学习笔记:人脸检测和人脸识别
人脸检测( Face Detection )和人脸识别技术是深度学习的重要应用之一。本章首先会介绍MTCNN算法的原理, 它是基于卷积神经网络的一种高精度的实时人脸检测和对齐技术。接着,还会介绍如何利用深度卷积网络提取人脸特征, 以及如何利用提取的特征进行人脸识别。最后会介绍如何在TensorFlow 中实践上述算法。
1 MTCNN 的原理
搭建人脸识别系统的第一步是人脸检测,也就是在图片中找到人脸的位置。在这个过程中,系统的输入是一张可能含有人脸的图片,输出是人脸位置的矩形框, 如图6-1所示。一般来说,人脸检测应该可以正确检测出图片中存在的所有人脸, 不能有遗漏, 也不能再错检。
获得包含人脸的矩形框后, 第二步要做的是人脸对齐(Face Alignment )。原始图片中人脸的姿态、位置可能再较大的区别,为了之后统一处理,要把人脸“摆正” 。为此, 需要检测人脸中的关键点( Landmark ),如眼睛的位置、鼻子的位置、嘴巴的位置、脸的轮廓点等。根据这些关键点可以使用仿射变换将人脸统一校准,以尽量消除姿势不同带来的误差,人脸对齐的过程如图6-2 所示。 
这里介绍一种基于深度卷积神经网络的人脸检测和人脸对齐方法——
MTCNN 。MT是英文单词Multi-task的简写,意即这种方法可以同时完成人
脸检测和人脸对齐两项任务。相比于传统方法, MTCNN的性能更好,可以
更精确地定位人脸;此外, MTCNN也可以做到实时的检测。
MTCNN 由三个神经网络组成,分别是P-Net 、R-Net 、0-Net。在使用这些网络之前,首先要将原始圄片缩放到不同尺度, 形成一个“图像金字塔”,如图6-3所示。接着会对每个尺度的图片通过神经网络计算一遍。这样做的原因在于:原始图片中的人脸存在不同的尺度, 如有的人脸比较大,有的人脸比较小。对于比较小的人脸,可以在放大后的图片上检测;对于比较大的
人脸,可以在缩小后的图片上检测。这样,就可以在统一的尺度下检测人脸了。 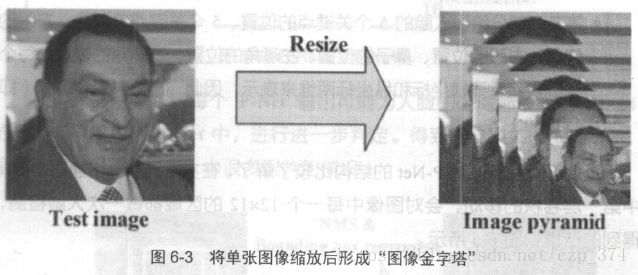
P-Net网络结构:
现在再来讨论第一个网络P-Net 的结构, 如图6-4所示, P-Net的输入是一个宽和高皆为12 像素,同时是3通道的RGB图像, 该网络要判断这个12x12的图像中是否含有人脸,并且给出人脸框相关键点的位置。因此,对应的输出由三部分组成: 
- 第一个部分要判断该图像是否是人脸(图6-4中的face classification),输出向量的形状为1x1x2,也就是两个值,分别为该图像是人脸的概率,以及该图像不是人脸的概率。这两个值加起来严格等于。之所以使用两个值来表示,是为了方便定义交叉损失。
- 第二个部分给出框的将却位置(图6-4中的bounding box regression),一般称之为框回归。P-Net输入的12x12的图像块可能并不是完美的人脸框的位置,如有的时候人脸并不正好为方形,有的时候12x12的图像块可能偏左或偏右,因此需要输出当前框位置相对于完美的人脸框位置的偏移。这个偏移由四个变量组成。一般地, 对于圄=图像中的框,可以用四个数来表示它的位置:框左上角的横坐标、框左上角的纵坐标、框的宽度、框的高度。因此,框回归输出的值是: 框左上角的横坐标的相对偏移、框左上角的纵坐标的相对偏移、框的宽度的误差、框的高度的误差。输出向量的形状就是图中的1x1x4。
- 第三个部分给出人脸的5 个关键点的位置。5 个关键点分别为:左眼的位置、右眼的位置、鼻子的位置、左嘴角的位置、右嘴角的位置。每个关键点又需要横坐标和纵坐标两维来表示,因此输出一共是10维(即1x1x10) 。
至此,我们应该对P-Net的结构比较了解了。在实际计算中,通过P-Net中的第一卷积层的移动,会对图像中每一个12x12的区域都做一次人脸检测,得到的结果如图6-5所示。 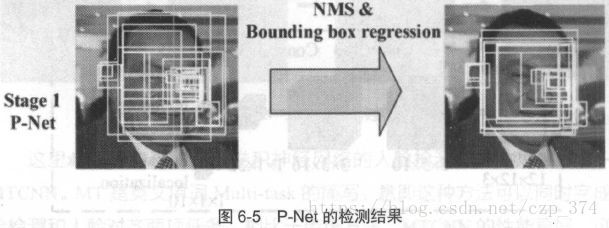
图中框的大小各有不同,除了框回归的影响外,主要是因为将图片金字塔中的各个尺度都使用了P-Net计算了一遍,因此形成了大小不同的人脸框。R-Net的网络结构如图6-6 所示。这个结构与之前的P-Net 非常类似,P-Net的输入是12×12×3的图像,R-Net是24x24×3的图像,也就是说,R-Net 判断
24×24×3的图像中是否有人脸,以及预测关键点的位置。R-Net的输出和
P-Net 完全一样,同样由人脸判别、框回归、关键点位置预测三部分组成。 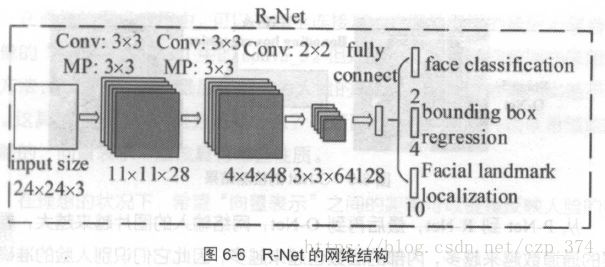
在实际应用中,对每个P-Net输出可能为人脸的区域都缩放到24x24的大小,再输入到R-Net中,进行进一步判定。得到的结果如图6-7 所示,显然R-Net消除了P-Net中很多误判的情况。 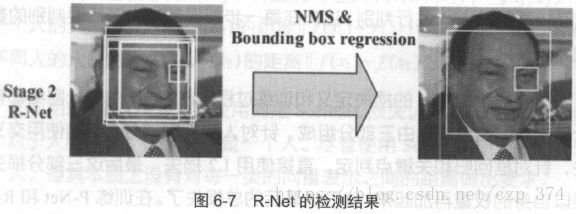
进一步把所高得到的区域缩放成48×48的大小,输入到最后的0-Net中, 0-Net的结构同样与P-Net类似,不同点在于它的输入是48×48×3的图像,网络的通道数和层数也更多了。o-Net的网络结构如图6-8 所示,检测结果如图6-9所示。 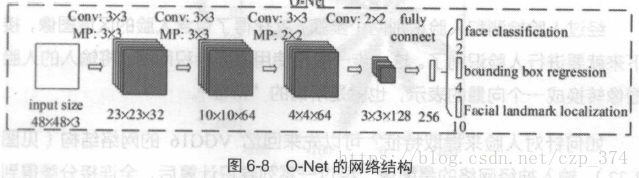

从P-Net到R-Net,最后再到O-Net,网络输入的图片越来越大,卷积层的通道数越来越多,内部的层数也越来越多, 因此它们识别人脸的准确率应该是越来越高的。同时, P-Net的运行速度是最快的, R-Net的速度其次,
O-Net的运行速度最慢。之所以要使用三个网络,是因为如果一开始直接对
图中的每个区域使用O-Net, 速度会非常慢。实际上P-Net先做了一遍过滤,将过滤后的结果再交给R-Net进行过滤,最后将过滤后的结果交给效果最好但速度较慢的O-Net进行判别。这样在每一步都提前减少了需要判别的数量,有效降低了处理时间。
最后介绍MTCNN的损失定义和训练过程。MTCNN中每个网络都有三部分输出,因此损失也由三部分组成。针对人脸判别部分,直接使用交叉熵损失,针对框回归和关键点判定,直接使用L2损失。最后这三部分损失各自乘以自身权重再加起来,就形成最后的总损失了。在训练P-Net和R-Net时,更关心框位置的准确性,而较少关注关键点判定的损失,因此关键点判定损失的权重很小。对于O-Net,关键点判定损失的权重较大。
2 使用深度卷积网络提取特征
经过人脸检测和人脸识别两个步骤,就获得了包含人脸的区域图像,接下来就要进行人脸识别了。这一步一般是使用深度卷积网络, 将输入的人脸图像转换成一个向量的表示,也就是所谓的“特征” 。
如何针对人脸来提取特征?可以先来回忆VGG16的网络结构(如下图),输入神经网络的是图像,经过一系列卷积计算后,全连接分类得到类别概率。 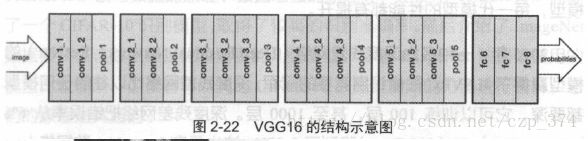
在通常的图像应用中,可以去掉全连接层,使用卷积层的最后一层当做图像的“特征”。但如果对人脸识别问题同样采用这种方法,即使用卷积层最后一层作为人脸“向量表示”,效果其实是不好的。这其中的原因和改进方法是什么?我们后面会谈到,这里我们先谈谈希望这种人脸的“向量表示”应该具有哪些性质。
在理想的状况下,希望“向量表示”之间的距离可以直接反应人脸的相似度:
- 对于同一个人的两张人脸图像,对应的向量之间的欧几里得距离应该是比较小的。
- 对于不同人的两张图像,对应的向量之间的欧几里得距离应该是比较大的
例如,这人脸图像为x1,x2x1,x2,对应的特征为f(x1),f(x2),f(x1),f(x2),当x1,x2x1,x2对应是同一个人的人脸时,f(x1),f(x2),f(x1),f(x2),的距离||f(x1)−f(x2)||2||f(x1)−f(x2)||2应该很小,而当是不同人脸时,f(x1),f(x2),f(x1),f(x2),的距离||f(x1)−f(x2)||2||f(x1)−f(x2)||2应该很大的。
在原始的CNN模型中,使用的是Softmax损失。Softmax是类别间的损失,对于人脸来说,每一类就是一个人。尽管使用Softmax损失可以区别出每个人,但其本质上没有对每一类的向量表示之间的距离作出要求。
举个例子,使用CNN对MNIST进行分类,设计一个特殊的卷积网络,让最后一层的选哪个量变成2维,此时可以画出每一类对应的2维向量,如图6-10所示。 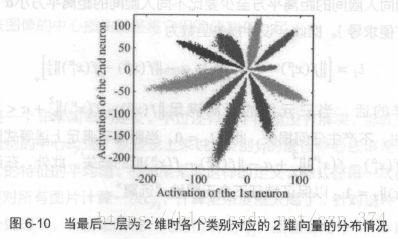
图6-10是直接使用Softmax训练得到的结果,它不符合希望特征具有的特点:
- 希望同一类对应的向量表示尽可能接近。但这里同一类的点可能具有很大的类间距离。
- 希望不同类对应的向量应该尽可能远。但在图中靠中心的位置,各个类别的距离都很近。
对于人脸图像同样会出现类似的情况。对此,有很多改进方法。这里介绍其中两种,一种是使用三元组损失(Triplet Loss),一种是使用中心损失。
2.1 三元组损失的定义
三元组损失( Triplet Loss )的原理是:既然目标是特征之间的距离应当具备某些性质,那么就围绕这个距离来设计损失。具体地,每次都在训练数据中去除三张人脸图像,第一章图像记为xaixia,第二章图像记为xpixip,第三章图片记为xnixin。这样一个“三元组”中,xaixia和xpixip对应的是同一个人的图像,而xnixin是另外一个不同人的人脸图像。因此,距离||f(xai)−f(xpi)||2||f(xia)−f(xip)||2应该较小,而距离||f(xai)−f(xni)||2||f(xia)−f(xin)||2应该较大。严格来说,三元组损失要求下面的式子成立
||f(xai)−f(xpi)||22+α<||f(xai)−f(xni)||22||f(xia)−f(xip)||22+α<||f(xia)−f(xin)||22
即相同人脸间的距离平方至少要比不同人脸间的距离平方小αα(取平方主要是方便求导)。据此,设计损失函数为:
Li=[||f(xai)−f(xpi)||22+α−||f(xai)−f(xni)||22]+Li=[||f(xia)−f(xip)||22+α−||f(xia)−f(xin)||22]+
这样的话,当三元组的距离满足
||f(xai)−f(xpi)||22+α<||f(xai)−f(xni)||22||f(xia)−f(xip)||22+α<||f(xia)−f(xin)||22时,不产生任何损失,此时Li=0Li=0。当距离不满足上述等式时,就会有值为||f(xai)−f(xpi)||22+α−||f(xai)−f(xni)||22||f(xia)−f(xip)||22+α−||f(xia)−f(xin)||22的损失。此外,在训练时会固定||f(x)||2=1||f(x)||2=1,以保证特征不会无限地“远离”。
三元组损失直接对距离进行优化,因此可以解决人脸的特征表示问题。但是在训练过程中,三元组的选择非常地高技巧性。如果每次都是随机选择三元组, 虽然模型可以正确地收敛,但是并不能达到最好的性能。如果加入“难例挖掘”,即每次都选择最难分辨的三元组进行训练,模型又往往不能正确地收敛。对此,又提出每次都选取那些“半难”( Semi-hard )的数据进行训练, 让模型在可以收敛的同时也保持良好的性能。此外,使用三元组损失
训练人脸模型通常还需要非常大的人脸数据集,才能取得较好的效果。
2.2 中心损失的定义
与三元损失不同,中心损失(Center Loss)不直接对距离进行优化,它保留了原有的分类模型,但又为每个类(在人脸识别模型中,一个类就对应一个人)指定了一个类别中心。同一类的图像对应的特征都应该尽量靠近自己的类别中心,不同类别中心尽量远离。与三元组损失相比,使用中心损失训练人脸魔心不需要使用特别的采样方法,而且利用较少的图像就可以达到与三元损失相似的效果。下面我们就一起来学习中心损失的定义。
还是设输入放入人脸图像为xixi,该人脸对应的类别为yiyi,对每个类别都规定一个类别中心,记作cyicyi。希望每个人脸图像对应的特征f(xi)f(xi)都尽可能接近其中心cyicyi。因此定义中心损失为
Li=12||f(xi)−cyi||22Li=12||f(xi)−cyi||22
多张图像的中心损失就是将他们的值加在一起
Lcenter=∑iLiLcenter=∑iLi
这是一个非常简单的定义。不过还有一个问题没有解决,那就是如何确定每个类别的中心cyicyi呢?从理论上来说,类别yiyi的最佳中心应该就是它对应所有图片的特征的平均值。但如果采取这样的定义,那么在每一次梯度下降时,都要对所有图片计算一次cyicyi,计算复杂度就太高了。针对这种情况,不妨近似处理一下,在初始阶段,先随机确定cyicyi,接着在每个batch内,使用Li=||f(xi)−cyi||22Li=||f(xi)−cyi||22对当前batch内的cyicyi也计算梯度,并使用该梯度更新cyicyi。此外,不能只是用中心损失来训练分类模型,还需要加入Softmax损失,也就是说,最终的损失由两部分构成,即L=Lsoftmax+λLcenterL=Lsoftmax+λLcenter,其中λλ是一个超参数。
最后来总结使用中心损失来训练人脸模型的过程。首先随机初始化各个中心cyicyi,接着不断地取出batch进行训练,在每个batch中,使用总的损失LL,除了使用神经网络模型的参数对模型进行更新外,也cyicyi进行梯度计算,并更新中心位置。
中心损失可以让训练处的特征具有“内聚性”。还是以MNIST的例子莱索,在未加入中心损失时,训练的结果不具有内聚性。再加入中心损失后,得到的特征如图6-11所示。 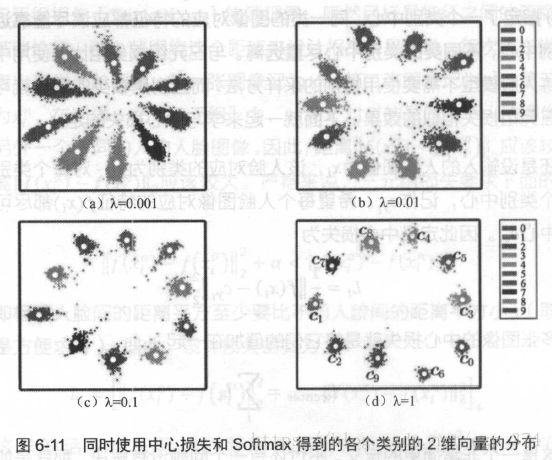
从图中可以看出,当中心损失的权重λ越大时,生成的特征就会具有越明显的“内聚性” 。
3 使用特征设计应用
在上一节中,当提取出特征后,剩下的问题就非常简单了。因为这种特征已经具有了相同人对应的向量的距离小,不同人对应的向量距离大的特点,接下来,一般的应用有以下几类:
- 人脸验证(Face Identification)。就是检测A、B是否属于同一个人。只需要计算向量之间的距离,设定合适的报警阈值(threshold)即可。
- 人脸识别(Face Recognition)。这个应用是最多的,给定一张图片,检测数据库中与之最相似的人脸。显然可以被转换为一个求距离的最近邻问题。
- 人脸聚类(Face Clustering)。在数据库中对人脸进行聚类,直接用K-means即可。
4 在TensorFlow中实现人脸识别
我们在这节会介绍一个项目,该项目支持使用MTCNN进行人脸的检测和对其,可以使用训练好的模型进行人脸识别,也支持训练自己的模型。接下来,我们首先介绍如何配置该项目的环境,接着介绍如何利用已经训练好的模型在LTW集合自己的图片上进行人脸识别,最后介绍如何重新训练自己的模型,以及在TensorFlow中是如何定义三元组损失和中心损失的。
4.1 项目环境设置
在运行该项目前,需要对环境进行适当设置。首先安装一些引用到的包,包括scipy、scikit-learn、opencv-python、hpy、matplotlib、Pillow、requests、psutil等。我们可以运行下面的代码,检查环境中缺少哪些包,然后自行安装。
# 以下是该项目中需要的库文件
import tensorflow as tf
import sklearn
import scipy
import cv2
import h5py
import matplotlib
import PIL
import requests
import psutil4.2 LFW人脸数据库
接下来会讲解如何使用已经训练好的模型在LFW ( Labeled Faces in the
Wild )数据库上测试,先来简单介绍下LFW 数据库。
LFW 人脸数据库是由美国马萨诸塞州立大学阿默斯特分校计算机视觉实验室整理完成的数据库,主要用来研究非受限情况下的人脸识别问题。LFW 数据库主要是从E联网上搜集图像,一共含高13000 多张人脸图像,每张图像都被标识出对应的人的名字,其中有1680 人对应不只一张图像。图6-12 展示了部分LFW数据库中的人脸图像: 
可以看出,在LFW 数据库中人脸的光照条件、姿态多种多样,有的人脸还存在部分遮挡的情况,因此识别难度较大。现在, LFW 数据库性能测评已经成为人脸识别算法性能的一个重要指标。
我们可以在网站http://vis-www.cs.umass.edu/lfw/lfw.tgz下载LFW数据库,这个数据库完全是开源的。下载后,假设假设有一个文件夹~/datasets专门保存数据集,就可以使用下面的命令将LFW 数据库解压,留待后面使用。
这里将下载的~/Downloads/Ifw.tgz文件解压到了文件夹~/datasets/lfw/raw 中,数据的结构应该类似于: 
即每个文件夹代表着一个人的名字,在每个人的文件夹下是这个人所有的人脸图像,这样LFW数据集就被准备好了。
4.3LFW数据库上的人脸检测和对齐
处理的第一步是使用MTCNN进行人脸检测和对齐3 并统一缩放到合适的大小。
MTCNN的实现主要在文件夹src/align中。其中,detect_face .py中定义了MTCNN的模型结构,由P-Net 、R-Net 、O-Net 三部分组成。这三部分网络已经提供好了预训练的模型,模型数据分别对应文件det1.npy 、det2.npy 、det3.npy 。align_dataset_ mtcnn. py 是使用MTCNN 的模型进行人脸的检测和对齐的入口代码。该文件夹中还有两个文件align_dataset.py和
align_dlib.py,它们都是使用dlib 中的传统方法对人脸进行检测,性能比
MTCNN稍差,在这里不再展开描述。
使用脚本align_dataset_mtcnn.py对LFW数据库进行人脸检测和对齐的方法是运行命令:
python src/align/align_dataset_mtcnn.py \
datasets/lfw/raw \
datasets/lfw/lfw_mtcnnpy_160 \
--image_size 160 --margin 32 \
--random_order该命令会创建一个datasets/lfw/lfw_mtcnnpy_160的文件夹,并将所有对齐好的人脸图像存放到这个文件夹中,数据的结构和原先datasets/lfw/raw中参数–mage_size 160 –margin 32 的含义是在MTCNN 检测得到的人脸框的基础上缩小32 像章在训练时使用的数据偏大),并缩放到160×160 大小。因此最后得到的对齐后的图像都是160x160像素的。这样的话,就成功地从原始图像中检测并对齐了人脸。
4.4 使用已有模型验证LFW数据库准确率
项目原作者提供了一个与训练模型。该模型使用的卷积网络结构是Inception ResNet v1,训练数据使用了一个非常大的人脸数据集MS-Celeb-1M,训练好的模型在LFW上可以达到99.2%左右的正确率。下载该模型后,将文件解压到目录~/models/facenet/下。解压后,应该得到一个~/models/facenet/20170512-110547目录,其中一下4个文件(我们可以将模型放到其他文件夹中,不过需要自行更改以下代码的对应部分):
20170512-110547.pb
model-20170512-110547.ckpt-250000.data-00000-of-00001
model-20170512-110547.ckpt-250000.index
model-20170512-110547.meta之后,运行下面的代码,可以在对齐好的LFW数据库中验证已有模型的正确率:
python src/validate_on_lfw.py \
~/datasets/lfw/lfw_mtcnnpy_160 \
~/models/facenet/20170512-110547 /最终得到的结果:
Runnning forward pass on LFW images
Accuracy: 0.992+-0.003
Validation rate: 0.97467+-0.01477 @ FAR=0.00133
Area Under Curve (AUC): 1.000
Equal Error Rate (EER): 0.0074.5 在自己的数据库上使用已有模型
当然,在实际应用过程中,还会关心如何在自己的图像上应用已有模型。下面就以计算人脸之间的距离为例,展示如何将模型应用到自己的数据上。
假设现在有三张图片./test_imgs/1.jpg、./test_imgs/2.jpg、./test_imgs/2.jpg
这三张图片中个含有一个人的脸,希望计算它们两两之间的距离。使用compare.py就可以实现,运行下面的代码:
python src/compare.py \
~/models/facenet/20170512-110547/ \
./test_imgs/1.jpg ./test_imgs/2.jpg ./test_imgs/3.jpg得到结果类似于:
Images:
0: ./test_imgs/1.jpg
1: ./test_imgs/2.jpg
2: ./test_imgs/3.jpg
Distance matrix
0 1 2
0 0.0000 0.7270 1.1283
1 0.7270 0.0000 1.0913
2 1.1283 1.0913 0.0000compare.py 首先会使用MTCNN在原始图片中进行检测和对齐:
# nrof_samples是图片总数目,image_paths存储了这些图片的路径
nrof_samples = len(image_paths)
# img_list中存储了对齐后的图像
img_list = [None] * nrof_samples
for i in list(range(nrof_samples)):
# 读入图像
img = misc.imread(os.path.expanduser(image_paths))
img_size = np.asarray(img.shape)[0:2]
# 使用P-Net、R-Net、O-Net(即MTCNN)检测并对齐图像
# 检测的结果存入bounding_boxes中
bounding_boxes, _ = align.detect_face.detect_face(img, minsize, pnet, rnet, onet, threshold, factor)
# 对于检测出的bounding_boxes,减去margin
det = np.squeeze(bounding_boxes[0, 0:4])
bb = np.zeros(4, dtype=np.int32)
bb[0] = np.maximum(det[0] - margin / 2, 0)
bb[1] = np.maximum(det[1] - margin / 2, 0)
bb[2] = np.minimum(det[2] + margin / 2, img_size[1])
bb[3] = np.minimum(det[3] + margin / 2, img_size[0])
# 裁剪出人脸区域,并缩放到卷积神经网络输入的大小
cropped = img[bb[1]:bb[3], bb[0]:bb[2], :]
aligned = misc.imresize(cropped, (image_size, image_size), interp='bilinear')
prewhitened = facenet.prewhiten(aligned)
img_list[i] = prewhitened
images = np.stack(img_list)对于返回的images,可以将它输入到已经训练好的模型中计算特征了,使用的代码为:
# Load the model
# 载入模型,args.model就是文件夹“~/models/facenet/20170512-110547/”
facenet.load_model(args.model)
# Get input and output tensors
# images_placeholder是输入图像的占位符,后面后面会把images传递给它
images_placeholder = tf.get_default_graph().get_tensor_by_name("input:0")
# embeddings就是卷积网络最后输出的“特征”
embeddings = tf.get_default_graph().get_tensor_by_name("embeddings:0")
phase_train_placeholder = tf.get_default_graph().get_tensor_by_name("phase_train:0")
# Run forward pass to calculate embeddings
# phase_train_placeholder占位符决定了现在是不是“训练阶段”
# 显然现在不是在训练模型,所以后面会指定phase_train_placeholder为False
# 计算特征
feed_dict = {images_placeholder: images, phase_train_placeholder: False}
emb = sess.run(embeddings, feed_dict=feed_dict)得到的emb存储了每个图像的“特征”。得到了特征,剩下的问题解决起来就非常简单了。这里是对计算两两之间的距离以得到人脸之间的相似度。对应的代码如下所示:
# nrof_images是图片总数目
nrof_images = len(args.image_files)
# 简单地打印图片名称
print('Images:')
for i in range(nrof_images):
print('%1d: %s' % (i, args.image_files[i]))
print('')
# 输出距离矩阵
# Print distance matrix
print('Distance matrix')
print(' ', end='')
for i in range(nrof_images):
print(' %1d ' % i, end='')
print('')
for i in range(nrof_images):
print('%1d ' % i, end='')
for j in range(nrof_images):
# 计算距离,emb[i,:]是第i个人脸图像特征,emb[j,:]是第j个人脸图的特征
dist = np.sqrt(np.sum(np.square(np.subtract(emb[i, :], emb[j, :]))))
print(' %1.4f ' % dist, end='')
print('')compare.py只是简单地计算了人脸之间的两两距离,我们可以根据得到的特征emb将程序应用到其它方面。例如人脸识别应用中,常常会被给定一张人脸图片,要求在某一个人脸数据库中检测与之最相似的图像。此时,就可以先对人脸数据库中的所有图片先计算一边与特征emb,并把这些特征保存下来,接着只需对给定人脸图片计算特征,并找出与之距离最近的特征即可,相关程序我们可以自行设计完成。
4.6 重新训练新模型
在第4.3~4.5节中,介绍了如何使用预训练的模型验证在LFW数据库上的正确率,以及识别用户自己的图像,本节介绍如何重新训练一个模型。
从头训练一个新模型需要非常多的训练数据,这里使用的是CASIA-WebFace数据集,该数据集包含了10575个人的494414张图像。CASIA-WebFace数据集需要研究机构自行申请,申请地址在http ://www.cbsr.ia.ac.cn/english/CASIA-WebFace-Database.html
获得CASIA-WebFace数据集后,将它解压到~/datasets/casia/raw目录中。此时文件夹~/datasets/casia/raw/中的数据结构应该类似于: 
其中,每个文件夹代表一个人,文件夹中对应这个人的所有人脸图片。与LFW数据集类似,同样先利用MTCNN对原始图像进行人脸检测和对齐,对应的代码为:
python src/align/align_dataset_mtcnn.py \
~/datasets/casia/raw/ \
~/datasets/casia/casia_maxpy_macnnpy_182 \
--image_size 182 --margin 44对齐后的人脸图像存放目录~./datasets/casia/casia_maxpy_mtcnnpy_182下。所有的图像像素都是182x182的图像,是为了流出一定空间给数据增强的裁剪环节。会在182x182像素的图像上随机裁剪出160x160的区域,在送入神经网络进行训练。
使用下面的命令即可开始训练:
python src/train_softmax.py \
--logs_base_dir ~/logs/facenet/ \
--models_base_dir ~/models/facenet/ \
--data_dir ~/datasets/casia/casia_maxpy_mtcnnpy_182 \
--image_size 160 \
--model_def models.inception_resnet_v1 \
--lfw_dir ~/datasets/lfw/lfw_mtcnnpy_160 \
--optimizer RMSPROP \
--learning_rate -1 \
--max_nrof_epochs 80 \
--random_crop --random_flip \
--learning_rate_schedule_file data/learning_rate_schedule_classifier_casia.txt \
--weight_decay 5e-5 \
--center_loss_factor 1e-2 \
--center_loss_alfa 0.9这里涉及的参数非常多,不必担心,下面会一一来进行说明。首先是文件src/train_softmax.py,它的功能是使用2.2节中讲解的中心损失来训练模型。之前已经讲过,单独使用中心损失的效果不好,必须结合Softmax损失一起使用,所以对应文件名是train_softmax.py。其他参数的含义如下:
- –logs_base_dir ~/logs/facenet/: 将会把孙连日志保存到~/logs/facenet/中。在运行时,会在~/logs/facenet/文件夹下新建一个以当前时间命名的目录,如20170621-114414,最终的日志会卸载~/logs/facenet/20170621-114414中。所谓日志文件,实际上就是TensorFlow中的events文件,包含当前损失、当前训练步数、当前学习率信息,可以使用TensorBoard查看这些信息。
- –models_base_dir ~/models/facenet/ : 最红训练好的模型就保存在~/models/facenet/ 目录下。在运行时同样会创建一个以当前时间命名的文件夹,训练好的模型就会被保存在类似~/models/facenet/20170621-114414的目录下。
- –data_dir ~/datasets/casia/casia_maxpy_mtcnnpy_182:训练数据的位置。这里使用之前已经对齐好的CASIA-WebFace数据。
- –image_size 160:输入网络的尺寸图片是160x160像素。
- –model_def models.inception_resnet_v1:比较关键的一个参数,他指定了训练的CNN结构为inception_resnet_v1。项目支持的所有CNN结构在src/models目录下。共支持inceotion_resnet_v1、inception_resnet_v2、squeezenet三个模型,真中前两个模型较大,最后一个模型较小。如果使用–model_def models.inception_resnet_v1后,出现内存或显存消耗光的情况,可以将其替换为–model_def models.squeezenet,来训练一个较小的模型。
- –lfw_dir ~/datasets/lfw/lfw_mtcnnpy_160:指定LFW数据集的位置。如果输入这个参数,每次执行完一个epoch,就会在LFW数据集上执行一次测试,并将测试后的正确率写到日志文件中。
- –optimizer RMSPROP 指定使用的优化方法。
- –learning_rate -1:原意指定学习率,但这里指定了辅助,在程序中将忽略这个参数,而是用后面的–learning_rate_schedule_file参数规划学习率。
- –max_nrof_epochs 80表示最多会跑80个epoch。
- keep_probability 0.8:在全连接层中,加入了dropout,这个参数表示dropout中链接被保持的概率。
- –random_crop –random_flip:这两个参数表示在数据增强时会进行随机的裁剪和翻转。
- –learning_rate_schedule_file data/learning_rate_schedule_classifier_casia.txt:在之前指定了–learning_rate -1,因此最终的学习率将有参数–learning_rate_schedule_file决定。这个参数指定了一个文件,该文件的内容为:
# Learning rate schedule
# Maps an epoch number to a learnig rate
0: 0.1
65: 0.01
77: 0.001
1000: 0.0001也就是说在开始时中一直使用0.1作为学习率,而运行到第65个epoch时使用0.01的学习率,运行第77个epoch时使用0.001的学习率。由于一共只运行80个epoch,因此最后的1000:0.0001实际不会生效。
- –weight_decay 5e-5:所有变量的正则化系数。
- –center_loss_factor 1e-2:中心损失和Softmax损失的平衡参数。
- –center_loss_alfa 0.9:中心损失的内部参数。
运行上述命令后即可开始训练,屏幕会打出类似下面的信息: 
其中,Epoch:[0][7/1000]表示当前为第0个epoch以及在当前epoch内的训练步数。Time表示在这一步消耗的事件,最后是损失相关的信息。
可以运行TensorBoard对训练情况进行监控。将目录切换至~/logs/facenet/<开始训练时间>文件夹中,就可以看到生成的events文件。打开TensorBoard的命令为。
tensorboard --logdir ~/logs/facenet/<开始训练时间>/- 1
打开http://localhost:6006,可以方便地监控训练情况。图6-13 展示了整
个训练过程中损失的变化情况(训练的模型为squeezenet ): 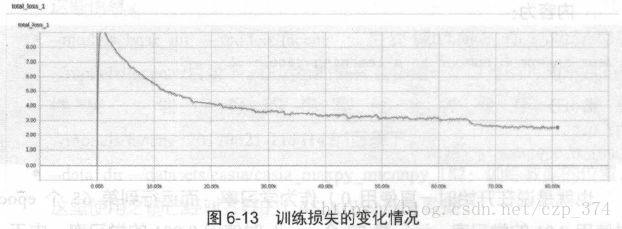
与之对应的,每个epoch 结束时程序还会在LFW数据库中自动做一次验证,对应的准确率的变化曲线如图6-14所示。 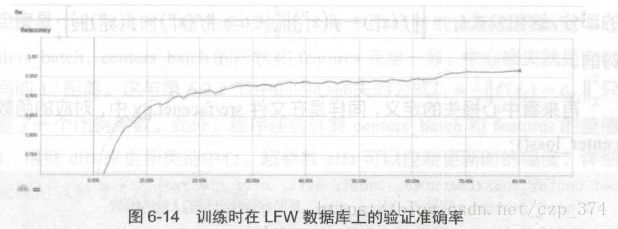
4.7三元组损失和中心损失的定义
最后,来分析代码中是如何定义三元组损失和中心损失的。
三元组损失的定义在src/facenet.py中,对应的函数为triplet_loss():
def triplet_loss(anchor, positive, negative, alpha):
with tf.variable_scope('triplet_loss'):
pos_dist = tf.reduce_sum(tf.square(tf.subtract(anchor, positive)), 1)
neg_dist = tf.reduce_sum(tf.square(tf.subtract(anchor, negative)), 1)
basic_loss = tf.add(tf.subtract(pos_dist,neg_dist), alpha)
loss = tf.reduce_mean(tf.maximum(basic_loss, 0.0), 0)
return loss输入的anchor、positive、negative分别为随机选取的人脸样本的特征、anchor的正样本的特征、anchor的负样本特征,它们的形状都是(batch_size,feature_size)。batch_size很好理解,feature_size是网络学习的人脸特征的维数。对应到三元组损失的公式Li=[||f(xai)−f(xpi)||22+α−||f(xai)−f(xni)||22]+Li=[||f(xia)−f(xip)||22+α−||f(xia)−f(xin)||22]+中的haul,anchor的每一行就是一个xaixia,poisitive的每一行就是一个xpixip,negative的每一行就是一个xnixin。先来分别计算正样本和负样本到anchor的L2L2距离。变量pos_dist就是anchor到各自正样本之间的距离||f(xai)−f(xpi)||22||f(xia)−f(xip)||22,变量neg_dist是anchor到负样本的距离||f(xai)−f(xni)||22||f(xia)−f(xin)||22。接下来,用pos_dist减去neg_dist再加上一个alpha,最红损失只计算大于0的部分,这和公式Li=[||f(xai)−f(xpi)||22+α−||f(xai)−f(xni)||22]+Li=[||f(xia)−f(xip)||22+α−||f(xia)−f(xin)||22]+是相符的。
再来看中心损失的定义,同样是在文件src/facenet.py中,对应的center_loss():
def center_loss(features, label, alfa, nrof_classes):
"""Center loss based on the paper "A Discriminative Feature Learning Approach for Deep Face Recognition"
(http://ydwen.github.io/papers/WenECCV16.pdf)
"""
# nrof_features就是feature_size,即神经网络计算的人脸维数
nrof_features = features.get_shape()[1]
# centers为变量,它是各个类别对应的类别中心
centers = tf.get_variable('centers', [nrof_classes, nrof_features], dtype=tf.float32,
initializer=tf.constant_initializer(0), trainable=False)
label = tf.reshape(label, [-1])
# 根据label,取出features中每一个样本对应的类别中心
# centers_batch的形状应该和features一致,为(batch_szie, feature_size)
centers_batch = tf.gather(centers, label)
# 计算类别中心和各个样本特征的差距diff
# diff用来更新各个类别中心的位置
# 计算diff时用到一个超参数,他可以控制中心位置的更新幅度
diff = (1 - alfa) * (centers_batch - features)
# 用diff来更新中心
centers = tf.scatter_sub(centers, label, diff)
# 计算loss
loss = tf.reduce_mean(tf.square(features - centers_batch))
# 返回loss和更新中心后
return loss, centers输入参数features是样本的也正,它的形状为(batch_size, feature_size)。label为这些样本各自的类别标签号(即属于哪一个人),它的形状为(batch_size, )。alfa是一个超参数,它是0~1之间的一个浮点数。nrof_classes是一个整数,他表示全部训练中样本的类别总数。
定义中心损失时,首先会根据各个样本的标签取出响应的类别中心centers_batch,centers_batch的形状和features完全一致,中心损失就是他们之间的L2L2距离。这与2.2节中的中心损失的公式Li=12||f(xi)−cyi||22Li=12||f(xi)−cyi||22只相差一个比例系数。此外,程序还会计算centers_batch和features的差值diff,根据diff来更新类别中心。超参数alfa可以控制更新时的幅度。详细的流程可以参考注释来阅读源码。
5 总结
这篇文章中,首先两部分介绍了使用深度学习进行人脸识别的接本原理,一是可以完成人脸检测和人脸对齐任务的MTCNN,二是使用合适损失来优化卷积神经网络以提取合适的人脸特征。接着,学习了如何在TensorFlow中实践上述内容。