电商用户行为分析-大数据
电商用户推荐分析
1 案例简介
本节介绍案例的目的、适用对象、时间安排、预备知识、硬件要求、软件工具、数据集和案例任务等内容。
1.1 案例目的
(1)熟悉Linux系统、MySQL,Hadoop,Hbase,Hive,Sqoop,R,Eclipse等系统和软件的安装和使用。
(2)了解大数据处理的基本流程。
(3)熟悉数据预处理方法。
(4)熟悉在不同类型数据库之间进行数据相互导入和导出。
(5)熟悉使用R语言进行可视化分析。
(6)熟悉使用Eclipse编写Java程序操作和Hbase数据库。
1.2 适用对象
(1)高校(高职)教师、学生
(2)大数据学习者
1.3 时间安排
本案例可以作为大数据入门级课程结束后的“大作业”,或者可以作为学生暑假或寒假大数据学习实践基础案例,建议在一周左右完成本案例。
1.4 预备知识
需要案例使用者,已经学习过大数据相关课程(例如入门级课程“大数据技术原理与应用”),了解大数据相关技术的基本概念与原理,了解Window操作系统、Linux操纵系统、大数据处理架构Hadoop的关键技术及其基本原理,列族数据库Hbase概念及其原理,数据仓库概念与原理,关系数据库概念与原理、R语言概念与应用等。
不过,由于本案例提供了全部操作细节,包括每个命令和运行结果,所以,即使没有相关背景知识,也可以按照操作说明顺利完成全部实验。
1.5 硬件要求
本案例可以在单机上完成,也可以在集群环境下完成。单机上完成本案例实验时,建议计算机硬件配置为:500GB以上硬盘,8GB以上内存。
1.6 软件工具
本案例所涉及的系统及软件包括Linux系统、MySQL,Hadoop,Hbase,Hive,Sqoop,R,Eclipse等。
相关软件的版本建议如下:
(1)Linux:Ubuntu16.04
(2)MySQL:5.7.16
(3)Hadoop:2.7.1
(4)Hbase:1.1.5
(5)Hive:1.2.1
(6)Sqoop:1.4.6
(7)R:3.2.3
(8)Eclipse:3.8
1.7 数据集
网站用户购物行为数据集,包括2000万条记录,其中实验截取了40000行。
1.8 案例任务
本案例需要完成以下实验任务。
(1)安装Linux操作系统。
(2)安装关系数据库MySQL。
(3)安装大数据处理框架Hadoop。
(4)安装列族数据库Hbase。
(5)安装数据仓库Hive。
(6)安装Sqoop。
(7)安装R。
(8)安装Eclipse。
(9)对文本文件形式的原始数据集进行预处理。
(10)把文本文件的数据集导入到数据仓库Hive中。
(11)对数据仓库Hive中的数据进行查询分析。
(12)使用Sqoop将数据从Hive导入MySQL。
(13)使用Sqoop将数据从MySQL导入Hbase。
(14)使用Hbase Java API把数据从本地导入到Hbase中。
(15)使用R对MySQL中的数据进行可视化分析。
2 实验环境搭建
为了顺利完成本案例各项实验,需要完成一下系统和软件的安装。
(1)安装Linux系统:如果未安装,参照第2章的相关内容,完成Linux系统的安装。
(2)安装Hadoop:如果未安装,参照第3章的相关内容,完成Hadoop的安装。
(3)安装MySQL:如果未安装,参照附录B的相关内容,完成MySQL的安装。
(4)安装Hbase:如果未安装,参照第5章的相关内容,完成Hbase的安装。
(5)安装Hive:如果未安装,参照第8章的相关内容,完成Hive的安装。
(6)安装Sqoop:如果未安装,参照第11章的相关内容,完成Sqoop的安装。
(7)安装Eclipse:如果未安装,参照第2章的相关内容,在Linux系统安装Eclipse。
3 实验步骤概述
本案例共包括4个实验步骤。
(1)本地数据集上传到数据仓库Hive。
(2)Hive数据分析。
(3)Hive,MySQL,Hbase数据互导。
(4)利用R进行数据可视化分析。
下面4个表分别给出了每个实验步骤所需的知识储备、训练技能和任务清单。
表1 本地数据集上传到数据仓库Hive
| 项目 | 解释 |
|---|---|
| 所需知识储备 | Linux系统基本命令、Hadoop项目结构、分布式文件系统(HDFS)的概念及其基本原理、数据仓库的概念及其基本原理、数据仓库Hive的概念及其基本原理 |
| 技能训练 | Hadoop的安装与基本操作、HDFS的基本操作、Linux的安装与基本操作、数据仓库Hive的安装与基本操作、基本的数据预处理方法 |
| 任务清单 | 安装Linux系统,数据集下载与查看,数据集预处理把数据集导入分布式文件系统HDFS中,在数据仓库Hive上创建数据库 |
表2 Hive数据分析
| 项目 | 解释 |
|---|---|
| 所需知识储备 | 数据仓库Hive的概念及其基本原理、SQL语句、数据库查询分析 |
| 训练技能 | 数据仓库Hive的基本操作、创建数据库和表、使用SQL语句进行查询分析 |
| 任务清单 | 启动Hadoop和Hive、创建数据库和表、简单查询分析、查询条数统计分析、关键字条件查询分析、根据用户行为分析、用户实时查询分析 |
表3 Hive、MySQL、Hbase数据互导
| 项目 | 解释 |
|---|---|
| 所需知识储备 | 数据仓库Hive的概念与基本原理、关系数据库的概念与基本原理、SQL语句、列族数据库Hbase的概念与基本原理 |
| 训练技能 | 数据仓库Hive的基本操作、关系数据库MySQL的基本操作、Sqoop工具的使用方法、Hbase API的Java编程、Eclipse开发工具的使用方法 |
| 任务清单 | Hive预操作、使用Sqoop将数据从Hive导入到MySQL、使用Sqoop将数据从MySQL导入到Hbase、使用Hbase Java API吧数据从本地导入到Hbase中 |
表4 利用R进行数据可视化分析
| 项目 | 解释 |
|---|---|
| 所需知识储备 | 数据可视化、R语言 |
| 训练技能 | 利用R语言对MySQL数据库中的数据进行数据可视化分析、R的安装、相关可视化依赖包的安装和使用、各种可视化图表的生成方法 |
| 任务清单 | 安装R语言包、安装可视化依赖包、柱形图可视化分析、散点图可视化分析、地图可视化分析 |
4 本地数据集上传到数据仓库Hive
4.1 实验数据集的下载
本案例采用的数据集为events_0.csv.zip,它包含一个数据集raw_events_0.csv(包含40000条记录)。
在Window系统中,把数据集events_0.csv.zip文件使用FTP方式,把Window系统中的events_0.csv.zip上传到Linux系统的“/home/hadoop/下载”目录下。
通过上面的方法,都可以顺利把数据集events_0.csv.zip文件下载到Linux系统的“/home/hadoop/下载”目录下。现在,在Linux系统中打开一个终端,执行下面命令:

通过上面命令,进入到events_0.csv.zip文件所在目录,并且可以看到有个events_0.csv.zip文件。
将events_0.csv.zip进行解压缩,首先建立一个用于运行本案例的目录bigdatacase,执行以下命令:

现在就可以看到在dataset目录下有一个文件,events_0.csv。执行下面命令取出前面10条记录看一下,可以看到,前10行记录如下:
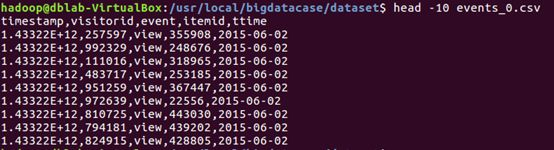
可以看出,每行记录都包含5个字段,数据集中的字段及其含义如下:
(1)timestamp(时间戳,后面的ttime由它转化而来,所以后面会用脚本做数据预处理时把这个字段全部删掉)
(2)visitorid (用户id)
(3)event(用户行为包括浏览、加购物车、交易,对应取值分别为view、addtocart、transaction)
(4)itemid (商品的id)
(5)ttime (记录产生时间,和时间戳一个意思,为了更直观转成了年月日的格式)
4.2 数据集的预处理
1.删掉文件第一行记录(即字段名称)
events_0.csv中的第一行是字段名称,把文件中的数据导入到数据仓库Hive中,不需要第一行字段名称,因此,在做数据预处理时,需要删掉第一行,执行以下命令:

2.对字段进行预处理
下面对数据集进行预处理,包括为每行记录增加一个id字段(让记录具有唯一性)、增加一个value价值字段(用来后续进行可视化分析),并且丢弃timestamp字段(后面分析不需要这个字段)。
下面要建一个脚本文件pre_deal1.sh,把这个脚本文件放在dataset目录下,和数据集events_0.csv放在同一个目录下:上面使用vim编辑器新建一个pre_deal.sh脚本文件,在这个脚本文件中加入下面代码:

使用awk可以逐个读取输入文件,并对逐行进行相应操作。其中,-F参数用于指出每行记录的不同字段之间用什么字符进行分隔,这里是用逗号进行分隔。处理逻辑代码需要用两个英文单引号引起来。 i n f i l e 是 输 入 文 件 文 件 的 名 称 , 这 里 会 输 入 e v e n t s 0 . c s v , infile是输入文件文件的名称,这里会输入events_0.csv, infile是输入文件文件的名称,这里会输入events0.csv,outfile表示处理结束后输出的文件名称,后面会使用tt.txt作为输出文件名称。
在上面的pre.deal1.sh代码的处理逻辑部分,srand()用于生成随机数的种子,id是为数据集新增的一个字段,它是一个自增类型,每条记录增加1,这样可以保证每条记录具有唯一性。这里再为数据集新增一个value字段,用来进行后面的数据可视化分析。为了给每条记录增加一个价值字段的值,在遍历数据集events_0.csv的时候,每当遍历到其中一条记录,就使用value=int(rand()*1001)语句随机生成一个0~1000的整数,作为商品的价值,增加到该记录中。
另外,代码中还包含下面这条语句:
print id"\t"$2"\t"$3"\t"$4"\t"value"\t"$5
在这行语句中,丢弃了每行记录的第1个字段,所以,没有出现$1。生成后的文件是\t进行分隔,这样,后续去查看数据的时候,屏幕上的显示效果就会更加整齐美观,每个字段在排版的时候都会对齐显示;相反,如果用逗号分隔,显示结果就会比较乱。
最后保存pre.deal1.sh代码文件,退出vim编辑器。
执行pre.deal1.sh脚本文件,对events_0.csv进行数据预处理,命令如下:
可以查看生成的user_table.txt,但是,不要直接打开,因为文件过大,直接打开会出错,可以使用head命令查看前10行数据:
执行上面命令后,可以得到如下结果:

4.3 导入数据库
下面把tt.txt中的数据导入到数据仓库Hive中。为了完成这个操作,首先需要把tt.txt上传到分布式文件系统HDFS中;然后在Hive中创建一个外部表,完成数据的导入。
1.启动HDFS
HDFS是是Hadoop的核心组件,因此,需要使用HDFS,必须首先安装Hadoop。这里假设已经安装了Hadoop,本书使用的是Hadoop2.7.1版本,安装目录是/usr/local/hadoop。
下面登录Linux系统,打开一个终端,执行下面命令启动Hadoop:
然后执行jps命令看一下当前运行的进程:

2.把tt.txt上传到HDFS中
现在需要把Linux本地文件系统中的tt.txt上传到分布式文件系统HDFS中,并存放在HDFS中的/bigdatacase/dataset目录下。
首先需要在HDFS的根目录下创建一个新的目录bigdatacase,并在这个目录下创建一个子目录dataset,具体命令如下:
然后把Linux本地文件系统中的tt.txt上传到分布式文件系统HDFS的/bigdatacase/dataset目录下,命令如下:
现在可以查看一下HDFS中的user_table.txt的前10条记录,命令如下:

3.在Hive上创建数据库
这里假设已经完成了Hive的安装,并且使用MySQL数据集保存Hive的元数据。本书安装的是Hive2.1.0版本,安装目录是/usr/local/hive。
下面在Linux系统中再新建一个终端。因为需要借助与MySQL保存Hive的元数据,所以,先启动MySQL数据库,可以在终端输入如下命令:
由于Hive是基于Hadoop的数据仓库,使用HiveQL语言撰写的查询语句,最终都会被Hive自动解析成MapReduce任务由Hadoop去具体执行;因此,需要启动Hadoop,然后再启动Hive。由于前面已经启动了Hadoop,所以,这里不需要再次启动Hadoop。下面在这个新的终端中执行下面命令进入Hive:

启动成功后,就进入了hive>命令提示符状态,可以输入类似SQL语句的HiveQL语句。
下面需要在Hive中创建一个数据库dblab,命令如下:
4.创建外部表
关于数据仓库Hive的内部表和外部表的区别可以查看相关网络资料,这里不再赘述。本书采用外部表方式。现在要在数据库dblab中创建一个外部表buser,它包含字段(id,visitorid,event,itemid,value,ttime),在hive命令提示符下输入如下命令:

现在可以使用下面命令查询相关数据:

5 数据分析
5.1 简单查询分析
首先执行一条简单的指令,执行结果如下:
![]()
![]()
5.2 查询条数统计分析
1.用聚合函数count()计算出表内有多少行数据,执行结果如下:
![]()
![]()
可以看到,在执行结果的最后有一个数字是40000,因为导入到Hive中的events_0.csv中包含了40000条记录。
2.在函数内部加上distinct,查出visitorid不重复的数据有多少条,命令及其执行结果如下:
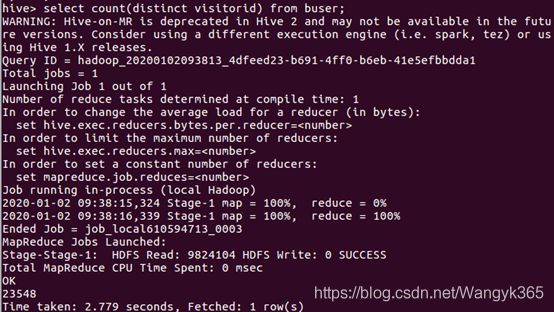
3.查询不重复的数据有多少条(为了排除客户刷单的情况),命令及其执行结果如下:


5.3 根据用户行为分析
1.查询表中商品被浏览的次数
![]()

2.查询表中商品被加入购物车的次数
![]()

3.查询表中商品被购买的次数
![]()
![]()
4.查询表中商品在2015-06-02这一天被购买的次数
![]()

| Event | 概率 |
|---|---|
| 浏览 | 96.8425% |
| 加入购物车 | 2.33% |
| 下单 | 0.8275% |
5.4 用户实时查询分析
查询2015-06-02这一天被点击的次数
![]()
![]()
查询2015-06-01这一天被下单的次数
![]()
![]()
查询2015-06-01这一天被下单的次数
![]()
![]()
查询2015-06-03这一天被下单的次数
![]()
![]()
5.5 分析高消费用户
假设一个商品消费在800以上的代表为高消费。
查询2015-06-01消费人数;
![]()
![]()
查询2015-06-01消费大于800的用户个数。
![]()
![]()
2015-06-01高消费率为26.67%。
查询2015-06-02消费大于800的用户个数。
![]()
![]()
查询2015-06-03消费人数;
![]()
![]()
查询2015-06-03消费大于800的用户个数。
![]()
![]()
2015-06-03高消费率为41.77%。
6 Hive、MySQL、Hbase数据互导
6.1 Hive预处理
1.创建临时表user_action
命令如下:

这个命令执行完以后,Hive会自动在HDFS文件系统中创建对应的数据文件/user/hive/warehouse/dblab.db/user_event。
现在可以新建一个终端,执行命令查看一下,确认这个数据文件在HDFS中确实已经被创建,在新建的终端中执行下面命令:
![]()
上述结果可以说明,这个数据文件在HDFS中确实被创建。
2.将buser表中的数据插入到user_event
在“Hive数据分析”中,已经在Hive中的dblab数据库中创建了一个外部表buser。下面把dblab.buser数据插入到dblab.user_event表中,命令如下:
然后执行下面命令查询上面的插入命令是否成功执行,执行结果如图所示:
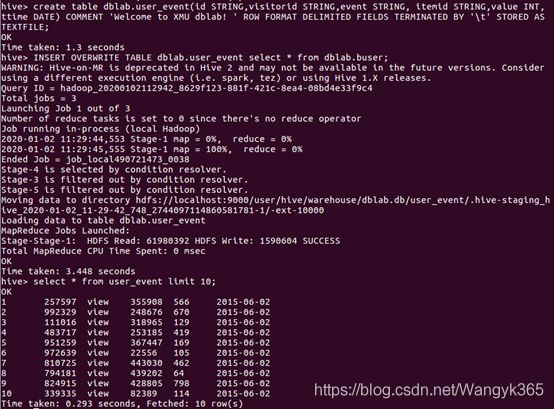
6.2 使用Sqoop将数据从Hive导入MySQL
1.将前面生成的临时表数据从Hive导入到MySQL中
MySQL连接成功:
1)登录MySQL
在Linux系统中新建一个终端,执行下面命令:

为了简化操作,本书直接使用root用户登录MySQL数据库,但是,在实际应用中,建议在MySQL中再另外创建一个用户。
执行上面命令以后,就进入mysql>命令提示符状态。
2)创建查看数据库

3)创建表
下面在MySQL的数据库dblab中创建一个新表user_event,并设置其编码为utf8:

创建成功后,输入下面命令退出MySQL:
![]()
4)导入数据
回到shell命令提示符状态。下面可以执行数据导入操作:

上面命令的具体含义如表5所示:
表5 sqoop export命令的含义
| 命令 | 含义 |
|---|---|
| ./bin/sqoop export | 数据从Hive复制到MySQL中 |
| connect jdbc:mysql://localhost:3306/dblab | 数据库的连接地址 |
| username root | MySQL数据库的登录用户名 |
| password hadoop | MySQL数据库的登录密码 |
| table user_event | MySQL中的表,即将被导入的表名称 |
| export-dir ‘/user/hive/warehouse/dblab.db/user_event | Hive中被导出的文件 |
| fields-terminated-by’\t’ | Hive中被导出的文件字段的分隔符 |
上面命令执行以后,如果输出以下信息,则表示导入成功:

2.查看MySQL中user_action表信息
下面需要再次启动MySQL,进入mysql>命令提示符状态:
然后执行下面命令查询user_event表中的数据,会得到类似下面的查询结果:

至此,从Hive导入数据到MySQL中的操作,顺利完成。
6.3 使用Sqoop将数据从MySQL导入 HBase
1.启动Hadoop集群、MySQL服务、HBase服务
之前已经启动了Hadoop集群和MySQL服务,这里请确认已经按照前面操作启动成功。现在需要再启动HBase服务。HBase都安装目录是/usr/local/hbase,且HDFS被配置为使用HDFS来存储数据。在Linux新建一个终端,执行下面命令:
2.启动HBase Shell
执行如下命令启动HBase Shell:
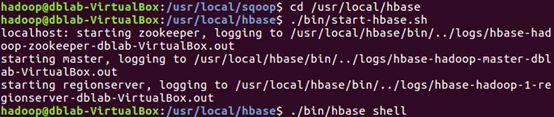
启动成功后,就进入了hbase>命令提示符状态:
3.创建表user_event
命令如下:

上面命令执行后,会在HBase中创建一个user_event表,这个表有一个列族f1,历史版本保留数量为5.
4.导入数据
下面新建一个终端,执行下面命令导入数据:

注意:IP部分改为本机IP地址或localhost。同时,HBase只支持十六进制存储中文。上面这条命令的具体含义如表6所示。
表 sqoop import命令的具体含义
| 命令 | 含义 |
|---|---|
| ./bin/sqoop import | 执行导入操作 |
| import | 执 |
| connect jdbc://localhost:3306/dblab | 数据库连接地址 |
| username root | 登录数据库的用户名 |
| password hadoop | 登录数据库的密码 |
| table user_event | 所要访问的数据库表 |
| hbase-table user_event | HBase中表的名称 |
| column-family f1 | 列族名称 |
| hbase-row-key id | HBase行键 |
| hbase-create-table | 是否在不存在情况下创建表 |
| m l | 启动Map的数量 |
执行上面的sqoop import命令后,会得到类似下面的结果:

5.查看HBase中user_action表数据
现在再次切换到HBase Shell运行的那个终端窗口,在hbase>命令提示符状态下,执行下面命令查询刚才导入的数据。因为有40000条记录,所以,用LIMIT只查询前10行记录,会得到类似下面的结果:

注意:用limit10是返回HBase表中前面10行数据,但是,上面的结果,从“行数”来看,似乎不是10行,而是远远多于10行,这是因为,HBase在显示数据的时候,和关系型数据库MySQL是不同的,每行显示的不是一行记录,而是一个“单元格”。
7 利用R进行数据可视化分析
7.1 安装R
作者已经提前安装。
7.2 安装依赖库
作者已经提前安装。
7.3分析结果及可视化分析
在进行可视化之前,首先要明确我们要分析什么,这样我们才会求出这个数据集,然后用图形化的表示出来。接下来,我要分析以下要点:
- 画出所有用户浏览不同价格商品的用户数量图(价格-浏览量)
- 所有被加入购物车的商品价格与对应加入数量图(购物车商品价格-数量)
- 所有被下单商品的价格与该上商品的下单数量图(商品价格-下单量)
1.连接MySQL,并获取数据
在Linux系统中新建另外一个终端,然后执行下面命令启动MySQL数据库:
屏幕上会弹出窗口提示你输入密码,本书的MySQL数据库的用户名是root,密码是hadoop,所以,直接输入密码hadoop,就可以成功启动MySQL数据库。
下面需要查看一下MySQL数据库中的数据,首选执行如下命令进入MySQL命令提示符状态:


2.分析消费者对商品的行为 - summary()函数可以得到样本数据类型和长度,如果样本是数值型,还能得到样本数据的最小值、最大值、四分位数和均值信息。首先使用summary()函数查看MySQL数据库中表user_event的字段value的类型,命令及其运行结果如下:

- 接下来用柱形图展示所有用户浏览不同价格商品的用户数量图(价格-浏览量),命令如下:

上面两行命令中:第一行library(ggplot2)命令用来导入依赖库ggplot2;第二行命令用来完成绘图。运行结果如图所示:

3. 分析浏览量排名前十的商品
分析浏览量排名前十的商品及其销量,可以采用如下命令:
在上面的命令语句中,subset()函数用于从某一个数据集中选择出符合某条件的数据或者相关的列。table()对应的就是统计学中的“列联表”,是一种记录频数的方法。sort()用来完成排序,返回排序后的数值向量。上述命令执行结果如下:

3. 分析浏览量排名前十的商品
分析浏览量排名前十的商品及其销量,可以采用如下命令:
在上面的命令语句中,subset()函数用于从某一个数据集中选择出符合某条件的数据或者相关的列。table()对应的就是统计学中的“列联表”,是一种记录频数的方法。sort()用来完成排序,返回排序后的数值向量。上述命令执行结果如下:

4. 分析浏览量排名前十的顾客

5. 分析下单量排名前十的商品

6. 加入购物车最多的排名前十的顾客

7. 加入购物车最多的排名前十的商品

8. 用柱形图展示所有被加入购物车的商品价格与对应加入数量图(购物车商品价格-数量),命令如下:
![]()

9. 用柱形图展示所有被下单商品价格与对应下单数量图(商品价格-下单量),命令如下:
![]()
