Python爬虫从入门到精通(三)简单爬虫的实现
目录
一、可能是史上最简单的爬虫Demo
二、回顾一下HTTP,HTTPS协议
1、关于URL:
2、HTTP协议,HTTPS协议
3、HTTP Request请求常用的两种方法:
4、关于****User-Agent
5、HTTP Response响应的状态码:
6、HTTP 响应体是我们爬虫需要关心的协议部分的内容:
三、关于爬虫抓取的策略
1、深度优先算法
2、广度/宽度优先算法
3、 实践中怎么来组合抓取策略
前言必读:
v搜索公众号:zhulin1028
后台回复:【Python1】【Python2】【Python3】【Python全栈】
免费获取对应资料。
欢迎技术交流,加我V:ZL3132537525一、可能是史上最简单的爬虫Demo
最简单的爬虫Demo:
第一个爬虫程序,两行代码写一个爬虫:
import urllib #Python3
print(urllib.request.urlopen(urllib.request.Request("GitHub - richardpenman/wswp_places")).read() )
这两行代码在Python3.6下可以正常运行,获取http://example.webscraping.com
这个页面的内容;
备注:如果是Python3 ,则使用如下两行代码:
import requests #Python3
print(requests.get('http://example.webscraping.com').text)如果没有requests 库,则需要使用命令pip install requests 安装一下;
说明:本讲义目前大部分代码以Python3.6的代码位蓝本,讲义的附录A中会将Python2和Python3在爬虫这块最主要几个库的对照表收录进来,按照这张表就可以方便的实现Python2与Python3在爬虫这块代码的移植。
二、回顾一下HTTP,HTTPS协议
1、关于URL:
URL(Uniform / Universal Resource Locator的缩写):统一资源定位符,是用于完整地描述Internet上网页和其他资源的地址的一种标识方法。
基本格式:scheme://host[:port#]/path/…/[?query-string][#anchor]
scheme:协议(例如:http, https, ftp)
host:服务器的IP地址或者域名
port#:服务器的端口(如果是走协议默认端口,缺省端口80)
path:访问资源的路径
query-string:参数,发送给http服务器的数据
anchor:锚(跳转到网页的指定锚点位置)
例如:
http://www.baidu.com
ftp://192.168.1.118:8081/index
URL是爬虫的入口,非常的重要。
2、HTTP协议,HTTPS协议
HTTP协议(HyperText Transfer Protocol,超文本传输协议):是一种发布和接收 HTML页面的方法。HTTP协议是一个应用层的协议,无连接(每次连接只处理一个请求),无状态(每次连接,传输都是独立的)
HTTPS(Hypertext Transfer Protocol over Secure Socket Layer)协议简单讲是HTTP的安全版,在HTTP下加入SSL层。HTTPS = HTTP+SSL(Secure Sockets Layer 安全套接层)主要用于Web的安全传输协议,在传输层对网络连接进行加密,保障在Internet上数据传输的安全
HTTP的端口号为80;HTTPS的端口号为443;
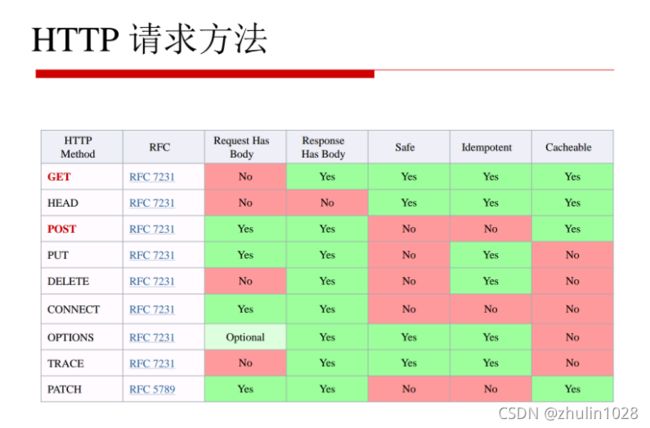
3、HTTP Request请求常用的两种方法:
Get:是为了从服务器上获取信息,传输给服务器的数据的过程不够安全,数据大小有限制;
Post:向服务器传递数据,传输数据的过程是安全的,大小理论上没有限制;
 4、关于****User-Agent
4、关于****User-Agent
User Agent中文名为用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。
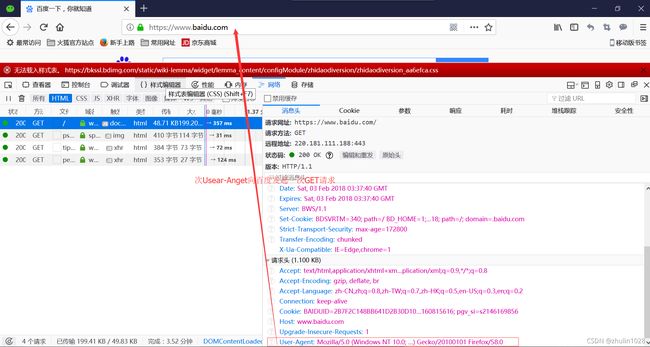
我们来看下我们最简单的爬虫跑起来时告诉服务器的User-Agent是什么?
通过这个例子,我们发现Python爬虫有个默认的带有版本号的User-Agent,由此很容易能识别出来这是一个Python写的爬虫程序。所以如果用默认的User-Agent,那些反爬虫的程序一眼就能识别出来我们是个Python爬虫,这对Python爬虫是不利的。
那么,我们如何修改这个User-Agent,来伪装我们的爬虫程序呢?
# Http协议中请求头的信息
headers={"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36"}
req = request.Request("http://www.sina.com.cn",
headers=headers)
# 返回http.client.HTTPResponse
response = request.urlopen(req)5、HTTP Response响应的状态码:
200为成功,300是跳转;
400,500意味着有错误:

说明:服务器返回给爬虫的信息可以用来判断我们爬虫当前是否正常在运行;
当出现异常错误时:一般来说如果是500的错误那么爬虫会进入休眠状态,说明服务器已经宕机;如果是400的错误,则需要考虑爬虫的抓取策略的修改,可能是网站更新了,或者是爬虫被禁了。如果在一个分布式的爬虫系统中,更容易发现和调整爬虫的策略。
6、HTTP 响应体是我们爬虫需要关心的协议部分的内容:
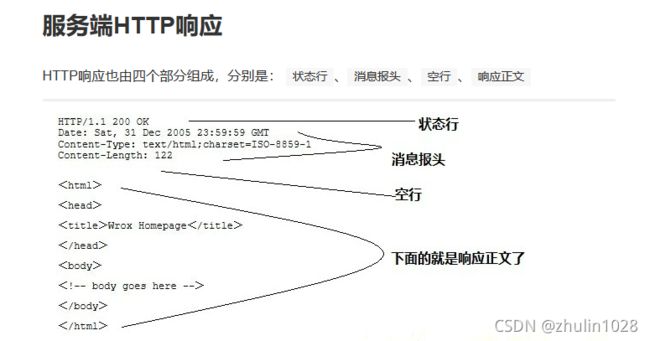
通过Python的交互是环境,我们可以直观的方便的看到请求响应的信息,这也看出了Python瑞士军刀般的作用。
>>> import requests #Python3
>>> html = requests.get('http://example.webscraping.com')
>>> print(html.status_code)
200
>>> print(html.elapsed)
0:00:00.818880
>>> print(html.encoding)
utf-8
>>> print(html.headers)
{'Server': 'nginx', 'Date': 'Thu, 01 Feb 2018 09:23:30 GMT', 'Content-Type': 'text/html; charset=utf-8', 'Transfer-Encoding': 'chunked', 'Connection': 'keep-alive', 'Vary': 'Accept-Encoding', 'X-Powered-By': 'web2py', 'Set-Cookie': 'session_id_places=True; httponly; Path=/, session_data_places="6853de2931bf0e3a629e019a5c352fca:1Ekg3FlJ7obeqV0rcDDmjBm3y4P4ykVgQojt-qrS33TLNlpfFzO2OuXnY4nyl5sDvdq7p78_wiPyNNUPSdT2ApePNAQdS4pr-gvGc0VvnXo3TazWF8EPT7DXoXIgHLJbcXoHpfleGTwrWJaHq1WuUk4yjHzYtpOhAbnrdBF9_Hw0OFm6-aDK_J25J_asQ0f7"; Path=/', 'Expires': 'Thu, 01 Feb 2018 09:23:30 GMT', 'Pragma': 'no-cache', 'Cache-Control': 'no-store, no-cache, must-revalidate, post-check=0, pre-check=0', 'Content-Encoding': 'gzip'}
>>> print(html.content)
# 略,内容太多了
三、关于爬虫抓取的策略
一般在抓取爬虫数据时,我们不会只抓取一个入口的URL数据就停止了。当有多个URL链接需要抓取时,我们怎么办?
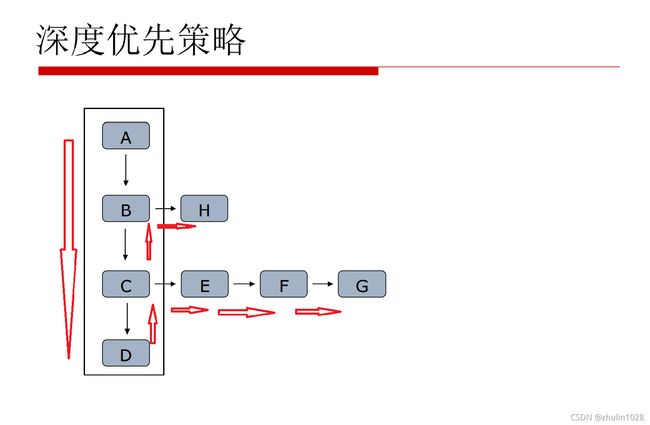
1、深度优先算法
深度优先是指搜索引擎先从网站页面上的某个链接进行抓取,进入到这个链接的页面之后,抓取页面上的内容,然后继续顺着当前页面上的这个链接进行抓取下去,直到顺着这个页面上的链接全部抓取完,最深的页面上没有链接了,爬虫再回过头来顺着第一个网站页面上的另外一个链接进行抓取;如下图所示。
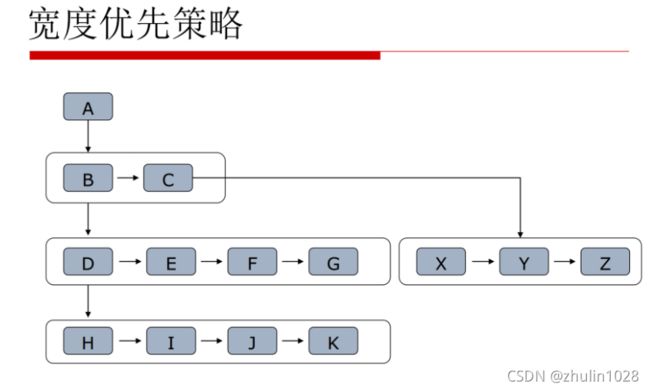
2、广度/宽度优先算法
广度优先则是另一个过程,它先把该层次的都遍历完,再继续往下走。
如下图所示:
练习: 构造一个完全二叉树,实现其深度优先和广度优先遍历算法。
一棵二叉树至多只有最下面的一层上的结点的度数可以小2,并且最下层上的结点都集中在该层最左边的若干位置上,而在最后一层上,右边的若干结点缺失的二叉树,则此二叉树成为完全二叉树。
完全二叉树如下:
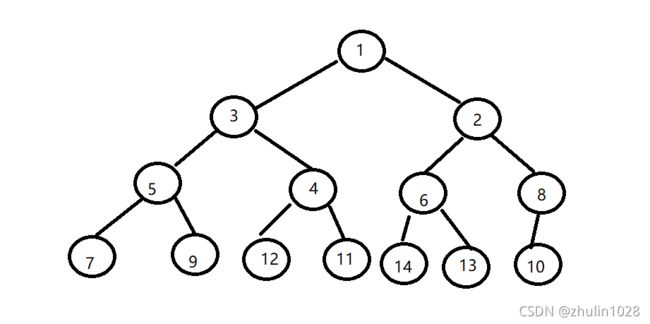
深度优先遍历的结果:[1, 3, 5, 7, 9, 4, 12, 11, 2, 6, 14, 13, 8, 10]
广度优先遍历的结果:[1, 3, 2, 5, 4, 6, 8, 7, 9, 12, 11, 14, 13, 10]
3、 实践中怎么来组合抓取策略
1.一般来说,重要的网页距离入口站点的距离很近;
2.宽度优先有利于多爬虫并行进行合作;
3.可以考虑将深度与广度相结合的方式来实现抓取的策略:优先考虑广度优先,
对深度进行限制最大深度;
总结:一个通用爬虫的流程如下:
