 阿里云云原生异地多活解决方案: https://baijiahao.baidu.com/s...
- AskF5 | Manual Chapter: Working with Dynamic Routing: https://techdocs.f5.com/kb/en...
- 阿里云SLB同城容灾方案-中存储网: https://www.chinastor.com/fan...