Day49_Hbase入门(二)
4、需求三:使用Java代码删除表
实现步骤:
- 判断表是否存在
- 如果存在,则禁用表
- 再删除表
参考代码:
// 删除表
@Test
public void dropTable() throws IOException {
// 表名
TableName tableName = TableName.valueOf("WATER_BILL");
// 1. 判断表是否存在
if(admin.tableExists(tableName)) {
// 2. 禁用表
admin.disableTable(tableName);
// 3. 删除表
admin.deleteTable(tableName);
}
}
5、需求二:往表中插入一条数据
(1)创建包
- 在 java 目录中创建 com.offcn.hbase.data.api_test 包
- 创建DataOpTest类
(2)初始化Hbase连接
在@BeforeTest中初始化HBase连接,在@AfterTest中关闭Hbase连接。
参考代码:
package com.offcn.hbase.data.api_test;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.junit.After;
import org.junit.Before;
public class DataOpTest {
private Configuration conf ;
private Connection conn ;
@Before
public void beforeOp()throws Exception {
// 1 获取配置对象
conf = HBaseConfiguration.create();
// 指定zookeeper地址
conf.set("hbase.zookeeper.quorum","bd-offcn-01,bd-offcn-02,bd-offcn-03");
// 2 获取与hbase的链接
conn = ConnectionFactory.createConnection(conf);
}
@After
public void afterOp()throws Exception {
// 4 关闭资源
conn.close();
}
}
(3)插入姓名列数据
在表中插入一个行,该行只包含一个列。
| ROWKEY |
姓名(列名:NAME) |
| 4944191 |
登卫红 |
实现步骤:
- 使用Hbase连接获取Htable
- 构建ROWKEY、列蔟名、列名
- 构建Put对象(对应put命令)
- 添加姓名列
- 使用Htable表对象执行put操作
- 关闭Htable表对象
参考代码:
@Test // 数据的操作都是用Htable对象来完成
public void insertOneData()throws Exception {
//1. 使用Hbase连接获取Htable
TableName tableName = TableName.valueOf("WATER_BILL");
Table waterTable = conn.getTable(tableName);
//2. 构建ROWKEY、列蔟名、列名
String rowkey = "4944191";
String columnFamily = "C1";
String columnQualifier = "NAME";
String columnValue = "登卫红";
//3. 构建Put对象(对应put命令)
Put put = new Put(Bytes.toBytes(rowkey));
//4. 添加姓名列
put.addColumn(Bytes.toBytes(columnFamily),Bytes.toBytes(columnQualifier),Bytes.toBytes(columnValue));
//5. 使用Htable表对象执行put操作
waterTable.put(put);
//6. 关闭Htable表对象
waterTable.close();
}
(4)查看HBase中的数据
get 'WATER_BILL','4944191',{FORMATTER => 'toString'}
(5)插入其他列
| 列名 |
说明 |
值 |
| ADDRESS |
用户地址 |
贵州省铜仁市德江县7单元267室 |
| SEX |
性别 |
男 |
| PAY_DATE |
缴费时间 |
2020-05-10 |
| NUM_CURRENT |
表示数(本次) |
308.1 |
| NUM_PREVIOUS |
表示数(上次) |
283.1 |
| NUM_USAGE |
用量(立方) |
25 |
| TOTAL_MONEY |
合计金额 |
150 |
| RECORD_DATE |
查表日期 |
2020-04-25 |
| LATEST_DATE |
最迟缴费日期 |
2020-06-09 |
参考代码:
@Test
public void addTest() throws IOException {
// 1.使用Hbase连接获取Htable
TableName waterBillTableName = TableName.valueOf("WATER_BILL");
Table waterBillTable = connection.getTable(waterBillTableName);
// 2.构建ROWKEY、列蔟名、列名
String rowkey = "4944191";
String cfName = "C1";
String colName = "NAME";
String colADDRESS = "ADDRESS";
String colSEX = "SEX";
String colPAY_DATE = "PAY_DATE";
String colNUM_CURRENT = "NUM_CURRENT";
String colNUM_PREVIOUS = "NUM_PREVIOUS";
String colNUM_USAGE = "NUM_USAGE";
String colTOTAL_MONEY = "TOTAL_MONEY";
String colRECORD_DATE = "RECORD_DATE";
String colLATEST_DATE = "LATEST_DATE";
// 3.构建Put对象(对应put命令)
Put put = new Put(Bytes.toBytes(rowkey));
// 4.添加姓名列
put.addColumn(Bytes.toBytes(cfName)
, Bytes.toBytes(colName)
, Bytes.toBytes("登卫红"));
put.addColumn(Bytes.toBytes(cfName)
, Bytes.toBytes(colADDRESS)
, Bytes.toBytes("贵州省铜仁市德江县7单元267室"));
put.addColumn(Bytes.toBytes(cfName)
, Bytes.toBytes(colSEX)
, Bytes.toBytes("男"));
put.addColumn(Bytes.toBytes(cfName)
, Bytes.toBytes(colPAY_DATE)
, Bytes.toBytes("2020-05-10"));
put.addColumn(Bytes.toBytes(cfName)
, Bytes.toBytes(colNUM_CURRENT)
, Bytes.toBytes("308.1"));
put.addColumn(Bytes.toBytes(cfName)
, Bytes.toBytes(colNUM_PREVIOUS)
, Bytes.toBytes("283.1"));
put.addColumn(Bytes.toBytes(cfName)
, Bytes.toBytes(colNUM_USAGE)
, Bytes.toBytes("25"));
put.addColumn(Bytes.toBytes(cfName)
, Bytes.toBytes(colTOTAL_MONEY)
, Bytes.toBytes("150"));
put.addColumn(Bytes.toBytes(cfName)
, Bytes.toBytes(colRECORD_DATE)
, Bytes.toBytes("2020-04-25"));
put.addColumn(Bytes.toBytes(cfName)
, Bytes.toBytes(colLATEST_DATE)
, Bytes.toBytes("2020-06-09"));
// 5.使用Htable表对象执行put操作
waterBillTable.put(put);
// 6. 关闭表
waterBillTable.close();
}
6、需求三:查看一条数据
查询rowkey为4944191的所有列的数据,并打印出来。
实现步骤:
- 获取HTable
- 使用rowkey构建Get对象
- 执行get请求
- 获取所有单元格
- 打印rowkey
- 迭代单元格列表
- 关闭表
参考代码:
@Test
public void getData()throws Exception {
//1. 获取HTable
TableName waterBillTableName = TableName.valueOf("WATER_BILL");
Table waterBillTable = conn.getTable(waterBillTableName);
//2. 使用rowkey构建Get对象
String rowkey = "4944191";
Get get = new Get(Bytes.toBytes(rowkey));
// get.addFamily()
// get.addColumn()
//3. 执行get请求
Result result = waterBillTable.get(get);
byte[] row = result.getRow();
//4. 获取所有单元格
List| cells = result.listCells();
//5. 打印rowkey
System.out.println("rowkey:"+Bytes.toString(row));
//6. 迭代单元格列表
for (Cell cell : cells) {
// 每个cell就是由列名和列值组成的
// 参数1:列名的字节数组 参数2:列名的第一个字符的偏移量 参数3: 列名的长度
System.out.print(Bytes.toString(cell.getQualifierArray(),cell.getQualifierOffset(),cell.getQualifierLength()));
System.out.println(":"+Bytes.toString(cell.getValueArray(),cell.getValueOffset(),cell.getValueLength()));
// System.out.print(Bytes.toString(cell.getQualifierArray()));
// System.out.println(":"+Bytes.toString(cell.getValueArray()));
}
//7. 关闭表
waterBillTable.close();
}
| 7、需求四:删除一条数据
删除rowkey为4944191的整条数据。
实现步骤:
- 获取HTable对象
- 根据rowkey构建delete对象
- 执行delete请求
- 关闭表
参考代码:
@Test
public void deleteData()throws Exception {
//1. 获取HTable
TableName waterBillTableName = TableName.valueOf("WATER_BILL");
Table waterBillTable = conn.getTable(waterBillTableName);
// 2 构建delete对象
String rowkey = "4944191";
Delete delete = new Delete(Bytes.toBytes(rowkey));
// delete.addFamily();
//delete.addColumn();
waterBillTable.delete(delete);
//3. 关闭表
waterBillTable.close();
}
8、需求五:导入数据
(1)需求
现在有一份10W的抄表数据文件,我们需要将这里面的数据导入到HBase中。

(2)Import JOB
在HBase中,有一个Import的MapReduce作业,可以专门用来将数据文件导入到HBase中。
用法
hbase org.apache.hadoop.hbase.mapreduce.Import 表名 HDFS数据文件路径
(3)导入数据
1、将资料中数据文件上传到Linux中
2、再将文件上传到hdfs中
hadoop fs -mkdir -p /water_bill/output_ept_10W
hadoop fs -put part-m-00000_10w /water_bill/output_ept_10W
3、启动YARN集群
start-yarn.sh
4、使用以下方式来进行数据导入
hbase org.apache.hadoop.hbase.mapreduce.Import WATER_BILL /water_bill/output_ept_10W
5、导出数据
hbase org.apache.hadoop.hbase.mapreduce.Export WATER_BILL /water_bill/output_ept_10W_export
9、需求六:查询2020年6月份所有用户的用水量
(1)需求分析
在Java API中,我们也是使用scan + filter来实现过滤查询。2020年6月份其实就是从2020年6月1日到2020年6月30日的所有抄表数据。
(2)准备工作
- 在com.offcn.hbase.data.api_test包下创建ScanFilterTest类
- 使用@Before、@After构建HBase连接、以及关闭HBase连接
(3)实现
实现步骤:
- 获取表
- 构建scan请求对象
- 构建两个过滤器
- 构建两个日期范围过滤器(注意此处请使用C1列族,RECORD_DATE列名——抄表日期比较 2020-06-01 2020-06-30
- 构建过滤器列表
- 执行scan扫描请求
- 迭代打印result
- 迭代单元格列表
- 关闭ResultScanner(这玩意把转换成一个个的类似get的操作,注意要关闭释放资源)
- 关闭表
参考代码:
(2)准备工作
1. 在com.offcn.hbase.data.api_test包下创建ScanFilterTest类
2. 使用@Before、@After构建HBase连接、以及关闭HBase连接
(3)实现
实现步骤:
1. 获取表
2. 构建scan请求对象
3. 构建两个过滤器
a) 构建两个日期范围过滤器(注意此处请使用C1列族,RECORD_DATE列名——抄表日期比较 2020-06-01 2020-06-30
b) 构建过滤器列表
4. 执行scan扫描请求
5. 迭代打印result
6. 迭代单元格列表
7. 关闭ResultScanner(这玩意把转换成一个个的类似get的操作,注意要关闭释放资源)
8. 关闭表
参考代码:
@Test
public void scanOnTimeData()throws Exception {
//1. 获取表
TableName waterBillTableName = TableName.valueOf("WATER_BILL");
Table waterBillTable = conn.getTable(waterBillTableName);
//2. 构建scan请求对象
Scan scan = new Scan();
//3. 构建两个过滤器
//a) 构建两个日期范围过滤器(注意此处请使用C1列族,RECORD_DATE列名——抄表日期比较 2020-06-01 2020-06-30
SingleColumnValueFilter startDate = new SingleColumnValueFilter(
Bytes.toBytes("C1"),
Bytes.toBytes("RECORD_DATE"),
CompareOperator.GREATER_OR_EQUAL,
Bytes.toBytes("2020-06-01"));
SingleColumnValueFilter endDate = new SingleColumnValueFilter(
Bytes.toBytes("C1"),
Bytes.toBytes("RECORD_DATE"),
CompareOperator.LESS_OR_EQUAL,
Bytes.toBytes("2020-06-30"));
//b) 构建过滤器列表
FilterList filterList = new FilterList(FilterList.Operator.MUST_PASS_ALL, startDate, endDate);
scan.setFilter(filterList);
//4. 执行scan扫描请求
ResultScanner scanner = waterBillTable.getScanner(scan);
//5. 迭代打印result
for (Result result : scanner) {
byte[] row = result.getRow();
System.out.println("rowkey:"+Bytes.toString(row));
List| cells = result.listCells();
//6. 迭代单元格列表
for (Cell cell : cells) {
String colName = Bytes.toString(cell.getQualifierArray(), cell.getQualifierOffset(), cell.getQualifierLength());
System.out.print(colName);
if(colName.equals("NUM_CURRENT")
|| colName.equals("NUM_PREVIOUS")
|| colName.equals("NUM_USAGE")
|| colName.equals("TOTAL_MONEY")) {
System.out.println(":" + Bytes.toDouble(cell.getValueArray(), cell.getValueOffset()));
}
else {
System.out.println(":" + Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength()));
}
}
System.out.println("=================================================");
}
//7. 关闭ResultScanner(这玩意把转换成一个个的类似get的操作,注意要关闭释放资源)
scanner.close();
//8. 关闭表
waterBillTable.close();
}
| (4)解决乱码问题
因为前面我们的代码,在打印所有的列时,都是使用字符串打印的,Hbase中如果存储的是int、double,那么有可能就会乱码了。
System.out.print(Bytes.toString(cell.getQualifierArray(), cell.getQualifierOffset(), cell.getQualifierLength()));
System.out.println(" => " + Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength()));
要解决的话,我们可以根据列来判断,使用哪种方式转换字节码。如下:
- NUM_CURRENT
- NUM_PREVIOUS
- NUM_USAGE
- TOTAL_MONEY
这4列使用double类型展示,其他的使用string类型展示。
参考代码:
String colName = Bytes.toString(cell.getQualifierArray(), cell.getQualifierOffset(), cell.getQualifierLength());
System.out.print(colName);
if(colName.equals("NUM_CURRENT")
|| colName.equals("NUM_PREVIOUS")
|| colName.equals("NUM_USAGE")
|| colName.equals("TOTAL_MONEY")) {
System.out.println(" => " + Bytes.toDouble(cell.getValueArray(), cell.getValueOffset()));
}
else {
System.out.println(" => " + Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength()));
}
(七)HBase高可用
考虑关于HBase集群的一个问题,在当前的HBase集群中,只有一个Master,一旦Master出现故障,将会导致HBase不再可用。所以,在实际的生产环境中,是非常有必要搭建一个高可用的HBase集群的。
(1)HBase高可用简介
HBase的高可用配置其实就是HMaster的高可用。要搭建HBase的高可用,只需要再选择一个节点作为HMaster,在HBase的conf目录下创建文件backup-masters,然后再backup-masters添加备份Master的记录。一条记录代表一个backup master,可以在文件配置多个记录。
(2)搭建HBase高可用
1. 在hbase的conf文件夹中创建 backup-masters 文件
cd /home/offcn/apps/hbase-2.2.4/conf
touch backup-masters
2. 将bd-offcn-02和bd-offcn-03添加到该文件中
vim backup-masters
bd-offcn-02
bd-offcn-03
3. 将backup-masters文件分发到所有的服务器节点中
scp backup-masters bd-offcn-02:$PWD
scp backup-masters bd-offcn-03:$PWD
4. 重新启动hbase
stop-hbase.sh
start-hbase.sh
5.查看webui,检查Backup Masters中是否有bd-offcn-02、bd-offcn-03
http://bd-offcn-01:16010/master-status
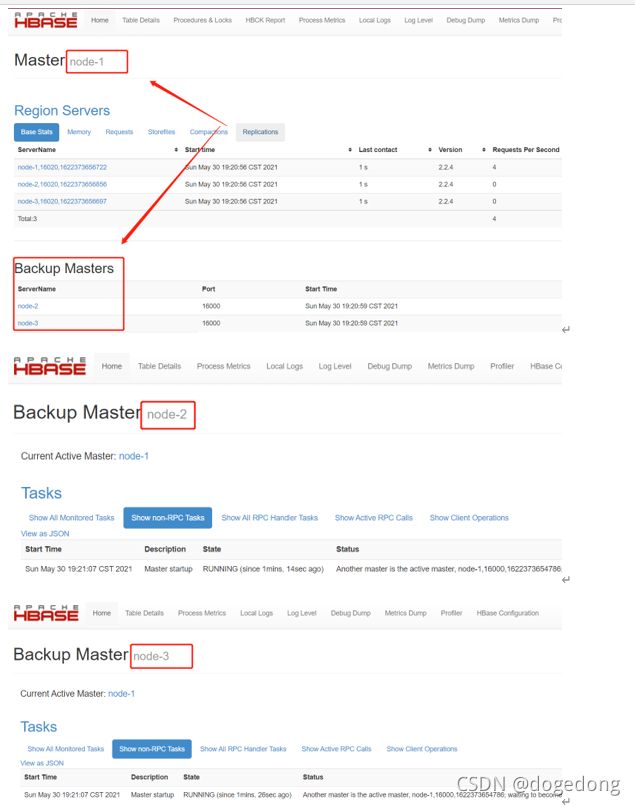
6. 尝试杀掉bd-offcn-01节点上的master
kill -9 HMaster进程id
7. 访问http://bd-offcn-02:16010和http://bd-offcn-03:16010,观察是否选举了新的Master
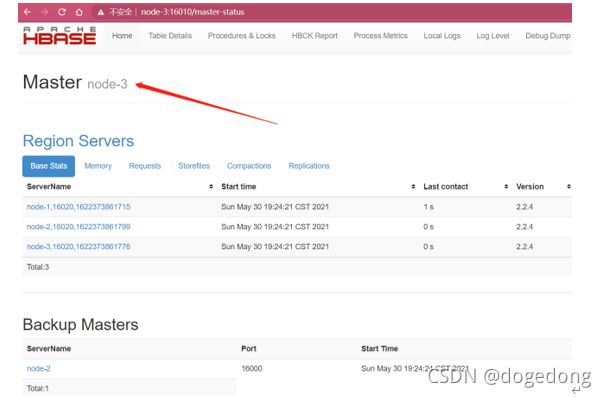
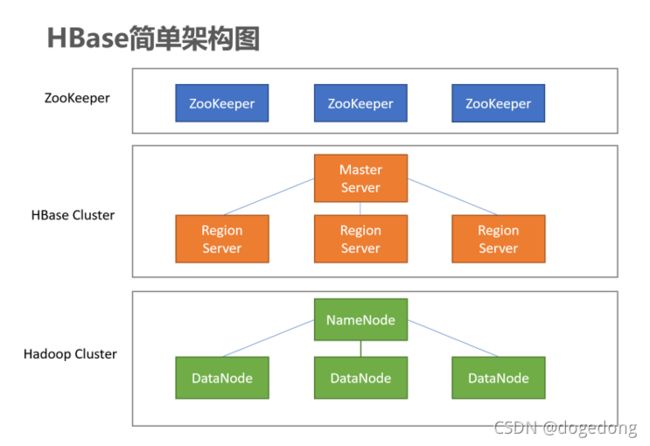
(八) HBase架构
1、系统架构
元数据:是指描述数据的数据,在不同的情景下,含义不一样
hdfs:元数据是指 类似文件名、文件的权限、文件的所有者这样信息的记录。这些元数据存放到了image、edits编辑日志。
hive:元数据是指hdfs目录与表的对应,hdfs目录里面结构化文件中的列与表的字段的对应关系,这些元数据存放到了mysql数据库
hbase:hbase的表是由若干个region组成的,某一条数据肯定位于某个表的,那个表?需要记录一下,是存在于某个region之上的,哪个region?需要记录一下,这个region由哪个regionserver管理,也需要记录一下,这些记录就是元数据,这些元数据存放到hbase的meta表,meta是由regionservere维护的,哪个呢?zookeeper记录着meta在哪个reginserver上。 体现出了zookeeper的什么作用呢?它掌管着元数据的入口。
(1)Client
客户端,例如:发出HBase操作的请求。例如:之前我们编写的Java API代码、以及HBase shell,都是CLient
(2)Master Server
在HBase的Web UI中,可以查看到Master的位置。
- 监控RegionServer
- 处理RegionServer故障转移
- 处理元数据的变更
- 处理region的分配或移除
- 在空闲时间进行数据的负载均衡
- 通过Zookeeper发布元数据的位置给客户端
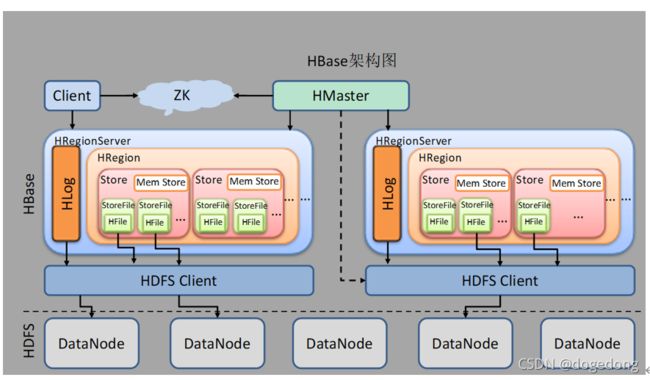
(3)Region Server

- 处理分配给它的Region
- 负责存储HBase的实际数据
- 刷新缓存到HDFS
- 维护HLog
- 执行压缩
- 负责处理Region分片(分region)
- RegionServer中包含了大量丰富的组件,如下:
- Write-Ahead logs
- HFile(StoreFile)
- Store
- MemStore
- Region
(4)Zookeeper
HBase通过Zookeeper来做master的高可用、RegionServer的监控、元数据的入口以及集群配置的维护等工作。具体工作如下:
通过Zoopkeeper来保证集群中只有1个master在运行,如果master异常,会通过竞争机制产生新的master提供服务
通过Zoopkeeper来监控RegionServer的状态,当RegionSevrer有异常的时候,通过回调的形式通知Master RegionServer上下线的信息
通过Zoopkeeper存储元数据的统一入口地址
2、逻辑结构模型
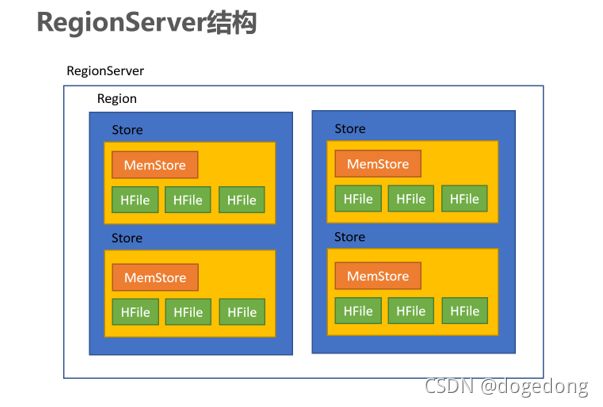
(1)Region
- 在HBASE中,表被划分为很多「Region」,并由Region Server提供服务

2)Store
- Region按列蔟垂直划分为「Store」,存储在HDFS在文件中
(3)MemStore
- MemStore与缓存内存类似
- 当往HBase中写入数据时,首先是写入到MemStore
- 每个列蔟将有一个MemStore
- 当MemStore存储快满的时候,整个数据将写入到HDFS中的HFile中
(4)StoreFile
- 每当任何数据被写入HBASE时,首先要写入MemStore
- 当MemStore快满时,整个排序的key-value数据将被写入HDFS中的一个新的HFile中
- 写入HFile的操作是连续的,速度非常快
- 物理上存储的是HFile
(5)WAL
- WAL全称为Write Ahead Log,它最大的作用就是 故障恢复
- WAL是HBase中提供的一种高并发、持久化的日志保存与回放机制
- 每个业务数据的写入操作(PUT/DELETE/INCR),都会保存在WAL中
- 一旦服务器崩溃,通过回放WAL,就可以实现恢复崩溃之前的数据
- 物理上存储是Hadoop的Sequence File
HFile是Hadoop的二进制格式文件,实际上StoreFile就是对HFile做了轻量级包装,即StoreFile底层就是HFile( When the HRegion is opened it sets up a Store instance for each HColumnFamily for every table as defined by the user beforehand.
Each Store instance can, in turn, have one or more StoreFile instances, which are lightweight wrappers around the actual storage file called HFile ---------HBase Definitive Guide)