大数据简介:从数据到大数据,数据技术&工具的演变
最近在看大数据相关的书和资料,顺便梳理下笔记,于是有了本文
本文将用4张逻辑图为主线,简单介绍一个产品从“小数据”演化为“大数据”的过程,及可能用到的工具。
(以下内容主要来自书籍和网络查询资料,如有错误,还请指正)
↓↓↓本文核心逻辑↓↓↓
↓↓↓本文目录↓↓↓
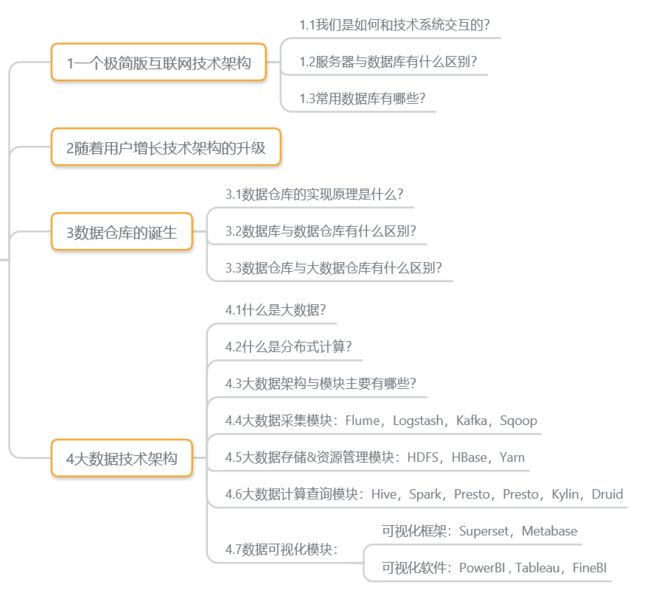
1.一个简陋版互联技术架构
假设我们要搭建一个小网站,在不使用成熟SaaS产品的前提下,我们的产品里面最少要有以下两个部分:

客户端:可以是APP,小程序,甚至是一个Web网站,作为入口给我们的用户访问。
服务端:服务端包括应用服务器和数据库,应用服务器用来部署应用端程序,处理前端请求,并进行服务响应;数据库用来存储数据,服务器通过专门与数据库交互的程序对数据库进行读写操作(如:SQL)
1.1我们是如何与技术系统交互的?
假设一个场景:
张三打开了一个了一个小网站,打开后出现了登录界面
张三输入自己的账号和密码之后点击“登录”
这时客户端会发送给服务端一个请求 ,查询查询一下数据库里有没有张三的账号信息
如果数据库有的话张三就能登录成功,可以使用小网站了
如果数据库没有张三的账号信息的话可能就会引导张三先进行注册
注册成功后数据库中的用户表中就会新增一条张三的信息
张三就能愉快的使用小网站了
我们通过客户端入口与这个系统交互,我们通过操作客户端界面,对服务端进行请求拉取服务器&数据库中的信息,给予我们反馈。
1.2服务器与数据库有什么区别?
一般我们常称为“服务器”的全称叫“应用服务器”,数据库全称叫“数据库服务器”,它们都是服务器,只是由于应用环境的不同,需要的性能不同做了区分。
数据库服务器的处理器性能要求比较高,因为其要进行频繁的操作,内存要求大,加快数据存取速度,应用服务器相对而言要求低一些。
1.3常用数据库有哪些?
常用数据库主要有“关系型数据库”和“非关系型数据库”
——关系型数据库:折射现实中的实体关系,将现实中的实体关系拆分维度,通过关系模型表达出来(表及表与表之间的关系),常用的有MySQL(开源数据库),SQL Server(微软家的),Oracle(甲骨文家的,有完善的数据管理功能可以实现数据仓库操作)
——非关系型数据库:一种相对松散且可以不按严格结构规范进行存储的数据库,一边叫NoSQL(常用的有mongoDB , CouchDB,在MongoDB中使用键值对的方式表示和存储数据,键值类似关系型数据库表中的字段名对应的值,在MngoDB中,使用JSON格式的数据进行数据表示和存储)
2.随着用户增长技术架构的升级
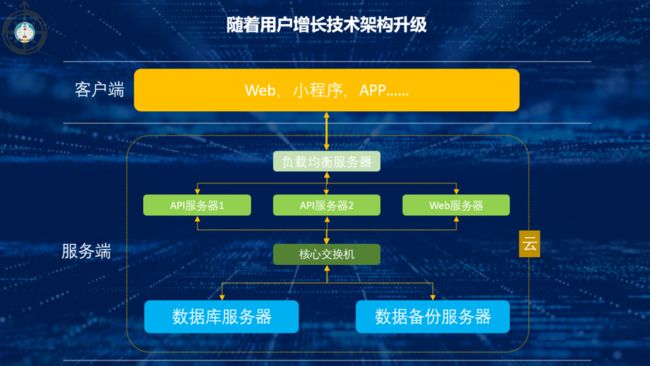
小网站的用户逐渐越来越多,小网站变成了大网站,单个服务器的负载很快就到了极限,这时就需要增加多台服务器,组成服务器组,同时引入负载均衡服务器,对流量进行动态分配。
由于数据是互联网产品的核心资产,为了保证系统数据的安全性,还需要增加数据备份服务器,多台数据库服务器同时运行,这样哪怕一个数据库出问题了,也不会影响业务正常运转。
3.数据仓库的诞生
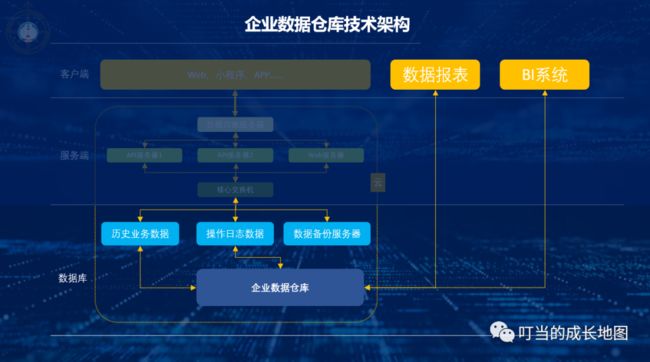
随着产品用户量越来越大,市场竞争也更加激烈,迫切需要更加准确的战略决策信息,数据库中的数据虽然对于产品的运营非常有用,但由于结构复杂,数据脏乱,难以理解,确少历史,大规模查询等问题对商业决策和目标制定的作用甚微。
在更好的发挥数据价值,1990数据仓库之父比尔·恩门(Bill Inmon)提出了“数据仓库”的概念,构建一种对历史数据进行存储和分析的数据系统,支撑企业的商业分析与战略决策。
3.1数据仓库的实现原理是什么?
数据仓库的数据来源通常是历史业务数据(订单数据,商品数据,用户数据,操作日志,行为数据……)这些数据统一汇总存储至企业数据仓库,通过对仓库里的综合数据进行有目的的分析支撑业务决策。
3.2数据库与数据仓库有什么区别?
数据库是对实时数据进行存储和事务性处理的系统,而数据仓库则是为了分析而设计。
3.3数据仓库与大数据仓库有什么区别?
数据仓库与大数据仓库的区别:大数据=海量数据+处理技术+平台工具+场景应用,数据仓库是一个数据开发过程,其区别主要体现在商业价值,处理对象,生产工具,三个方面。
——商业价值:都是业务驱动的,有明确的业务场景需求,通过海量数据分析为业务提供决策依据,“传统数仓”出现更早,场景单一保守(报表,BI);而大数据技术更成熟成本更低,应用场景更多(用户画像,推荐,风控,搜索……)
——处理对象:都是对数据进行获取,加工,管理,治理,应用处理,但大数据处理数据类型更多样化,传统数仓基本只擅长处理结构化和半结构化的数据。
——生产工具:“传统数仓”一般采购国外知名厂商成熟方案,价格昂贵可拓展性差,“大数据”则有成套的开源技术——建设方法:大数据技术沿用了“传统数仓的数据建设理论,但由于在处理技术上新增了非结构化数据,生产工具上新增了流式计算(比实时计算要稍微迟钝些,但比离线计算又实时的多)
4.大数据技术架构
4.1什么是大数据?
一种规模大到在获取、存储、管理、分析方面大大超出了传统数据库软件工具能力范围的数据集合,具有海量的数据规模(一般以TB为起始单位)、快速的数据流转、多样的数据类型和价值密度低四大特征。
根据“海量的数据规模”,“快速的数据流转”,“多样的数据类型”,“价值密度低”去看,符合这些特点的大都是平台型公司,有海量用户产生内容。
Facebook基础设施工程副总裁杰·帕里克(Jay Parikh)曾透露,Facebook每天处理的数据量多达500TB(1TB=1000GB)。
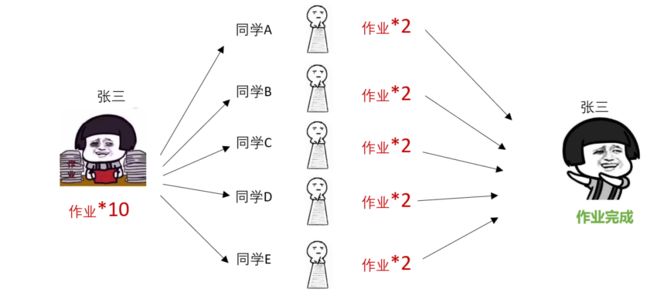
4.2什么是分布式计算?
看完上面,你可能会想,像Facebook每天500TB的数据量要用什么样的技术才能处理呢?
这就要引入“分布式计算”了,既然单个数据库的计算能力有限,那我们就把大量的数据分割成多个小块,由多台计算机分工完成,然后将结果汇总,这些执行分布式计算的计算机叫做集群。
如果还不理解的话我们举个栗子:
假期要结束了张三还有有10份作业没写,他找了5个同学,每个同学写2份,最后汇总给张三。
大数据时代存储计算的经典模型,Apache基金会名下的Hadhoop系统,核心就是采用的分布式计算架构,也是Yahoo、IBM、Facebook、亚马逊、阿里巴巴、华为、百度、腾讯等公司,都采用技术架构。(下方逻辑图中黄框部分都是Hadoop生态的成员)
4.3大数据架构与模块主要有哪些?
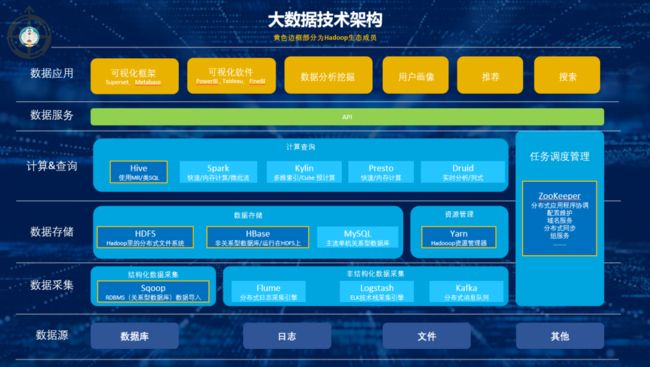
大数据架构主要可以分为:数据采集,数据存储,计算查询,数据服务,数据应用5个环节。
——数据采集:通过采集工具把结构化数据进行采集,分发,校验,清洗转换;非结构化数据通过爬取,分词,信息抽取,文本分类,存入数据仓库中。
——数据存储:一般分3层,最底层的式ODS(操作数据)层,直接存放业务系统抽取过来的数据,将不同业务系统中的数据汇聚在一起;中间是DW(数据仓库)层,存放按照主题建立的各种数据模型;最上层是DM(数据集市)层,基于DW层上的基础数据整合汇总成分析某一个主题域的报表数据。
——计算查询:根据具体的需求选择对应的解决方案,离线,非实时,静态数据的可以用批处理方案;非离线,实时,动态数据,低延迟的场景可用流处理方案。
——数据服务:通过API把数仓中海量的数据高效便捷的开放出去支撑业务,发挥数据价值。
——数据应用:基于数据仓库中结构清晰的数据高效的构建BI系统支撑业务决策;根据海量的数据构建以标签树为核心的用户画像系统,为个性化推荐,搜索,等业务模块提供支撑。
4.4大数据采集模块

一般应用于公司日志平台,将数据缓存在某个地方,供后续的计算流程进行使用 针对不同数据源(APP,服务器,日志,业务表,各种API接口,数据文件……)有各自的采集方式 目前市面上针对日志采集的有 Flume, Logstash,Kafka……
——Flume:是一款 Cloudera 开发的实时采集日志引擎,主打高并发,高速度,分布式海量日志采集,支持在日志系统中定制各类数据发送,支持对数据简单处理并写给各种数据接受方,主要特点:
-
侧重数据传输,有内部机制确保不会丢数据,用于重要日志场景
-
由java开发,没有丰富的插件,主要靠二次开发
-
配置繁琐,对外暴露监控端口有数据 最初定位是把数据传入HDFS中,跟侧重于 数据传输和安全,需要更多二次开发配置
——Logstash:是 Elastic旗下的一个开源数据收集引擎,可动态的统一不同的数据源的数据至目的地,搭配 ElasticSearch 进行分析,Kibana 进行页面展示,主要特点:
-
内部没有一个persist queue(存留队列),异常情况可能会丢失部分数据
-
由ruby编写,需要ruby环境,插件很多
-
配置简单,偏重数据前期处理,分析方便 侧重对日志数据进行预处理为后续解析做铺垫,搭配ELK技术栈使用简单。
——Kafka:最初是由领英开发,2012 年开源由Apache Incubato孵化出站 以为处理实时数据提供一个统一,高吞吐,低延迟的平台 适合作为企业级基础设施来处理流式数据 (本质是:按照分布式事务日志架构的大规模发布/订阅消息队列)
——Sqoop:与上面的日志采集工具不同,Sqoop的主要功能是为 Hadoop 提供了方便的 RDBMS(关系型数据库)数据导入功能,使得传统数据库数据向 HBase 中迁移变的非常方便
4.5大数据存储&资源管理模块

在数据量小的时候一般用单机数据库(如:MySQL) 但当数据量大到一定程度就必须采用分布式系统了,Apache基金会名下的Hadhoop系统是大数据时代存储计算的经典模型。
——HDFS :是 Hadoop里的分布式文件系统,为HBase 和 Hive提供了高可靠性的底层存储支持
——HBase:是Hadoop数据库,作为基于非关系型数据库运行在HDFS上,具备HDFS缺乏的随机读写能力,比较适合实时分析。
——Yarn:是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
4.6大数据计算查询模块
这里首先要介绍一下批处理和流处理的区别:
批计算:离线场景,静态数据,非实时,高延迟(场景:数据分析,离线报表……)
流计算:实时场景,动态数据,实时,低延迟(场景:实时推荐,业务监控……)
大数据常用的计算查询引擎主要有:Hive,Spark,Presto,Presto,Kylin,Druid

——Hive:是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。其优点是学习成本低
——Spark: Spark 则是加州大学伯克利分校AMP实验室所开源的专门用于大数据量下的迭代式计算.是为了跟 Hadoop 配合。
批处理模式下的类Hadoop MapReduce的通用并行框架, ,Spark 与 MapReduce 不同,它将数据处理工作全部在内存中进行,提高计算性能;
流处理模式下,Spark 主要通过 Spark Streaming 实现了一种叫做微批(Micro-batch)的概念可以将数据流视作一系列非常小的“批”,借此即可通过批处理引擎的原生语义进行处理。
Spark适合多样化工作负载处理任务的场景,在批处理方面适合众数吞吐率而非延迟的工作负载。SparkSQL兼容可以把Hive作为数据源spark作为计算引擎。
——Presto:由 Facebook 开源,是一个分布式数据查询框架,原生集成了 Hive、 Hbase 和关系型数据库。但背后的执行模式跟Spark类似,所有的处理都在内存中完成,大部分场景下要比 Hive 快一个数量级。
——Kylin:Cube 预计算技术是其核心,基本思路是预先对数据作多维索引,查询时只扫描索引而不访问原始数据从而提速。劣势在于每次增减维度必须对 Cube 进行历史数据重算追溯,非常消耗时间。
——Druid:由 MetaMarket 开源,是一个分布式、面向列式存储的准实时分析数据存储系统,延迟性最细颗粒度可到 5 分钟。它能够在高并发环境下,保证海量数据查询分析性能,同时又提供海量实时数据的查询、分析与可视化功能。
3.7数据可视化模块

3.7.1可视化框架
开源可视化框架: 业界比较有名的式Superset和Metabase
Superset的方案更加完善,支持聚合不同数据源形成对应的指标,再通过丰富的图表类型进行可视化,在时间序列分析上比较出色,与Druid深度集成,可快速解析大规模数据集,但不支持分组管理和图表下钻及联动功能,权限管理不友好。
Metabase比较重视非技术人员的使用体验,界面更加美观,权限管理上做的比较完善,无需账号也可以对外共享图表和数据内容,但在时间序列分析上 不支持不同日期对比,还需要自动逸SQL实现,每次查询只能针对一个数据库,操作比较繁琐。
3.7.2可视化软件:
商用软件主流的主要有:PowerBI , Tableau,FineBI
| 软件 | 上手难度 | 自由度 | 价格 |
| PowerBI | 高 | 高 | ¥780/人/年 |
| Tableau | 中 | 低 | ¥60000+/人/年 |
| FineBI | 中 | 低 | 几十万/永久 |
——Tableau:操作简单,可视化,基本所有的功能都可以拖拽实现,但价格贵,且数据清洗功能一般,需要有较好的数据仓库支持
——FineBI:操作简单,与Tableau类似,但数据清洗能力比Tableau要好,付费方式采用按功能模块收费,永久买断。
——PowerBI :可以做复杂报表,筛选、计算逻辑清晰,可自定义,但很多功能要用DAX编程序,托拉拽能实现的功能很有限,不易入门。
【参考资料】
《产品经理必懂得技术那点事儿》作者唐韧
《大数据架构商业之路》作者黄申
深入浅出大数据:到底什么是Hadoop?:https://mp.weixin.qq.com/s/cTJ_j1s2oUHPZEh1TdfFUg
一篇文章读懂大数据中台架构:https://mp.weixin.qq.com/s/3dktekrWZKmEuVGhQuPfsQ