Eclipse中使用Hadoop伪分布模式开发配置及简单程序示例(Linux下)
Hadoop入门配置系列博客目录一览
1、Eclipse中使用Hadoop伪分布模式开发配置及简单程序示例(Linux下)
2、使用Hadoop命令行执行jar包详解(生成jar、将文件上传到dfs、执行命令、下载dfs文件至本地)
3、Hadoop完全分布式集群安装及配置(基于虚拟机)
4、Eclipse中使用Hadoop集群模式开发配置及简单程序示例(Windows下)
5、Zookeeper3.4.9、Hbase1.3.1、Pig0.16.0安装及配置(基于Hadoop2.7.3集群)
6、mysql5.7.18安装、Hive2.1.1安装和配置(基于Hadoop2.7.3集群)
7、Sqoop-1.4.6安装配置及Mysql->HDFS->Hive数据导入(基于Hadoop2.7.3)
8、Hadoop完全分布式在实际中优化方案
9、Hive:使用beeline连接和在eclispe中连接
10、Scala-2.12.2和Spark-2.1.0安装配置(基于Hadoop2.7.3集群)
11、Win下使用Eclipse开发scala程序配置(基于Hadoop2.7.3集群)
12、win下Eclipse远程连接Hbase的配置及程序示例(create、insert、get、delete)
Hadoop入门的一些简单实例详见本人github:https://github.com/Nana0606/hadoop_example
本篇博客主要介绍“Eclipse中使用Hadoop伪分布模式开发配置及简单程序示例(Linux下)”。
一、JDK安装、Hadoop的安装及伪分布模式配置
具体参见博客:Hadoop安装以及伪分布模式搭建过程
本篇博客的OS版本及软件版本均与上述版本一致。
已安装好的JDK目录:/opt/Java/jdk1.8
已安装好的Hadoop目录:/opt/Hadoop/hadoop-2.8.0
二、Eclipse安装
下载linux版的eclipse(eclipse-jee-oxygen-R-linux-gtk.tar.gz):https://www.eclipse.org/downloads/eclipse-packages/?osType=linux&release=undefined 如图: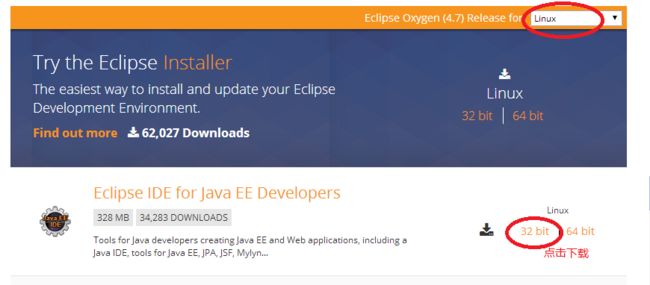
将下载的文件解压到相应的目录下,这里将其解压到/opt下,文件名称为eclipse。解压完毕之后,双击下图所示的图标即可打开:

三、配置Eclipse和Hadoop关联起来
1、下载hadoop-2.8.0的eclipse插件:hadoop-eclipse-plugin-2.8.0.jar 将下载的hadoop-eclipse-plugin-2.8.0.jar文件放到Eclipse的plugins文件夹下,即放在/opt/eclipse/plugins/下,重启eclipse即可看到该插件生效,如图:
2、设置hadoop开发模式
(1)点击“Window --> Preferences --> Hadoop Map/Reduce”选择Hadoop安装目录,点击“Apply”和“Apply and Close”,如图:

(2)点击“Window --> Perspective --> Open Perspective --> Other --> Map/Reduce”,如下图:
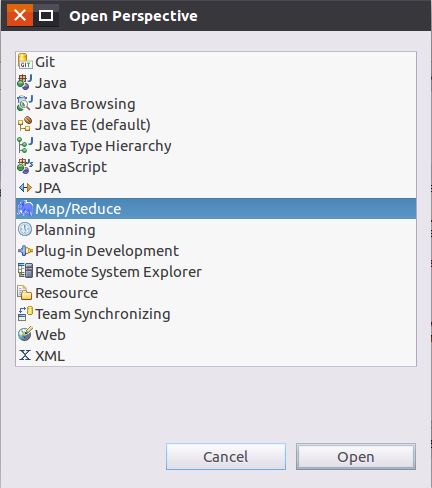
(3)点击“Window --> Show View --> Other --> Map/Reduce Locations”,如图:

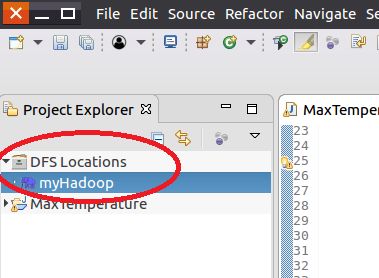
四、添加Hadoop Location
经过上述步骤之后,控制台如下:
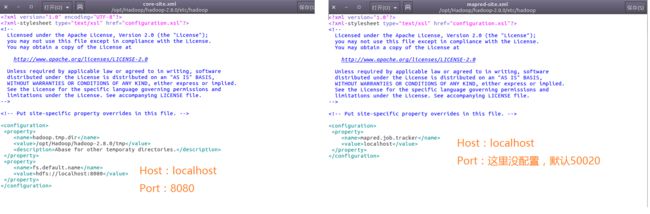
点击**处的大象标志“New Hadoop Location ”,配置如右图所示:
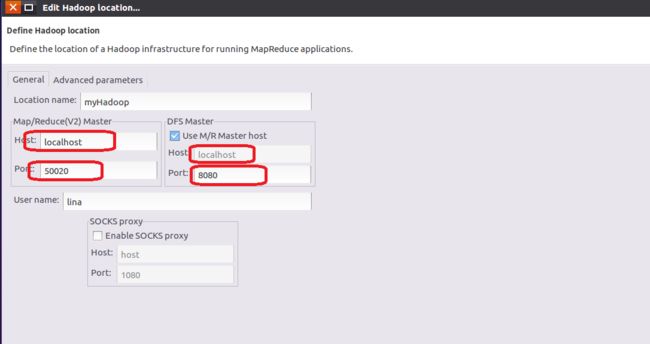
五、简单示例(代码、运行配置、结果)
代码来源:http://blog.csdn.net/zythy/article/details/17397367(稍微有一点点改动) (1)源代码目录结构: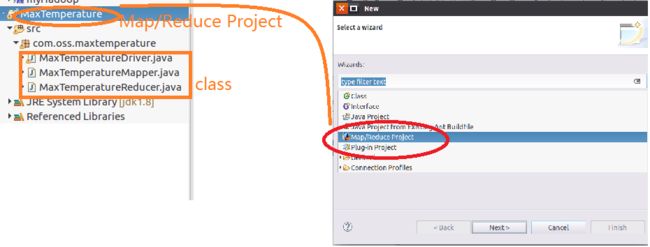
(2)相应代码:
MaxTemperatureDriver.java:
package com.oss.maxtemperature;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class MaxTemperatureDriver extends Configured implements Tool {
@SuppressWarnings("deprecation")
@Override
public int run(String[] args) throws Exception {
if (args.length != 2){
System.err.printf("Usage: %s MaxTemperatureMapper.java:
packagecom.oss.maxtemperature;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class MaxTemperatureMapper extends Mapper {
@Override
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException{
String line = value.toString();
if( !line.equals("") ){
try {
String year = line.substring(0,4);
int airTemperature = Integer.parseInt(line.substring(5));
context.write(new Text(year),new IntWritable(airTemperature));
} catch (Exception e) {
System.out.print("Error in line:" + line);
}
} else {
return;
}
}
}
MaxTemperatureReducer.java:
packagecom.oss.maxtemperature;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class MaxTemperatureReducer extendsReducer {
@Override
public void reduce(Text key, Iterable values, Context context)throws IOException, InterruptedException {
int maxValue = Integer.MIN_VALUE;
for(IntWritable value: values){
maxValue = Math.max(maxValue,value.get());
}
context.write(key, new IntWritable(maxValue));
}
}
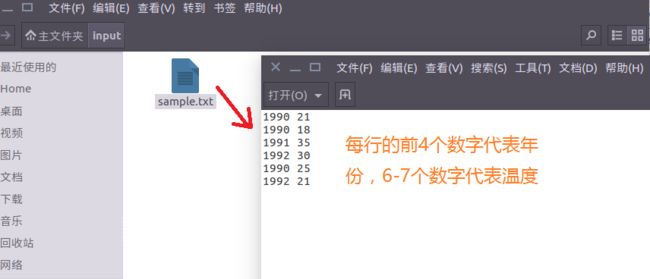
(3)输入文件sample.txt,所在目录/home/lina/input,其内容为:
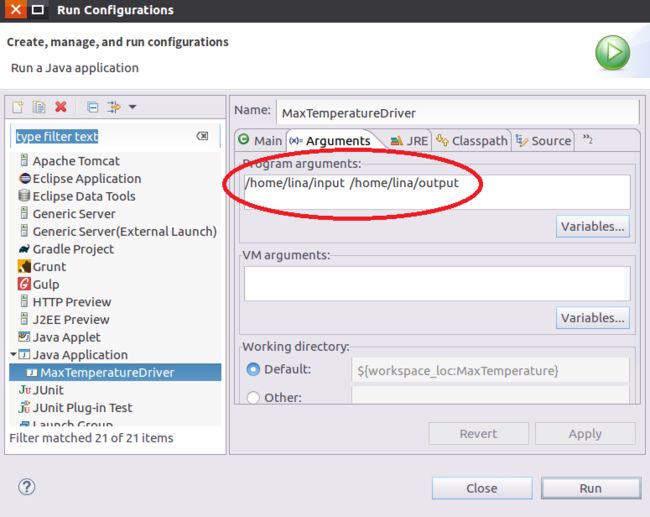

至此,Eclipse中开发Hadoop的配置以及简单的Hadoop程序完成。
将程序打包成jar包,在命令行中使用hadoop命令执行的方法详见: 使用Hadoop命令行执行jar包详解(生成jar、将文件上传到dfs、执行命令)