MySQL系列-innodb doublewrite
DBW(double write)
double wirte是innodb存储引擎为了保证数据页的安全性而引入的一项技术,那么数据库安全性从何说起呢?
就从数据磁盘的一次io是4KB说起,一项简单的命令来证实。
[root@hostname ~]# getconf PAGESIZE
4096众所周知mysql数据页(page)大小为16KB,那么就会出现一个现象就是innodb一次IO,OS往往需要4次IO才能处理完,这就会引入一个问题,如果在第2次或者第3次IO的时候数据库crash或者服务器或者存储掉电等等不可抗力现象出现时数据库写入数据页不完整,数据库出现了名副其实的物理坏块。这是在以数据安全为宗旨的数据库领域不被接受和允许的。那么可能会有很多人想到redo和binlog,或许会有这样的一个疑问,innodb 刷脏过程中数据库或者os crash的话可以由redo或者binlog来恢复啊,其实了解redo和binlog之后就会得到答案是否定的,redo记录的是物理位置(即变更向量)binlog记录的是逻辑日志(即纯粹的SQL),他们都无法恢复这个数据页的数据,毕竟每一次更改不是改变了整个数据页,而是改变一个数据页的一小部分。
下面做一个数据写入过程的大致描述:
当用户userA发起一个update,首先需要从os存储(.ibd文件)中读取对应的数据页到buffer cache中;然后SQL对其进行更改,更改的数据物理位置(位置偏移量)写入redo log;完成日志落盘后buffer刷脏时,需要将buffer中更改的脏数据页(dirty page)完完整整的写入OS存储中,这里就会出现数据库和OS调用IO次数不同的鸿沟。
注:此过程描述主要为了描述数据刷脏,其他过程不做详细赘述
innodb为了解决这一问题引入了double write,顾名思义就是innodb IO线程需要写两次。在buffer中单独开辟一块内存用来存储脏页(同其他内存一样是通过LRU list管理),在数据库初始化的时候会确定具体的位置,同时使用真实的存储DBW数据的空间,对应的空间都是一个簇(被同一个段管理),一个簇包括64个页面,16KB*64,=1MB,两次写就是2MB,当出现写丢失时通过持久化的DBW表空间对数据文件(.ibd)进行恢复,保证数据页的完整性。DBW buffer每次刷脏时是直接一次1M的将脏数据从DBW buffer连续的写入DBW表空间中,顺序写入速度极快,并不会对性能造成太大的影响。
[root@MySQL8-SmallA mysql]# ls -lh *.dblwr
-rw-r-----. 1 mysql mysql 384K 11月 24 17:22 #ib_16384_0.dblwr
-rw-r-----. 1 mysql mysql 8.4M 11月 16 2020 #ib_16384_1.dblwrinnodb怎么保证数据文件写入完整性
从数据页结构中可以看到在每个页尾部都有一个file trailer,其只有一个FIL_PAGE_END_LSN部分,占用8字节,前4个字节代表checksum值,后4个字节和file header中的FIL_PAGE_LSN相同,将这两个值与file header中的FILE_PAGE_SPACE_OR_CHECKSUM和FILE_PAGE_LSN值进行比较是否一致,以此来保证页的完整性(not corrupted)
在IO线程从DBW buffer异步的写入DBW内存后回去校验file trailer,确保校验完整才会认为写入成功,否则数据库就会crash。来确保数据完整性。

innodb通过一次将DBW buffer1M(64 page)完全写入DBW表空间,并通过数据页file trailer来验证数据页写入的完整性,来保证脏页刷新不丢失
通过源码可以发现实际上mysql是有page checksum操作的
/** Issue a warning when the checksum that is stored in the page is valid,
but different than the global setting innodb_checksum_algorithm.
@param[in] curr_algo current checksum algorithm
@param[in] page_checksum page valid checksum
@param[in] page_id page identifier */
voidpage_warn_strict_checksum(srv_checksum_algorithm_tcurr_algo,
srv_checksum_algorithm_tpage_checksum,
constpage_id_t&page_id);
/** Issue a warning when the checksum that is stored in the page is valid,
but different than the global setting innodb_checksum_algorithm.
@param[in] curr_algo current checksum algorithm
@param[in] page_checksum page valid checksum
@param[in] page_id page identifier */
voidpage_warn_strict_checksum(srv_checksum_algorithm_tcurr_algo,
srv_checksum_algorithm_tpage_checksum,
constpage_id_t&page_id);工作方式
DBW在实际写入中分为单一页面刷入磁盘和批量页面刷入磁盘 。
单一page刷入磁盘:
在第一次建库时,会分配一个段的空间存储DBW信息偏移位置(TRX_SYS_DOUBLEWRITE_FSEG),每次使用DBW机制写数据时都会读取到段这个位置已确定段的首选地址。TRX_SYS_DOUBLEWRITE_MAGIC位置用来存储DBW写入状态的标志。TRX_SYS_DOUBLEWRITE_BLOCK1和TRX_SYS_DOUBLEWRITE_BLOCK2存储BDW的空间位置,他们在DBW表空间(ibdata或#ib_16384_1.dblwr)属于同一个段,在初始化数据库时确定。TRX_SYS_DOUBLEWRITE_REPEAT存储的是TRX_SYS_DOUBLEWRITE_MAGIC+TRX_SYS_DOUBLEWRITE_BLOCK1+TRX_SYS_DOUBLEWRITE_BLOCK2。同时在内存区域也会有一个数组(128page 即DBW buffer)来管理这些。在进行page落盘的时候现在DBW buffer(即DBW 数组)找到一个空闲位置,然后将这个位置标记为已使用状态,然后memcopy函数将dirty page复制到DBW buffer中,复制完成之后会将这个页面数据异步(ASYNC)的写入到DBW表空间(ibdata或#ib_16384_1.dblwr)中,这里DBW的偏移位置信息是一一对应的,写入成功之后调用异步IO(ASYNC)离散的写入数据文件中(.ibd),写入完毕之后返回主线程刷脏成功,DWB buffer释放进行下一轮刷脏,同时DBW表空间进行复用。
/* 存储DBW page所在段的地址信息 */
#define TRX_SYS_DOUBLEWRITE_FSEG 0
/*!< 用来判断是否已经初始化过DBW page */
#define TRX_SYS_DOUBLEWRITE_MAGIC FSEG_HEADER_SIZE
/*! DBW page第一个簇的首地址,DBW共两个簇,每个簇64 page */
#define TRX_SYS_DOUBLEWRITE_BLOCK1 (4+ FSEG_HEADER_SIZE)
/*! DBW page第而二个簇的首地址 */
#define TRX_SYS_DOUBLEWRITE_BLOCK2 (8+ FSEG_HEADER_SIZE)
/* 重复存储MAGIC、BLOCK1、BLOCK2信息 */
#define TRX_SYS_DOUBLEWRITE_REPEAT 12批量page写入磁盘
讨论完一个page写入磁盘过程,就必须要考虑到生产环境中多page的情况,mysql势必要进行IO合并来减少IO操作。InnoDB将buffer分成多个instance,每个instance管理自身一套DBW buffer(通过LRUlist管理),当然这也是为了减少buffer里的latch争用,每个instance批量缓存空间由innodb_doublewrite_batch_size控制,默认120个。
DBW page(128 page)=innodb_buffer_pool_instances *2(list +lru) * innodb_doublewrite_batch_size
其逻辑架构如下

其中管理buffer写入的方式分为LRU和LIST。如果buffer使用较高,需要淘汰内存区域就需要LRU管理,根据当前page所在的instance找到对应的shared缓存,如果shared没有写满(即未达到innodb_doublewrite_batch_size大小)就字节追加到shared区域即可,此时不需要进行DBW写入。如果shared已经写满(即已经达到innodb_doublewrite_batch_size大小)就需要先将shared缓存异步(ASYNC)写入DBW表空间中,待整个shared页面都已写入完成然后在异步(ASYNC)的随机写入数据文件(.idb)文件中,然后这个shared才可以被重新使用
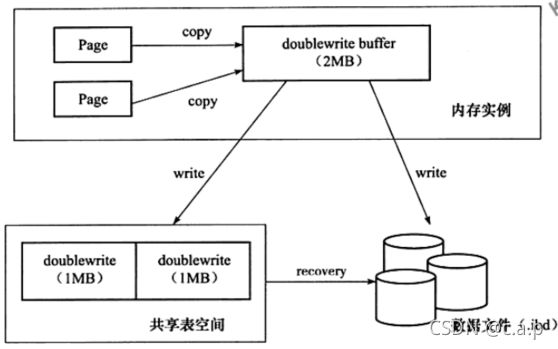
如何保证数据完整可恢复
①如果dirty page在写入DBW表空间前数据库crash,可通过binlog+redo log进行恢复
②如果写入DBW表空间后还没有写入数据文件(.ibd),可通过DBW表空间recover数据文件(.ibd)
DBW带来的性能问题
虽然在整个double write过程中innodb触发了两次async(一次写入DBW表空间,一次写入数据文件),但是所要消耗的时间可不是原来的两倍,由于写入DBW表空间是顺序写入,所消耗的时间极端,经测试开启DBW后innodb的写入时间仅仅比不开启高10%,为了数据安全方式写丢失,这个代价是可以承受的。
DBW相关参数
mysql> select version();
+-----------+
| version() |
+-----------+
| 8.0.21 |
+-----------+
1 row in set (0.00 sec)
mysql> show variables like '%double%';
+-------------------------------+-------+
| Variable_name | Value |
+-------------------------------+-------+
| innodb_doublewrite | ON |
| innodb_doublewrite_batch_size | 0 |
| innodb_doublewrite_dir | |
| innodb_doublewrite_files | 2 |
| innodb_doublewrite_pages | 8 |
+-------------------------------+-------+
5 rows in set (0.00 sec)
mysql> innodb_doublewrite:控制是否启用doublewrite buffer。默认启用。设置innodb_doublewrite=0或者启动MySQL服务时加--skip-innodb-doublewrite选项禁用。
innodb_doublewrite_dir:8.0.20引入的,定义了InnoDB创建双写文件的目录。如果目录没有指定,双写文件创建在数据目录下。哈希符'#'会自动创建在指定目录名前缀,避免与shema名冲突。
innodb_doublewrite_files:参数定义了双写文件的数量。默认情况下,每个缓冲池实例都会创建2个双写文件:一个刷新列表双写文件和一个LRU列表双写文件。
刷新列表双写文件用于从缓冲池刷新列表中刷新页。刷新列表双写文件默认大小是InnoDB page size * doublewrite page bytes.
LRU列表双写文件是用于刷新从缓冲池LRU列表的页。它也包括单个页刷新的槽。LRU列表双写文件默认大小为InnoDB page size * (doublewrite pages + (512 / the number of buffer pool instances)),512是为单个页刷新保留的槽的总数。
至少有2个双写文件。双写文件的最大数量是缓冲池实例的两倍。(缓冲池实例的数量由参数innodb_buffer_pool_instances控制)双写文件有以下格式:#ib_page_size_file_number.dblwr。
[root@MySQL8-SmallA mysql]# ls -lh *.dblwr
-rw-r-----. 1 mysql mysql 384K 11月 24 17:22 #ib_16384_0.dblwr
-rw-r-----. 1 mysql mysql 8.4M 11月 16 2020 #ib_16384_1.dblwrinnodb_doublewrite_pages:MySQL8.0.20引入的,控制每个线程双写页的最大数量。如果这个值没有指定,innodb_doublewrite_pages设置为innodb_write_io_threads值。这个参数用于高级性能调优。默认值已经适用于大多数用户。
innodb_doublewrite_batch_size:参数MySQL8.0.20引入的,控制一批写入双写页的数量。这个参数用于高级性能调优。默认值已经适用于大多数用户。
DBW不适用的场景
double write默认是开启的,
①如果都使用了支持原子写的fusion-io 等存储设备,那么double write机制会被自动disable。同时官方建议将innodb_fush_method设置为o_direct;这样可以充分发挥硬件性能。
②如果文件系统类型是ZFS类型,innodb也会自动禁用double write。
#if!defined(NO_FALLOCATE) &&defined(UNIV_LINUX)
/* Note: This should really be per node and not per
tablespace because a tablespace can contain multiple
files (nodes). The implication is that all files of
the tablespace should be on the same medium. */
if (fil_fusionio_enable_atomic_write(it->m_handle)) {
if (srv_use_doublewrite_buf) {
ib::info(ER_IB_MSG_456) << "FusionIO atomic IO enabled,"
" disabling the double write buffer";
srv_use_doublewrite_buf = false;
}
it->m_atomic_write = true;
} else {
it->m_atomic_write = false;
}
#else
it->m_atomic_write = false;
#endif /* !NO_FALLOCATE && UNIV_LINUX*/
#if!defined(NO_FALLOCATE) &&defined(UNIV_LINUX)
/* Note: This should really be per node and not per
tablespace because a tablespace can contain multiple
files (nodes). The implication is that all files of
the tablespace should be on the same medium. */
if (fil_fusionio_enable_atomic_write(it->m_handle)) {
if (srv_use_doublewrite_buf) {
ib::info(ER_IB_MSG_456) << "FusionIO atomic IO enabled,"
" disabling the double write buffer";
srv_use_doublewrite_buf = false;
}
it->m_atomic_write = true;
} else {
it->m_atomic_write = false;
}
#else
it->m_atomic_write = false;
#endif /* !NO_FALLOCATE && UNIV_LINUX*/③批量导入数据时,可关掉DBW
④服务器磁盘性能较低,已成为影响性能的主要因素时,关闭DBW提高性能。
Oracle中为什么没有DBW
了解Oracle的人可能会有这样的一个疑问,既然innodb为了保证数据的完整性有DBW这样的一个技术,那么怎么没有听说Oracle类似的技术呢,Oracle又是如何保证数据完整性防止写丢失的呢。
说到这里需要知道的是Oracle默认数据块大小为8KB,实际Oracle在数据完整性这一方面做了很多努力,他是直接写入数据文件并多重校验的。
下面看下Oracle data block
BBED> set file 7 block 347
FILE# 7
BLOCK# 347
BBED> map
File: /opt/oracle/oradata/ENMOTECH/users01.dbf (7)
Block: 347 Dba:0x01c0015b
------------------------------------------------------------
KTB Data Block (Table/Cluster)
struct kcbh, 20 bytes @0
struct ktbbh, 96 bytes @20
struct kdbh, 14 bytes @124
struct kdbt[1], 4 bytes @138
sb2 kdbr[66] @142
ub1 freespace[911] @274
ub1 rowdata[7003] @1185
ub4 tailchk @8188
BBED> p kcbh
struct kcbh, 20 bytes @0
ub1 type_kcbh @0 0x06
ub1 frmt_kcbh @1 0xa2
ub2 wrp2_kcbh @2 0x0000
ub4 rdba_kcbh @4 0x01c0015b
ub4 bas_kcbh @8 0x00791f1a
ub2 wrp_kcbh @12 0x0000
ub1 seq_kcbh @14 0x02
ub1 flg_kcbh @15 0x04 (KCBHFCKV)
ub2 chkval_kcbh @16 0xfe84
ub2 spare3_kcbh @18 0x0000
BBED> p tailchk
ub4 tailchk @8188 0x1f1a0602从结构上来看,我们知道Oracle 这里有一种机制来判断Block是否属于断裂block,即在block尾部写入一个tailchk值,其中tailchk 的value=bas_kcbh(后4位)+type_kcbh+seq_kcbh。
正常业务逻辑的情况下,如果检查发现块头部和尾部的值不匹配,则认为是断裂块。Oracle中的标准叫法为Fractured Block
Oracle keeps track off the header of each block and before writing down to disk updates a 4 byte field/value in the tail of each block (tailchk) to guarantee afterwards consistency check that the block is complete after written.
然后Oracle在每次读写的时候都要进行checksum进行校验,一旦写入失败就会进行回退,其实及时这样我们仍能在很繁忙的Oracle系统上见到物理坏块,所以很常见的会通过expdp或者ogg对数据库系统进行容灾备份。
关于Oracle doublewrite问题可以了解一下roger对double的研究https://www.modb.pro/db/23489
--end