从端到端的Fast RCNN到走向实时的Faster RCNN (原理及Pytorch代码解析)
目录
RCNN
背景:
原理:
缺点:
端到端的Fast RCNN
背景:
原理:
缺点:
走向实时:Faster RCNN (two-stage)
背景:
原理:
RPN详解:
Anchor的理解:
RPN的真值和预测值:
RPN卷积网络:
RPN真值的求取:
损失函数:
NMS与生成Proposal:
筛选Proposal得到ROl:
ROl Pooling层:
相关主干代码:
RCNN
背景:
RCNN全称为Regions with CNN Features,是将深度学习应用到物体检测领域的经典之作,并凭借卷积网络出色的特征提取能力,大幅度提升了物体检测的效果。而随后基于RCNN的Fast RCNN及Faster RCNN将物体检测问题进一步优化,在实现方式、速度、精度上均有了大幅度提升。 物体检测领域出现的新成果很大一部分也是基于RCNN系列的思想,尤其是Faster RCNN,并且在解决小物体、拥挤等较难任务时,RCNN系列仍然具有较强的优势。因此,想要学习物体检测,RCNN系列是第一个需要全面掌握的算法。
RCNN算法最初由Ross Girshick等人发表在CVPR 2014,将卷积神经网络应用于特征提取,并借助于CNN良好的特征提取性能,一举将PASCAL VOC数据集的检测率从35.1%提升到了53.7%。
原理:
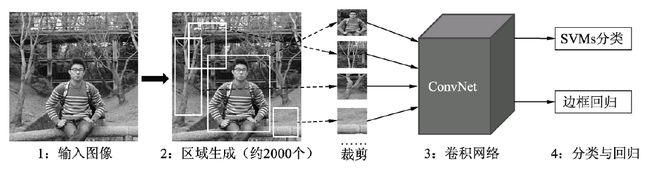
RCNN算法流程如图所示,RCNN仍然延续传统物体检测的思想,将物体检测当做分类问题处理,即先提取一系列的候选区域,然后对候选区域进行分类。 具体过程主要包含4步:
-
候选区域生成。采用Region Proposal提取候选区域,例如Selective Search算法,先将图像分割成小区域,然后合并包含同一物体可能性高的区域,并输出,在这一步需要提取约2000个候选区域。在提取完后,还需要将每一个区域进行归一化处理,得到固定大小的图像。
-
CNN特征提取。将上述固定大小的图像,利用CNN网络得到固定维度的特征输出。
-
SVM分类器。使用线性二分类器对输出的特征进行分类,得到是否属于此类的结果,并采用难样本挖掘来平衡正负样本的不平衡。
-
位置精修。通过一个回归器,对特征进行边界回归以得到更为精确的目标区域。
缺点:
RCNN虽然显著提升了物体检测的效果,但仍存在3个较大的问题。
-
首先RCNN需要多步训练,步骤烦琐且训练速度较慢;
-
其次,由于涉及分类中的全连接网络,因此输入尺寸是固定的,造成了精度的降低;
-
最后,候选区域需要提前提取并保存,占用空间较大。
端到端的Fast RCNN
背景:
在RCNN之后,SPPNet算法解决了重复卷积计算与固定输出尺度的两个问题,但仍然存在RCNN的其他弊端。在2015年,Ross Girshick独自提出了更快、更强的Fast RCNN算法,不仅训练的步骤可以实现端到端,而且算法基于VGG16网络,在训练速度上比RCNN快了近9倍,在测试速度上快了213倍,并在VOC 2012数据集上达到了68.4%的检测率。
原理:
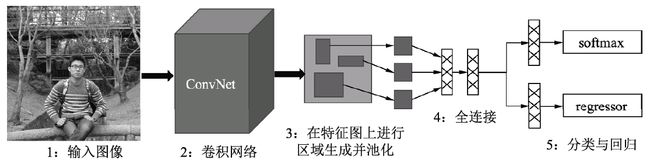
Fast RCNN算法框架图如图所示,相比起RCNN,主要有3点改进:
-
共享卷积:将整幅图送到卷积网络中进行区域生成,而不是像RCNN那样一个个的候选区域,虽然仍采用Selective Search方法,但共享卷积的优点使得计算量大大减少。
-
RoI Pooling:利用特征池化(RoI Pooling)的方法进行特征尺度变换,这种方法可以有任意大小图片的输入,使得训练过程更加灵活、准确。
-
多任务损失:将分类与回归网络放到一起训练,并且为了避免SVM分类器带来的单独训练与速度慢的缺点,使用了Softmax函数进行分类。
缺点:
Fast RCNN算法虽然取得了显著的成果,但在该算法中,Selective Search需要消耗2~3秒,而特征提取仅需要0.2秒,因此这种区域生成方法限制了Fast RCNN算法的发挥空间,这也为后来的Faster RCNN算法提供了改进方向。
走向实时:Faster RCNN (two-stage)
背景:
Faster RCNN算法发表于NIPS 2015,该算法最大的创新点在于提出了RPN(Region Proposal Network)网络,利用Anchor机制将区域生成与卷积网络联系到一起,将检测速度一举提升到了17 FPS(Frames Per Second),并在VOC 2012测试集上实现了70.4%的检测结果。
优势:
Anchor可以看做是图像上很多固定大小与宽高的方框,由于需要检测的物体本身也都是一个个大小宽高不同的方框,因此Faster RCNN将Anchor当做强先验的知识,接下来只需要将Anchor与真实物体进行匹配,进行分类与位置的微调即可。相比起没有Anchor的物体检测算法,这样的先验无疑降低了网络收敛的难度,再加上一系列的工程优化,使得Faster RCNN达到了物体检测中的一个高峰。
原理:
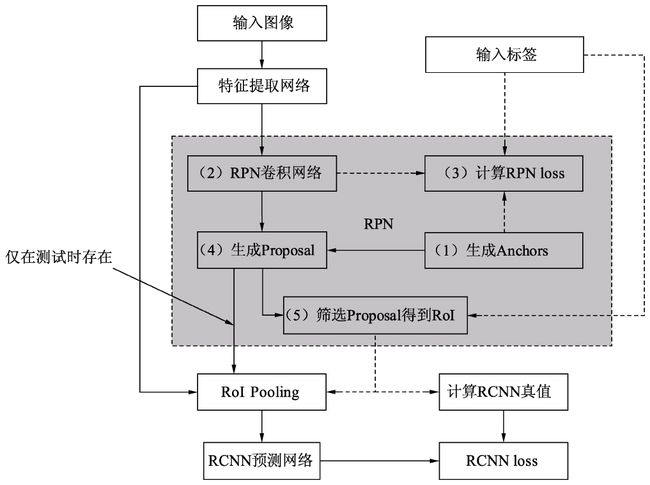
如图4所示为Faster RCNN算法的基本流程,从功能模块来讲,主要包括4部分:特征提取网络、RPN模块、RoI Pooling(Region of Interest)模块与RCNN模块,虚线表示仅仅在训练时有的步骤。Faster RCNN延续了RCNN系列的思想,即先进行感兴趣区域RoI的生成,然后再把生成的区域分类,最后完成物体的检测,这里的RoI使用的即是RPN模块,区域分类则是RCNN网络。
-
特征提取网络Backbone:输入图像首先经过Backbone得到特征图,在此以VGGNet为例,假设输入图像的维度为3×600×800,由于VGGNet包含4个Pooling层(物体检测使用VGGNet时,通常不使用第5个Pooling层),下采样率为16,因此输出的feature map的维度为512×37×50。
-
RPN模块:区域生成模块,如图4.3的中间部分,其作用是生成较好的建议框,即Proposal,这里用到了强先验的Anchor。RPN包含5个子模块:
-
Anchor生成:RPN对feature map上的每一个点都对应了9个Anchors,这9个Anchors大小宽高不同,对应到原图基本可以覆盖所有可能出现的物体。因此,有了数量庞大的Anchors,RPN接下来的工作就是从中筛选,并调整出更好的位置,得到Proposal。
-
RPN卷积网络:与上面的Anchor对应,由于feature map上每个点对应了9个Anchors,因此可以利用1×1的卷积在feature map上得到每一个Anchor的预测得分与预测偏移值。
-
计算RPN loss:这一步只在训练中,将所有的Anchors与标签进行匹配,匹配程度较好的Anchors赋予正样本,较差的赋予负样本,得到分类与偏移的真值,与第二步中的预测得分与预测偏移值进行loss的计算。
-
生成Proposal:利用第二步中每一个Anchor预测的得分与偏移量,可以进一步得到一组较好的Proposal,送到后续网络中。
-
筛选Proposal得到RoI:在训练时,由于Proposal数量还是太多(默认是2000),需要进一步筛选Proposal得到RoI(默认数量是256)。在测试阶段,则不需要此模块,Proposal可以直接作为RoI,默认数量为300。
-
-
RoI Pooling模块:这部分承上启下,接受卷积网络提取的feature map和RPN的RoI,输出送到RCNN网络中。由于RCNN模块使用了全连接网络,要求特征的维度固定,而每一个RoI对应的特征大小各不相同,无法送入到全连接网络,因此RoI Pooling将RoI的特征池化到固定的维度,方便送到全连接网络中。
-
RCNN模块:将RoI Pooling得到的特征送入全连接网络,预测每一个RoI的分类,并预测偏移量以精修边框位置,并计算损失,完成整个Faster RCNN过程。主要包含3部分:
-
RCNN全连接网络:将得到的固定维度的RoI特征接到全连接网络中,输出为RCNN部分的预测得分与预测回归偏移量。
-
计算RCNN的真值:对于筛选出的RoI,需要确定是正样本还是负样本,同时计算与对应真实物体的偏移量。在实际实现时,为实现方便,这一步往往与RPN最后筛选RoI那一步放到一起。
-
RCNN loss:通过RCNN的预测值与RoI部分的真值,计算分类与回归loss。
-
从整个过程可以看出,Faster RCNN是一个两阶的算法,即RPN与RCNN,这两步都需要计算损失,只不过前者还要为后者提供较好的感兴趣区域。
RPN详解:
RPN部分的输入、输出如下:
-
输入:feature map、物体标签,即训练集中所有物体的类别与边框位置。
-
输出:Proposal、分类Loss、回归Loss,其中,Proposal作为生成的区域,供后续模块分类与回归。两部分损失用作优化网络
Anchor的理解:
理解Anchor是理解RPN乃至Faster RCNN的关键。Faster RCNN先提供一些先验的边框,然后再去筛选与修正,这样在Anchor的基础上做物体检测要比从无到有的直接拟合物体的边框容易一些。
Anchor的本质是在原图大小上的一系列的矩形框,但Faster RCNN将这一系列的矩形框和feature map进行了关联。具体做法是,首先对feature map进行3×3的卷积操作,得到的每一个点的维度是512维,这512维的数据对应着原始图片上的很多不同的大小与宽高区域的特征,这些区域的中心点都相同。如果下采样率为默认的16,则每一个点的坐标乘以16即可得到对应的原图坐标。
为适应不同物体的大小与宽高,在作者的论文中,默认在每一个点上抽取了9种Anchors,具体Scale为{8,16,32},Ratio为{0.5,1,2},将这9种Anchors的大小反算到原图上,即得到不同的原始Proposal,如图4.4所示。由于feature map大小为37×50,因此一共有37×50×9=16650个Anchors。而后通过分类网络与回归网络得到每一个Anchor的前景背景概率和偏移量,前景背景概率用来判断Anchor是前景的概率,回归网络则是将预测偏移量作用到Anchor上使得Anchor更接近于真实物体坐标。
原理图:

在具体的代码实现时
def generate_anchors(base_size=16, ratios=[0.5, 1, 2], scales=2**np.arange(3, 6)):
\# 首先创建一个基本Anchor为[0, 0, 15, 15]
base_anchor = np.array([1, 1, base_size, base_size]) - 1
\# 将基本Anchor进行宽高变化,生成三种宽高比的s:Anchor
ratio_anchors = _ratio_enum(base_anchor, ratio)
\# 将上述Anchor再进行尺度变化,得到最终的9种Anchors
anchors = np.vstack([_scale_enum(ratio_anchors[I, :], scales)
for i in xrange(ratio_anchors.shape[0])])
\# 返回对应于feature map大小的Anchors
return anchors1 **RPN的真值和预测值:
理解RPN的预测量与真值分别是什么,也是理解RPN原理的关键。对于物体检测任务来讲,模型需要预测每一个物体的类别及其出现的位置,即类别、中心点坐标x与y、宽w与高h这5个量。由于有了Anchor这个先验框,RPN可以预测Anchor的类别作为预测边框的类别,并且可以预测真实的边框相对于Anchor的偏移量,而不是直接预测边框的中心点坐标x与y、宽高w与h。

举个例子,如上图所示,输入图像中有3个Anchors与两个标签,从位置来看,Anchor A、C分别和标签M、N有一定的重叠,而Anchor B位置更像是背景。
首先介绍模型的真值。对于类别的真值,由于RPN只负责区域生成,保证recall,而没必要细分每一个区域属于哪一个类别,因此只需要前景与背景两个类别,前景即有物体,背景则没有物体。
RPN通过计算Anchor与标签的IoU来判断一个Anchor是属于前景还是背景。IoU的含义是两个框的公共部分占所有部分的比例,即重合比例。在图4.5中,Anchor A与标签M的IoU计算公式如式所示。

当IoU大于一定值时,该Anchor的真值为前景,低于一定值时,该Anchor的真值为背景。
然后是偏移量的真值。仍以图4.5中的Anchor A与标签M为例,假设Anchor A的中心坐标为xa与ya,宽高分别为wa与ha,标签M的中心坐标为x与y,宽高分别为w与h,则对应的偏移真值计算公式如式所示。
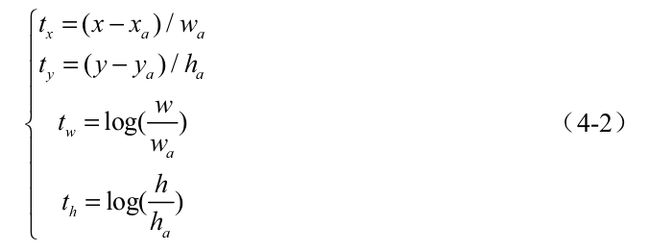
从式中可以看到,位置偏移tx与ty利用宽与高进行了归一化,而宽高偏移tw与th进行了对数处理,这样的好处是进一步限制了偏移量的范围,便于预测。 有了上述的真值,为了求取损失,RPN通过卷积网络分别得到了类别与偏移量的预测值。具体来讲,RPN需要预测每一个Anchor属于前景与背景的概率,同时也需要预测真实物体相对于Anchor的偏移量,记为tx、ty、tw和th。具体的网络下一节细讲。
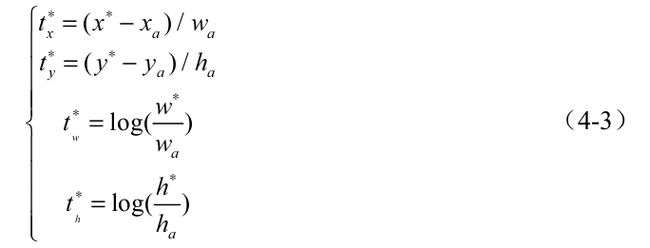
另外,在得到预测偏移量后,可以使用上式的公式将预测偏移量作用到对应的Anchor上,得到预测框的实际位置x、y、w和 h。
如果没有Anchor,做物体检测需要直接预测每个框的坐标,由于框的坐标变化幅度大,使网络很难收敛与准确预测,而Anchor相当于提供了一个先验的阶梯,使得模型去预测Anchor的偏移量,即可更好地接近真实物体。 实际上,Anchor是我们想要预测属性的先验参考值,并不局限于矩形框。如果需要,我们也可以增加其他类型的先验,如多边形框、角度和速度等。
RPN卷积网络:
为了实现上述的预测,RPN搭建了如图下图所示的网络结构。具体实现时,在feature map上首先用3×3的卷积进行更深的特征提取,然后利用1×1的卷积分别实现分类网络和回归网络。
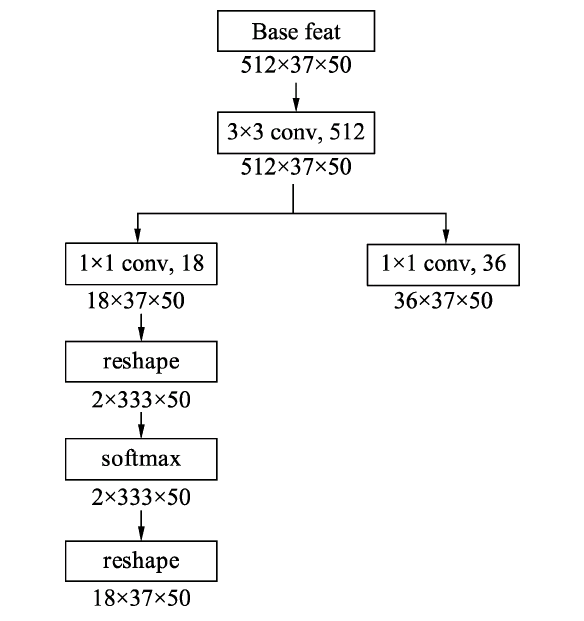
在物体检测中,通常我们将有物体的位置称为前景,没有物体的位置称为背景。在分类网络分支中,首先使用1×1卷积输出18×37×50的特征,由于每个点默认有9个Anchors,并且每个Anchor只预测其属于前景还是背景,因此通道数为18。随后利用torch.view()函数将特征映射到2×333×75,这样第一维仅仅是一个Anchor的前景背景得分,并送到Softmax函数中进行概率计算,得到的特征再变换到18×37×50的维度,最终输出的是每个Anchor属于前景与背景的概率。 在回归分支中,利用1×1卷积输出36×37×50的特征,第一维的36包含9个Anchors的预测,每一个Anchor有4个数据,分别代表了每一个Anchor的中心点横纵坐标及宽高这4个量相对于真值的偏移量。RPN的网络部分代码如下:
\# 输入数据的第一维是batch值
batch_size = base_feat.size(0)
\# 首先利用3×3卷积进一步融合特征
rpn_conv1 = F.relu(self.RPN_Conv(base_feat), inplace=True)
\# 利用1×1卷积得到分类网络,每个点代表Anchor的前景背景得分
rpn_cls_score = self.RPN_cls_score(rpn_conv1)
\# 利用reshape与softmax得到Anchor的前景背景概率
rpn_cls_score_reshape = self.reshape(rpn_cls_score, 2)
rpn_cls_prob_reshape = F.softmax(rpn_cls_score_reshape, 1)
rpn_cls_prob = self.reshape(rpn_cls_prob_reshape, 18)
\# 利用1×1卷积得到回归网络,每一个点代表Anchor的偏移
rpn_bbox_pred = self.RPN_bbox_pred(rpn_conv1)RPN真值的求取:

上面的RPN分类与回归网络得到的是模型的预测值,而为了计算预测的损失,还需要得到分类与偏移预测的真值,具体指的是每一个Anchor是否对应着真实物体,以及每一个Anchor对应物体的真实偏移值。求真值的具体实现过程如图所示,主要包含4步,下面具体介绍。
-
Anchor生成 这部分与前面Anchor的生成过程一样,可以得到37×50×9=16650个Anchors。由于按照这种方式生成的Anchor会有一些边界在图像边框外,因此还需要把这部分超过图像边框的Anchors过滤掉,具体生成过程如下:
def forward(self, input): ······ \# 利用NumPy首先得到原图上的中心点坐标,并利用contiguous保证内存连续 shifts = torch.from_numpy(np.vstack((shift_x.ravel(), shift_y.ravel(), shift_x.ravel(), shift_y.ravel())).transpose()) shifts = shifts.contiguous().type_as(rpn_cls_score).float() ······· \# 调用基础Anchor生成所有Anchors self._anchors = self._anchors.type_as(gt_boxes) all_anchors = self._anchors.view(1, A, 4) + shifts.view(K, 1, 4) ······· \# 保留边框内的Anchors inds_inside = torch.nonzero(keep).view(-1) anchors = all_anchors[inds_inside, :]
-
Anchor与标签的匹配 为了计算Anchor的损失,在生成Anchor之后,我们还需要得到每个Anchor的类别,由于RPN的作用是建议框生成,而非详细的分类,因此只需要区分正样本与负样本,即每个Anchor是属于正样本还是负样本。
前面已经介绍了通过计算Anchor与标签的IoU来判断是正样本还是负样本。在具体实现时,需要计算每一个Anchor与每一个标签的IoU,因此会得到一个IoU矩阵,具体的判断标准如下:
-
对于任何一个Anchor,与所有标签的最大IoU小于0.3,则视为负样本。
-
对于任何一个标签,与其有最大IoU的Anchor视为正样本。
-
对于任何一个Anchor,与所有标签的最大IoU大于0.7,则视为正样本。 匹配与筛选的代码示例如下:
需要注意的是,上述三者的顺序不能随意变动,要保证一个Anchor既符合正样本,也符合负样本时,赋予正样本。并且为了保证这一阶段的召回率,允许多个Anchors对应一个标签,而不允许一个标签对应多个Anchors。
-
-
Anchor的筛选 由于Anchor的总数量接近于2万,并且大部分Anchor的标签都是背景,如果都计算损失的话则正、负样本失去了均衡,不利于网络的收敛。在此,RPN默认选择256个Anchors进行损失的计算,其中最多不超过128个的正样本。如果数量超过了限定值,则进行随机选取。当然,这里的256与128都可以根据实际情况进行调整,而不是固定死的。
代码示例如下:
def forward(self, input): ···· for i in range(batch_size): \# 如果正样本数量太多,则进行下采样随机选取 if sum_fg[i] > 128: fg_inds = torch.nonzero(labels[i] == 1).view(-1) rand_num = torch.from_numpy(np.random.permutation (fg_inds.size(0))).type_as(gt_boxes).long() disable_inds = fg_inds[rand_num[:fg_inds.size(0)-num_fg]] labels[i][disable_inds] = -1 \# 负样本同上
-
求解回归偏移真值 上一步将每个Anchor赋予正样本或者负样本代表了预测类别的真值,而回归部分的偏移量真值还需要利用Anchor与对应的标签求解得到,具体公式见第二个式子。 得到偏移量的真值后,将其保存在bbox_targets中。与此同时,还需要求解两个权值矩阵bbox_inside_weights和bbox_outside_weights,前者是用来设置正样本回归的权重,正样本设置为1,负样本设置为0,因为负样本对应的是背景,不需要进行回归;后者的作用则是平衡RPN分类损失与回归损失的权重,在此设置为1/256。 求解回归的偏移真值示例如下:
def forward(self, input): ······ \# 选择每一个Anchor对应最大IoU的标签进行偏移计算 bbox_targets = _compute_targets_batch(anchors, gt_boxes.view(-1, 5)[argmax_overlaps.view(-1), :].view(batch_ size, -1, 5)) \# 设置两个权重向量 bbox_inside_weights[labels==1] = 1 num_examples = torch.sum(labels[i] >=0) bbox_outside_weights[labels == 1] = 1.0 / examples.item() bbox_outside_weights[labels == 0] = 1.0 / examples.item()真值的求取部分最后的输出包含了分类的标签label、回归偏移的真值bbox_targets,以及两个权重向量bbox_inside_weights与bbox_outside_weights。
损失函数:
有了网络预测值与真值,接下来就可以计算损失了。RPN的损失函数包含分类与回归两部分,具体公式如式所示。
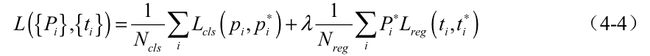
前一项代表了256个筛选出的Anchors的分类损失,Pi为每一个Anchor的类别真值,pi为每一个Anchor的预测类别。由于RPN的作用是选择出Proposal,并不要求细分出是哪一类前景,因此在这一阶段是二分类,使用的是交叉熵损失。值得注意的是,在F.cross_entropy()函数中集成了Softmax的操作,因此应该传入得分,而非经过Softmax之后的预测值。
后一项代表了回归损失,其中bbox_inside_weights实际上起到了pi进行筛选的作用,bbox_outside_weights起到了来平衡两部分损失的作用。回归损失使用了smoothL1函数,具体公式如式(4-5)与式(4-6)所示。
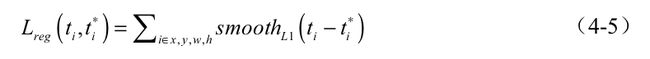

从式(4-6)中可以看到,smoothL1函数结合了1阶与2阶损失函数,原因在于,当预测偏移量与真值差距较大时,使用2阶函数时导数太大,模型容易发散而不容易收敛,因此在大于1时采用了导数较小的1阶损失函数。 损失函数的代码接口如下:
\# 先对scores进行筛选得到256个样本的得分,随后进行交叉熵求解
self.rpn_loss_cls = F.cross_entropy(rpn_cls_score, rpn_label)
\# 利用smoothL1损失函数进行loss计算
self.rpn_loss_box = _smooth_l1_loss(rpn_bbox_pred, rpn_bbox_targets,
rpn_bbox_inside_weights, rpn_bbox_outside_weights, sigma=3,
dim=[1, 2, 3])NMS与生成Proposal:
完成了损失的计算,RPN的另一个功能就是区域生成,即生成较好的Proposal,以供下一个阶段进行细分类与回归。
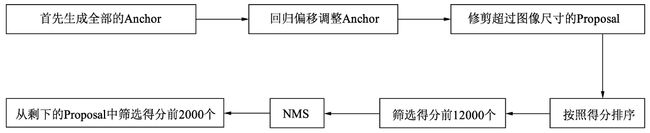
NMS生成Proposal的主要过程如图所示,首先生成大小固定的全部Anchors,然后将网络中得到的回归偏移作用到Anchor上使Anchor更加贴近于真值,并修剪超出图像尺寸的Proposal,得到最初的建议区域。在这之后,按照分类网络输出的得分对Anchor排序,保留前12000个得分高的Anchors。由于一个物体可能会有多个Anchors重叠对应,因此再应用非极大值抑制(NMS)将重叠的框去掉,最后在剩余的Proposal中再次根据RPN的预测得分选择前2000个,作为最终的Proposal,输出到下一个阶段。 NMS与Proposal的筛选过程如下,源代码:
def forward(self, input):
\# 生成Anchor后,首先利用回归网络对Anchor进行偏移修整
proposals = bbox_transform_inv(anchors, bbox_deltas, batch_size)
\# 将超出图像范围的边框修整到图像边界
proposals = clip_boxes(proposals, im_info, batch_size)
\# 利用分类网络的得分对proposal进行排序
_, order = torch.sort(scores_keep, 1, True)
\# 选取前12000个
order_single = order_single[:12000]
\# 进行NMS,在此利用GPU进行计算,提高效率
keep_idx_i = nms(torch.cat((proposals_single, scores_single), 1), 0.7,
force_cpu=False)
\# 最终选择前2000个作为最终的Proposal输出
keep_idx_i = keep_idx_i[:2000]
筛选Proposal得到ROl:
在训练时,上一步生成的Proposal数量为2000个,其中仍然有很多背景框,真正包含物体的仍占少数,因此完全可以针对Proposal进行再一步筛选,过程与RPN中筛选Anchor的过程类似,利用标签与Proposal构建IoU矩阵,通过与标签的重合程度选出256个正负样本。这一步有3个作用:
-
筛选出了更贴近真实物体的RoI,使送入到后续网络的物体正、负样本更均衡,避免了负样本过多,正样本过少的情况。
-
减少了送入后续全连接网络的数量,有效减少了计算量。
-
筛选Proposal得到RoI的过程中,由于使用了标签来筛选,因此也为每一个RoI赋予了正、负样本的标签,同时可以在此求得RoI变换到对应标签的偏移量,这样就求得了RCNN部分的真值。
具体实现时,首先计算Proposal与所有的物体标签的IoU矩阵,然后根据IoU矩阵的值来筛选出符合条件的正负样本。筛选标准如下:
-
对于任何一个Proposal,其与所有标签的最大IoU如果大于等于0.5,则视为正样本。
-
对于任何一个Proposal,其与所有标签的最大IoU如果大于等于0且小于0.5,则视为负样本。
经过上述标准的筛选,选出的正、负样本数量不一,在此设定正、负样本的总数为256个,其中正样本的数量为p个。为了控制正、负样本的比例基本满足1:3,在此正样本数量p不超过64,如果超过了64则从正样本中随机选取64个。剩余的数量256-p为负样本的数量,如果超过了256-p则从负样本中随机选取256-p个。 经过上述操作后,选出了最终的256个RoI,并且每一个RoI都赋予了正样本或者负样本的标签。在此也可以进一步求得每一个RoI的真值,即属于哪一个类别及对应真值物体的偏移量。 筛选Proposal过程的代码示例如下:
def _sample_rois_pytorch(self, all_rois, gt_boxes,
fg_rois_per_image, rois_per_image, num_class):
\# 利用Proposal与标签生成IoU矩阵
overlaps = bbox_overlaps_batch(all_rois, gt_boxes)
\# 选择满足条件的正负样本
fg_inds = torch.nonzero(max_overlaps[i] >= 0.5).view(-1)
bg_inds = torch.nonzero((max_overlaps[i] < 0.5 & max_overlaps[i] >= 0)).
view(-1)
\# 如果正样本超过64个,负样本超过(256-正样本)的数量,则进行下采样随机选取
rand_num torch.from_numpy(np.random.permutation
(fg_num_rois)).type_as(gt_boxes).long()
fg_inds = fg_inds[rand_num[:fg_rois_per_this_image]]
\# 计算每一个Proposal相对于其标签的偏移量,并记录权重
bbox_target_data = self._compute_targets_pytorch(rois_batch[:, :, 1:5],
gt_rois_batch[:,:,:4])
bbox_targets, bbox_inside_weights =
self._get_bbox_regression_labels_pytorch(bbox_target_data, labels_
batch, num_classes)最终返回分类的真值label,回归的偏移真值bbox_targets,以及每一个Proposal对应的权重bbox_inside_weights与bbox_outside_weights。
ROl Pooling层:
上述步骤得到了256个RoI,以及每一个RoI对应的类别与偏移量真值,为了计算损失,还需要计算每一个RoI的预测量。 前面的VGGNet网络已经提供了整张图像的feature map,因此自然联想到可以利用此feature map,将每一个RoI区域对应的特征提取出来,然后接入一个全连接网络,分别预测其RoI的分类与偏移量。 然而,由于RoI是由各种大小宽高不同的Anchors经过偏移修正、筛选等过程生成的,因此其大小不一且带有浮点数,然而后续相连的全连接网络要求输入特征大小维度固定,这就需要有一个模块,能够把各种维度不同的RoI变换到维度相同的特征,以满足后续全连接网络的要求,于是RoI Pooling就产生了。 对RoI进行池化的思想在SPPNet中就已经出现了,只不过在Fast RCNN中提出的RoI Pooling算法利用最近邻差值算法将池化过程进行了简化,而在随后的Mask RCNN中进一步提出了RoI Align的算法,利用双线性插值,进一步提升了算法精度。 在此我们举一个例子来讲解这几种算法的思想,假设当前RoI大小为332×332,使用VGGNet的全连接层,其所需的特征向量维度为512×7×7,由于目前的特征图通道数为512,Pooling的过程就是如何获得7×7大小区域的特征。
1.RoI Pooling简介 RoI Pooling的实现过程如图4.9所示,假设当前的RoI为图4.9中左侧图像的边框,大小为332×332,为了得到这个RoI的特征图,首先需要将该区域映射到全图的特征图上,由于下采样率为16,因此该区域在特征图上的坐标直接除以16并取整,而对应的大小为332/16=20.75。在此,RoI Pooling的做法是直接将浮点数量化为整数,取整为20×20,也就得到了该RoI的特征,即图中第3步的边框。
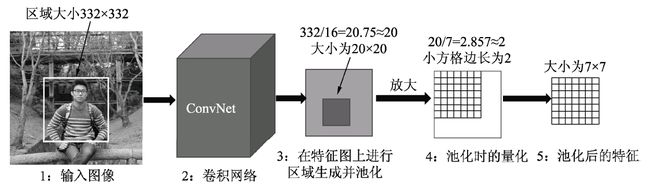
下一步还要将该20×20区域处理为7×7的特征,然而20/7≈2.857,再次出现浮点数,RoI Pooling的做法是再次量化取整,将2.857取整为2,然后以2为步长从左上角开始选取出7×7的区域,这样每个小方格在特征图上都对应2×2的大小,如图中第4步所示。
最后,取每个小方格内的最大特征值,作为这个小方格的输出,最终实现了7×7的输出,也完成了池化的过程,如图中第5步所示。
从实现过程中可以看到,RoI本来对应于20.75×20.75的特征图区域,最后只取了14×14的区域,因此RoI Pooling算法虽然简单,但量化取整带来的偏差势必会影响网络,尤其是回归物体位置的准确率。
2.RoI Align简介 RoI Align的思想是使用双线性插值获得坐标为浮点数的点的值,主要过程如下图所示,依然将RoI对应到特征图上,但坐标与大小都保留着浮点数,大小为20.75×20.75,不做量化。

接下来,将特征图上的20.75×20.75大小均匀分成7×7方格的大小,中间的点依然保留浮点数。在此选择其中2×2方格为例,如图4.11所示,在每一个小方格内的特定位置选取4个采样点进行特征采样,如图4.11中每个小方格选择了4个小黑点,然后对这4个黑点的值选择最大值,作为这个方格最终的特征。这4个小黑点的位置与值该如何计算呢?

对于黑点的位置,可以将小方格平均分成2×2的4份,然后这4份更小单元的中心点可以作为小黑点的位置。 至于如何计算这4个小黑点的值,RoI Align使用了双线性插值的方法。小黑点周围会有特征图上的4个特征点,利用这4个特征点双线性插值出该黑点的值。 由于Align算法最大可能地保留了原始区域的特征,因此Align算法对检测性能有显著的提升,尤其是对于受RoI Pooling影响大的情形,如本身特征区域较小的小物体,改善更为明显。上述步骤得到了256个RoI,以及每一个RoI对应的类别与偏移量真值,为了计算损失,还需要计算每一个RoI的预测量。
相关主干代码:
# --------------------------------------------------------
# Tensorflow Faster R-CNN
# Licensed under The MIT License [see LICENSE for details]
# Written by Jiasen Lu, Jianwei Yang, based on code from Ross Girshick
# --------------------------------------------------------
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import _init_paths
import os
import sys
import numpy as np
import argparse
import pprint
import pdb
import time
import cv2
import torch
from torch.autograd import Variable
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
import torchvision.datasets as dset
from scipy.misc import imread
from roi_data_layer.roidb import combined_roidb
from roi_data_layer.roibatchLoader import roibatchLoader
from model.utils.config import cfg, cfg_from_file, cfg_from_list, get_output_dir
from model.rpn.bbox_transform import clip_boxes
from model.nms.nms_wrapper import nms
from model.rpn.bbox_transform import bbox_transform_inv
from model.utils.net_utils import save_net, load_net, vis_detections
from model.utils.blob import im_list_to_blob
from model.faster_rcnn.vgg16 import vgg16
from model.faster_rcnn.resnet import resnet
import pdb
try:
xrange # Python 2
except NameError:
xrange = range # Python 3
def parse_args():
"""
Parse input arguments
"""
parser = argparse.ArgumentParser(description='Train a Fast R-CNN network')
parser.add_argument('--dataset', dest='dataset',
help='training dataset',
default='pascal_voc', type=str)
parser.add_argument('--cfg', dest='cfg_file',
help='optional config file',
default='cfgs/vgg16.yml', type=str)
parser.add_argument('--net', dest='net',
help='vgg16, res50, res101, res152',
default='vgg16', type=str)
parser.add_argument('--set', dest='set_cfgs',
help='set config keys', default=None,
nargs=argparse.REMAINDER)
parser.add_argument('--load_dir', dest='load_dir',
help='directory to load models',
default="models")
parser.add_argument('--image_dir', dest='image_dir',
help='directory to load images for demo',
default="images")
parser.add_argument('--cuda', dest='cuda',
help='whether use CUDA',
default=True, action='store_true')
parser.add_argument('--mGPUs', dest='mGPUs',
help='whether use multiple GPUs',
action='store_true')
parser.add_argument('--cag', dest='class_agnostic',
help='whether perform class_agnostic bbox regression',
action='store_true')
parser.add_argument('--parallel_type', dest='parallel_type',
help='which part of model to parallel, 0: all, 1: model before roi pooling',
default=0, type=int)
parser.add_argument('--checksession', dest='checksession',
help='checksession to load model',
default=1, type=int)
parser.add_argument('--checkepoch', dest='checkepoch',
help='checkepoch to load network',
default=1, type=int)
parser.add_argument('--checkpoint', dest='checkpoint',
help='checkpoint to load network',
default=10021, type=int)
parser.add_argument('--bs', dest='batch_size',
help='batch_size',
default=1, type=int)
parser.add_argument('--vis', dest='vis',
help='visualization mode',
action='store_true')
parser.add_argument('--webcam_num', dest='webcam_num',
help='webcam ID number',
default=-1, type=int)
args = parser.parse_args()
return args
lr = cfg.TRAIN.LEARNING_RATE
momentum = cfg.TRAIN.MOMENTUM
weight_decay = cfg.TRAIN.WEIGHT_DECAY
def _get_image_blob(im):
"""Converts an image into a network input.
Arguments:
im (ndarray): a color image in BGR order
Returns:
blob (ndarray): a data blob holding an image pyramid
im_scale_factors (list): list of image scales (relative to im) used
in the image pyramid
"""
im_orig = im.astype(np.float32, copy=True)
im_orig -= cfg.PIXEL_MEANS
im_shape = im_orig.shape
im_size_min = np.min(im_shape[0:2])
im_size_max = np.max(im_shape[0:2])
processed_ims = []
im_scale_factors = []
for target_size in cfg.TEST.SCALES:
im_scale = float(target_size) / float(im_size_min)
# Prevent the biggest axis from being more than MAX_SIZE
if np.round(im_scale * im_size_max) > cfg.TEST.MAX_SIZE:
im_scale = float(cfg.TEST.MAX_SIZE) / float(im_size_max)
im = cv2.resize(im_orig, None, None, fx=im_scale, fy=im_scale,
interpolation=cv2.INTER_LINEAR)
im_scale_factors.append(im_scale)
processed_ims.append(im)
# Create a blob to hold the input images
blob = im_list_to_blob(processed_ims)
return blob, np.array(im_scale_factors)
if __name__ == '__main__':
args = parse_args()
print('Called with args:')
print(args)
if args.cfg_file is not None:
cfg_from_file(args.cfg_file)
if args.set_cfgs is not None:
cfg_from_list(args.set_cfgs)
cfg.USE_GPU_NMS = args.cuda
print('Using config:')
pprint.pprint(cfg)
np.random.seed(cfg.RNG_SEED)
# train set
# -- Note: Use validation set and disable the flipped to enable faster loading.
input_dir = args.load_dir + "/" + args.net + "/" + args.dataset
if not os.path.exists(input_dir):
raise Exception('There is no input directory for loading network from ' + input_dir)
load_name = os.path.join(input_dir,
'faster_rcnn_{}_{}_{}.pth'.format(args.checksession, args.checkepoch, args.checkpoint))
pascal_classes = np.asarray(['__background__',
'aeroplane', 'bicycle', 'bird', 'boat',
'bottle', 'bus', 'car', 'cat', 'chair',
'cow', 'diningtable', 'dog', 'horse',
'motorbike', 'person', 'pottedplant',
'sheep', 'sofa', 'train', 'tvmonitor'])
# initilize the network here.
if args.net == 'vgg16':
fasterRCNN = vgg16(pascal_classes, pretrained=False, class_agnostic=args.class_agnostic)
elif args.net == 'res101':
fasterRCNN = resnet(pascal_classes, 101, pretrained=False, class_agnostic=args.class_agnostic)
elif args.net == 'res50':
fasterRCNN = resnet(pascal_classes, 50, pretrained=False, class_agnostic=args.class_agnostic)
elif args.net == 'res152':
fasterRCNN = resnet(pascal_classes, 152, pretrained=False, class_agnostic=args.class_agnostic)
else:
print("network is not defined")
pdb.set_trace()
fasterRCNN.create_architecture()
print("load checkpoint %s" % (load_name))
if args.cuda > 0:
checkpoint = torch.load(load_name)
else:
checkpoint = torch.load(load_name, map_location=(lambda storage, loc: storage))
fasterRCNN.load_state_dict(checkpoint['model'])
if 'pooling_mode' in checkpoint.keys():
cfg.POOLING_MODE = checkpoint['pooling_mode']
print('load model successfully!')
# pdb.set_trace()
print("load checkpoint %s" % (load_name))
# initilize the tensor holder here.
im_data = torch.FloatTensor(1)
im_info = torch.FloatTensor(1)
num_boxes = torch.LongTensor(1)
gt_boxes = torch.FloatTensor(1)
# ship to cuda
if args.cuda > 0:
im_data = im_data.cuda()
im_info = im_info.cuda()
num_boxes = num_boxes.cuda()
gt_boxes = gt_boxes.cuda()
# make variable
im_data = Variable(im_data, volatile=True)
im_info = Variable(im_info, volatile=True)
num_boxes = Variable(num_boxes, volatile=True)
gt_boxes = Variable(gt_boxes, volatile=True)
if args.cuda > 0:
cfg.CUDA = True
if args.cuda > 0:
fasterRCNN.cuda()
fasterRCNN.eval()
start = time.time()
max_per_image = 100
thresh = 0.05
vis = True
webcam_num = args.webcam_num
# Set up webcam or get image directories
if webcam_num >= 0 :
cap = cv2.VideoCapture(webcam_num)
num_images = 0
else:
imglist = os.listdir(args.image_dir)
num_images = len(imglist)
print('Loaded Photo: {} images.'.format(num_images))
while (num_images >= 0):
total_tic = time.time()
if webcam_num == -1:
num_images -= 1
# Get image from the webcam
if webcam_num >= 0:
if not cap.isOpened():
raise RuntimeError("Webcam could not open. Please check connection.")
ret, frame = cap.read()
im_in = np.array(frame)
# Load the demo image
else:
im_file = os.path.join(args.image_dir, imglist[num_images])
# im = cv2.imread(im_file)
im_in = np.array(imread(im_file))
if len(im_in.shape) == 2:
im_in = im_in[:,:,np.newaxis]
im_in = np.concatenate((im_in,im_in,im_in), axis=2)
# rgb -> bgr
im = im_in[:,:,::-1]
blobs, im_scales = _get_image_blob(im)
assert len(im_scales) == 1, "Only single-image batch implemented"
im_blob = blobs
im_info_np = np.array([[im_blob.shape[1], im_blob.shape[2], im_scales[0]]], dtype=np.float32)
im_data_pt = torch.from_numpy(im_blob)
im_data_pt = im_data_pt.permute(0, 3, 1, 2)
im_info_pt = torch.from_numpy(im_info_np)
im_data.data.resize_(im_data_pt.size()).copy_(im_data_pt)
im_info.data.resize_(im_info_pt.size()).copy_(im_info_pt)
gt_boxes.data.resize_(1, 1, 5).zero_()
num_boxes.data.resize_(1).zero_()
# pdb.set_trace()
det_tic = time.time()
rois, cls_prob, bbox_pred, \
rpn_loss_cls, rpn_loss_box, \
RCNN_loss_cls, RCNN_loss_bbox, \
rois_label = fasterRCNN(im_data, im_info, gt_boxes, num_boxes)
scores = cls_prob.data
boxes = rois.data[:, :, 1:5]
if cfg.TEST.BBOX_REG:
# Apply bounding-box regression deltas
box_deltas = bbox_pred.data
if cfg.TRAIN.BBOX_NORMALIZE_TARGETS_PRECOMPUTED:
# Optionally normalize targets by a precomputed mean and stdev
if args.class_agnostic:
if args.cuda > 0:
box_deltas = box_deltas.view(-1, 4) * torch.FloatTensor(cfg.TRAIN.BBOX_NORMALIZE_STDS).cuda() \
+ torch.FloatTensor(cfg.TRAIN.BBOX_NORMALIZE_MEANS).cuda()
else:
box_deltas = box_deltas.view(-1, 4) * torch.FloatTensor(cfg.TRAIN.BBOX_NORMALIZE_STDS) \
+ torch.FloatTensor(cfg.TRAIN.BBOX_NORMALIZE_MEANS)
box_deltas = box_deltas.view(1, -1, 4)
else:
if args.cuda > 0:
box_deltas = box_deltas.view(-1, 4) * torch.FloatTensor(cfg.TRAIN.BBOX_NORMALIZE_STDS).cuda() \
+ torch.FloatTensor(cfg.TRAIN.BBOX_NORMALIZE_MEANS).cuda()
else:
box_deltas = box_deltas.view(-1, 4) * torch.FloatTensor(cfg.TRAIN.BBOX_NORMALIZE_STDS) \
+ torch.FloatTensor(cfg.TRAIN.BBOX_NORMALIZE_MEANS)
box_deltas = box_deltas.view(1, -1, 4 * len(pascal_classes))
pred_boxes = bbox_transform_inv(boxes, box_deltas, 1)
pred_boxes = clip_boxes(pred_boxes, im_info.data, 1)
else:
# Simply repeat the boxes, once for each class
pred_boxes = np.tile(boxes, (1, scores.shape[1]))
pred_boxes /= im_scales[0]
scores = scores.squeeze()
pred_boxes = pred_boxes.squeeze()
det_toc = time.time()
detect_time = det_toc - det_tic
misc_tic = time.time()
if vis:
im2show = np.copy(im)
for j in xrange(1, len(pascal_classes)):
inds = torch.nonzero(scores[:,j]>thresh).view(-1)
# if there is det
if inds.numel() > 0:
cls_scores = scores[:,j][inds]
_, order = torch.sort(cls_scores, 0, True)
if args.class_agnostic:
cls_boxes = pred_boxes[inds, :]
else:
cls_boxes = pred_boxes[inds][:, j * 4:(j + 1) * 4]
cls_dets = torch.cat((cls_boxes, cls_scores.unsqueeze(1)), 1)
# cls_dets = torch.cat((cls_boxes, cls_scores), 1)
cls_dets = cls_dets[order]
keep = nms(cls_dets, cfg.TEST.NMS, force_cpu=not cfg.USE_GPU_NMS)
cls_dets = cls_dets[keep.view(-1).long()]
if vis:
im2show = vis_detections(im2show, pascal_classes[j], cls_dets.cpu().numpy(), 0.5)
misc_toc = time.time()
nms_time = misc_toc - misc_tic
if webcam_num == -1:
sys.stdout.write('im_detect: {:d}/{:d} {:.3f}s {:.3f}s \r' \
.format(num_images + 1, len(imglist), detect_time, nms_time))
sys.stdout.flush()
if vis and webcam_num == -1:
# cv2.imshow('test', im2show)
# cv2.waitKey(0)
result_path = os.path.join(args.image_dir, imglist[num_images][:-4] + "_det.jpg")
cv2.imwrite(result_path, im2show)
else:
im2showRGB = cv2.cvtColor(im2show, cv2.COLOR_BGR2RGB)
cv2.imshow("frame", im2showRGB)
total_toc = time.time()
total_time = total_toc - total_tic
frame_rate = 1 / total_time
print('Frame rate:', frame_rate)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
if webcam_num >= 0:
cap.release()
cv2.destroyAllWindows()

全部的源码地址:aaalds/faster-rcnn-pytorch: Faster RCNN用pytorch实现 (github.com)