微信(WeChat)是腾讯公司推出的一款面向智能终端的即时通讯软件。为用户提供聊天、朋友圈、微信支付、公众平台、微信小程序等功能,同时提供生活缴费、直播等服务。微信是全国用户数最多的手机应用,每天有超过10亿人使用。服务如此大用户规模的系统,对于运维的挑战很大。传统的监控手段和思想已经无法应对如此海量的场景。微信技术架构部在充分调研之后引入了StarRocks。StarRocks凭借其灵活的分桶和物化视图等特性,高效支持了微信多维监控平台的运行。
“ 作者:仇弈彬,
微信基础监控平台后台工程师 ”
微信监控体系背景
微信的监控体系,主要分为三个方面:
框架级监控:自建了一个非常定制化的模块调用关系监控,这部分监控包含了模块的调用链、主调、背调、调用的平均耗时以及失败等。
用户自定义指标监控:多用于用户自助上报业务情况,比如支付、商户的调用失败、微信上报消息的成功率等。这部分主要有两个平台来完成。一个是固定维度的打点监控 (ID+Key) 。用户需要自己去申请一个 ID,并且在 ID 下自己去定义 Key,但这套监控的适用范围比较有限,只能监控一些比较简单的需求,因为它只有两个维度。另一种是比较复杂的监控需求。比如需要上报每个城市、每个运营商、每个错误码的一些上报情况,这样显然两个维度是无法满足的,需要引入一套 OLAP 监控体系,也就微信多维监控。
微信内部在建设云原生可观测性平台:主要包括一些 Traces、Metrics、Logs,基于 OpenTelemetry 标准。
本文主要介绍 StarRocks 在微信多维监控平台的应用。
多维监控平台原架构及挑战
微信多维监控平台是一套基于多个维度灵活自助分析的 OLAP 监控体系。关于微信多维监控平台,主要有以下三个比较重要的概念。
协议,也就是用户自定义的监控表,它主要包含两个重要的信息。一个是维度,是支持分组过滤和聚合的字段。比如监控一些模块的调用情况,那么模块和 API 就是它的维度。另一个是指标,指标可以通过 Sum, Max, Min, Unique Count 等聚合。
视图,基于监控表的维度和指标,可以对它们进行排列组合,排列出各种各样的时间曲线,从而构成监控视图供业务方进行问题的查询和定位。
异常检测平台,对指标下的一个或多个维度组合的时间序列曲线,通过算法、阈值、波动检测数据异常,从而帮助业务及时发出告警,让业务及时关注自己的指标有没有出现异常。
业务规模
多维监控平台整体业务规模:
协议:3000 多个协议,也就是对应 3000 多个维度表。
数据量:维度表的原始数据量非常大,峰值数据达到33亿条/min ,3万亿/天。
并发量:异常检测平台调用,最高33w/min 的调用峰值。
业务特点
微信多维监控平台主要面对的业务特点有以下几个特点:
- 不需要保留明细数据,数据是依据指标的维度聚合的,只需要一个聚合模型。
- 以单表查询为主,也就是说每个协议都是独立的单表,也就是说不存在跨表查询。
- 高频查询的模式是比较固定且容易预测的,一方面需要对若干个维度进行 TopN 的处理,比如一个模块,要对上报量进行 TopN 的操作,求出最大上报量的 3000 个模块,然后进行监控。另一方面是对于若干维度的时间序列,也就是 GROUP BY time_minute 。
基于以上三个特点,需求如下:
- 稳定低延迟的数据导入能力,因为用户上报的需求量非常多。
- 支持聚合模型的 OLAP 引擎。
- 单表高并发,因为 OLAP 平台以单表查询为主,所以对单表查询的性能要求较高。并且因为异常检测需要实时的拉取很多维度组合的曲线,进行每分钟的监控处理,所以需要支持高并发。
- 根据数据特点设置索引,通过物化视图加速常用查询。
原有架构
监控平台的协议非常多,数据场景也是多种多样。可以按两个维度分为四类:一是以数据量的大小来分,也就是它上报的原始数据量大概有多少。二是每分钟的维度复不复杂,就是有多少个维度排列组合。两个维度组合后就有了四种分类,小的维度组合+比较少的数据量,这部分占大多数;小的维度组合+大的数据量;维度组合复杂+少的数据量;维度组合复杂+大的数据量。面对这些数据场景,此前的架构如下图:
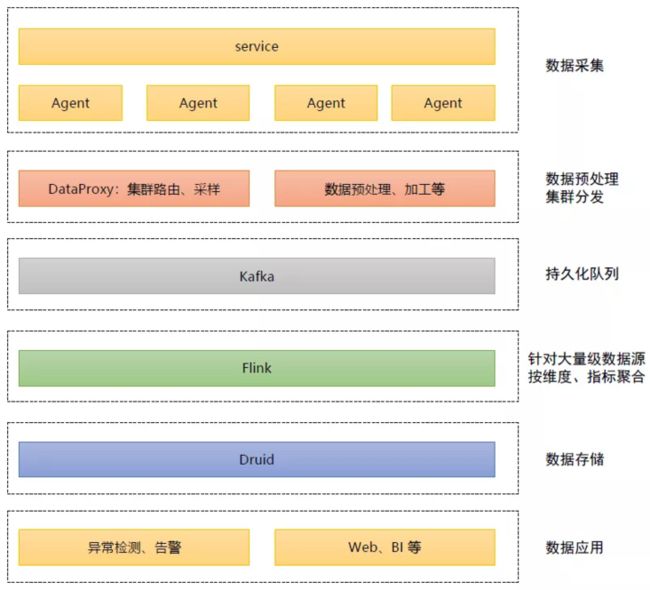
业务通过共享内存,把数据写入共享内存中,然后 Agent 会一直轮询这个共享内存的数据,再异步推给中控的 Proxy ,由它进行采样、路由的操作。同时会在预处理层进行数据的预处理、加工等,把预处理后的数据发给持久化的 Kafka 队列。Kafka 队列中一小部分数据会被 Druid 直接消费。大部分的数据,会通过 Flink 进行预聚合,Flink 会以每6秒的粒度把明细数据进行聚合,然后重新写回 Kafka 供 Druid 消费。Druid 的数据通过数据层把它的数据查询出来,提供给 Web,后续提供给异常检测做告警处理。
痛点分析
基于上述四种数据场景,在原有的架构中:
- 简单的维度组合+小的数据量,可以用 Druid 直接解决。
- 简单的维度组合+大的数据量,比如每分钟协议上报量大于 3000万 ,但是它的维度组合也会相对简单,比如只有 10万 的维度组合,也可以通过 Flink 对它进行提前的预聚合处理,再导入 Druid。
- 复杂的维度组合+小的数据量,比如它每分钟有 100万、1000万 甚至上亿这种量级的维度组合,直接用 Druid 处理会发现,它的数据查询是非常慢。
- 复杂的维度组合+大的数据量,现有的手段无法解决这类问题。

微信监控平台作为Druid的重度用户,在 Druid在使用过程中存在的以下的痛点:
- 架构复杂,有实时节点、历史节点、查询节点等 6 种不同类型的节点,同时需要依赖 MySQL、ZK、HDFS 等外部组件。
- Druid 只支持单维 RollUp ,但没有物化视图概念,导致对于复杂的维度,优化手段会相对复杂,需要自己去实现一套类似物化视图的效果。业务自行拆字表,并且在业务层匹配子表。
- 不能够自定义数据分区,某些查询场景无法加速。Druid 是严格的时间分区,Segment 严格按照时间存储,也就相当于它的数据会根据时间聚合在某一两台机上,如果数据诉求对时间不是很敏感,性能表现会比较差。
- Druid 对于高基数维度的查询性能差。虽然 Druid 对简单的维度查询性能非常高,并发能力的上限也很高,但对于维度基数比较大,比如几千万个排列组合,它的慢查询会非常慢。总结下来就是维度复杂度高的场景下,Druid 的查询性能不能满足需求。
因此我们尝试引入其他的 OLAP 平台。在调研过程中,我们对 StarRocks 进行了充分的调研和验证。StarRocks 的优势有以下四点:
- 同时支持聚合模型和明细模型,监控需求主要以聚合模型为主的,部分明细查询为辅。
- 可以自定义分区分桶,更容易针对数据特点做针对性优化,从而加速查询性能。
- 拥有灵活的物化视图,常用的大量级查询维度通常是固定的,可以通过物化视图进行聚合,能够提升整体的查询性能。而且 StarRocks 自动匹配物化视图,无需业务自行通过代码逻辑判断。
- 高并发的查询能力。
StarRocks 性能测试
选型过程中我们使用了平台真实的数据和场景对StarRocks的各项能力进行了测试。
数据导入能力测试
测试过程中使用真实的线上数据,通过使用 Kafka RoutineLoad 导入 JSON 数据格式。
机器配置:单机 48 物理核,超线程 96 核 (8255C),192G 内存,16T NVMeSSD ;5 台机。
数据源(线上真实数据):导入速度是 5kw/min ,平均 1KB/条(JSON) 。
测试过程:先把数据先导入 Kafka ,积累一定时间再启动消费,有助于压测 StarRocks 最大接入能力。
主要配置:routine_load_task_consume_second = 30 ;routine_load_task_timeout_second = 60;max_batch_rows = 20,000,000;desired_concurrent_number = 5。
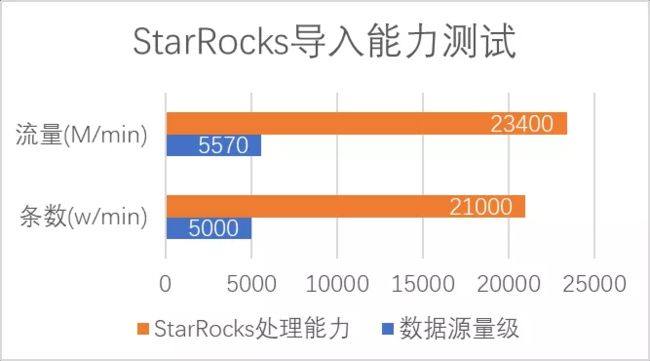
测试结果:StarRocks 的表现还是非常优秀的。通过上图可以看到,数据源导入量大概是 5000万/min ,但实际上 StarRocks 的消费能力可以达到 2.1亿/min ,这个数据远高于 Kafka 的写入速度,也完全符合我们对数据接入能力的要求。
StarRocks 和 Druid 的查询测试对比
机器配置:单机48物理核,超线程96核(8255C),192G内存, 16T NVMeSSD;5 台机。
基数:高基数维度协议是维度排列基数(排除时间维)1.15kw。
版本:StarRocks 1.18.1;Druid 0.20.0。
低并发测试结果:
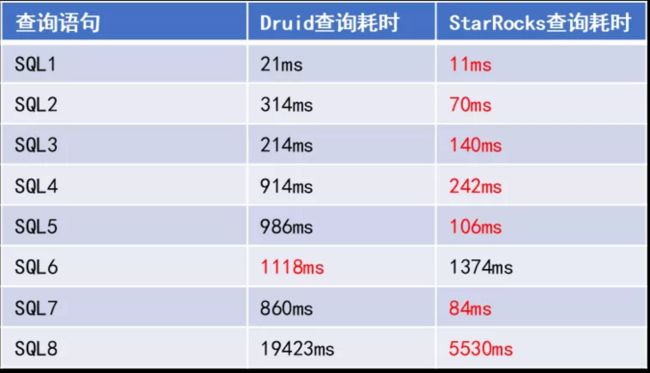

StarRocks 和 Druid 在低并发环境下,选取 4 个时间序列 SQL 和4 个普通维度 TopN SQL 。每次查询进行 5 次,取平均值。对于优化方面,Druid 会全维度建立 RollUp ,StarRocks 会建立物化视图。
整体表现如上表,可以看到有7个在低并发环境下 StarRocks 是优于 Druid 的,而这部分的数据特点就是维度比较复杂。针对于一个慢查询,也就是对于它高基维度分桶下的 TopN 查询,StarRocks 表现非常优异:5s 完成,Druid 需要 20s 左右。所以,在低并发环境下,StarRocks 的性能相对于 Druid 有比较大的提升。
高并发测试结果:


StarRocks 和 Druid 在高并发环境下,还是之前的 8 个 SQL ,分别采用 16 和 32 并发的情况去测试整体的 QPS 和平均耗时,数据如上表。我们可以看到在 16 次查询中,StarRocks 12 次平均耗时优于 Druid ,而且 16 次测试中,StarRocks 的 10 次 QPS 测试高于 Druid ,2 个慢查询 Druid 和StarRocks 都无法在高并发环境下完成。
结论:对于复杂协议,StarRocks 凭借着灵活的分桶和物化视图等特性,在相对高并发环境下表现出了高于 Druid 的性能。同时我们也发现 StarRocks 的并发能力和 CPU 强相关,CPU 使用率过高性能会降低,Druid 相对会更稳定。
经过测试,对比 StarRocks 与 Druid 的优劣势。

StarRocks在微信监控中的成果

现在在微信监控体系中,整体的架构如上图。在计算和存储层, StarRocks 和 Druid 同时作为平台的存储和计算引擎。
目前 StarRocks 在微信多维监控平台,对于复杂维度的协议分析场景表现出了强于 Druid 的性能。所以我们已经将部分维度复杂协议的实时计算和存储从 Druid 迁移至 StarRocks ,总体迁移了 9 个协议,覆盖了微信支付、视频号、微信搜一搜、微信安全等产品。
StarRocks 接入的数据量峰值已经达到了7kw/min ,600亿/天 的原始数据。通过 StarRocks ,协议的平均查询耗时从 1200ms 优化到了 500ms 左右,对于慢查询的耗时,从 20s 优化到了 6s。
总结与展望
在微信多维监控平台,拥有数以千计的数据源,每个数据源都有各自的特点。在实践中,Druid 和 StarRocks 在不同的场景下都各有所长。StarRocks 的优秀性能帮助我们解决了很多在原有 Druid 架构体系下较难解决的问题。未来我们也会持续保留这两个 OLAP 引擎作为我们的主力存储和计算引擎,同时我们也会积极探索 StarRocks 在更多场景下的应用。
后续我们期望 StarRocks 在高并发,CPU 高负载的场景有进一步的性能提升。未来发布的存储和计算分离版本,也会在系统稳定性上带来更大的改进。我们相信 StarRocks 未来会飞的更高。