飞桨 | 基于 Paddle 从零开始实现 Resnet18 之 模型结构
建模 Resnet18
- 一、网络结构
-
- Resnet18 的整体结构
- Resnet 18 的主要部件
- 二、代码实现
-
- 1. 定义 Block
- 2. 定义 Layer 层
- 3. 定义 stem 和 head
- 4. 输出模型结构
- 三、相关API
-
- 1. Conv2D
- 2. BatchNorm
- 3. Relu
- 4. AdaptiveAvgPool2D
- 5. MaxPool2D
- 6. nn.Sequential(*layers)
- 参考链接
Resnet18 是何恺明在论文 Deep Residual Learning for Image Recognition 中提出的一个卷积神经网络。本文将带你根据论文基于百度深度学习框架 paddle 从头开始实现 Resnet18 模型结构。
一、网络结构
首先,我们来看一下要实现的目标 Resnet18 的整体结构。然后,再将 Resnet18 拆成几个主要部件分别进行代码实现。
Resnet18 的整体结构
Resnet18 的整体结构如下图所示,共有 18 个有权重的层(卷积层和全连接层),池化层和 BN 层不计入层数。Resnet18 图片来源自 PyTorch实现ResNet18。
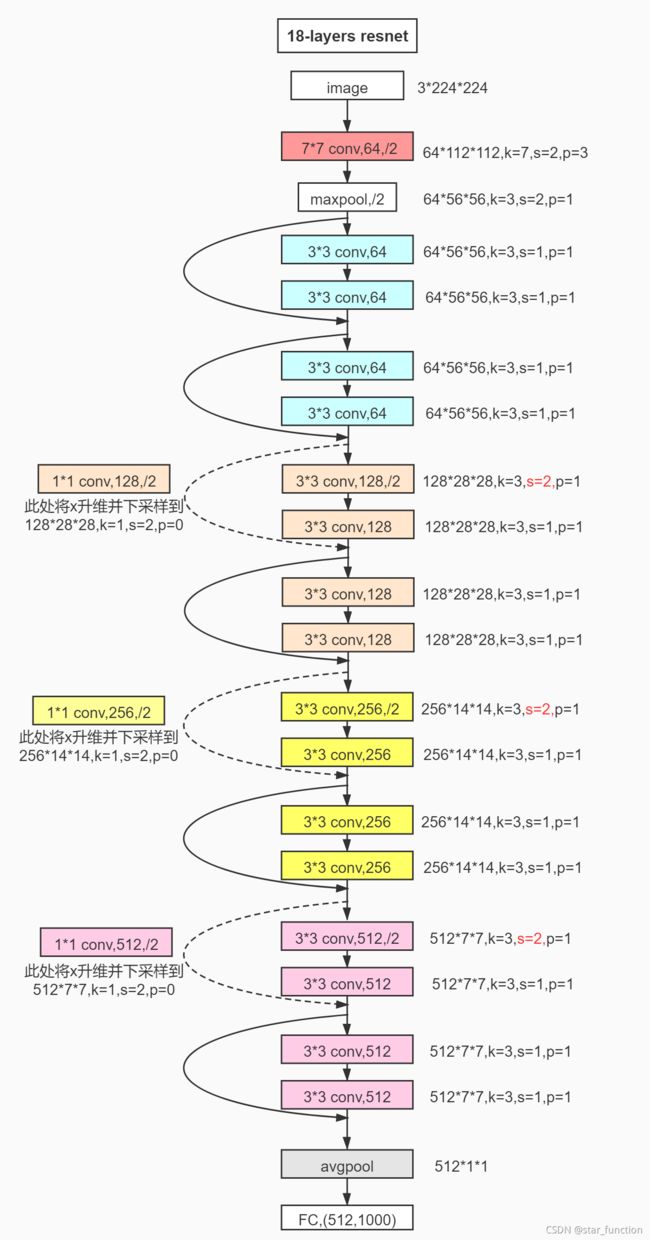
Resnet 18 的主要部件
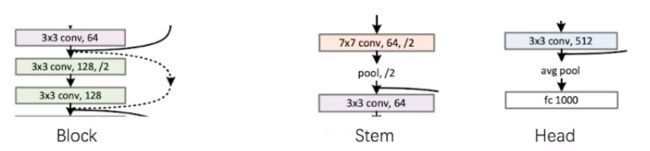
Resnet18 主要包括 stem、block 和 head 三种部件。它们的结构如下图所示:
Block + Stem + Head
二、代码实现
那么如何用 stem、block 和 head 构成 Resnet18 呢?
为了简化代码,将两个 block 封装成一个 layer,所有 layer 组成 body。因此 Resnet18 由 stem、body 和 head 三个部分组成。
其中,
- stem 包括一个 7x7 的卷积层,一个 3x3 的最大池化层
- body 包括 4 个 layer,每个 layer 由两个 Block 组成
- head 包括一个 average pool 层 和 fc 层
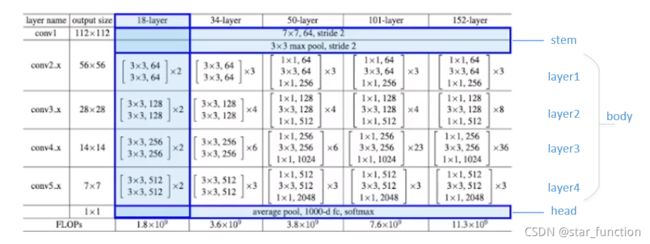
Resnet18 各层的具体参数如下,下面我们依照下图利用 paddle 开始实现 Resnet18。
利用 paddle 实现 Resnet18,首先需要导入必要的库
import paddle
import paddle.nn as nn
然后分别实现 block , stem 和 head 结构。在实现这些结构之前,先写一个 Identity 类,它的作用是保持输入和输出一致,直接返回输入
# 定义一个类,直接返回输入,不对输入做任何操作
class Identity(nn.Layer):
def __init_(self):
super().__init__()
def forward(self, x):
return x
1. 定义 Block
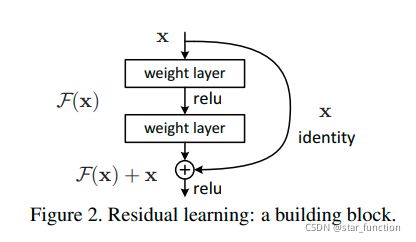
残差块 block 的结构如下图所示,由两个卷积层和一个 shortcut 组成。shortcut 分为实线 shortcut 和 虚线 shortcut。
- 实线 shortcut 的输入输出有相同的维度,故对输入特征执行 identity 保持输入输出一致即可
- 虚线 shortcut 的输入输出有不同的维度,输出维度增加,故需要将输入维度扩展到输出维度大小,同时伴随特征图大小减半操作
Block 的代码实现如下:
先做两次卷积操作,再将 shortcut h 和 block 的输出 x 求和,返回二者之和即可。
# 定义残差块 Block
# 一个 Block 由两个卷积层组成
class Block(nn.Layer):
def __init__(self, in_dim, out_dim, stride):
super().__init__()
self.conv1 = nn.Conv2D(in_dim, out_dim, 3, stride=stride, padding=1,bias_attr=False)
self.bn1 = nn.BatchNorm2D(out_dim)
self.conv2 = nn.Conv2D(out_dim, out_dim, 3, stride=1,padding=1,bias_attr=False)
self.bn2 = nn.BatchNorm2D(out_dim)
self.relu = nn.ReLU()
# shortcut 分为 实线 shortcut 和 虚线 shortcut
# 实线 shortcut 的输入输出有相同的维度,故无需处理
# 虚线 shortcut 的输出维度增加,故需要将输入维度扩展到输出维度大小,同时令 stride=2 减小特征图大小
# 当 滑动步长为 2 或者 特征图输入输出维度不相等时,为虚线 shortcut,需要下采样
if stride == 2 or in_dim != out_dim:
# 增加维度 + 下采样调整大小
self.downsample = nn.Sequential(*[
nn.Conv2D(in_dim, out_dim, 1, stride = stride),
nn.BatchNorm2D(out_dim)])
else:
# 实线 shortcut 不做操作,保持不变
self.downsample = Identity()
def forward(self, x):
# shortcut
h = x
# 做两次卷积
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.bn2(x)
# 对 shortcut h 做处理,方便连接 x
identity = self.downsample(h)
x = x + identity
x = self.relu(x)
return x
2. 定义 Layer 层
body 中一共包括 4 个 layer,每个 layer 由两个 block 组成。第一个 block 可能会对特征图下采样(stride=2 或 stride=1),第二个 block 不会改变特征图大小(stride=1)。因此先将第一个 block 加入 layer,之后再循环加入剩余的 block。
def _make_layer(self, out_dim, n_blocks, stride):
layers = []
# 先加入一个 stride 不为 1 的 block,对特征图进行下采样
layers.append(Block(self.in_dim,out_dim,stride=stride))
self.in_dim = out_dim
# 再加入 stride 为 1 的若干 block,特征图大小保持不变
for i in range(1, n_blocks):
layers.append(Block(self.in_dim, out_dim, stride=1))
return nn.Sequential(*layers)
参考上图,layer1 —— layer4 的维度分别为
self.layer1 = self._make_layer(out_dim=64, n_blocks=2, stride=1)
self.layer2 = self._make_layer(out_dim=128, n_blocks=2, stride=2)
self.layer3 = self._make_layer(out_dim=256, n_blocks=2, stride=2)
self.layer4 = self._make_layer(out_dim=512, n_blocks=2, stride=2)
3. 定义 stem 和 head
stem 包括一个 7x7 的卷积层,一个 3x3 的最大池化层。
self.in_dim = in_dim
self.conv1 = nn.Conv2D(in_channels=3,
out_channels=in_dim,
kernel_size=7,
stride=2,
padding=3,
bias_attr=False)
self.bn1 = nn.BatchNorm2D(in_dim)
self.relu = nn.ReLU()
self.maxpool = nn.MaxPool2D(kernel_size=3, stride=2, padding=1)
head 包括一个 average pool 层 和 fc 层。
self.avgpool = nn.AdaptiveAvgPool2D(1)
self.classifier = nn.Linear(512, num_classes)
ResNet18 类的整体代码实现如下:
# 定义 ResNet18 类
# Resnet18 由 stem、body 和 head 三个部分组成
# 其中,stem 包括一个 7x7 的卷积层,一个 3x3 的最大池化层
# body 包括 4 个 layer,每个 layer 由两个 Block 组成
# head 包括一个 average pool 层 和 fc 层
class ResNet18(nn.Layer):
def __init__(self, in_dim=64, num_classes=1000):
super().__init__()
self.in_dim = in_dim
self.conv1 = nn.Conv2D(in_channels=3,
out_channels=in_dim,
kernel_size=7,
stride=2,
padding=3,
bias_attr=False)
self.bn1 = nn.BatchNorm2D(in_dim)
self.relu = nn.ReLU()
self.maxpool = nn.MaxPool2D(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(out_dim=64, n_blocks=2, stride=1)
self.layer2 = self._make_layer(out_dim=128, n_blocks=2, stride=2)
self.layer3 = self._make_layer(out_dim=256, n_blocks=2, stride=2)
self.layer4 = self._make_layer(out_dim=512, n_blocks=2, stride=2)
self.avgpool = nn.AdaptiveAvgPool2D(1)
self.classifier = nn.Linear(512, num_classes)
def _make_layer(self, out_dim, n_blocks, stride):
layers = []
# 先加入一个 stride 不为 1 的 block,对特征图进行下采样
layers.append(Block(self.in_dim,out_dim,stride=stride))
self.in_dim = out_dim
# 再加入 stride 为 1 的若干 block,特征图大小保持不变
for i in range(1, n_blocks):
layers.append(Block(self.in_dim, out_dim, stride=1))
return nn.Sequential(*layers)
def forward(self, x):
## stem
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
## body
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
## head
x = self.avgpool(x)
# 为了连接全连接层 fc, 即 classifier ,需要将特征展成一维
x = x.flatten(1)
x = self.classifier(x)
return x
4. 输出模型结构
# 测试代码
def main():
model = ResNet18()
print(model)
paddle.summary(model, (2, 3, 32, 32))
# x = paddle.randn([2, 3, 32, 32])
# out = model(x)
# print(out.shape)
if __name__ == "__main__":
main()
输出结果如下所示:
ResNet18(
(conv1): Conv2D(3, 64, kernel_size=[7, 7], stride=[2, 2], padding=3, data_format=NCHW)
(bn1): BatchNorm2D(num_features=64, momentum=0.9, epsilon=1e-05)
(relu): ReLU()
(maxpool): MaxPool2D(kernel_size=3, stride=2, padding=1)
(layer1): Sequential(
(0): Block(
(conv1): Conv2D(64, 64, kernel_size=[3, 3], padding=1, data_format=NCHW)
(bn1): BatchNorm2D(num_features=64, momentum=0.9, epsilon=1e-05)
(conv2): Conv2D(64, 64, kernel_size=[3, 3], padding=1, data_format=NCHW)
(bn2): BatchNorm2D(num_features=64, momentum=0.9, epsilon=1e-05)
(relu): ReLU()
(downsample): Identity()
)
(1): Block(
(conv1): Conv2D(64, 64, kernel_size=[3, 3], padding=1, data_format=NCHW)
(bn1): BatchNorm2D(num_features=64, momentum=0.9, epsilon=1e-05)
(conv2): Conv2D(64, 64, kernel_size=[3, 3], padding=1, data_format=NCHW)
(bn2): BatchNorm2D(num_features=64, momentum=0.9, epsilon=1e-05)
(relu): ReLU()
(downsample): Identity()
)
)
(layer2): Sequential(
(0): Block(
(conv1): Conv2D(64, 128, kernel_size=[3, 3], stride=[2, 2], padding=1, data_format=NCHW)
(bn1): BatchNorm2D(num_features=128, momentum=0.9, epsilon=1e-05)
(conv2): Conv2D(128, 128, kernel_size=[3, 3], padding=1, data_format=NCHW)
(bn2): BatchNorm2D(num_features=128, momentum=0.9, epsilon=1e-05)
(relu): ReLU()
(downsample): Sequential(
(0): Conv2D(64, 128, kernel_size=[1, 1], stride=[2, 2], data_format=NCHW)
(1): BatchNorm2D(num_features=128, momentum=0.9, epsilon=1e-05)
)
)
(1): Block(
(conv1): Conv2D(128, 128, kernel_size=[3, 3], padding=1, data_format=NCHW)
(bn1): BatchNorm2D(num_features=128, momentum=0.9, epsilon=1e-05)
(conv2): Conv2D(128, 128, kernel_size=[3, 3], padding=1, data_format=NCHW)
(bn2): BatchNorm2D(num_features=128, momentum=0.9, epsilon=1e-05)
(relu): ReLU()
(downsample): Identity()
)
)
(layer3): Sequential(
(0): Block(
(conv1): Conv2D(128, 256, kernel_size=[3, 3], stride=[2, 2], padding=1, data_format=NCHW)
(bn1): BatchNorm2D(num_features=256, momentum=0.9, epsilon=1e-05)
(conv2): Conv2D(256, 256, kernel_size=[3, 3], padding=1, data_format=NCHW)
(bn2): BatchNorm2D(num_features=256, momentum=0.9, epsilon=1e-05)
(relu): ReLU()
(downsample): Sequential(
(0): Conv2D(128, 256, kernel_size=[1, 1], stride=[2, 2], data_format=NCHW)
(1): BatchNorm2D(num_features=256, momentum=0.9, epsilon=1e-05)
)
)
(1): Block(
(conv1): Conv2D(256, 256, kernel_size=[3, 3], padding=1, data_format=NCHW)
(bn1): BatchNorm2D(num_features=256, momentum=0.9, epsilon=1e-05)
(conv2): Conv2D(256, 256, kernel_size=[3, 3], padding=1, data_format=NCHW)
(bn2): BatchNorm2D(num_features=256, momentum=0.9, epsilon=1e-05)
(relu): ReLU()
(downsample): Identity()
)
)
(layer4): Sequential(
(0): Block(
(conv1): Conv2D(256, 512, kernel_size=[3, 3], stride=[2, 2], padding=1, data_format=NCHW)
(bn1): BatchNorm2D(num_features=512, momentum=0.9, epsilon=1e-05)
(conv2): Conv2D(512, 512, kernel_size=[3, 3], padding=1, data_format=NCHW)
(bn2): BatchNorm2D(num_features=512, momentum=0.9, epsilon=1e-05)
(relu): ReLU()
(downsample): Sequential(
(0): Conv2D(256, 512, kernel_size=[1, 1], stride=[2, 2], data_format=NCHW)
(1): BatchNorm2D(num_features=512, momentum=0.9, epsilon=1e-05)
)
)
(1): Block(
(conv1): Conv2D(512, 512, kernel_size=[3, 3], padding=1, data_format=NCHW)
(bn1): BatchNorm2D(num_features=512, momentum=0.9, epsilon=1e-05)
(conv2): Conv2D(512, 512, kernel_size=[3, 3], padding=1, data_format=NCHW)
(bn2): BatchNorm2D(num_features=512, momentum=0.9, epsilon=1e-05)
(relu): ReLU()
(downsample): Identity()
)
)
(avgpool): AdaptiveAvgPool2D(output_size=1)
(classifier): Linear(in_features=512, out_features=1000, dtype=float32)
)
-------------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===============================================================================
Conv2D-61 [[2, 3, 32, 32]] [2, 64, 16, 16] 9,408
BatchNorm2D-61 [[2, 64, 16, 16]] [2, 64, 16, 16] 256
ReLU-28 [[2, 64, 16, 16]] [2, 64, 16, 16] 0
MaxPool2D-4 [[2, 64, 16, 16]] [2, 64, 8, 8] 0
Conv2D-62 [[2, 64, 8, 8]] [2, 64, 8, 8] 36,864
BatchNorm2D-62 [[2, 64, 8, 8]] [2, 64, 8, 8] 256
ReLU-29 [[2, 64, 8, 8]] [2, 64, 8, 8] 0
Conv2D-63 [[2, 64, 8, 8]] [2, 64, 8, 8] 36,864
BatchNorm2D-63 [[2, 64, 8, 8]] [2, 64, 8, 8] 256
Identity-16 [[2, 64, 8, 8]] [2, 64, 8, 8] 0
Block-25 [[2, 64, 8, 8]] [2, 64, 8, 8] 0
Conv2D-64 [[2, 64, 8, 8]] [2, 64, 8, 8] 36,864
BatchNorm2D-64 [[2, 64, 8, 8]] [2, 64, 8, 8] 256
ReLU-30 [[2, 64, 8, 8]] [2, 64, 8, 8] 0
Conv2D-65 [[2, 64, 8, 8]] [2, 64, 8, 8] 36,864
BatchNorm2D-65 [[2, 64, 8, 8]] [2, 64, 8, 8] 256
Identity-17 [[2, 64, 8, 8]] [2, 64, 8, 8] 0
Block-26 [[2, 64, 8, 8]] [2, 64, 8, 8] 0
Conv2D-66 [[2, 64, 8, 8]] [2, 128, 4, 4] 73,728
BatchNorm2D-66 [[2, 128, 4, 4]] [2, 128, 4, 4] 512
ReLU-31 [[2, 128, 4, 4]] [2, 128, 4, 4] 0
Conv2D-67 [[2, 128, 4, 4]] [2, 128, 4, 4] 147,456
BatchNorm2D-67 [[2, 128, 4, 4]] [2, 128, 4, 4] 512
Conv2D-68 [[2, 64, 8, 8]] [2, 128, 4, 4] 8,320
BatchNorm2D-68 [[2, 128, 4, 4]] [2, 128, 4, 4] 512
Block-27 [[2, 64, 8, 8]] [2, 128, 4, 4] 0
Conv2D-69 [[2, 128, 4, 4]] [2, 128, 4, 4] 147,456
BatchNorm2D-69 [[2, 128, 4, 4]] [2, 128, 4, 4] 512
ReLU-32 [[2, 128, 4, 4]] [2, 128, 4, 4] 0
Conv2D-70 [[2, 128, 4, 4]] [2, 128, 4, 4] 147,456
BatchNorm2D-70 [[2, 128, 4, 4]] [2, 128, 4, 4] 512
Identity-18 [[2, 128, 4, 4]] [2, 128, 4, 4] 0
Block-28 [[2, 128, 4, 4]] [2, 128, 4, 4] 0
Conv2D-71 [[2, 128, 4, 4]] [2, 256, 2, 2] 294,912
BatchNorm2D-71 [[2, 256, 2, 2]] [2, 256, 2, 2] 1,024
ReLU-33 [[2, 256, 2, 2]] [2, 256, 2, 2] 0
Conv2D-72 [[2, 256, 2, 2]] [2, 256, 2, 2] 589,824
BatchNorm2D-72 [[2, 256, 2, 2]] [2, 256, 2, 2] 1,024
Conv2D-73 [[2, 128, 4, 4]] [2, 256, 2, 2] 33,024
BatchNorm2D-73 [[2, 256, 2, 2]] [2, 256, 2, 2] 1,024
Block-29 [[2, 128, 4, 4]] [2, 256, 2, 2] 0
Conv2D-74 [[2, 256, 2, 2]] [2, 256, 2, 2] 589,824
BatchNorm2D-74 [[2, 256, 2, 2]] [2, 256, 2, 2] 1,024
ReLU-34 [[2, 256, 2, 2]] [2, 256, 2, 2] 0
Conv2D-75 [[2, 256, 2, 2]] [2, 256, 2, 2] 589,824
BatchNorm2D-75 [[2, 256, 2, 2]] [2, 256, 2, 2] 1,024
Identity-19 [[2, 256, 2, 2]] [2, 256, 2, 2] 0
Block-30 [[2, 256, 2, 2]] [2, 256, 2, 2] 0
Conv2D-76 [[2, 256, 2, 2]] [2, 512, 1, 1] 1,179,648
BatchNorm2D-76 [[2, 512, 1, 1]] [2, 512, 1, 1] 2,048
ReLU-35 [[2, 512, 1, 1]] [2, 512, 1, 1] 0
Conv2D-77 [[2, 512, 1, 1]] [2, 512, 1, 1] 2,359,296
BatchNorm2D-77 [[2, 512, 1, 1]] [2, 512, 1, 1] 2,048
Conv2D-78 [[2, 256, 2, 2]] [2, 512, 1, 1] 131,584
BatchNorm2D-78 [[2, 512, 1, 1]] [2, 512, 1, 1] 2,048
Block-31 [[2, 256, 2, 2]] [2, 512, 1, 1] 0
Conv2D-79 [[2, 512, 1, 1]] [2, 512, 1, 1] 2,359,296
BatchNorm2D-79 [[2, 512, 1, 1]] [2, 512, 1, 1] 2,048
ReLU-36 [[2, 512, 1, 1]] [2, 512, 1, 1] 0
Conv2D-80 [[2, 512, 1, 1]] [2, 512, 1, 1] 2,359,296
BatchNorm2D-80 [[2, 512, 1, 1]] [2, 512, 1, 1] 2,048
Identity-20 [[2, 512, 1, 1]] [2, 512, 1, 1] 0
Block-32 [[2, 512, 1, 1]] [2, 512, 1, 1] 0
AdaptiveAvgPool2D-4 [[2, 512, 1, 1]] [2, 512, 1, 1] 0
Linear-4 [[2, 512]] [2, 1000] 513,000
===============================================================================
Total params: 11,700,008
Trainable params: 11,680,808
Non-trainable params: 19,200
-------------------------------------------------------------------------------
Input size (MB): 0.02
Forward/backward pass size (MB): 2.53
Params size (MB): 44.63
Estimated Total Size (MB): 47.19
-------------------------------------------------------------------------------
三、相关API
1. Conv2D
class paddle.nn.Conv2D(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, padding_mode='zeros', weight_attr=None, bias_attr=None, data_format='NCHW')
2. BatchNorm
class paddle.nn.BatchNorm(num_channels, act=None, is_test=False, momentum=0.9, epsilon=1e-05, param_attr=None, bias_attr=None, dtype='float32', data_layout='NCHW', in_place=False, moving_mean_name=None, moving_variance_name=None, do_model_average_for_mean_and_var=False, use_global_stats=False, trainable_statistics=False)
3. Relu
paddle.nn.functional.relu(x, name=None)
4. AdaptiveAvgPool2D
paddle.nn.AdaptiveAvgPool2D(output_size, data_format='NCHW', name=None)
5. MaxPool2D
paddle.nn.MaxPool2D(kernel_size, stride=None, padding=0, ceil_mode=False, return_mask=False, data_format='NCHW', name=None)
6. nn.Sequential(*layers)
针对顺序的线性网络结构可以直接使用Sequential来快速完成组网,可以减少类的定义等代码编写。
下面 paddle 上的一个示例
import paddle
# Sequential形式组网
mnist = paddle.nn.Sequential(
paddle.nn.Flatten(),
paddle.nn.Linear(784, 512),
paddle.nn.ReLU(),
paddle.nn.Dropout(0.2),
paddle.nn.Linear(512, 10)
)
参考链接
- PyTorch实现ResNet18
- 从零开始学视觉Transformer